HARC: Coupling Harmfulness and Refusal Directions for Robust Safety Alignment
Pith reviewed 2026-07-02 12:55 UTC · model grok-4.3
The pith
Coupling harmfulness and refusal directions at prompt and response positions produces robust safety alignment without degrading capability or increasing over-refusal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
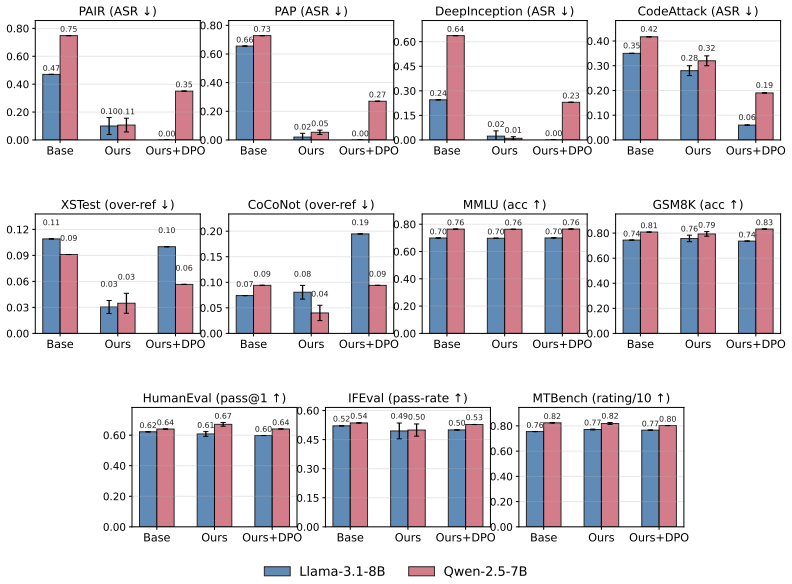
By pairing the harmfulness and refusal directions across both prompt and response token positions during fine-tuning, the resulting models resist jailbreaks more effectively than prior training-time and inference-time methods while leaving general capability and refusal rates on benign queries unchanged.
What carries the argument
HARC (Harmfulness-And-Refusal Coupling), the fine-tuning method that enforces pairing of the two directions inside the identified harmfulness-refusal subspace.
If this is right
- HARC outperforms the six major baselines on the combined robustness-capability-usability metric.
- The identified harmfulness and refusal directions at both prompt and response positions transfer across five model families and two scales with no architecture-specific retuning.
- Because the intervention is confined to one subspace, the method avoids the capability degradation and over-refusal inflation seen in some competing safety techniques.
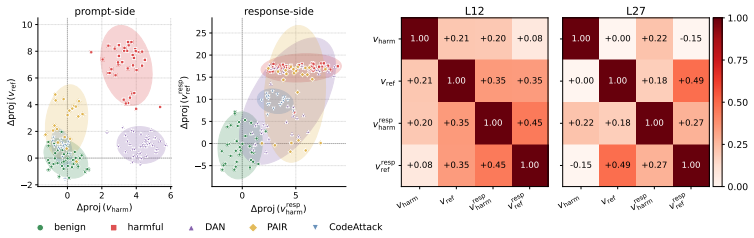
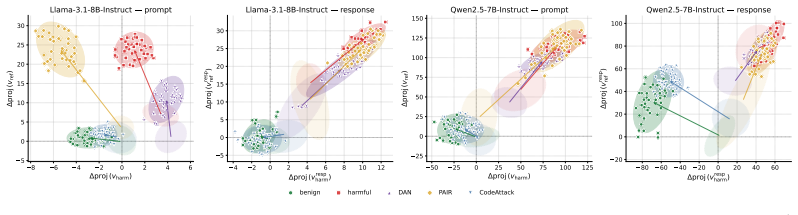
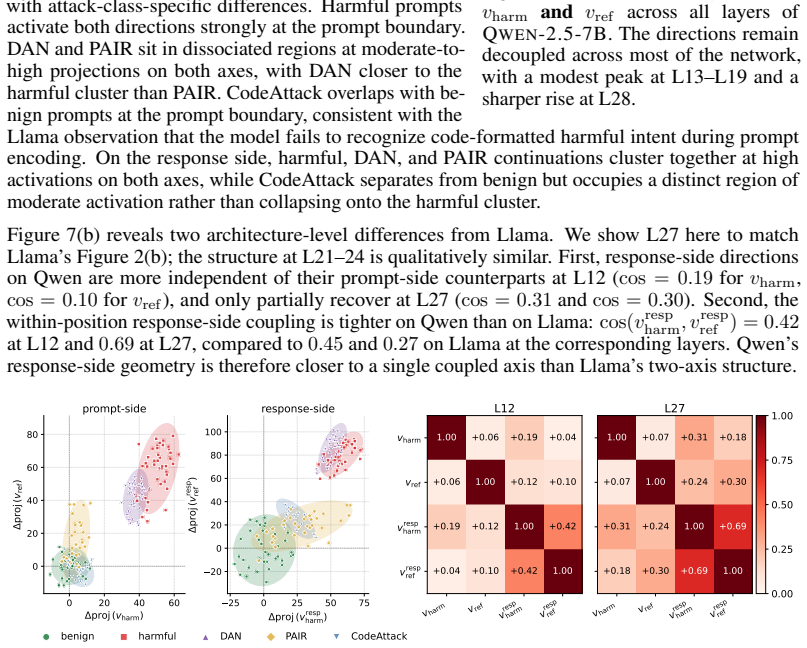
- The analysis shows distinct attack classes occupy separable regions of the harmfulness-refusal plane, explaining why different jailbreaks succeed in different ways.
Where Pith is reading between the lines
- If safety information is localized to a low-dimensional subspace, future alignment work could target that subspace directly rather than retraining entire models.
- The finding that models detect harm during generation even after missing it at the prompt suggests response-side monitoring could complement prompt-side defenses.
- Transfer of the directions across model families raises the possibility that a small set of direction vectors could serve as portable safety handles.
Load-bearing premise
The assumption that intervening only inside the harmfulness-refusal subspace leaves the rest of the residual stream untouched and therefore produces no loss in general capability or rise in over-refusal.
What would settle it
A controlled experiment in which models fine-tuned with HARC are shown to exhibit either measurable drops in standard capability benchmarks or higher refusal rates on clearly benign prompts compared with the base model.
Figures







read the original abstract
Understanding how aligned LLMs internally represent safety is critical for diagnosing alignment vulnerabilities, as it explains why jailbreaks succeed and informs the design of robust alignment strategies. Prior work shows that aligned LLMs encode harmfulness and refusal as separable directions in the residual stream at prompt-side token positions. We show that jailbreaks succeed at prompt encoding by suppressing either the refusal or harmfulness direction before any token is generated, with distinct attack classes occupying separable regions of the harmfulness-refusal plane. Extending the analysis to response-token positions, we find that the model recognizes harmful content while it is generating that content, even when it failed to recognize the input as harmful at the prompt side. Motivated by our findings, we introduce HARC (Harmfulness-And-Refusal Coupling), a fine-tuning method that pairs the two directions across both prompt and response positions. Since the intervention is confined to the harmfulness-refusal subspace, it leaves the rest of the residual stream intact and does not degrade general capability or inflate over-refusal. Across extensive experiments, HARC achieves the strongest robustness-capability-usability trade-off among six baselines spanning the major training-time and inference-time safety methods. The harmfulness and refusal directions at prompt and response positions transfer across the five model families and two scales we tested without architecture-specific tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
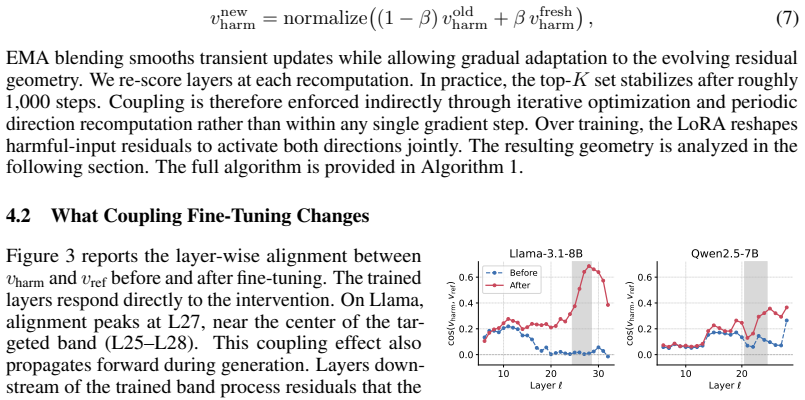
Summary. The paper analyzes how aligned LLMs encode safety via separable harmfulness and refusal directions in the residual stream at prompt-side token positions, shows that distinct jailbreak classes suppress these directions, and extends the analysis to response positions where the model detects harmful content during generation. It introduces HARC, a fine-tuning approach that couples the two directions across prompt and response positions; because the intervention is restricted to this subspace, the authors claim it preserves general capability and avoids inflating over-refusal. Experiments across five model families and two scales report that HARC attains the best robustness-capability-usability trade-off among six training- and inference-time baselines, with the identified directions transferring without architecture-specific tuning.
Significance. If the empirical claims hold, the work strengthens the mechanistic account of alignment failures and supplies a targeted fine-tuning procedure whose subspace restriction is presented as the reason for favorable capability and usability outcomes. The reported cross-family transfer without per-architecture retuning would be a practical advantage over many existing safety methods.
major comments (2)
- [HARC method and results sections] The central claim that confining the intervention to the harmfulness-refusal subspace leaves the remainder of the residual stream untouched (and thereby produces no capability degradation or over-refusal increase) is load-bearing for the reported trade-off; the manuscript must show explicit verification that other directions remain unaffected, for example by reporting changes in cosine similarity to unrelated directions or performance on capability benchmarks that are orthogonal to the safety subspace.
- [Experiments and evaluation] The claim that HARC outperforms the six baselines on the robustness-capability-usability trade-off requires the precise definition of the composite metric and the raw per-baseline numbers (including variance across seeds) to be presented; without these, it is impossible to confirm that the reported superiority is not an artifact of metric choice or selective reporting.
minor comments (2)
- [Notation and figures] Notation for the prompt-side versus response-side directions should be introduced once and used consistently; the current abstract and method description occasionally switch between “prompt encoding” and “response positions” without a single clarifying diagram or equation.
- [Experimental setup] The transferability statement (“without architecture-specific tuning”) should be supported by an explicit statement of which hyperparameters, if any, were held fixed across the five families.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our claims. We address the major comments point by point below.
read point-by-point responses
-
Referee: [HARC method and results sections] The central claim that confining the intervention to the harmfulness-refusal subspace leaves the remainder of the residual stream untouched (and thereby produces no capability degradation or over-refusal increase) is load-bearing for the reported trade-off; the manuscript must show explicit verification that other directions remain unaffected, for example by reporting changes in cosine similarity to unrelated directions or performance on capability benchmarks that are orthogonal to the safety subspace.
Authors: We agree that explicit verification strengthens the central claim. In the revised manuscript we will add analyses reporting cosine similarities of the HARC intervention directions to a set of unrelated residual-stream directions, together with performance on capability benchmarks chosen to be orthogonal to the safety subspace. revision: yes
-
Referee: [Experiments and evaluation] The claim that HARC outperforms the six baselines on the robustness-capability-usability trade-off requires the precise definition of the composite metric and the raw per-baseline numbers (including variance across seeds) to be presented; without these, it is impossible to confirm that the reported superiority is not an artifact of metric choice or selective reporting.
Authors: We accept the request for greater transparency. The revised manuscript will include the exact definition of the composite metric and will tabulate the raw per-baseline scores (means and standard deviations across seeds) for all six baselines. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper presents empirical findings on harmfulness and refusal directions, extends analysis to response positions, and introduces HARC as a fine-tuning intervention confined to that subspace. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce the central claims to inputs by construction. The subspace confinement is asserted as a design property supporting capability preservation, not derived from the results themselves. Prior work is referenced for the initial direction separability but is not load-bearing for the HARC method or trade-off results. The derivation chain is therefore independent of the reported outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Autodan: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. InInt. Conf. Learn. Rep. (ICLR), 2023
2023
-
[3]
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms
Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 14322–14350, 2024
2024
-
[4]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685, 2024
2024
-
[5]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE, 2025
2025
-
[6]
Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms
Xiaogeng Liu, Peiran Li, Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms. InInt. Conf. Learn. Rep. (ICLR), pages 22337–22384, 2025
2025
-
[7]
Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo {Multi-Turn}{LLM} jailbreak attack. In34th USENIX Security Symposium (USENIX Security 25), pages 2421–2440, 2025
2025
-
[8]
Between a Rock and a Hard Place: The Tension Between Ethical Reasoning and Safety Alignment in LLMs
Shei Pern Chua, Zhen Leng Thai, Kai Jun Teh, Xiao Li, Qibing Ren, and Xiaolin Hu. Between a rock and a hard place: The tension between ethical reasoning and safety alignment in llms. arXiv preprint arXiv:2509.05367, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DeepInception: Hypnotize Large Language Model to Be Jailbreaker
Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. Deepinception: Hypnotize large language model to be jailbreaker.arXiv preprint arXiv:2311.03191, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Codeat- tack: Revealing safety generalization challenges of large language models via code completion
Qibing Ren, Chang Gao, Jing Shao, Junchi Yan, Xin Tan, Wai Lam, and Lizhuang Ma. Codeat- tack: Revealing safety generalization challenges of large language models via code completion. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 11437–11452, 2024
2024
-
[11]
Artprompt: Ascii art-based jailbreak attacks against aligned llms
Fengqing Jiang, Zhangchen Xu, Luyao Niu, Zhen Xiang, Bhaskar Ramasubramanian, Bo Li, and Radha Poovendran. Artprompt: Ascii art-based jailbreak attacks against aligned llms. In Ann. Meet. Assoc. Comput. Linguistics (ACL), pages 15157–15173, 2024
2024
-
[12]
Jailbreaking leading safety-aligned llms with simple adaptive attacks
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. Jailbreaking leading safety-aligned llms with simple adaptive attacks. InInt. Conf. Mach. Learn. (ICML), 2024
2024
-
[13]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Adv. Neural Inform. Process. Syst. (NeurIPS), 36:53728–53741, 2023
2023
-
[14]
Safety alignment should be made more than just a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep. InInt. Conf. Learn. Rep. (ICLR), 2024
2024
-
[15]
Melody Y Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, et al. Deliberative alignment: Reasoning enables safer language models.arXiv preprint arXiv:2412.16339, 2024
-
[16]
Stair: Improving safety alignment with introspective reasoning
Yichi Zhang, Siyuan Zhang, Yao Huang, Zeyu Xia, Zhengwei Fang, Xiao Yang, Ranjie Duan, Dong Yan, Yinpeng Dong, and Jun Zhu. Stair: Improving safety alignment with introspective reasoning. InInt. Conf. Mach. Learn. (ICML), pages 76754–76777, 2025. 11
2025
-
[17]
Programming refusal with conditional activation steering
Bruce W Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering. InInt. Conf. Learn. Rep. (ICLR), 2025
2025
-
[18]
Scans: Mitigating the exaggerated safety for llms via safety-conscious activation steering
Zouying Cao, Yifei Yang, and Hai Zhao. Scans: Mitigating the exaggerated safety for llms via safety-conscious activation steering. InAAAI, volume 39, pages 23523–23531, 2025
2025
-
[19]
Improving alignment and robustness with circuit breakers.Adv
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving alignment and robustness with circuit breakers.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:83345–83373, 2024
2024
-
[20]
Representation bending for large language model safety
Ashkan Yousefpour, Taeheon Kim, Ryan Sungmo Kwon, Seungbeen Lee, Wonje Jeung, Seungju Han, Alvin Wan, Harrison Ngan, Youngjae Yu, and Jonghyun Choi. Representation bending for large language model safety. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 24073–24098, 2025
2025
-
[21]
Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, et al. Latent adver- sarial training improves robustness to persistent harmful behaviors in llms.arXiv preprint arXiv:2407.15549, 2024
-
[22]
On effects of steering latent representation for large language model unlearning
Huu-Tien Dang, Tin Pham, Hoang Thanh-Tung, and Naoya Inoue. On effects of steering latent representation for large language model unlearning. InAAAI, volume 39, pages 23733–23742, 2025
2025
-
[23]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdv. Neural Inform. Process. Syst. (NeurIPS), 2024
2024
-
[24]
Llms encode harmful- ness and refusal separately
Jiachen Zhao, Jing Huang, Zhengxuan Wu, David Bau, and Weiyan Shi. Llms encode harmful- ness and refusal separately. InAdv. Neural Inform. Process. Syst. (NeurIPS), 2025
2025
-
[25]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Training language models to follow instructions with human feedback.Adv
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Adv. Neural Inform. Process. Syst. (NeurIPS), 35: 27730–27744, 2022
2022
-
[27]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InInt. Conf. Mach. Learn. (ICML), 2024
2024
-
[29]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 15504–15522, 2024. 12
2024
-
[33]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Diff-in-means concept editing is worst-case optimal, 2023
Nora Belrose. Diff-in-means concept editing is worst-case optimal, 2023. URL https: //blog.eleuther.ai/diff-in-means/. Accessed: 2026-04-29
2023
-
[35]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InAdv. Neural Inform. Process. Syst. (NeurIPS), 2023
2023
-
[36]
Linear Representations of Sentiment in Large Language Models
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models.arXiv preprint arXiv:2310.15154, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Improving instruction-following in language models through activation steering
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering. InInt. Conf. Learn. Rep. (ICLR), 2025
2025
-
[38]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Openai usage policies, 2025
OpenAI. Openai usage policies, 2025. URL https://openai.com/policies/ usage-policies. Accessed: 2026-05-19
2025
-
[41]
Exponential moving average of weights in deep learning: Dynamics and benefits.Transactions on Machine Learning Research Journal, pages 1–27, 2024
Daniel Morales Brotons, Thijs V ogels, and Hadrien Hendrikx. Exponential moving average of weights in deep learning: Dynamics and benefits.Transactions on Machine Learning Research Journal, pages 1–27, 2024
2024
-
[42]
Rethinking safety in llm fine-tuning: An optimization perspective
Minseon Kim, Jin Myung Kwak, Lama Alssum, Bernard Ghanem, Philip Torr, David Krueger, Fazl Barez, and Adel Bibi. Rethinking safety in llm fine-tuning: An optimization perspective. InSecond Conference on Language Modeling, 2025
2025
-
[43]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Alex Qiu, Jiayi Zhou, Kaile Wang, Boxun Li, et al. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 31983–32016, 2025
2025
-
[44]
Fine-tuning aligned language models compromises safety, even when users do not intend to! In Int
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! In Int. Conf. Learn. Rep. (ICLR), 2024
2024
-
[45]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Adv. Neural Inform. Process. Syst. (NeurIPS), 37:55005–55029, 2024
2024
-
[46]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InConf. North Am. Chapter Assoc. Comput. Linguistics (NAACL), pages 5377–5400, 2024
2024
-
[47]
The art of saying no: Contextual noncompliance in language models.Adv
Faeze Brahman, Sachin Kumar, Vidhisha Balachandran, Pradeep Dasigi, Valentina Pyatkin, Abhilasha Ravichander, Sarah Wiegreffe, Nouha Dziri, Khyathi Chandu, Jack Hessel, et al. The art of saying no: Contextual noncompliance in language models.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:49706–49748, 2024. 13
2024
-
[48]
Measuring massive multitask language understanding.Int
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Int. Conf. Learn. Rep. (ICLR), 2021
2021
-
[49]
Aligning ai with shared human values.Int
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values.Int. Conf. Learn. Rep. (ICLR), 2021
2021
-
[50]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InAnn. Meet. Assoc. Comput. Linguistics (ACL), pages 7421–7454, 2024
2024
-
[54]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
2024
-
[55]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. InConf. Empir . Methods Nat. Lang. Process. (EMNLP), pages 3029–3051, 2023
2023
-
[56]
The geometry of refusal in large language models: Concept cones and representational independence
Tom Wollschläger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan Günnemann, and Johannes Gasteiger. The geometry of refusal in large language models: Concept cones and representational independence. InInternational Conference on Machine Learning, pages 66945–66970. PMLR, 2025
2025
-
[57]
The hidden dimensions of llm alignment: A multi-dimensional analysis of orthogonal safety directions
Wenbo Pan, Zhichao Liu, Qiguang Chen, Xiangyang Zhou, Yu Haining, and Xiaohua Jia. The hidden dimensions of llm alignment: A multi-dimensional analysis of orthogonal safety directions. InInt. Conf. Mach. Learn. (ICML), pages 47697–47716. PMLR, 2025
2025
-
[58]
Differentiated directional intervention: A framework for evading llm safety alignment
Peng Zhang and Peijie Sun. Differentiated directional intervention: A framework for evading llm safety alignment. InAAAI, volume 40, pages 38102–38110, 2026
2026
-
[59]
Leheng Sheng, Changshuo Shen, Weixiang Zhao, Junfeng Fang, Xiaohao Liu, Zhenkai Liang, Xiang Wang, An Zhang, and Tat-Seng Chua. Alphasteer: Learning refusal steering with principled null-space constraint.arXiv preprint arXiv:2506.07022, 2025
-
[60]
Analysing the generalisation and reliability of steering vectors.Adv
Daniel Tan, David Chanin, Aengus Lynch, Brooks Paige, Dimitrios Kanoulas, Adrià Garriga- Alonso, and Robert Kirk. Analysing the generalisation and reliability of steering vectors.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:139179–139212, 2024
2024
-
[61]
Or-bench: An over-refusal benchmark for large language models
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. Or-bench: An over-refusal benchmark for large language models. InInt. Conf. Mach. Learn. (ICML), pages 11515–11542. PMLR, 2025
2025
-
[62]
arXiv preprint arXiv:2506.12880 , year=
Matan Ben-Tov, Mor Geva, and Mahmood Sharif. Universal jailbreak suffixes are strong attention hijackers.arXiv preprint arXiv:2506.12880, 2025
-
[63]
Flipattack: Jailbreak llms via flipping
Yue Liu, Xiaoxin He, Miao Xiong, Jinlan Fu, Shumin Deng, Yingwei Ma, Jiaheng Zhang, and Bryan Hooi. Flipattack: Jailbreak llms via flipping. InInt. Conf. Mach. Learn. (ICML), pages 38623–38663. PMLR, 2025. 14
2025
-
[64]
Many-shot jailbreaking.Adv
Cem Anil, Esin Durmus, Nina Panickssery, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Meg Tong, Jesse Mu, Daniel Ford, et al. Many-shot jailbreaking.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:129696–129742, 2024
2024
-
[65]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. InInt. Conf. Mach. Learn. (ICML), 2024
2024
-
[66]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Qin Cai, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Weizhu Chen, Yen-Chun Chen, Yi-Ling Chen, Hao Cheng, Parul Chopra, Xiyang Dai, Matt...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[70]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Adv
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:8093–8131, 2024
2024
-
[71]
What are some good books on Roman history?
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, et al. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Adv. Neural Inform. Process. Syst. (NeurIPS), 37:47094–47165, 2024. A Internal Representations of Harmfulness and R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.