From SRA to Self-Flow: Data Augmentation or Self-Supervision?
Pith reviewed 2026-07-03 14:34 UTC · model grok-4.3
The pith
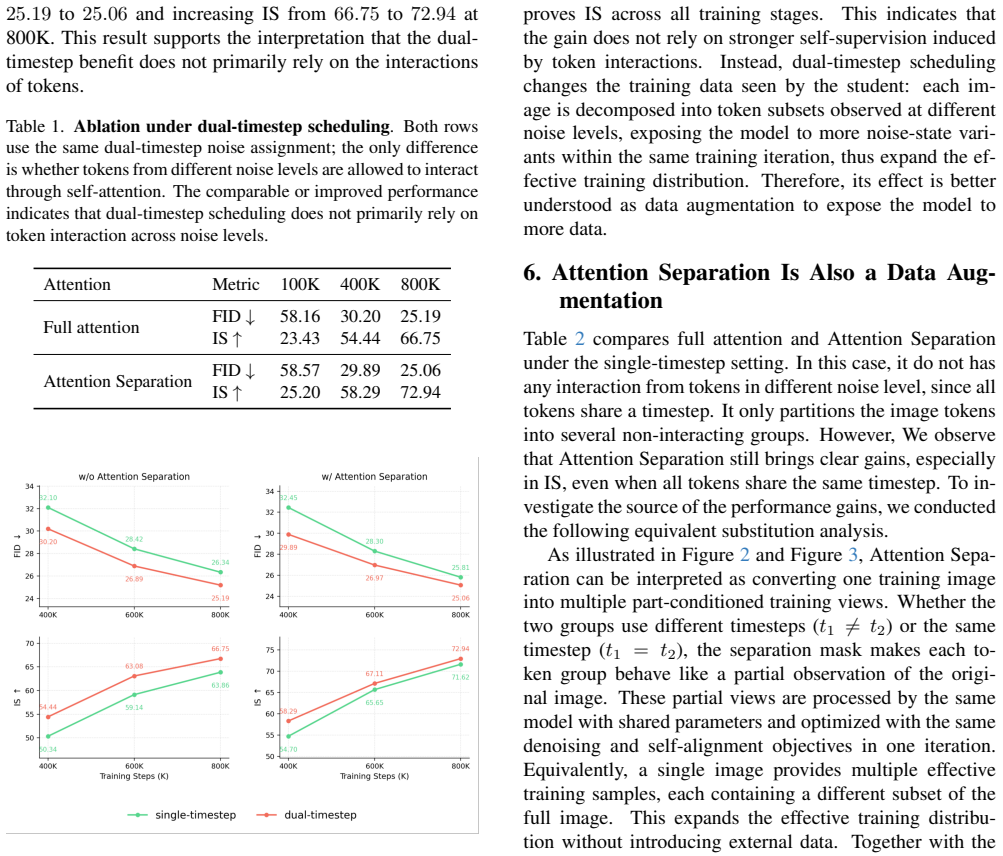
Removing cross-noise attention in dual-timestep diffusion training does not degrade performance and can improve it, showing the gains from SRA to Self-Flow come from data augmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
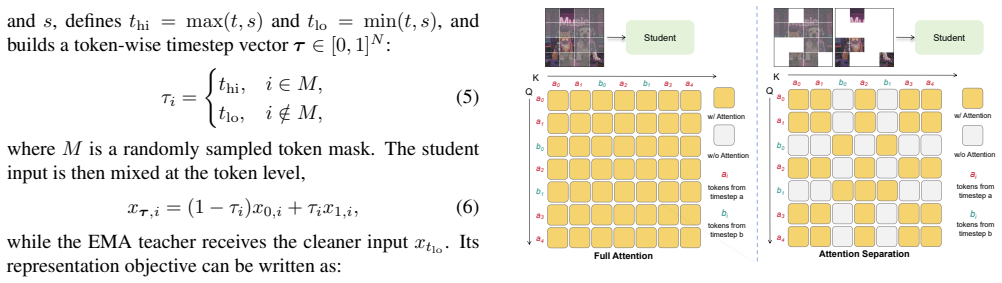
Attention Separation preserves dual-timestep inputs while blocking attention between tokens assigned to different noise levels; removing those interactions does not degrade performance and can improve it, indicating that the improvement from SRA to Self-Flow arises mainly from data augmentation along the noise dimension rather than cross-noise token interactions.
What carries the argument
Attention Separation, a modification that blocks attention between tokens at different noise levels while retaining the same dual-timestep input and loss computation as Self-Flow.
If this is right
- The performance lift in Self-Flow is attributable to data augmentation along the noise dimension rather than self-supervision through token interactions.
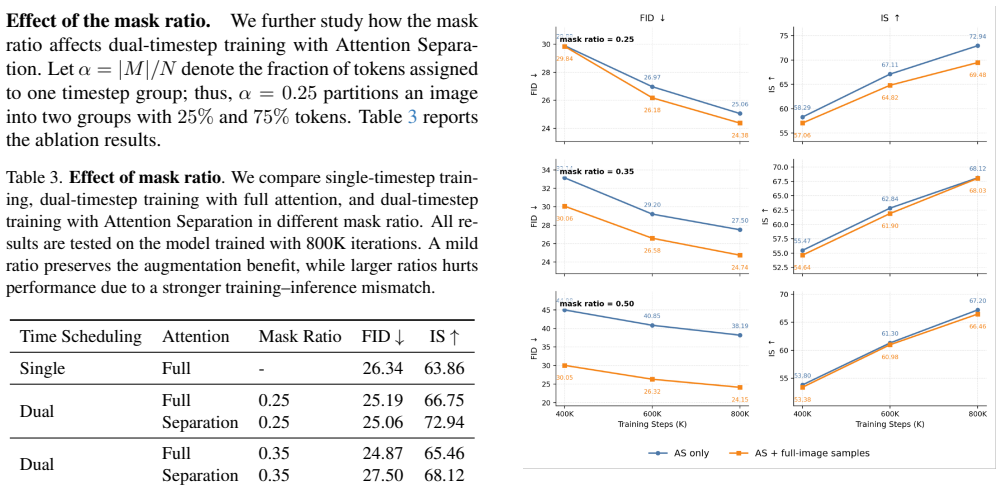
- Attention Separation itself expands the effective training set by splitting each image into multiple parts for separate noise assignments.
- A design that pairs self-representation alignment with both dual-timestep scheduling and attention-separation augmentation produces strong results on ImageNet.
Where Pith is reading between the lines
- The same separation technique could be tested in other generative models that use multi-scale or multi-noise inputs to isolate augmentation effects.
- If the augmentation view holds, similar noise-dimension splitting might improve training efficiency in non-diffusion self-supervised settings.
- The result invites direct measurement of how many additional effective samples Attention Separation creates per original image.
Load-bearing premise
Attention Separation isolates only the cross-noise attention effect while leaving every other aspect of dual-timestep processing and loss computation unchanged.
What would settle it
A large performance drop when Attention Separation is applied to the same dual-timestep setup on ImageNet would show that cross-noise interactions are required after all.
Figures



read the original abstract
Representation alignment has become an effective way to accelerate diffusion transformer training and improve generation quality. Recent self-alignment methods, such as SRA and Self-Flow, further remove the dependency on external pretrained encoders by constructing alignment within the diffusion model itself. However, the mechanism behind the improvement from SRA to Self-Flow, dual-time scheduling, remains under-examined: Self-Flow attributes its gain to interactions between tokens at different noise levels, where cleaner tokens help infer noisier ones. In this work, we revisit this explanation and ask whether the gain instead comes from data augmentation along the noise dimension. To disentangle these factors, we introduce Attention Separation, which preserves the same dual-timestep input as Self-Flow while blocking attention between tokens assigned to different noise levels. Surprisingly, removing such interaction does not degrade performance and can even improve it, suggesting that the improvement from SRA to Self-Flow mainly comes from data augmentation. Furthermore,We show that Attention Separation itself provides an augmentation effect by splitting a single image into multiple effective training parts to expand the training data. Based on these observations, we combine self-representation alignment with dual-timestep and attention-separation augmentation, and demonstrate the effectiveness of this design on ImageNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that performance gains from SRA to Self-Flow arise from data augmentation along the noise dimension rather than cross-noise token interactions. It introduces Attention Separation, which retains dual-timestep inputs but blocks attention between tokens at different noise levels; experiments reportedly show no performance degradation (or even improvement), supporting the data-augmentation interpretation. The work further shows that Attention Separation itself acts as an augmentation by splitting images into multiple effective training parts and combines self-representation alignment with dual-timestep scheduling and attention-separation augmentation, demonstrating effectiveness on ImageNet.
Significance. If the central empirical claim holds after proper controls, the result would usefully reframe self-alignment methods in diffusion transformers toward augmentation effects, potentially simplifying training by de-emphasizing inter-noise supervision. The ablation-based approach to disentangling mechanisms is a constructive contribution, though its interpretive strength depends on verifying isolation of the intended variable.
major comments (1)
- [Attention Separation ablation (methods/experiments sections)] The central claim that gains are due to data augmentation rests on Attention Separation isolating only the blocked cross-noise interactions. No verification is provided that other dynamics (token embeddings, positional encodings, loss terms, gradient flow, or effective batch statistics) remain identical to the Self-Flow baseline; masking can introduce side effects such as altered regularization or intra-group propagation. Explicit checks (e.g., matching intermediate activations or per-component losses) are required for the ablation to support the conclusion.
minor comments (2)
- [Abstract] Abstract contains a typo: 'Furthermore,We show' should read 'Furthermore, we show'.
- [Experiments] The manuscript would benefit from explicit reporting of metrics, controls, and statistical significance for the ablation comparisons to allow readers to assess the strength of the 'maintained or improved' performance statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Attention Separation ablation (methods/experiments sections)] The central claim that gains are due to data augmentation rests on Attention Separation isolating only the blocked cross-noise interactions. No verification is provided that other dynamics (token embeddings, positional encodings, loss terms, gradient flow, or effective batch statistics) remain identical to the Self-Flow baseline; masking can introduce side effects such as altered regularization or intra-group propagation. Explicit checks (e.g., matching intermediate activations or per-component losses) are required for the ablation to support the conclusion.
Authors: We agree that stronger verification of isolation would reinforce the ablation. In Attention Separation, the dual-timestep inputs, token embeddings, positional encodings, loss computation, and batch statistics are identical to the Self-Flow baseline by construction; the only change is an attention mask that blocks cross-noise token interactions while leaving intra-noise attention and all other model components unchanged. Nevertheless, we acknowledge that masking could in principle affect regularization or gradient flow in unexamined ways. In the revised manuscript we will add explicit checks, including side-by-side comparisons of intermediate activations and per-component losses, to confirm that no unintended dynamics are introduced. revision: yes
Circularity Check
No circularity; empirical ablation is self-contained
full rationale
The paper's central claim rests on an ablation experiment (Attention Separation vs. Self-Flow) that reports performance metrics. No derivation chain, equations, or self-referential definitions appear in the provided text. The conclusion is drawn directly from observed results rather than reducing to fitted parameters or self-citations by construction. This is the expected non-finding for an empirical computer-vision paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard diffusion model training assumptions hold, including that the noise schedule and attention mechanisms behave as expected under dual-timestep inputs.
invented entities (1)
-
Attention Separation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023. 3
2023
- [2]
-
[3]
BEiT: BERT pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: BERT pre-training of image transformers. InInternational Conference on Learning Representations, 2022. 3
2022
-
[4]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vi- sion, 2021. 3
2021
-
[5]
Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, and Robin Rom- bach. Self-supervised flow matching for scalable multi- modal synthesis.arXiv preprint arXiv:2603.06507, 2026. 1, 2, 3, 4, 7
-
[6]
A simple framework for contrastive learn- ing of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learn- ing of visual representations. InInternational Conference on Machine Learning, pages 1597–1607, 2020. 3
2020
-
[7]
Context autoencoder for self- supervised representation learning.International Journal of Computer Vision, 132:208 – 223, 2022
Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context autoencoder for self- supervised representation learning.International Journal of Computer Vision, 132:208 – 223, 2022. 3
2022
-
[8]
How far can we go with imagenet for text-to-image generation?arXiv preprint arXiv:2502.21318, 2025
Lucas Degeorge, Arijit Ghosh, Nicolas Dufour, David Pi- card, and Vicky Kalogeiton. How far can we go with imagenet for text-to-image generation?arXiv preprint arXiv:2502.21318, 2025. 3
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 4
2009
-
[10]
Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 7
2021
-
[11]
Patrick Esser, Sumith Kulal, A. Blattmann, Rahim Entezari, Jonas Muller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on...
2024
-
[12]
Richemond, Elena Buchatskaya, Carl Do- ersch, Bernardo ´Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko
Jean-Bastien Grill, Florian Strub, Florent Altch’e, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Do- ersch, Bernardo ´Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural in- formati...
2020
-
[13]
Layersync: Self-aligning intermediate lay- ers.arXiv preprint arXiv:2510.12581, 2025
Yasaman Haghighi, Bastien van Delft, Mariam Hassan, and Alexandre Alahi. Layersync: Self-aligning intermediate lay- ers.arXiv preprint arXiv:2510.12581, 2025. 1, 2
-
[14]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 3
2020
-
[15]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 3
2022
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 4, 7
2017
-
[17]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Low-biased general annotated dataset generation
Dengyang Jiang, Haoyu Wang, Lei Zhang, Wei Wei, Guang Dai, Mengmeng Wang, Jingdong Wang, and Yanning Zhang. Low-biased general annotated dataset generation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 25113–25123, 2025. 3
2025
-
[19]
Dengyang Jiang, Mengmeng Wang, Liuzhuozheng Li, Lei Zhang, Haoyu Wang, Wei Wei, Guang Dai, Yanning Zhang, and Jingdong Wang. No other representation component is needed: Diffusion transformers can provide representation guidance by themselves.arXiv preprint arXiv:2505.02831,
-
[20]
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
Dengyang Jiang, Xin Jin, Dongyang Liu, Zanyi Wang, Mingzhe Zheng, Ruoyi Du, Xiangpeng Yang, Qilong Wu, Zhen Li, Peng Gao, Harry Yang, and Steven Hoi. D-opsd: On-policy self-distillation for continuously tuning step- distilled diffusion models.arXiv preprint arXiv:2605.05204,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Improved precision and recall met- ric for assessing generative models.Advances in neural in- formation processing systems, 32, 2019
Tuomas Kynk ¨a¨anniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall met- ric for assessing generative models.Advances in neural in- formation processing systems, 32, 2019. 7
2019
-
[22]
Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025. 1, 2
2025
-
[23]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Rep- resentations, 2023. 3
2023
-
[25]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Sit: Explor- ing flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Explor- ing flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Com- puter Vision, pages 23–40. Springer, 2024. 1, 3, 4, 7
2024
-
[27]
Generating images with sparse representations
Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W Battaglia. Generating images with sparse representations. arXiv preprint arXiv:2103.03841, 2021. 7
-
[28]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russ Howes, Po-Yao (Bernie) Huang, Shang-Wen Li, Ishan Misra, Michael G. Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´e J´egou, Julie...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 7
2022
-
[31]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 4, 7
2016
-
[32]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Saining Xie. What mat- ters for representation alignment: Global information or spa- tial structure?arXiv preprint arXiv:2512.10794, 2025. 2
-
[33]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image Team, Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, Zhen Li, Zhong-Yu Li, David Liu, Dongyang Liu, Junhan Shi, Qilong Wu, Fengyi Yu, Chi Zhang, Shifeng Zhang, and Shilin Zhou. Z-image: An effi- cient image generation foundation model with single-stream diffusion transforme...
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Manifold mixup: Better representations by interpolating hidden states
Vikas Verma, Alex Lamb, Christopher Beckham, Amir Na- jafi, Ioannis Mitliagkas, Aaron Courville, David Lopez-Paz, and Yoshua Bengio. Manifold mixup: Better representations by interpolating hidden states. InInternational Conference on Machine Learning, pages 6438–6447, 2019. 3
2019
-
[35]
Sra 2: Variational au- toencoder self-representation alignment for efficient diffu- sion training
Mengmeng Wang, Dengyang Jiang, Liuzhuozheng Li, Yucheng Lin, Guojiang Shen, Xiangjie Kong, Yong Liu, Guang Dai, and Jingdong Wang. Sra 2: Variational au- toencoder self-representation alignment for efficient diffu- sion training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 32978– 32987, 2026. 1, 2
2026
-
[36]
Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025
Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang. Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025. 2
-
[37]
Ziqiao Wang, Wangbo Zhao, Yuhao Zhou, Zekai Li, Zhiyuan Liang, Mingjia Shi, Xuanlei Zhao, Pengfei Zhou, Kaipeng Zhang, Zhangyang Wang, Kai Wang, and Yang You. Repa works until it doesn’t: Early-stopped, holistic alignment supercharges diffusion training.arXiv preprint arXiv:2505.16792, 2025. 2
-
[38]
Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, Ming-Ming Cheng, and Xiang Li. Representa- tion entanglement for generation: Training diffusion trans- formers is much easier than you think.arXiv preprint arXiv:2507.01467, 2025. 1, 2
-
[39]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InInternational Con- ference on Learning Representations, 2025. 1, 2, 7
2025
-
[40]
Cutmix: Regular- ization strategy to train strong classifiers with localizable fea- tures
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regular- ization strategy to train strong classifiers with localizable fea- tures. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 6023–6032, 2019. 2, 3
2019
-
[41]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimiza- tion. InInternational Conference on Learning Representa- tions, 2018. 2, 3
2018
-
[42]
Waver: Wave your way to lifelike video genera- tion.arXiv preprint arXiv:2508.15761, 2025
Yifu Zhang, Hao Yang, Yuqi Zhang, Yifei Hu, Fengda Zhu, Chuang Lin, Xiaofeng Mei, Yi Jiang, Bingyue Peng, and Ze- huan Yuan. Waver: Wave your way to lifelike video genera- tion.arXiv preprint arXiv:2508.15761, 2025. 1
-
[43]
Fast training of diffusion models with masked transformers.arXiv preprint arXiv:2306.09305, 2023
Hongkai Zheng, Weili Nie, Arash Vahdat, and Anima Anandkumar. Fast training of diffusion models with masked transformers.arXiv preprint arXiv:2306.09305, 2023. 3
-
[44]
ibot: Image bert pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. InInternational Conference on Learn- ing Representations, 2022. 3
2022
-
[45]
Sd-dit: Unleash- ing the power of self-supervised discrimination in diffusion transformer
Rui Zhu, Yingwei Pan, Yehao Li, Ting Yao, Zhenglong Sun, Tao Mei, and Chang Wen Chen. Sd-dit: Unleash- ing the power of self-supervised discrimination in diffusion transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8435– 8445, 2024. 3 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.