LMPAN: A Lightweight Multi-Path Alignment Network for Joint Full-Duplex Acoustic Echo Cancellation and Noise Suppression
Pith reviewed 2026-07-03 05:04 UTC · model grok-4.3
The pith
LMPAN achieves performance comparable to DeepVQE-S for joint full-duplex echo cancellation and noise suppression using only 480K parameters and real-time inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
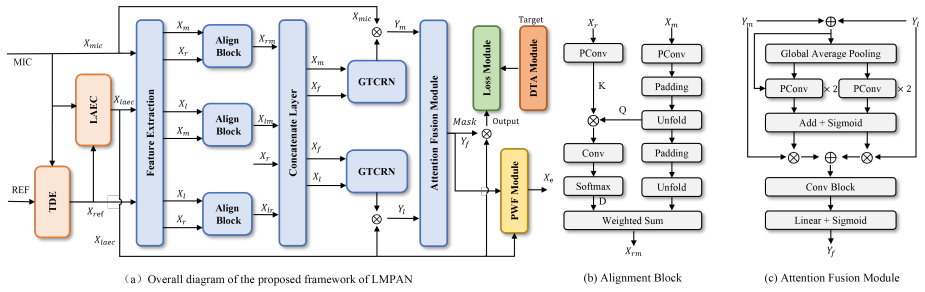
LMPAN performs joint full-duplex acoustic echo cancellation and noise suppression through a multi-path alignment stage that corrects temporal and energy mismatches across reference, linear AEC output, and microphone signals, followed by an attention-based mechanism that dynamically integrates enhanced features under varying conditions and a post-filtering module with dynamic target generation for downstream tasks. The network is trained in two stages leveraging self-supervised learning representations, resulting in a model with 480K parameters and 126 MACs that achieves performance comparable to DeepVQE-S while supporting real-time inference.
What carries the argument
Multi-path alignment stage that corrects temporal and energy mismatches across reference, LAEC output, and microphone signals, paired with an attention-based mechanism for dynamic feature integration.
If this is right
- The model enables real-time on-device processing for full-duplex spoken dialogue systems without cloud offloading.
- The post-filtering module with dynamic targets improves compatibility with downstream tasks such as ASR and VAD.
- Two-stage training with self-supervised representations enhances perceptual quality under varying acoustic scenarios.
- Low parameter count and MACs support deployment on resource-constrained hardware while maintaining comparable performance.
Where Pith is reading between the lines
- On-device processing could reduce latency and privacy risks by keeping audio handling local rather than sending data to servers.
- The alignment approach might extend to other multi-signal audio problems such as multi-microphone setups or beamforming.
- Further hardware-specific testing could reveal whether the design maintains robustness across different microphone and speaker configurations in consumer devices.
Load-bearing premise
The multi-path alignment stage and attention-based mechanism can reliably correct mismatches and integrate features across diverse acoustic conditions and hardware distortions.
What would settle it
A controlled test on recordings with large temporal offsets or energy mismatches between signals where LMPAN metrics fall below DeepVQE-S would show the alignment and attention components do not deliver the claimed correction and integration.
Figures

read the original abstract
We propose a lightweight multi-path alignment network (LMPAN) for on-device joint acoustic echo cancellation (AEC) and noise suppression (NS) in full-duplex spoken dialogue systems. To address hardware-induced distortions and dynamic acoustic conditions, we introduce three core innovations: (1) a multi-path alignment stage correcting temporal and energy mismatches across reference, linear AEC (LAEC) output, and microphone signals; (2) an attention-based mechanism that dynamically integrates enhanced LAEC and microphone features under varying acoustic scenarios; (3) a post-filtering module with a dynamic target generation strategy for downstream tasks (ASR, VAD). Furthermore, we adopt a two-stage training framework leveraging self-supervised learning representations to enhance perceptual quality. Experiments show that LMPAN, with only 480K parameters and 126 MACs, achieves performance comparable to the state-of-the-art lightweight model DeepVQE-S, while ensuring real-time inference capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LMPAN, a lightweight multi-path alignment network for joint full-duplex acoustic echo cancellation (AEC) and noise suppression (NS). It introduces three innovations: (1) a multi-path alignment stage to correct temporal and energy mismatches across reference, LAEC output, and microphone signals; (2) an attention-based mechanism for dynamic feature integration under varying conditions; (3) a post-filtering module with dynamic target generation. A two-stage training framework using self-supervised learning representations is adopted. The central claim is that LMPAN (480K parameters, 126 MACs) achieves performance comparable to DeepVQE-S while supporting real-time inference on-device.
Significance. If the performance claims hold with proper validation, the work would provide a practical contribution to efficient on-device audio processing for full-duplex spoken dialogue systems, addressing hardware distortions at low computational cost (480K params / 126 MACs). The emphasis on real-time capability and downstream task compatibility (ASR, VAD) aligns with deployment needs in resource-constrained environments.
major comments (2)
- [Abstract] Abstract: The headline claim that LMPAN achieves performance comparable to the state-of-the-art lightweight model DeepVQE-S is stated without any supporting metrics, datasets, baselines, error analysis, or quantitative results. This leaves the central experimental claim without verifiable evidence.
- [Abstract] Abstract (and implied experimental section): No ablation studies, removal experiments, or per-component metric deltas are reported for the multi-path alignment stage or the attention-based integration mechanism. These are presented as core innovations responsible for mismatch correction and dynamic feature integration, yet their specific contributions cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where the abstract and experimental reporting can be strengthened. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that LMPAN achieves performance comparable to the state-of-the-art lightweight model DeepVQE-S is stated without any supporting metrics, datasets, baselines, error analysis, or quantitative results. This leaves the central experimental claim without verifiable evidence.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript, we will augment the abstract with key metrics (e.g., ERLE, PESQ, STOI) from the AEC-Challenge and internal datasets, along with direct comparisons to DeepVQE-S and other baselines. The full experimental details, including error analysis, remain in Section 4. revision: yes
-
Referee: [Abstract] Abstract (and implied experimental section): No ablation studies, removal experiments, or per-component metric deltas are reported for the multi-path alignment stage or the attention-based integration mechanism. These are presented as core innovations responsible for mismatch correction and dynamic feature integration, yet their specific contributions cannot be assessed.
Authors: We acknowledge the absence of ablation studies for the multi-path alignment and attention-based integration components. We will add a dedicated ablation subsection in the experimental results (Section 4) that reports performance deltas when each module is removed, using the same evaluation metrics and datasets. revision: yes
Circularity Check
No significant circularity; empirical model proposal with external benchmarks
full rationale
The paper proposes an empirical neural network architecture (LMPAN) for joint AEC and NS, describing three architectural innovations and reporting experimental performance against an external baseline (DeepVQE-S). No equations, derivations, or first-principles predictions are presented that reduce by construction to fitted parameters, self-defined quantities, or self-citation chains. All performance claims reference independent comparison models and datasets outside the paper's own fitted values, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
free parameters (1)
- Network weights
axioms (1)
- domain assumption Linear acoustic echo paths and additive background noise can be modeled and mitigated by a combination of linear AEC followed by nonlinear neural stages.
invented entities (3)
-
Multi-path alignment stage
no independent evidence
-
Attention-based integration mechanism
no independent evidence
-
Post-filtering module with dynamic target generation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Full-duplex spoken dialogue systems (FDSDS) have made re- markable progress with the development of large language mod- els (LLMs), enabling more natural interactions [1,2]. However, their performance degrades substantially under adverse echo and noise conditions [3], highlighting the critical importance of acoustic echo cancellation (AEC) an...
-
[2]
METHODOLOGY 2.1. Problem formulation We assume an FDSDS in Fig. 1, where near-end speech is con- taminated by echo and noise. The observed signal model can be arXiv:2607.02062v1 [eess.AS] 2 Jul 2026 Figure 2:Overall structure of the proposed LMPAN system. Details for key components are given in: (a) Overall diagram of the proposed framework of LMPAN, (b) ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
EXPERIMENTS 3.1. Experimental Setup Datasets:In our experiments, we utilize matched clean and noisy speech pairs from ICASSP 2022/2023 AEC Chal- lenge [10,27] and noise data from DNS Challenge [28,29]. For realistic full-duplex evaluation, we additionally collect a large- scale echo dataset from 40 smartphones at varying playback volume levels (30%–100%),...
2022
-
[4]
By incorporating multi-path alignment and attention-based fusion module, the model effec- tively adapts to diverse acoustic conditions and hardware vari- ations
CONCLUSION In this paper, we propose LMPAN, a lightweight multi-path alignment network for on-device joint AEC and NS in full- duplex spoken dialogue systems. By incorporating multi-path alignment and attention-based fusion module, the model effec- tively adapts to diverse acoustic conditions and hardware vari- ations. Combined with a two-stage training s...
-
[5]
LLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems
H. Zhang, W. Li, R. Chen,et al., “LLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems,”arXiv preprint arXiv:2502.14145, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A Full-Duplex Speech Dia- logue Scheme Based on Large Language Models,
P. Wang, S. Lu, Y . Tang,et al., “A Full-Duplex Speech Dia- logue Scheme Based on Large Language Models,”arXiv preprint arXiv:2405.19487, 2024
-
[7]
ICASSP 2021 Acoustic Echo Cancellation Challenge: Datasets, Testing Framework, and Results,
K. Sridhar, R. Cutler, A. Saabas,et al., “ICASSP 2021 Acoustic Echo Cancellation Challenge: Datasets, Testing Framework, and Results,” inProc. ICASSP, 2021, pp. 151–155
2021
-
[8]
A Small-Footprint Acoustic Echo Cancel- lation Solution for Mobile Full-Duplex Speech Interactions,
Y . Jiang and T. Tian, “A Small-Footprint Acoustic Echo Cancel- lation Solution for Mobile Full-Duplex Speech Interactions,” in Proc. ICASSP, 2025, pp. 1–5
2025
-
[9]
Benesty, T
J. Benesty, T. G ¨ansler, D. R. Morgan,et al.,Advances in Network and Acoustic Echo Cancellation. Springer, 2001
2001
-
[10]
An Online Algorithm for Echo Cancellation, Dereverberation and Noise Reduction Based on a Kalman-EM Method,
N. Cohen, G. Hazan, and B. Schwartz, “An Online Algorithm for Echo Cancellation, Dereverberation and Noise Reduction Based on a Kalman-EM Method,”J. Audio, Speech, Music Process., vol. 2021, no. 1, p. 33, 2021
2021
-
[11]
Two-Stage Acoustic Echo Cancel- lation Network with Dual-Path Alignment Interactions,
Z. Jiang, H. Li, and N. Zheng, “Two-Stage Acoustic Echo Cancel- lation Network with Dual-Path Alignment Interactions,” inProc. ICASSP, 2024, pp. 606–610
2024
-
[12]
DeepVQE: Real Time Deep V oice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation,
E. Indenbom, N.-C. Ristea, A. Saabas,et al., “DeepVQE: Real Time Deep V oice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation,” inProc. ICASSP, 2023, pp. 20–24
2023
-
[13]
Improv- ing Acoustic Echo Cancellation for V oice Assistants Using Neu- ral Echo Suppression and Multi-Microphone Noise Reduction,
J. Heitkaemper, A. Narayanan, T. Z. Shabestary,et al., “Improv- ing Acoustic Echo Cancellation for V oice Assistants Using Neu- ral Echo Suppression and Multi-Microphone Noise Reduction,” in Proc. ICASSP, 2024, pp. 736–740
2024
-
[14]
ICASSP 2023 Acoustic Echo Cancellation Challenge,
R. Cutler, A. Saabas, T. Parnamaa,et al., “ICASSP 2023 Acoustic Echo Cancellation Challenge,”arXiv preprint arXiv:2309.12553, 2023
-
[15]
Y . Liu, L. Wan, Y . Li,et al., “FADI-AEC: Fast Score Based Dif- fusion Model Guided by Far-end Signal for Acoustic Echo Can- cellation,”arXiv preprint arXiv:2401.04283, 2024
-
[16]
Two-Step Band-Split Neural Network Approach for Full-Band Residual Echo Suppression,
Z. Zhang, S. Zhang, M. Liu,et al., “Two-Step Band-Split Neural Network Approach for Full-Band Residual Echo Suppression,” in Proc. ICASSP, 2023, pp. 1–5
2023
-
[17]
Multi-Task Deep Residual Echo Suppression with Echo-Aware Loss,
S. Zhang, Z. Wang, J. Sun,et al., “Multi-Task Deep Residual Echo Suppression with Echo-Aware Loss,” inProc. ICASSP, 2022, pp. 9127–9131
2022
-
[18]
Real-Time Joint Person- alized Speech Enhancement and Acoustic Echo Cancellation,
S. Eskimez, T. Yoshioka, A. Ju,et al., “Real-Time Joint Person- alized Speech Enhancement and Acoustic Echo Cancellation,” in Proc. Interspeech, 2023, pp. 1–5
2023
-
[19]
Align-ULCNet: Towards Low-Complexity and Robust Acoustic Echo and Noise Reduction,
S. S. Shetu, N. K. Desiraju, W. Mack,et al., “Align-ULCNet: Towards Low-Complexity and Robust Acoustic Echo and Noise Reduction,”arXiv preprint arXiv:2410.13620, 2025
-
[20]
SCA: Streaming Cross- Attention Alignment for Echo Cancellation,
Y . Liu, Y . Shi, Y . Li,et al., “SCA: Streaming Cross- Attention Alignment for Echo Cancellation,”arXiv preprint arXiv:2211.00589, 2022
-
[21]
Data Augmentation and Loss Normaliza- tion for Deep Noise Suppression,
S. Braun and I. Tashev, “Data Augmentation and Loss Normaliza- tion for Deep Noise Suppression,” inProc. Interspeech, 2020, pp. 3815–3819
2020
-
[22]
Time Delay Estimation by Generalized Cross Correlation Methods,
M. Azaria and D. Hertz, “Time Delay Estimation by Generalized Cross Correlation Methods,”IEEE Trans. Acoust., Speech, Signal Process., vol. 32, no. 2, pp. 280–285, 1984
1984
-
[23]
On the Importance of Power Compression and Phase Estimation in Monaural Speech Dere- verberation,
A. Li, C. Zheng, R. Peng,et al., “On the Importance of Power Compression and Phase Estimation in Monaural Speech Dere- verberation,”J. Acoust. Soc. Am. Express Lett., vol. 2, no. 8, p. 085001, 2021
2021
-
[24]
GTCRN: A Speech Enhance- ment Model Requiring Ultralow Computational Resources,
X. Rong, T. Sun, X. Zhang,et al., “GTCRN: A Speech Enhance- ment Model Requiring Ultralow Computational Resources,” in Proc. ICASSP, 2024, pp. 971–975
2024
-
[25]
A Closer Look at Wav2vec2 Embeddings for On-Device Single-Channel Speech Enhance- ment,
R. Shankar, K. Tan, B. Xu,et al., “A Closer Look at Wav2vec2 Embeddings for On-Device Single-Channel Speech Enhance- ment,” inProc. ICASSP, 2024, pp. 1–5
2024
-
[26]
Vec-Tok Speech: Speech Vector- ization and Tokenization for Neural Speech Generation,
X. Zhu, Y . Lv, Y . Lei,et al., “Vec-Tok Speech: Speech Vector- ization and Tokenization for Neural Speech Generation,”arXiv preprint arXiv:2310.07246, 2023
-
[27]
EchoFree: Towards Ultra Lightweight and Efficient Neural Acoustic Echo Cancellation,
X. Li, B. Kang, Z. Wang,et al., “EchoFree: Towards Ultra Lightweight and Efficient Neural Acoustic Echo Cancellation,” arXiv preprint arXiv:2508.06271, 2025
-
[28]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen,et al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[29]
SNR Loss: A New Objective Measure for Predicting Speech Intelligibility of Noise-Suppressed Speech,
J. Ma and P. C. Loizou, “SNR Loss: A New Objective Measure for Predicting Speech Intelligibility of Noise-Suppressed Speech,” ELSEVIER Speech Commun., vol. 53, no. 3, pp. 340–354, 2011
2011
-
[30]
A Deep Learning Loss Function Based on the Perceptual Evaluation of Speech Quality,
J. M. Martin-Donas, A. M. Gomez, J. A. Gonzalez,et al., “A Deep Learning Loss Function Based on the Perceptual Evaluation of Speech Quality,”IEEE Signal Process. Lett., vol. 25, no. 11, pp. 1680–1684, 2018
2018
-
[31]
ICASSP 2022 Acoustic Echo Cancellation Challenge,
R. Cutler, A. Saabas, T. P ¨arnamaa,et al., “ICASSP 2022 Acoustic Echo Cancellation Challenge,” inProc. ICASSP, 2022, pp. 9107– 9111
2022
-
[32]
ICASSP 2022 Deep Noise Suppression Challenge,
H. Dubey, V . Gopal, R. Cutler,et al., “ICASSP 2022 Deep Noise Suppression Challenge,” inProc. ICASSP, 2022, pp. 9271–9275
2022
-
[33]
The Interspeech 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,
C. K. Reddy, V . Gopal, R. Cutler,et al., “The Interspeech 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,” inProc. Interspeech, 2020, pp. 340–354
2020
-
[34]
A study on more realistic room simulation for far-field keyword spotting,
E. Bezzam, R. Scheibler, C. Cadoux,et al., “A study on more realistic room simulation for far-field keyword spotting,” inProc. APSIPA ASC, 2020
2020
-
[35]
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,
D. S. Park, W. Chan, Y . Zhang,et al., “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” inProc. Interspeech, 2019, pp. 2613–2617
2019
-
[36]
AECMOS: A Speech Quality Assessment Metric for Echo Impairment,
M. Purin, S. Sootla, M. Sponza,et al., “AECMOS: A Speech Quality Assessment Metric for Echo Impairment,”arXiv preprint arXiv:2110.03010, 2022
-
[37]
Semantic V AD: Low-Latency V oice Activity Detection for Speech Interaction,
M. Shi, Y . Shu, L. Zuo,et al., “Semantic V AD: Low-Latency V oice Activity Detection for Speech Interaction,” inProc. Inter- speech, 2023, pp. 5047–5051
2023
-
[38]
Paraformer: Fast and Accurate Parallel Transformer for Non-Autoregressive End-to- End Speech Recognition,
Z. Gao, S. Zhang, I. McLoughlin,et al., “Paraformer: Fast and Accurate Parallel Transformer for Non-Autoregressive End-to- End Speech Recognition,” inProc. Interspeech, 2022, pp. 5144– 5148
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.