Understanding Agent-Based Patching of Compiler Missed Optimizations
Pith reviewed 2026-07-03 08:32 UTC · model grok-4.3
The pith
Coding agents often optimize specific LLVM missed optimization cases but produce patches whose scope only partially matches or overlaps with developer-intended changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
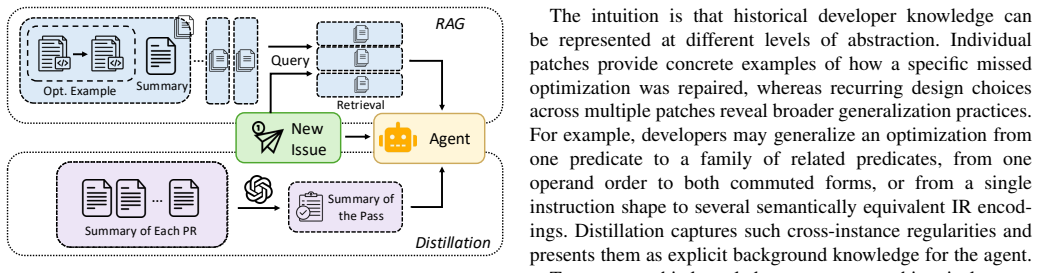
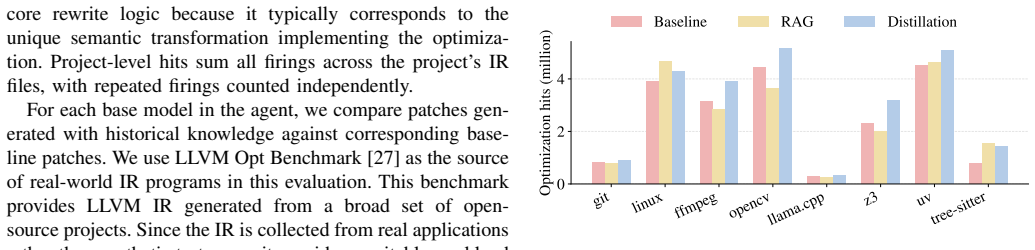
Patching a compiler missed optimization requires generalizing beyond the reported case to cover similar situations. On a benchmark of real-world LLVM missed optimization issues, coding agents commonly optimize the supplied examples, but many generated patches cover only part of the developer-intended scope, partially overlap with it, or in some cases generalize beyond the reference patch. Augmentation techniques that leverage historical LLVM optimization pull requests via retrieval and distillation measurably increase the degree of developer-aligned generalization and produce practical improvements when applied to real-world IR.
What carries the argument
Comparison of optimization scope between agent-generated patches and developer reference patches on a benchmark of real-world LLVM missed optimization issues.
If this is right
- Agents can generate initial patches for missed optimizations but require additional mechanisms to ensure full scope alignment with developer intent.
- Retrieval and distillation of prior pull requests measurably improve how well agent patches match the generalization level chosen by developers.
- The same augmentation approach yields measurable benefits when the resulting patches are applied to real-world LLVM intermediate representation.
- Patching tasks that involve generalization beyond a single example remain a distinct challenge even when the agent succeeds on the reported case.
Where Pith is reading between the lines
- Agent systems for code editing may benefit from explicit scope-inference steps that go beyond example-level fixes.
- The partial-overlap pattern observed here could appear in other maintenance domains where changes must apply to families of similar code rather than isolated instances.
- Re-running the evaluation on LLVM issues reported after the benchmark construction date would test whether the observed generalization gap persists over time.
Load-bearing premise
The constructed benchmark of real-world LLVM missed optimization issues sufficiently represents the generalization requirements that human developers apply when patching.
What would settle it
Collect a fresh set of LLVM missed optimization reports not used in the original benchmark, have the same agents generate patches, and measure whether the distribution of scope coverage (partial, overlapping, beyond-reference) matches the statistics reported in the paper.
Figures






read the original abstract
Compiler missed optimizations refer to cases in which compilers failed to optimize certain code. It takes many compiler developers' efforts to implement or patch such missed optimizations. In this paper, we present a systematic study of how well agents patch compiler missed optimizations. We identify a significant challenge that patching a missed optimization requires more than just fixing the reported case, and instead requires generalizing to similar cases. We construct a benchmark of real-world LLVM missed optimization issues and compare agent-generated patches with patches from developers in terms of optimization scope. Our results show that coding agents often optimize the given examples, but many generated patches either cover only part of the developer-intended scope or partially overlap with it; in some cases, they further generalize beyond the reference patch. We further introduce historical-knowledge augmentation techniques that leverage prior LLVM optimization pull requests through retrieval and distillation, showing that they improve developer-aligned generalization and yield practical benefits when applied to real-world IR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic study of coding agents patching real-world LLVM missed optimizations. It constructs a benchmark from developer-reported issues, compares agent-generated patches to reference developer patches on optimization scope (finding frequent partial coverage, partial overlap, or over-generalization by agents), and proposes historical-knowledge augmentation via retrieval and distillation from prior LLVM PRs that improves alignment with developer scope and yields practical benefits on IR.
Significance. If the results hold, the work usefully documents generalization challenges for agents on compiler tasks and shows that retrieval/distillation from historical patches can measurably improve developer-aligned scope; the augmentation techniques constitute a concrete, reusable contribution that could inform agent tooling for optimization-related SE tasks.
major comments (2)
- [Benchmark Construction] The central evaluation treats the chosen developer reference patches as defining the correct optimization scope (partial coverage, overlap, or over-generalization), yet the manuscript provides no independent validation or inter-rater study confirming that these references match the generalization decisions human compiler developers would typically make on similar cases. This assumption is load-bearing for all reported mismatch rates.
- [§4] §4 (Evaluation) and the abstract state quantitative results on scope but supply no details on benchmark construction criteria, exact scope-classification procedure, statistical methods, controls for patch size, or inter-annotator agreement; without these the data-to-claim link cannot be assessed.
minor comments (2)
- Clarify the precise definition and operationalization of 'optimization scope' and 'generalize beyond the reference patch' with examples or pseudocode.
- The paper would benefit from an explicit limitations subsection discussing selection bias in the LLVM issues chosen for the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our benchmark and evaluation methodology. We will revise the manuscript to address these points by expanding the relevant sections with additional details and discussion.
read point-by-point responses
-
Referee: [Benchmark Construction] The central evaluation treats the chosen developer reference patches as defining the correct optimization scope (partial coverage, overlap, or over-generalization), yet the manuscript provides no independent validation or inter-rater study confirming that these references match the generalization decisions human compiler developers would typically make on similar cases. This assumption is load-bearing for all reported mismatch rates.
Authors: Developer patches from real LLVM pull requests serve as our reference because they embody the generalization decisions made by experienced compiler engineers in practice. We acknowledge the absence of a separate inter-rater study with multiple independent developers. In the revision we will add an explicit subsection in §4 discussing this design choice, its rationale, and the associated limitations, while retaining the developer patches as the primary reference. revision: partial
-
Referee: [§4] §4 (Evaluation) and the abstract state quantitative results on scope but supply no details on benchmark construction criteria, exact scope-classification procedure, statistical methods, controls for patch size, or inter-annotator agreement; without these the data-to-claim link cannot be assessed.
Authors: We will substantially expand §4 (and update the abstract if needed) to document: (i) the precise criteria used to select the benchmark issues from the LLVM issue tracker, (ii) the step-by-step scope-classification procedure with definitions and examples for partial coverage, partial overlap, and over-generalization, (iii) the statistical methods and tests applied, (iv) any controls or matching performed for patch size, and (v) clarification on the annotation process (including whether multiple annotators were used and any agreement measures). These additions will make the evaluation fully reproducible and the link from data to claims transparent. revision: yes
Circularity Check
No circularity detected in empirical evaluation
full rationale
The paper is an empirical study comparing agent-generated patches to developer patches on a constructed benchmark of real-world LLVM missed optimizations. No equations, derivations, fitted parameters, or self-definitional constructs are present in the provided text. The evaluation uses developer patches as the reference scope by design for the comparison task, which does not constitute a reduction to inputs by construction under the specified circularity patterns. No load-bearing self-citations, uniqueness theorems, or ansatzes are identified. The work is self-contained as an observational analysis against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alfred, S
V . Alfred, S. Monica, S. Ravi, U. Jeffrey Det al.,Compilers Principles, Techniques. Pearson, 2007
2007
-
[2]
Llvm: A compilation framework for lifelong program analysis & transformation,
C. Lattner and V . Adve, “Llvm: A compilation framework for lifelong program analysis & transformation,” inInternational symposium on code generation and optimization, 2004. CGO 2004.IEEE, 2004, pp. 75–86
2004
-
[3]
Lpo: Discovering missed peephole optimizations with large language models,
Z. Xu, H. Xu, Y . Tian, X. Zhou, and C. Sun, “Lpo: Discovering missed peephole optimizations with large language models,” in Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’26. New York, NY , USA: Association for Computing Machinery, 2026, p. 1136–1150. [...
-
[4]
Souper: A Synthesizing Superoptimizer
R. Sasnauskas, Y . Chen, P. Collingbourne, J. Ketema, G. Lup, J. Taneja, and J. Regehr, “Souper: A synthesizing superoptimizer,”arXiv preprint arXiv:1711.04422, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Hydra: Generalizing peephole optimiza- tions with program synthesis,
M. Mukherjee and J. Regehr, “Hydra: Generalizing peephole optimiza- tions with program synthesis,”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 725–753, 2024
2024
-
[6]
Finding missed code size optimizations in compilers using large language models,
D. Italiano and C. Cummins, “Finding missed code size optimizations in compilers using large language models,” inProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction, 2025, pp. 81–91
2025
-
[7]
Agentic harness for real- world compilers,
Y . Zheng, C. Li, S. Li, Y . Zhang, and Z. Su, “Agentic harness for real- world compilers,”arXiv preprint arXiv:2603.20075, 2026
-
[8]
Automatically finding patches using genetic programming,
W. Weimer, T. Nguyen, C. Le Goues, and S. Forrest, “Automatically finding patches using genetic programming,” in2009 IEEE 31st Interna- tional Conference on Software Engineering. IEEE, 2009, pp. 364–374
2009
-
[9]
Is the cure worse than the disease? overfitting in automated program repair,
E. K. Smith, E. T. Barr, C. Le Goues, and Y . Brun, “Is the cure worse than the disease? overfitting in automated program repair,” in Proceedings of the 2015 10th joint meeting on foundations of software engineering, 2015, pp. 532–543
2015
-
[10]
History driven program repair,
X. B. D. Le, D. Lo, and C. Le Goues, “History driven program repair,” in2016 IEEE 23rd international conference on software analysis, evolution, and reengineering (SANER), vol. 1. IEEE, 2016, pp. 213– 224
2016
-
[11]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[12]
An empirical study of optimization bugs in gcc and llvm,
Z. Zhou, Z. Ren, G. Gao, and H. Jiang, “An empirical study of optimization bugs in gcc and llvm,”Journal of Systems and Software, vol. 174, p. 110884, 2021
2021
-
[13]
Llvm language reference manual,
LLVM Project, “Llvm language reference manual,” https://llvm.org/ docs/LangRef.html, 2026, lLVM 23.0.0git documentation
2026
-
[14]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,”arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Alive2: bounded translation validation for llvm,
N. P. Lopes, J. Lee, C.-K. Hur, Z. Liu, and J. Regehr, “Alive2: bounded translation validation for llvm,” inProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, 2021, pp. 65–79
2021
-
[16]
llvm-mca - LLVM Machine Code Analyzer,
LLVM Project, “llvm-mca - LLVM Machine Code Analyzer,” 2026, lLVM 23.0.0git documentation. [Online]. Available: https: //llvm.org/docs/CommandGuide/llvm-mca.html
2026
-
[17]
lit - LLVM Integrated Tester,
——, “lit - LLVM Integrated Tester,” lLVM 23.0.0git documentation. Last updated: 2026-06-12. Accessed: 2026-06-12. [Online]. Available: https://llvm.org/docs/CommandGuide/lit.html
2026
-
[18]
Whitefox: White-box compiler fuzzing empowered by large language models,
C. Yang, Y . Deng, R. Lu, J. Yao, J. Liu, R. Jabbarvand, and L. Zhang, “Whitefox: White-box compiler fuzzing empowered by large language models,”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA2, pp. 709–735, 2024
2024
-
[19]
GPT-5.5 System Card,
OpenAI, “GPT-5.5 System Card,” https://openai.com/index/ gpt-5-5-system-card/, Apr. 2026, updated April 24, 2026. Accessed June 15, 2026
2026
-
[20]
Deepseek-v4: Towards highly efficient million-token context intelligence,
A. DeepSeek, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[21]
Qwen3.5: Accelerating productivity with native multimodal agents,
Q. Team, “Qwen3.5: Accelerating productivity with native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id= qwen3.5
2026
-
[22]
Kimi K2.5: Visual Agentic Intelligence
K. Team, T. Bai, Y . Bai, Y . Bao, S. Cai, Y . Cao, Y . Charles, H. Che, C. Chen, G. Chenet al., “Kimi k2. 5: Visual agentic intelligence,”arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
High-throughput, formal-methods-assisted fuzzing for llvm,
Y . Fan and J. Regehr, “High-throughput, formal-methods-assisted fuzzing for llvm,” in2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2024, pp. 349–358
2024
-
[25]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Linet al., “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Llvm opt benchmark,
Y . Zheng, “Llvm opt benchmark,” 2023. [Online]. Available: https://github.com/dtcxzyw/llvm-opt-benchmark
2023
-
[28]
Patchpilot: A cost-efficient software engineering agent with early attempts on formal verification,
H. Li, Y . Tang, S. Wang, and W. Guo, “Patchpilot: A cost-efficient software engineering agent with early attempts on formal verification,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 35 922–35 941
2025
-
[29]
Claude Code by Anthropic — AI Coding Agent, Terminal, IDE,
Anthropic, “Claude Code by Anthropic — AI Coding Agent, Terminal, IDE,” https://claude.com/product/claude-code, 2026, accessed: 2026-05- 27
2026
-
[30]
Codex — AI Coding Partner from OpenAI,
OpenAI, “Codex — AI Coding Partner from OpenAI,” https://openai. com/codex/, 2026, accessed: 2026-05-27
2026
-
[31]
Optgen: A generator for local optimizations,
S. Buchwald, “Optgen: A generator for local optimizations,” inInter- national Conference on Compiler Construction. Springer, 2015, pp. 171–189
2015
-
[32]
Generating compiler optimizations from proofs,
R. Tate, M. Stepp, and S. Lerner, “Generating compiler optimizations from proofs,”ACM Sigplan Notices, vol. 45, no. 1, pp. 389–402, 2010
2010
-
[33]
Leveraging large lan- guage models for generalizing peephole optimizations,
C. Liao, H. Xu, X. Zhou, Z. Xu, and C. Sun, “Leveraging large lan- guage models for generalizing peephole optimizations,”arXiv preprint arXiv:2603.18477, 2026
-
[34]
An analysis of patch plausibility and correctness for generate-and-validate patch generation systems,
Z. Qi, F. Long, S. Achour, and M. Rinard, “An analysis of patch plausibility and correctness for generate-and-validate patch generation systems,” inProceedings of the 2015 international symposium on software testing and analysis, 2015, pp. 24–36
2015
-
[35]
Identifying patch correctness in test-based program repair,
Y . Xiong, X. Liu, M. Zeng, L. Zhang, and G. Huang, “Identifying patch correctness in test-based program repair,” inProceedings of the 40th international conference on software engineering, 2018, pp. 789–799
2018
-
[36]
Automatic patch generation learned from human-written patches,
D. Kim, J. Nam, J. Song, and S. Kim, “Automatic patch generation learned from human-written patches,” in2013 35th international con- ference on software engineering (ICSE). IEEE, 2013, pp. 802–811
2013
-
[37]
Automatic patch generation by learning correct code,
F. Long and M. Rinard, “Automatic patch generation by learning correct code,” inProceedings of the 43rd annual ACM SIGPLAN-SIGACT symposium on principles of programming languages, 2016, pp. 298– 312
2016
-
[38]
Getafix: Learning to fix bugs automatically,
J. Bader, A. Scott, M. Pradel, and S. Chandra, “Getafix: Learning to fix bugs automatically,”Proceedings of the ACM on Programming Languages, vol. 3, no. OOPSLA, pp. 1–27, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.