SelectTSL: Prompt-Guided Selective Target Sound Localization in Complex Scenarios
Pith reviewed 2026-07-03 05:38 UTC · model grok-4.3
The pith
SelectTSL localizes only a user-specified target sound among multiple sources using prompt guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
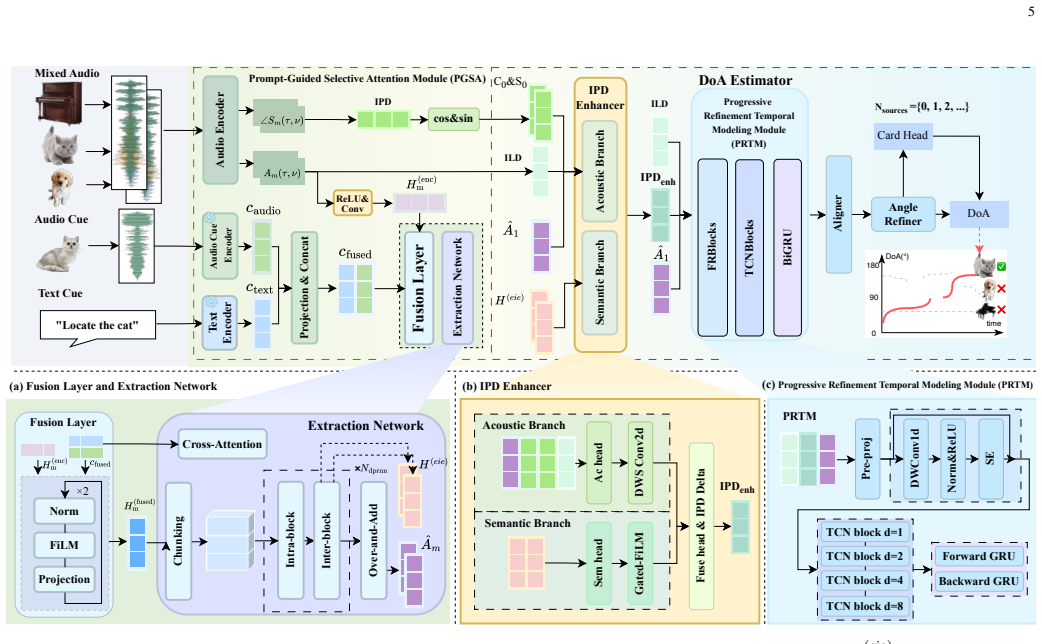
SelectTSL is an end-to-end architecture that localizes only the user-specified target in multi-source acoustic scenes. It employs a Prompt-Guided Selective Attention Module to generate prompt-informed embeddings. These embeddings guide an inter-channel phase difference enhancer to refine raw phase cues, which are then fused with target magnitudes to jointly estimate direction of arrival and target-source cardinality.
What carries the argument
Prompt-Guided Selective Attention Module (PGSA) that produces prompt-informed embeddings to steer the IPD enhancer toward target spatial cues while preserving multichannel information.
If this is right
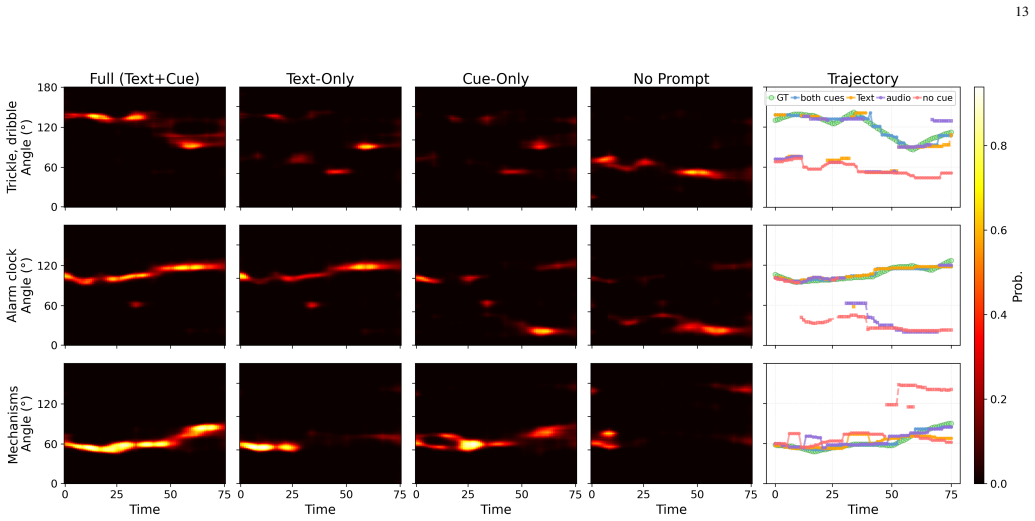
- Localization occurs selectively for the prompted target and ignores other sources.
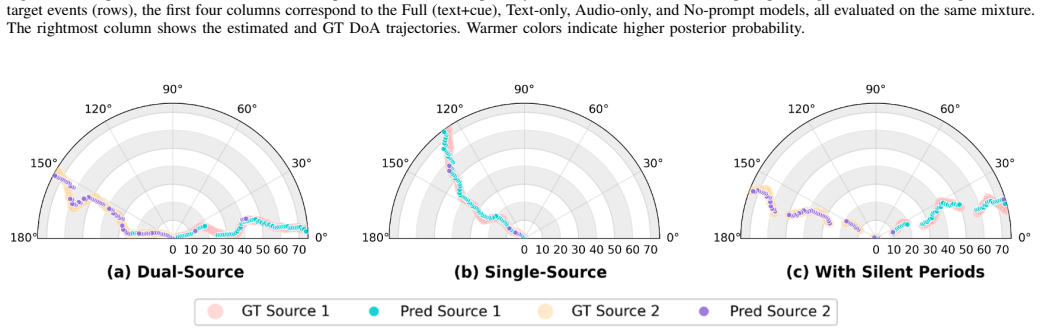
- Direction of arrival and target-source count are estimated together in one model.
- The system outperforms baselines on both synthetic data and real-world recordings.
- Robust performance holds across real acoustic environments.
Where Pith is reading between the lines
- The same prompt mechanism could be paired with source separation models to both locate and extract the designated sound.
- Voice or text prompts might allow consumer devices to focus audio processing on one chosen source in a room.
- The joint estimation of count and direction opens a route to tracking moving targets whose number changes.
Load-bearing premise
The prompt-guided module can create embeddings that reliably direct the phase enhancer to the correct spatial cues without discarding multichannel details.
What would settle it
Experiments on real recordings where the method fails to outperform baselines on direction estimation accuracy or loses performance when the number of target sources varies would falsify the central claim.
Figures

read the original abstract
Humans can selectively attend to a target sound and estimate its direction in complex scenarios, whereas such selective localization remains challenging for current deep learning-based systems. Sound source localization (SSL) has achieved remarkable success with deep learning, yet most methods localize all active sources without selectivity. Conversely, target sound extraction (TSE) extracts sources using multimodal prompts but typically fails to preserve the multichannel spatial information required for accurate localization. To bridge this gap, we formulate the task of prompt-guided selective target sound localization and propose SelectTSL, an end-to-end architecture that localizes only the user-specified target in multi-source acoustic scenes. Specifically, we design a target-aware selective localization strategy that employs a Prompt-Guided Selective Attention Module (PGSA) to generate prompt-informed embeddings. These embeddings guide an inter-channel phase difference (IPD) enhancer to refine raw phase cues, fusing with target magnitudes to jointly estimate direction of arrival (DoA) and target-source cardinality, i.e., the number of target sound sources. This coupled design effectively focuses on the user-specified target spatial cues for selective localization and also handles time-varying numbers of target sources. Extensive experiments on both synthetic data and real-world recordings demonstrate that our proposed method consistently outperforms other baselines and exhibits robust generalization to real acoustic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SelectTSL, an end-to-end architecture for prompt-guided selective target sound localization in multi-source scenes. It introduces a Prompt-Guided Selective Attention Module (PGSA) to produce prompt-informed embeddings that guide an inter-channel phase difference (IPD) enhancer; the refined phase cues are fused with target magnitudes to jointly estimate direction of arrival (DoA) and target-source cardinality. Experiments on synthetic data and real-world recordings are reported to show consistent outperformance over baselines together with robust generalization to real acoustic environments.
Significance. If the experimental support holds, the work usefully bridges target sound extraction and sound source localization by adding prompt-based selectivity while preserving the spatial cues needed for DoA. The joint estimation of DoA and time-varying source cardinality is a constructive design choice. No machine-checked proofs or open reproducible code are mentioned.
major comments (1)
- [Abstract] Abstract (architecture paragraph): the claim that PGSA embeddings 'guide' the IPD enhancer and are 'fused with target magnitudes' to refine raw phase cues lacks an explicit mechanism (additive residual, channel-wise gating, or complex-valued attention). Without this, it is impossible to verify that inter-channel phase differences survive the operation, which is load-bearing for both the selectivity claim and the reported DoA accuracy on real recordings.
minor comments (1)
- The abstract states outperformance on synthetic and real data but supplies no quantitative metrics, error bars, baseline descriptions, or ablation results; these must appear with full experimental detail in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and agree that greater clarity is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract (architecture paragraph): the claim that PGSA embeddings 'guide' the IPD enhancer and are 'fused with target magnitudes' to refine raw phase cues lacks an explicit mechanism (additive residual, channel-wise gating, or complex-valued attention). Without this, it is impossible to verify that inter-channel phase differences survive the operation, which is load-bearing for both the selectivity claim and the reported DoA accuracy on real recordings.
Authors: We agree that the abstract, as written, provides only a high-level description and does not specify the precise mechanism (e.g., additive residual, channel-wise gating, or complex-valued attention) by which PGSA embeddings guide the IPD enhancer or how fusion with target magnitudes occurs. This omission makes it difficult to confirm preservation of inter-channel phase differences from the abstract alone. In the revised manuscript we will update the abstract paragraph to include a concise statement of the actual mechanism used in the architecture while preserving its summary character; the detailed implementation remains in Section 3. revision: yes
Circularity Check
No circularity: end-to-end learned architecture with external evaluation
full rationale
The paper presents SelectTSL as an end-to-end neural architecture whose central claims rest on experimental outperformance on synthetic and real recordings. No equations, predictions, or uniqueness theorems are shown that reduce by construction to fitted inputs or self-citations; the PGSA and IPD enhancer are described as learned components whose behavior is validated externally rather than defined tautologically. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benesty, J
J. Benesty, J. Chen, and Y . Huang,Microphone array signal processing. Springer, 2008. 14
2008
-
[2]
H ¨eb-Umbach, T
R. H ¨eb-Umbach, T. Nakatani, M. Delcroix, C. Boeddeker, and T. Ochiai, “Microphone array signal processing and deep learning for speech enhancement: Combining model-based and data-driven approaches to parameter estimation and filtering [special issue on model-based and data-driven audio signal processing],”IEEE Signal Processing Maga- zine, vol. 41, no. ...
2025
-
[3]
The generalized correlation method for estimation of time delay,
C. Knapp and G. Carter, “The generalized correlation method for estimation of time delay,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 24, no. 4, pp. 320–327, 2003
2003
-
[4]
Multiple emitter location and signal parameter estimation,
R. Schmidt, “Multiple emitter location and signal parameter estimation,” IEEE transactions on antennas and propagation, vol. 34, no. 3, pp. 276– 280, 1986
1986
-
[5]
Multi-speaker doa estimation using deep convolutional networks trained with noise signals,
S. Chakrabarty and E. A. Habets, “Multi-speaker doa estimation using deep convolutional networks trained with noise signals,”IEEE J. Sel. Topics Signal Process., vol. 13, no. 1, pp. 8–21, 2019
2019
-
[6]
Some experiments on the recognition of speech, with one and with two ears,
E. C. Cherry, “Some experiments on the recognition of speech, with one and with two ears,”J. Acoust. Soc. Am., vol. 25, no. 5, pp. 975–979, 1953
1953
-
[7]
Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,
S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,”IEEE J. Sel. Topics Signal Process., vol. 13, no. 1, pp. 34–48, 2018
2018
-
[8]
Overview and evaluation of sound event localization and detection in dcase 2019,
A. Politis, A. Mesaros, S. Adavanne, T. Heittola, and T. Virtanen, “Overview and evaluation of sound event localization and detection in dcase 2019,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 29, pp. 684–698, 2020
2019
-
[9]
Toward interactive sound source localization: Better align sight and sound!
A. Senocak, H. Ryu, J. Kim, T.-H. Oh, H. Pfister, and J. S. Chung, “Toward interactive sound source localization: Better align sight and sound!”IEEE Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[10]
V oiceFilter: Targeted voice separation by speaker-conditioned spectrogram masking,
Q. Wang, H. Muckenhirn, K. Wilson, P. Sridhar, Z. Wu, J. R. Hershey, R. A. Saurous, R. J. Weiss, Y . Jia, and I. L. Moreno, “V oiceFilter: Targeted voice separation by speaker-conditioned spectrogram masking,” INTERSPEECH, pp. 2728–2732, 2019
2019
-
[11]
Separate what you describe: Language-queried audio source separation,
X. Liu, H. Liu, Q. Kong, X. Mei, J. Zhao, Q. Huang, M. D. Plumbley, and W. Wang, “Separate what you describe: Language-queried audio source separation,” inINTERSPEECH, 2022, pp. 1801–1805
2022
-
[12]
Leveraging audio-only data for text-queried target sound extraction,
K. Saijo, J. Ebbers, F. G. Germain, S. Khurana, G. Wiehern, and J. Le Roux, “Leveraging audio-only data for text-queried target sound extraction,” inICASSP. IEEE, 2025, pp. 1–5
2025
-
[13]
Contextual speech extraction: Leveraging textual history as an implicit cue for target speech extraction,
M. Kim, R. Mira, H. Chen, S. Petridis, and M. Pantic, “Contextual speech extraction: Leveraging textual history as an implicit cue for target speech extraction,” inICASSP. IEEE, 2025, pp. 1–5
2025
-
[14]
Deep audio-visual speech recognition,
T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, “Deep audio-visual speech recognition,”IEEE Trans. Pattern Anal. Mach. Intell., 2018
2018
-
[15]
An audio-visual speech separation model inspired by cortico-thalamo-cortical circuits,
K. Li, F. Xie, H. Chen, K. Yuan, and X. Hu, “An audio-visual speech separation model inspired by cortico-thalamo-cortical circuits,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 10, pp. 6637–6651, 2024
2024
-
[16]
Usev: Universal speaker extraction with visual cue,
Z. Pan, M. Ge, and H. Li, “Usev: Universal speaker extraction with visual cue,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 30, pp. 3032–3045, 2022
2022
-
[17]
Audio-visual target speaker extraction with reverse selective auditory attention,
R. Tao, X. Qian, Y . Jiang, J. Li, J. Wang, and H. Li, “Audio-visual target speaker extraction with reverse selective auditory attention,”IEEE Trans. on Audio, Speech, and Language Processing, 2025
2025
-
[18]
Neural spatial filter: Target speaker speech separation assisted with directional information
R. Gu, L. Chen, S.-X. Zhang, J. Zheng, Y . Xu, M. Yu, D. Su, Y . Zou, and D. Yu, “Neural spatial filter: Target speaker speech separation assisted with directional information.” inINTERSPEECH, 2019, pp. 4290–4294
2019
-
[19]
Towards unified all-neural beamforming for time and frequency domain speech separation,
R. Gu, S.-X. Zhang, Y . Zou, and D. Yu, “Towards unified all-neural beamforming for time and frequency domain speech separation,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 31, pp. 849– 862, 2022
2022
-
[20]
Speakerbeam: Speaker aware neural network for target speaker extraction in speech mixtures,
K. ˇZmol´ıkov´a, M. Delcroix, K. Kinoshita, T. Ochiai, T. Nakatani, L. Bur- get, and J. ˇCernock`y, “Speakerbeam: Speaker aware neural network for target speaker extraction in speech mixtures,”IEEE J. Sel. Topics Signal Process., vol. 13, no. 4, pp. 800–814, 2019
2019
-
[21]
Spex: Multi-scale time domain speaker extraction network,
C. Xu, W. Rao, E. S. Chng, and H. Li, “Spex: Multi-scale time domain speaker extraction network,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 28, pp. 1370–1384, 2020
2020
-
[22]
X-sepformer: End-to-end speaker extraction network with explicit optimization on speaker confusion,
K. Liu, Z. Du, X. Wan, and H. Zhou, “X-sepformer: End-to-end speaker extraction network with explicit optimization on speaker confusion,” in ICASSP. IEEE, 2023, pp. 1–5
2023
-
[23]
Clipsep: Learning text-queried sound separation with noisy unlabeled videos,
H.-W. Dong, N. Takahashi, Y . Mitsufuji, J. McAuley, and T. Berg- Kirkpatrick, “Clipsep: Learning text-queried sound separation with noisy unlabeled videos,”arXiv preprint arXiv:2212.07065, 2022
-
[24]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP. IEEE, 2023, pp. 1–5
2023
-
[25]
Clapsep: Lever- aging contrastive pre-trained model for multi-modal query-conditioned target sound extraction,
H. Ma, Z. Peng, X. Li, M. Shao, X. Wu, and J. Liu, “Clapsep: Lever- aging contrastive pre-trained model for multi-modal query-conditioned target sound extraction,”IEEE Trans. on Audio, Speech, and Language Processing, 2024
2024
-
[26]
Separate anything you describe,
X. Liu, Q. Kong, Y . Zhao, H. Liu, Y . Yuan, Y . Liu, R. Xia, Y . Wang, M. D. Plumbley, and W. Wang, “Separate anything you describe,”IEEE Trans. on Audio, Speech, and Language Processing, 2024
2024
-
[27]
Zero-shot audio source separation through query-based learning from weakly-labeled data,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “Zero-shot audio source separation through query-based learning from weakly-labeled data,” inAAAI, vol. 36, no. 4, 2022, pp. 4441–4449
2022
-
[28]
Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019
2019
-
[29]
Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,
Y . Luo, Z. Chen, and T. Yoshioka, “Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation,” inICASSP. IEEE, 2020, pp. 46–50
2020
-
[30]
Tf-gridnet: Integrating full-and sub-band modeling for speech separa- tion,
Z.-Q. Wang, S. Cornell, S. Choi, Y . Lee, B.-Y . Kim, and S. Watanabe, “Tf-gridnet: Integrating full-and sub-band modeling for speech separa- tion,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 31, pp. 3221–3236, 2023
2023
-
[31]
A survey of sound source localization with deep learning methods,
P.-A. Grumiaux, S. Kiti ´c, L. Girin, and A. Gu ´erin, “A survey of sound source localization with deep learning methods,”J. Acoust. Soc. Am., vol. 152, no. 1, pp. 107–151, 2022
2022
-
[32]
Learning to localize sound sources in visual scenes: Analysis and applications,
A. Senocak, T.-H. Oh, J. Kim, M.-H. Yang, and I. S. Kweon, “Learning to localize sound sources in visual scenes: Analysis and applications,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 5, pp. 1605–1619, 2019
2019
-
[33]
Robust audio-visual contrastive learning for proposal-based self-supervised sound source localization in videos,
H. Xuan, Z. Wu, J. Yang, B. Jiang, L. Luo, X. Alameda-Pineda, and Y . Yan, “Robust audio-visual contrastive learning for proposal-based self-supervised sound source localization in videos,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 7, pp. 4896–4907, 2024
2024
-
[34]
Enhancing sound source localization via false negative elimination,
Z. Song, J. Zhang, Y . Wang, J. Fan, and Z. Zhang, “Enhancing sound source localization via false negative elimination,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 10 499–10 514, 2024
2024
-
[35]
Salsa: Spatial cue-augmented log-spectrogram features for polyphonic sound event localization and detection,
T. N. T. Nguyen, K. N. Watcharasupat, N. K. Nguyen, D. L. Jones, and W.-S. Gan, “Salsa: Spatial cue-augmented log-spectrogram features for polyphonic sound event localization and detection,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 30, pp. 1749–1762, 2022
2022
-
[36]
Fn-ssl: Full-band and narrow-band fusion for sound source localization,
Y . Wang, B. Yang, and X. Li, “Fn-ssl: Full-band and narrow-band fusion for sound source localization,” inINTERSPEECH, 2023, pp. 3779–3783
2023
-
[37]
Ipdnet: A universal direct-path ipd estimation network for sound source localization,
——, “Ipdnet: A universal direct-path ipd estimation network for sound source localization,”IEEE Trans. on Audio, Speech, and Language Processing, 2024
2024
-
[38]
Salad- net: Self-attentive multisource localization in the ambisonics domain,
P.-A. Grumiaux, S. Kiti ´c, P. Srivastava, L. Girin, and A. Gu´erin, “Salad- net: Self-attentive multisource localization in the ambisonics domain,” inIEEE Workshop Appl. Signal Process. Audio Acoust.IEEE, 2021, pp. 336–340
2021
-
[39]
W. Huang, Q. Huang, L. Ma, and C. Wang, “Swg-former: A sliding- window graph convolutional network for simultaneous spatial-temporal information extraction in sound event localization and detection,”arXiv preprint arXiv:2310.14016, 2023
-
[40]
J. Hu, Y . Cao, M. Wu, Q. Kong, F. Yang, M. D. Plumbley, and J. Yang, “Sound event localization and detection for real spatial sound scenes: Event-independent network and data augmentation chains,” arXiv preprint arXiv:2209.01802, 2022
-
[41]
Cst-former: Transformer with channel-spectro- temporal attention for sound event localization and detection,
Y . Shul and J.-W. Choi, “Cst-former: Transformer with channel-spectro- temporal attention for sound event localization and detection,” in ICASSP. IEEE, 2024, pp. 8686–8690
2024
-
[42]
Salsa-lite: A fast and effective feature for polyphonic sound event localization and detection with microphone arrays,
T. N. T. Nguyen, D. L. Jones, K. N. Watcharasupat, H. Phan, and W.-S. Gan, “Salsa-lite: A fast and effective feature for polyphonic sound event localization and detection with microphone arrays,” inICASSP. IEEE, 2022, pp. 716–720
2022
-
[43]
The lu system for dcase 2024 sound event localization and detection challenge,
A. Berg, J. Engman, J. Gulin, K. Astr ¨om, M. Oskarsson, and B. Sony Eu- rope, “The lu system for dcase 2024 sound event localization and detection challenge,” DCASE2024 Challenge, Tech. Rep, Tech. Rep., 2024
2024
-
[44]
Learning multi-target tdoa features for sound event localization and detection,
A. Berg, J. Engman, J. Gulin, K. ˚Astr¨om, and M. Oskarsson, “Learning multi-target tdoa features for sound event localization and detection,” arXiv preprint arXiv:2408.17166, 2024
-
[45]
Srp-dnn: Learning direct-path phase difference for multiple moving sound source localization,
B. Yang, H. Liu, and X. Li, “Srp-dnn: Learning direct-path phase difference for multiple moving sound source localization,” inICASSP. IEEE, 2022, pp. 721–725
2022
-
[46]
H. Yin, M. Ge, Y . Fu, G. Zhang, L. Wang, L. Zhang, L. Qiu, and J. Dang, “Mimo-doanet: Multi-channel input and multiple outputs doa 15 network with unknown number of sound sources,”arXiv preprint arXiv:2207.07307, 2022
-
[47]
Accdoa: Activity-coupled cartesian direction of arrival representation for sound event localization and detection,
K. Shimada, Y . Koyama, N. Takahashi, S. Takahashi, and Y . Mitsufuji, “Accdoa: Activity-coupled cartesian direction of arrival representation for sound event localization and detection,” inICASSP. IEEE, 2021, pp. 915–919
2021
-
[48]
Multi-accdoa: Localizing and detecting overlapping sounds from the same class with auxiliary duplicating permutation invariant training,
K. Shimada, Y . Koyama, S. Takahashi, N. Takahashi, E. Tsunoo, and Y . Mitsufuji, “Multi-accdoa: Localizing and detecting overlapping sounds from the same class with auxiliary duplicating permutation invariant training,” inICASSP. IEEE, 2022, pp. 316–320
2022
-
[49]
Event-independent network for polyphonic sound event localization and detection,
Y . Cao, T. Iqbal, Q. Kong, Y . Zhong, W. Wang, and M. D. Plumbley, “Event-independent network for polyphonic sound event localization and detection,”arXiv preprint arXiv:2010.00140, 2020
-
[50]
An improved event-independent network for polyphonic sound event localization and detection,
Y . Cao, T. Iqbal, Q. Kong, F. An, W. Wang, and M. D. Plumbley, “An improved event-independent network for polyphonic sound event localization and detection,” inICASSP. IEEE, 2021, pp. 885–889
2021
-
[51]
D. Mu, Z. Zhang, and H. Yue, “Mff-einv2: Multi-scale feature fusion across spectral-spatial-temporal domains for sound event localization and detection,”arXiv preprint arXiv:2406.08771, 2024
-
[52]
Stereo sound event localization and detection with onscreen/offscreen classification,
K. Shimada, A. Politis, I. R. Roman, P. Sudarsanam, D. Diaz-Guerra, R. Pandey, K. Uchida, Y . Koyama, N. Takahashi, T. Shibuyaet al., “Stereo sound event localization and detection with onscreen/offscreen classification,”arXiv preprint arXiv:2507.12042, 2025
-
[53]
S. Adavanne, A. Politis, and T. Virtanen, “Localization, detection and tracking of multiple moving sound sources with a convolutional recurrent neural network,”arXiv preprint arXiv:1904.12769, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[54]
Differentiable tracking-based training of deep learning sound source localizers,
——, “Differentiable tracking-based training of deep learning sound source localizers,” inIEEE Workshop Appl. Signal Process. Audio Acoust.IEEE, 2021, pp. 211–215
2021
-
[55]
Keyword-based speaker localization: Localizing a target speaker in a multi-speaker environment,
S. Sivasankaran, E. Vincent, and D. Fohr, “Keyword-based speaker localization: Localizing a target speaker in a multi-speaker environment,” inINTERSPEECH, 2018
2018
-
[56]
Locate this, not that: Class-conditioned sound event doa estimation,
O. Slizovskaia, G. Wichern, Z.-Q. Wang, and J. Le Roux, “Locate this, not that: Class-conditioned sound event doa estimation,” inICASSP. IEEE, 2022, pp. 711–715
2022
-
[57]
Text-queried target sound event localization,
J. Zhao, X. Qian, Y . Xu, H. Liu, Y . Cao, D. Berghi, and W. Wang, “Text-queried target sound event localization,” inEUSIPCO. IEEE, 2024, pp. 261–265
2024
-
[58]
Locselect: Target speaker localization with an auditory selective hearing mechanism,
Y . Chen, X. Qian, Z. Pan, K. Chen, and H. Li, “Locselect: Target speaker localization with an auditory selective hearing mechanism,” inICASSP. IEEE, 2024, pp. 8696–8700
2024
-
[59]
Gcc-speaker: Target speaker localization with optimal speaker-dependent weighting in multi-speaker scenarios,
G. Li, W. Xue, W. Liu, J. Yi, and J. Tao, “Gcc-speaker: Target speaker localization with optimal speaker-dependent weighting in multi-speaker scenarios,” inICASSP. IEEE, 2023, pp. 1–5
2023
-
[60]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” inICASSP. IEEE, 2015, pp. 5206–5210
2015
-
[61]
A holistic evaluation of piano sound quality,
M. Zhou, S. Wu, S. Ji, Z. Li, and W. Li, “A holistic evaluation of piano sound quality,” inNational Conf. on Sound and Music Technology. Springer, 2023, pp. 3–17
2023
-
[62]
Guitarset: A dataset for guitar transcription
Q. Xi, R. M. Bittner, J. Pauwels, X. Ye, and J. P. Bello, “Guitarset: A dataset for guitar transcription.” inISMIR, 2018, pp. 453–460
2018
-
[63]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” inICASSP. IEEE, 2017, pp. 776–780
2017
-
[64]
Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research,
X. Mei, C. Meng, H. Liu, Q. Kong, T. Ko, C. Zhao, M. D. Plumbley, Y . Zou, and W. Wang, “Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research,”IEEE Trans. on Audio, Speech, and Language Processing, vol. 32, pp. 3339– 3354, 2024
2024
-
[65]
C. K. Reddy, V . Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braunet al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,”arXiv preprint arXiv:2005.13981, 2020
-
[66]
WHAM!: Extending Speech Separation to Noisy Environments
G. Wichern, J. Antognini, M. Flynn, L. R. Zhu, E. McQuinn, D. Crow, E. Manilow, and J. L. Roux, “Wham!: Extending speech separation to noisy environments,”arXiv preprint arXiv:1907.01160, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[67]
ESC: Dataset for Environmental Sound Classification,
K. J. Piczak, “ESC: Dataset for Environmental Sound Classification,” in ACM Int. Conf. Multimedia. ACM Press, pp. 1015–1018
-
[68]
A dataset and taxonomy for urban sound research,
J. Salamon, C. Jacoby, and J. P. Bello, “A dataset and taxonomy for urban sound research,” inACM Int. Conf. Multimedia, Orlando, FL, USA, Nov. 2014, pp. 1041–1044
2014
-
[69]
The qut-noise- timit corpus for evaluation of voice activity detection algorithms,
D. Dean, S. Sridharan, R. V ogt, and M. Mason, “The qut-noise- timit corpus for evaluation of voice activity detection algorithms,” in INTERSPEECH. International Speech Communication Association, 2010, pp. 3110–3113
2010
-
[70]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[71]
gpurir: A python library for room impulse response simulation with gpu acceleration,
D. Diaz-Guerra, A. Miguel, and J. R. Beltran, “gpurir: A python library for room impulse response simulation with gpu acceleration,” Multimedia Tools and Applications, vol. 80, no. 4, pp. 5653–5671, 2021
2021
-
[72]
A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,”arXiv preprint arXiv:2006.01919, 2020
-
[73]
TAU Spatial Room Impulse Response Database (TAU-SRIR DB),
A. Politis, S. Adavanne, T. Virtanen, E. Fagerlund, A. Koskimies, A. Hakala, and A. Gohar, “TAU Spatial Room Impulse Response Database (TAU-SRIR DB),” Apr. 2022
2022
-
[74]
Zero-and few-shot sound event localization and detection,
K. Shimada, K. Uchida, Y . Koyama, T. Shibuya, S. Takahashi, Y . Mit- sufuji, and T. Kawahara, “Zero-and few-shot sound event localization and detection,” inICASSP. IEEE, 2024, pp. 636–640
2024
-
[75]
Two vs. four-channel sound event localization and detection,
J. Wilkins, M. Fuentes, L. Bondi, S. Ghaffarzadegan, A. Abavisani, and J. P. Bello, “Two vs. four-channel sound event localization and detection,”arXiv preprint arXiv:2309.13343, 2023
-
[76]
Data augmentation and class-based ensembled cnn-conformer networks for sound event localization and detection,
Y . Zhang, S. Wang, Z. Li, K. Guo, S. Chen, and Y . Pang, “Data augmentation and class-based ensembled cnn-conformer networks for sound event localization and detection,”Proc. DCASE, vol. 2021, 2021
2021
-
[77]
A. Politis, K. Shimada, P. Sudarsanam, S. Adavanne, D. Krause, Y . Koyama, N. Takahashi, S. Takahashi, Y . Mitsufuji, and T. Virtanen, “Starss22: A dataset of spatial recordings of real scenes with spatiotem- poral annotations of sound events,”arXiv preprint arXiv:2206.01948, 2022
-
[78]
A metric on the space of finite sets of trajectories for evaluation of multi-target tracking algorithms,
´A. F. Garc´ıa-Fern´andez, A. S. Rahmathullah, and L. Svensson, “A metric on the space of finite sets of trajectories for evaluation of multi-target tracking algorithms,”IEEE Trans. on Signal Processing, vol. 68, pp. 3917–3928, 2020
2020
-
[79]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T. Liu, W....
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.