Object-centric LeJEPA
Pith reviewed 2026-07-03 15:09 UTC · model grok-4.3
The pith
Object-centric LeJEPA using SAM masks outperforms image-level LeJEPA on tracking, classification, segmentation and re-identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
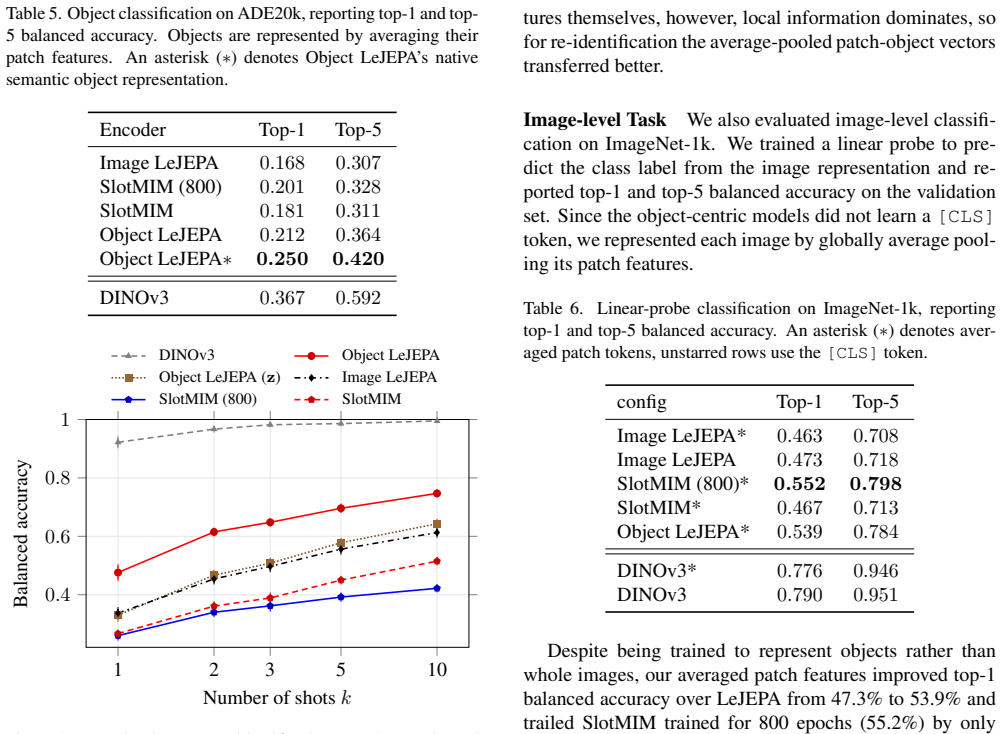
By treating object masks from SAM as given inputs, LeJEPA can be applied directly to align object-centric representations rather than whole-image representations; the distributional anti-collapse objective ports naturally to sets of objects, and an instance-separating loss that uses intra-scene objects as negatives further improves the learned features, yielding higher performance than image-level LeJEPA on DAVIS tracking, ImageNet-1k classification, ADE20k segmentation, and NAVI re-identification across model scales and data fractions.
What carries the argument
Extension of LeJEPA's distributional anti-collapse objective to variable-sized sets of objects supplied by SAM, together with an instance-separating loss that treats other objects in the same image as negatives.
If this is right
- Object-level alignment improves downstream performance on tracking, classification, segmentation, and re-identification relative to image-level training.
- The gains hold across two model scales and when only 10 to 100 percent of COCO is available.
- The instance-separating loss contributes additional improvement beyond the distributional objective alone.
- The method avoids the need to jointly optimize partitioning and representation learning inside the same training loop.
Where Pith is reading between the lines
- The same fixed-mask strategy could be tried with other self-supervised objectives that already possess a distributional anti-collapse term.
- Performance would likely degrade on domains where SAM produces inconsistent or semantically poor masks.
- The approach suggests a general route for increasing data efficiency in any contrastive or distributional self-supervised method by moving from image-level to object-level alignment.
Load-bearing premise
That off-the-shelf SAM proposals already supply object partitions that are consistent enough and semantically coherent for the anti-collapse objective to operate without reintroducing circular dependence between partitioning and representation quality.
What would settle it
Replace the SAM masks with random or inconsistent partitions during training and check whether the performance gap over image-level LeJEPA on the four downstream tasks disappears.
Figures





read the original abstract
Image encoders trained with LeJEPA can deliver strong features for downstream tasks, but, like other image-level self-supervised methods, typically require large training datasets. Aligning representations at the level of objects rather than whole scenes promises greater data efficiency, but doing this in a completely self-supervised way, effectively jointly partitioning a scene and representing its objects, is unstable: the two are locked in a cyclic dependency, partitioning requires meaningful representations, while meaningful representations require consistent partitioning. We sidestep this instability by taking object masks as given during training, using cheap, off-the-shelf SAM proposals. We extend LeJEPA - whose distributional anti-collapse objective ports naturally from whole images to variable-sized sets of objects - to align object-centric representations rather than whole images. An additional instance-separating loss, which treats other objects in the same scene as negatives, further boosts downstream performance. Across two model scales and 10-100% of COCO, object-level LeJEPA outperforms image-level LeJEPA on tracking (DAVIS), classification (ImageNet-1k), segmentation (ADE20k), and re-identification (NAVI).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to extend LeJEPA to object-centric representations by using fixed off-the-shelf SAM object masks during training (sidestepping the cyclic dependency between partitioning and representation learning), adding an instance-separating loss that treats co-occurring objects as negatives, and reports outperformance versus image-level LeJEPA on DAVIS tracking, ImageNet-1k classification, ADE20k segmentation, and NAVI re-identification across two model scales and 10-100% COCO subsets.
Significance. If the gains hold under rigorous evaluation, the approach could offer a pragmatic path to data-efficient object-centric self-supervised learning without jointly optimizing partitions, with downstream benefits for tasks needing object-level features.
major comments (2)
- [Abstract] Abstract: the central empirical claim of consistent outperformance on four benchmarks is asserted without experimental details, baselines, error bars, ablation results, or statistical tests, so the claim cannot be evaluated.
- [Method] Method: the distributional anti-collapse objective is applied to SAM-derived object sets under the assumption that these masks supply sufficiently consistent partitions across augmentations; no verification of object-count stability, boundary consistency, or semantic coherence is provided, leaving open the possibility that gains are artifacts of the particular mask distribution rather than a general solution to the cyclic dependency.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of consistent outperformance on four benchmarks is asserted without experimental details, baselines, error bars, ablation results, or statistical tests, so the claim cannot be evaluated.
Authors: We agree that the abstract, being a concise summary, omits the full experimental details present in the main text. The manuscript reports results with baselines (image-level LeJEPA), two model scales, 10-100% COCO subsets, error bars, and ablations across DAVIS, ImageNet-1k, ADE20k, and NAVI. To make the central claim more evaluable at a glance, we will revise the abstract to briefly reference the evaluation protocol, data regimes, and presence of ablations and error bars, while directing readers to the experiments section for complete details and statistical reporting. revision: yes
-
Referee: [Method] Method: the distributional anti-collapse objective is applied to SAM-derived object sets under the assumption that these masks supply sufficiently consistent partitions across augmentations; no verification of object-count stability, boundary consistency, or semantic coherence is provided, leaving open the possibility that gains are artifacts of the particular mask distribution rather than a general solution to the cyclic dependency.
Authors: The referee correctly identifies that the original submission lacks explicit quantitative verification of SAM mask consistency. Our method uses fixed, off-the-shelf SAM masks transformed deterministically with augmentations to avoid the cyclic dependency, but we will add an analysis (new appendix or subsection) reporting object-count stability, boundary IoU under augmentations, and semantic coherence examples on COCO. This will directly test whether gains could be mask-distribution artifacts. We maintain that fixing partitions sidesteps the cyclic issue as stated in the introduction, but the added verification will strengthen the evidence that the approach is not tied to idiosyncrasies of SAM. revision: yes
Circularity Check
No circularity: empirical extension using external masks
full rationale
The manuscript presents an empirical method that applies off-the-shelf SAM masks as fixed inputs and extends LeJEPA's distributional objective plus an added loss term to object sets. No equations, derivations, or self-citation chains are shown that reduce any claimed performance gain to a quantity defined by the method itself. All reported improvements are measured on external downstream benchmarks (DAVIS, ImageNet-1k, ADE20k, NAVI) rather than by construction from fitted parameters or prior self-citations. The work is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf SAM proposals supply consistent object partitions that allow the distributional anti-collapse objective to be applied stably to variable-sized object sets.
Reference graph
Works this paper leans on
-
[1]
How Learning by Re- construction Produces Uninformative Features For Percep- tion
Randall Balestriero and Yann Lecun. How Learning by Re- construction Produces Uninformative Features For Percep- tion. InProceedings of the 41st International Conference on Machine Learning, pages 2566–2585. PMLR, 2024. 2
2024
-
[2]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics,
Randall Balestriero and Yann LeCun. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics,
-
[3]
VICRegL: Self-Supervised Learning of Local Visual Features.Ad- vances in Neural Information Processing Systems, 35:8799– 8810, 2022
Adrien Bardes, Jean Ponce, and Yann LeCun. VICRegL: Self-Supervised Learning of Local Visual Features.Ad- vances in Neural Information Processing Systems, 35:8799– 8810, 2022. 2
2022
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021. 2, 6, 15
2021
-
[5]
Contrastive learning of global and local features for medical image segmentation with limited annotations
Krishna Chaitanya, Ertunc Erdil, Neerav Karani, and Ender Konukoglu. Contrastive learning of global and local features for medical image segmentation with limited annotations. In Advances in Neural Information Processing Systems, pages 12546–12558. Curran Associates, Inc., 2020. 2
2020
-
[6]
ImageNet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical im- age database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 5
2009
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In9th International Conference on Learning Rep- resentations, ICLR 202...
2021
-
[8]
OpenReview.net, 2021. 5
2021
-
[9]
S. M. Ali Eslami, Nicolas Heess, Theophane Weber, Yuval Tassa, David Szepesvari, koray kavukcuoglu, and Geoffrey E Hinton. Attend, infer, repeat: Fast scene understanding with generative models. InAdvances in Neural Information Pro- cessing Systems 29, pages 3225–3233. Curran Associates, Inc., 2016. 1, 3
2016
-
[10]
Slots, Transitions, Loops: Learning Composable World Models for ARC
Gege Gao, Bernhard Sch ¨olkopf, and Andreas Geiger. Slots, transitions, loops: Learning composable world models for ARC.arXiv preprint arXiv:2606.12316, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Boosting unsupervised semantic segmentation with principal mask proposals.Transactions on Machine Learning Research (TMLR), 2024
Oliver Hahn, Nikita Araslanov, Simone Schaub-Meyer, and Stefan Roth. Boosting unsupervised semantic segmentation with principal mask proposals.Transactions on Machine Learning Research (TMLR), 2024. 3
2024
-
[12]
Ef- ficient visual pretraining with contrastive detection.Interna- tional Conference on Computer Vision, 2021
Olivier J H ´enaff, Skanda Koppula, Jean-Baptiste Alayrac, Aaron van den Oord, Oriol Vinyals, and Jo ˜ao Carreira. Ef- ficient visual pretraining with contrastive detection.Interna- tional Conference on Computer Vision, 2021. 2
2021
-
[13]
Object discovery and representa- tion networks
Olivier J H ´enaff, Skanda Koppula, Evan Shelhamer, Daniel Zoran, Andrew Jaegle, Andrew Zisserman, Jo ˜ao Carreira, and Relja Arandjelovi ´c. Object discovery and representa- tion networks. InEuropean Conference on Computer Vision, pages 123–143. Springer, 2022. 2
2022
-
[14]
NA VI: Category- agnostic image collections with high-quality 3D shape and pose annotations
Varun Jampani, Kevis-Kokitsi Maninis, Andreas Engel- hardt, Arjun Karpur, Karen Truong, Kyle Sargent, Stefan Popov, Andre Araujo, Ricardo Martin-Brualla, Kaushal Pa- tel, Daniel Vlasic, Vittorio Ferrari, Ameesh Makadia, Ce Liu, Yuanzhen Li, and Howard Zhou. NA VI: Category- agnostic image collections with high-quality 3D shape and pose annotations. InNeur...
2023
-
[15]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
-
[16]
Bootstrap- ping top-down information for self-modulating slot atten- tion.Advances in Neural Information Processing Systems, 37:103751–103773, 2024
Dongwon Kim, Seoyeon Kim, and Suha Kwak. Bootstrap- ping top-down information for self-modulating slot atten- tion.Advances in Neural Information Processing Systems, 37:103751–103773, 2024. 3
2024
-
[17]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 3
2023
-
[18]
Does object binding naturally emerge in large pretrained vi- sion transformers?Advances in Neural Information Process- ing Systems, 38:3394–3423, 2026
Yihao Li, Saeed Salehi, Lyle Ungar, and Konrad Kording. Does object binding naturally emerge in large pretrained vi- sion transformers?Advances in Neural Information Process- ing Systems, 38:3394–3423, 2026. 2, 5, 6, 14
2026
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755. Springer, 2014. 5
2014
-
[20]
Metaslot: Break through the fixed number of slots in object-centric learning.Advances in Neural Information Processing Systems, 38:67319–67344, 2026
Hongjia Liu, Rongzhen Zhao, Haohan Chen, and Joni Pa- jarinen. Metaslot: Break through the fixed number of slots in object-centric learning.Advances in Neural Information Processing Systems, 38:67319–67344, 2026. 3
2026
-
[21]
Object- Centric Learning with Slot Attention
Francesco Locatello, Dirk Weissenborn, Thomas Un- terthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object- Centric Learning with Slot Attention. InAdvances in Neural Information Processing Systems, pages 11525–11538. Cur- ran Associates, Inc., 2020. 1, 3
2020
-
[22]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled Weight Decay Reg- ularization. InInternational Conference on Learning Repre- sentations, 2017. 5
2017
-
[23]
Temporally consistent object-centric learning by contrasting slots
Anna Manasyan, Maximilian Seitzer, Filip Radovic, Georg Martius, and Andrii Zadaianchuk. Temporally consistent object-centric learning by contrasting slots. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5401–5411, 2025. 3
2025
-
[24]
Object-aware crop- ping for self-supervised learning.Transactions on Machine Learning Research, 2022
Shlok Kumar Mishra, Anshul Shah, Ankan Bansal, Janit K Anjaria, Abhyuday Narayan Jagannatha, Abhishek Sharma, David Jacobs, and Dilip Krishnan. Object-aware crop- ping for self-supervised learning.Transactions on Machine Learning Research, 2022. 3
2022
-
[25]
Causal-JEPA: Learning world models through object-level latent masking
Heejeong Nam, Quentin Le Lidec, Lucas Maes, Yann Le- Cun, and Randall Balestriero. Causal-JEPA: Learning world models through object-level latent masking. In2nd Work- shop on Compositional Learning: Safety, Interpretability, and Agents, 2026. 1 9
2026
-
[26]
ChatGPT, 2026
OpenAI. ChatGPT, 2026. 2
2026
-
[27]
DINOv2: Learning Robust Visual Features without Supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
2024
-
[28]
The 2017 DA VIS Challenge on Video Object Segmentation, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 DA VIS Challenge on Video Object Segmentation, 2017. 5
2017
-
[29]
Sam 2: Seg- ment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Seg- ment anything in images and videos. InInternational Con- ference on Learning Representations, pages 28085–28128,
-
[30]
Are We Done with Object-Centric Learn- ing?, 2025
Alexander Rubinstein, Ameya Prabhu, Matthias Bethge, and Seong Joon Oh. Are We Done with Object-Centric Learn- ing?, 2025. 3
2025
-
[31]
Bridging the gap to real-world object-centric learning
Maximilian Seitzer, Max Horn, Andrii Zadaianchuk, Do- minik Zietlow, Tianjun Xiao, Carl-Johann Simon-Gabriel, Tong He, Zheng Zhang, Bernhard Sch¨olkopf, Thomas Brox, and Francesco Locatello. Bridging the gap to real-world object-centric learning. InThe Eleventh International Con- ference on Learning Representations, 2023. 1, 3
2023
-
[32]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
2025
-
[33]
Illiterate DALL- E Learns to Compose
Gautam Singh, Fei Deng, and Sungjin Ahn. Illiterate DALL- E Learns to Compose. InThe Tenth International Con- ference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. 1
2022
-
[34]
Represen- tation Learning with Contrastive Predictive Coding, 2019
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Represen- tation Learning with Contrastive Predictive Coding, 2019. 2
2019
-
[35]
Dense contrastive learning for self-supervised visual pre-training
Xinlong Wang, Rufeng Zhang, Chunhua Shen, Tao Kong, and Lei Li. Dense contrastive learning for self-supervised visual pre-training. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3024–3033, 2021. 2
2021
-
[36]
A data-centric revisit of pre-trained vision models for robot learning
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, and Xiaojuan Qi. A data-centric revisit of pre-trained vision models for robot learning. InCVPR, 2025. 3, 5
2025
-
[37]
Ziyi Wu, Nikita Dvornik, Klaus Greff, Thomas Kipf, and Animesh Garg. SlotFormer: Unsupervised visual dynam- ics simulation with object-centric models.arXiv preprint arXiv:2210.05861, 2022. 1
-
[38]
Scene Parsing through ADE20K Dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene Parsing through ADE20K Dataset. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5122–5130,
-
[39]
iBOT: Image BERT pre- training with online tokenizer.International Conference on Learning Representations (ICLR), 2022
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: Image BERT pre- training with online tokenizer.International Conference on Learning Representations (ICLR), 2022. 2 10 A. Visual Results In this section we present visual results for models that are trained on the COCO dataset. Only DINOv3 was trained on a larger da...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.