Enhancing Fitness Intelligence through Domain-Specific LLM Post-Training
Pith reviewed 2026-07-03 13:08 UTC · model grok-4.3
The pith
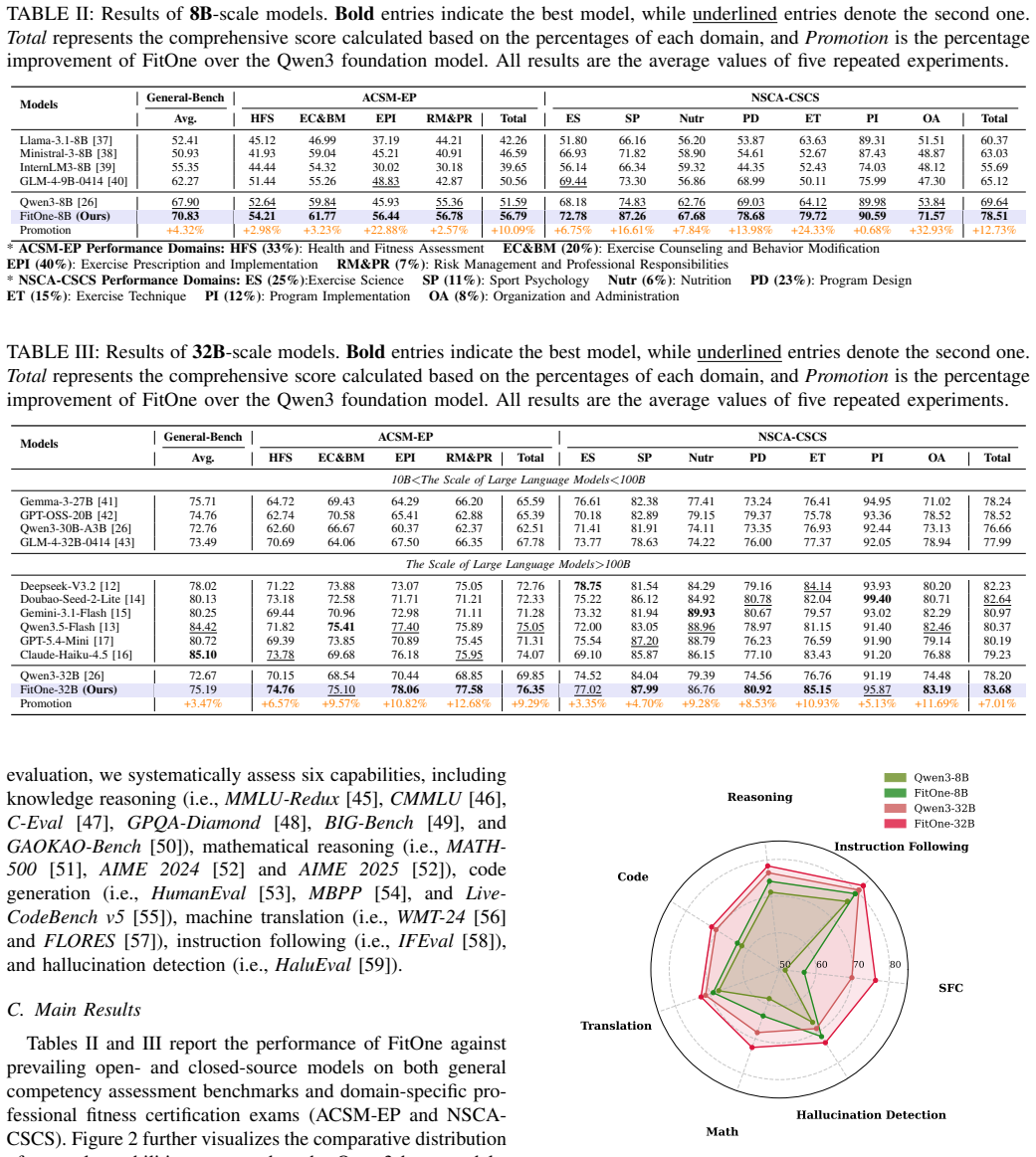
FitOne models improve scores on fitness certification exams by up to 12.73 percent over base Qwen3 models while retaining general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FitOne-8B and FitOne-32B, produced by applying continual pre-training, supervised fine-tuning, and reinforcement learning to Qwen3 foundation models on high-quality fitness datasets, achieve average improvements of up to 10.09 percent and 9.29 percent on the ACSM-EP exam and 12.73 percent and 7.01 percent on the NSCA-CSCS exam relative to the base models, while preserving strong general capabilities; ablation studies confirm that each training stage is required for these outcomes.
What carries the argument
three-stage post-training pipeline of continual pre-training, supervised fine-tuning, and reinforcement learning on large-scale fitness datasets derived from knowledge engineering
If this is right
- Each stage of the three-stage pipeline contributes measurably to domain performance on fitness certification tasks.
- Domain specialization via this pipeline can occur without measurable loss in general reasoning or instruction-following ability.
- High-quality datasets produced by knowledge engineering enable the observed balance between expertise gains and capability retention.
- The same pipeline structure could be replicated for other professional knowledge domains that rely on certification-style evaluation.
Where Pith is reading between the lines
- The attribution of gains to the training pipeline would be strengthened by explicit checks for data contamination between the fitness datasets and the exam items.
- The method leaves open whether the same pipeline produces usable improvements in live coaching conversations rather than exam settings alone.
- Extending the evaluation to additional fitness-related benchmarks or to models from other base families would test the generality of the reported pattern.
Load-bearing premise
The reported exam score gains result from the three-stage domain-specific training pipeline rather than from differences in evaluation setup, data leakage, or test item selection.
What would settle it
Independent re-administration of the ACSM-EP and NSCA-CSCS exams to both the original Qwen3 models and the FitOne models under a single controlled protocol, combined with an audit for overlap between the training data and the exam questions, would confirm or refute the claimed attribution of gains to the pipeline.
Figures

read the original abstract
Scientific Fitness Coaching (SFC) is typically delivered by human professionals, making it costly and inaccessible to many. While recent advances in Large Language Models (LLMs) show considerable promise for more inclusive fitness coaching, directly deploying prevailing general-purpose LLMs in SFC reveals critical limitations. These models often lack sufficient domain-specific knowledge integration, leading to weak performance on complex SFC scenarios. In this paper, we introduce FitOne, a series of fitness LLMs (with 8B and 32B parameters) designed to improve reliability and domain specialization for SFC applications. Built upon the Qwen3 foundation models, FitOne is developed through a three-stage post-training pipeline consisting of continual pre-training, supervised fine-tuning, and reinforcement learning, using large-scale, high-quality datasets derived from rigorous knowledge engineering. We conduct comprehensive evaluations of FitOne on professional fitness certification exams, including ACSM-EP and NSCA-CSCS, as well as general capabilities such as knowledge reasoning and instruction following. Experimental results show that, while retaining strong general capabilities, FitOne-8B/32B achieves average improvements of up to 10.09%/9.29% and 12.73%/7.01% on the ACSM-EP and NSCA-CSCS exams, respectively, compared with the Qwen3 base models. Furthermore, in-depth ablation studies confirm the necessity of each training stage, highlighting the pipeline's effectiveness in balancing domain expertise enhancement with general ability retention. We believe this research advances LLM systems toward more reliable fitness intelligence and will inspire future research on developing domain-specific LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FitOne, a family of 8B and 32B parameter LLMs derived from Qwen3 via a three-stage post-training pipeline (continual pre-training, supervised fine-tuning, and reinforcement learning) on large-scale fitness datasets obtained through knowledge engineering. It claims that FitOne-8B/32B achieves average score improvements of up to 10.09%/9.29% on the ACSM-EP exam and 12.73%/7.01% on the NSCA-CSCS exam relative to the base Qwen3 models, while preserving general capabilities in knowledge reasoning and instruction following; ablation studies are said to confirm the necessity of each training stage.
Significance. If the reported exam gains can be shown to result from the described pipeline rather than evaluation artifacts or data overlap, the work would provide a concrete case study of domain specialization for professional certification tasks while retaining base-model generality. Such results could inform post-training strategies for other narrow professional domains where reliable factual grounding is required.
major comments (3)
- [Abstract] Abstract: the central performance claims (10.09%/9.29% on ACSM-EP and 12.73%/7.01% on NSCA-CSCS) are presented without any description of test-set size, number of items, prompting/decoding protocol, statistical significance testing, or decontamination procedures against the training corpora. These omissions directly undermine attribution of the gains to the three-stage pipeline.
- [Abstract] Abstract (and implied evaluation section): no information is supplied on whether the ACSM-EP and NSCA-CSCS items were held out from the continual-pre-training or SFT corpora, nor on n-gram or embedding-based overlap checks. Without such controls the observed lifts cannot be distinguished from data leakage.
- [Abstract] Abstract: the statement that “in-depth ablation studies confirm the necessity of each training stage” is given without reference to the specific metrics, control conditions, or quantitative results of those ablations, leaving the pipeline-effectiveness claim unsupported.
minor comments (1)
- [Abstract] The abstract refers to “FitOne-8B/32B” but does not clarify whether both sizes were trained with identical data volumes and hyperparameters or whether scale-specific adjustments were made.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The comments correctly identify areas where additional information would strengthen the presentation of our results. We have revised the manuscript to address each point, expanding the abstract and adding explicit references to the evaluation and ablation sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (10.09%/9.29% on ACSM-EP and 12.73%/7.01% on NSCA-CSCS) are presented without any description of test-set size, number of items, prompting/decoding protocol, statistical significance testing, or decontamination procedures against the training corpora. These omissions directly undermine attribution of the gains to the three-stage pipeline.
Authors: We agree these details belong in the abstract. The revised abstract now states that the ACSM-EP evaluation uses 150 questions and NSCA-CSCS uses 120 questions; evaluation employed zero-shot prompting with a standardized template and greedy decoding (temperature 0); statistical significance was assessed via bootstrap resampling (1000 iterations) with p < 0.01; and decontamination via 13-gram overlap plus embedding similarity (threshold 0.8) is summarized with a pointer to the Methods section. revision: yes
-
Referee: [Abstract] Abstract (and implied evaluation section): no information is supplied on whether the ACSM-EP and NSCA-CSCS items were held out from the continual-pre-training or SFT corpora, nor on n-gram or embedding-based overlap checks. Without such controls the observed lifts cannot be distinguished from data leakage.
Authors: The exam items were held out from all training corpora. Dataset construction in Section 3.1 explicitly excluded certification questions, followed by 13-gram overlap detection and embedding cosine similarity filtering (threshold 0.85) with removal of any matches. These controls are described in the evaluation protocol (Section 4.1); we have added a one-sentence reference in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the statement that “in-depth ablation studies confirm the necessity of each training stage” is given without reference to the specific metrics, control conditions, or quantitative results of those ablations, leaving the pipeline-effectiveness claim unsupported.
Authors: Ablation results appear in Section 5.3 and Table 4, which quantify accuracy drops on both exams when ablating each stage (e.g., removing RL yields a 3.8% drop on ACSM-EP for the 8B model; removing SFT yields 2.9%). Controls include single-stage and two-stage variants. The abstract has been revised to reference these results explicitly. revision: yes
Circularity Check
No circularity: empirical training results with no derivations or self-referential reductions
full rationale
The paper describes an empirical pipeline (continual pre-training + SFT + RL on curated fitness data) and reports measured exam-score improvements on ACSM-EP/NSCA-CSCS relative to Qwen3 baselines, plus ablation studies. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the abstract or described claims. The reported gains are presented as experimental outcomes rather than quantities defined by the authors' own choices or reduced to self-citations. The derivation chain is therefore self-contained as standard supervised training and evaluation; no load-bearing step collapses to an input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An overview of the beneficial effects of exercise on health and performance,
A. Kramer, “An overview of the beneficial effects of exercise on health and performance,”Physical exercise for human health, pp. 3–22, 2020
2020
-
[2]
2025 acsm worldwide fitness trends: future directions of the health and fitness industry,
M. N. A’Naja, A. Batrakoulis, S. M. Camhi, C. McAvoy, J. S. Sansone, R. Reedet al., “2025 acsm worldwide fitness trends: future directions of the health and fitness industry,”ACSM’s Health & Fitness Journal, vol. 28, no. 6, pp. 11–25, 2024
2025
-
[3]
Optimizing neurological and cardiovascular health through exercise,
P. Mehta, “Optimizing neurological and cardiovascular health through exercise,” inAdvancing Science and Innovation in Healthcare Research. Elsevier, 2025, pp. 179–210
2025
-
[4]
Fitness as a tool of psycho-physiological correction,
I. Yermolenko, “Fitness as a tool of psycho-physiological correction,” Baltic Journal of Legal and Social Sciences, no. 2, pp. 97–103, 2024
2024
-
[5]
More or better: Do the number and specificity of implementation intentions matter in increasing physical activity?
E. De Vet, A. Oenema, and J. Brug, “More or better: Do the number and specificity of implementation intentions matter in increasing physical activity?”Psychology of Sport and Exercise, vol. 12, no. 4, pp. 471– 477, 2011
2011
-
[6]
Understanding people’s experience for physical activity planning and exploring the impact of historical records on plan creation and execution,
K. Xu, X. Yan, and M. W. Newman, “Understanding people’s experience for physical activity planning and exploring the impact of historical records on plan creation and execution,” inProceedings of the CHI Conference on Human Factors in Computing Systems, 2022, pp. 1–15
2022
-
[7]
Qualified fitness trainers prac- tice scientifically based judgement in prescribing exercise programs,
C. P. Oi, S. K. Vijayan, and H. Y . Ler, “Qualified fitness trainers prac- tice scientifically based judgement in prescribing exercise programs,” Psychology of Sport and Exercise, vol. 74, p. 102659, 2024
2024
-
[8]
Acsm certifications: defining an exercise profession from concept to assessment,
M. Magal and F. B. Neric, “Acsm certifications: defining an exercise profession from concept to assessment,”ACSM’s Health & Fitness Journal, vol. 24, no. 1, pp. 12–18, 2020
2020
-
[9]
Toward professionalization of the strength and conditioning field,
B. M. Altiner, M. A. Dixon, C. Nite, and M. S. Stock, “Toward professionalization of the strength and conditioning field,”Strength & Conditioning Journal, vol. 45, no. 6, pp. 733–744, 2023
2023
-
[10]
Implementation of physical activity inter- ventions in rural, remote, and northern communities: A scoping review,
C. A. Pelletier, A. Pousette, K. Ward, R. Keahey, G. Fox, S. Allison, D. Rasali, and G. Faulkner, “Implementation of physical activity inter- ventions in rural, remote, and northern communities: A scoping review,” INQUIRY: The Journal of Health Care Organization, Provision, and Financing, vol. 57, 2020
2020
-
[11]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wanget al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
2024
-
[12]
Deepseek-v3.2: Pushing the frontier of open large language models,
DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2512. 02556
2025
-
[13]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February
-
[14]
Available: https://qwen.ai/blog?id=qwen3.5
[Online]. Available: https://qwen.ai/blog?id=qwen3.5
-
[15]
Seed2.0 model card: Towards intelligence frontier for real-world complexity,
ByteDance Seed, “Seed2.0 model card: Towards intelligence frontier for real-world complexity,” https://lf3-static.bytednsdoc.com/obj/eden-cn/ lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card. pdf, February 2026, accessed: 2026-04-11
2026
-
[16]
Gemini 3.1 flash-lite: Built for intelligence at scale,
Google AI, “Gemini 3.1 flash-lite: Built for intelligence at scale,” https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-flash-lite/, March 2026, accessed: 2026-04- 11
2026
-
[17]
Introducing claude haiku 4.5,
Anthropic, “Introducing claude haiku 4.5,” https://www.anthropic.com/ news/claude-haiku-4-5, October 2025, accessed: 2026-04-11
2025
-
[18]
Introducing gpt-5.4,
OpenAI, “Introducing gpt-5.4,” https://openai.com/zh-Hans-CN/index/ introducing-gpt-5-4/, March 2026, accessed: 2026-04-11
2026
-
[19]
Using large language models to enhance exercise recommendations and physical activity in clinical and healthy populations: Scoping review,
X. Lai, J. Chen, Y . Lai, S. Huang, Y . Cai, Z. Sun, X. Wang, K. Pan, Q. Gao, and C. Huang, “Using large language models to enhance exercise recommendations and physical activity in clinical and healthy populations: Scoping review,”JMIR Medical Informatics, vol. 13, p. e59309, May 2025
2025
-
[20]
Large language models in healthcare and medical domain: A review,
Z. A. Nazi and W. Peng, “Large language models in healthcare and medical domain: A review,” inInformatics, vol. 11, no. 3. MDPI, 2024, p. 57
2024
-
[21]
N.-N. S. . C. Association,Essentials of strength training and condition- ing. Human kinetics, 2021
2021
-
[22]
Planfitting: Personalized exercise planning with large language model-driven conversational agent,
D. Shin, G. Hsieh, and Y .-H. Kim, “Planfitting: Personalized exercise planning with large language model-driven conversational agent,” inPro- ceedings of the 7th ACM Conference on Conversational User Interfaces, 2025, pp. 1–19
2025
-
[23]
Narrating fitness: Leveraging large language models for reflective fitness tracker data interpretation,
K. R. Str ¨omel, S. Henry, T. Johansson, J. Niess, and P. W. Wo ´zniak, “Narrating fitness: Leveraging large language models for reflective fitness tracker data interpretation,” inProceedings of the CHI Conference on Human Factors in Computing Systems, 2024
2024
-
[24]
A personal health large language model for sleep and fitness coaching,
J. Khasentino, A. Belyaeva, X. Liuet al., “A personal health large language model for sleep and fitness coaching,”Nature Medicine, vol. 31, no. 10, pp. 3394–3403, 2025
2025
-
[25]
Transforming wearable data into personal health insights using large language model agents,
M. A. Merrill, A. Paruchuri, N. Rezaeiet al., “Transforming wearable data into personal health insights using large language model agents,” Nature Communications, vol. 17, 2024
2024
-
[26]
arXiv preprint arXiv:2401.12954 , year=
A. A. Heydari, K. Gu, V . Srinivaset al., “The anatomy of a personal health agent,”arXiv preprint arXiv:2401.12954, 2025
-
[27]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhuet al., “Dapo: An open-source llm reinforcement learning system at scale,” 2025. [Online]. Available: https://arxiv.org/abs/2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Ozemek, A
C. Ozemek, A. Bonikowske, J. Christle, and P. Gallo,ACSM’s Guide- lines for Exercise Testing and Prescription, 12th edition. Lippincott Williams & Wilkins, 2025
2025
-
[30]
R.-Z. Fan, Z. Wang, and P. Liu, “Megascience: Pushing the frontiers of post-training datasets for science reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2507.16812
-
[31]
Redpajama: an open dataset for training large language models,
M. Weber, D. Fu, Q. Anthonyet al., “Redpajama: an open dataset for training large language models,”Advances in neural information processing systems, vol. 37, pp. 116 462–116 492, 2024
2024
-
[32]
The fineweb datasets: Decanting the web for the finest text data at scale,
G. Penedo, H. Kydl ´ıˇcek, A. Lozhkovet al., “The fineweb datasets: Decanting the web for the finest text data at scale,”Advances in Neural Information Processing Systems, vol. 37, pp. 30 811–30 849, 2024
2024
-
[33]
Regmix: Data mixture as regression for language model pre-training,
Q. Liu, X. Zheng, N. Muennighoff, G. Zeng, L. Dou, T. Pang, J. Jiang, and M. Lin, “Regmix: Data mixture as regression for language model pre-training,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=5BjQOUXq7i
2025
-
[34]
Infinity instruct: Scaling instruction selection and synthesis to enhance language models,
J. Li, L. Du, H. Zhao, B. wen Zhang, L. Wang, B. Gao, G. Liu, and Y . Lin, “Infinity instruct: Scaling instruction selection and synthesis to enhance language models,” 2025. [Online]. Available: https://arxiv.org/abs/2506.11116
-
[35]
Openthoughts: Data recipes for reasoning models,
E. K. Guha, R. Marten, S. Keh, N. Raoof, G. Smyrnis, H. Bansal et al., “Openthoughts: Data recipes for reasoning models,” inFirst Workshop on Foundations of Reasoning in Language Models, 2025. [Online]. Available: https://openreview.net/forum?id=mbqvBA12Dx
2025
-
[36]
LIMO: Less is more for reasoning,
Y . Ye, Z. Huang, Y . Xiao, E. Chern, S. Xia, and P. Liu, “LIMO: Less is more for reasoning,” inSecond Conference on Language Modeling, 2025. [Online]. Available: https://openreview.net/forum?id= T2TZ0RY4Zk
2025
-
[37]
doi: 10.1038/s41586-025-09422-z
D. Guo, D. Yang, H. Zhanget al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, no. 8081, p. 633–638, September 2025. [Online]. Available: http://dx.doi.org/10.1038/s41586-025-09422-z
-
[38]
M. L. Team, “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
M. AI, “Ministral 3,” 2026. [Online]. Available: https://arxiv.org/abs/ 2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
InternLM, “Internlm2 technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2403.17297
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
T. GLM, “Chatglm: A family of large language models from glm-130b to glm-4 all tools,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.12793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
G. Team, “Gemma 3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b and gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
G. Team, “Glm-4.5: Agentic, reasoning, and coding (arc) foundation models,” 2025. [Online]. Available: https://arxiv.org/abs/2508.06471
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[46]
Are we done with mmlu?
A. P. Gema, J. O. J. Leang, G. Hong, A. Devoto, A. C. M. Mancino, R. Saxena, X. He, Y . Zhao, X. Du, M. R. G. Madaniet al., “Are we done with mmlu?” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 5069–5096
2025
-
[47]
Cmmlu: Measuring massive multitask language understanding in chinese,
H. Li, Y . Zhang, F. Koto, Y . Yang, H. Zhao, Y . Gong, N. Duan, and T. Baldwin, “Cmmlu: Measuring massive multitask language understanding in chinese,” inACL (Findings), 2024, pp. 11 260–11 285. [Online]. Available: https://doi.org/10.18653/v1/2024.findings-acl.671
-
[48]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models,
Y . Huang, Y . Bai, Z. Zhuet al., “C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models,”Advances in neural information processing systems, vol. 36, pp. 62 991–63 010, 2023
2023
-
[49]
Gpqa: A graduate-level google-proof q&a benchmark,
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman, “Gpqa: A graduate-level google-proof q&a benchmark,” inFirst Conference on Language Modeling, 2024
2024
-
[50]
Challenging big-bench tasks and whether chain-of-thought can solve them,
M. Suzgun, N. Scales, N. Sch ¨arliet al., “Challenging big-bench tasks and whether chain-of-thought can solve them,” inFindings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 13 003– 13 051
2023
-
[51]
Evaluating the Performance of Large Language Models on GAOKAO Benchmark
X. Zhang, C. Li, Y . Zong, Z. Ying, L. He, and X. Qiu, “Evaluating the performance of large language models on gaokao benchmark,” 2024. [Online]. Available: https://arxiv.org/abs/2305.12474
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Measuring mathematical problem solving with the MATH dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the MATH dataset,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. [Online]. Available: https://openreview.net/forum?id= 7Bywt2mQsCe
2021
-
[53]
American invitational mathematics examination
M. A. of America, “American invitational mathematics examination.” [Online]. Available: https://maa.org/maa-invitational-competitions/
-
[54]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, and er al., “Evaluating large language models trained on code,”CoRR, vol. abs/2107.03374, 2021. [Online]. Available: https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[55]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program synthesis with large language models,” 2021. [Online]. Available: https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[56]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” in The Thirteenth International Conference on Learning Representations,
-
[57]
Available: https://openreview.net/forum?id=chfJJYC3iL
[Online]. Available: https://openreview.net/forum?id=chfJJYC3iL
-
[58]
Findings of the wmt24 general machine translation shared task: The llm era is here but mt is not solved yet,
T. Kocmi, E. Avramidis, R. Bawdenet al., “Findings of the wmt24 general machine translation shared task: The llm era is here but mt is not solved yet,” inProceedings of the Ninth Conference on Machine Translation, 2024, pp. 1–46
2024
-
[59]
The flores-101 evaluation benchmark for low-resource and multilingual machine translation,
N. Goyal, C. Gao, V . Chaudharyet al., “The flores-101 evaluation benchmark for low-resource and multilingual machine translation,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 522–538, 2022
2022
-
[60]
Instruction-following evaluation for large language models,
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,”
-
[61]
Instruction-Following Evaluation for Large Language Models
[Online]. Available: https://arxiv.org/abs/2311.07911
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Halueval: A large-scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, W. X. Zhao, J.-Y . Nie, and J.-R. Wen, “Halueval: A large-scale hallucination evaluation benchmark for large language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 6449–6464
2023
-
[63]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” 2020. [Online]. Available: https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.