LIFT and PLACE: A Simple, Stable, and Effective Knowledge Distillation Framework for Lightweight Diffusion Models
Pith reviewed 2026-05-21 07:27 UTC · model grok-4.3
The pith
Breaking the teacher's denoising into coarse linear alignment then locally adaptive fine refinement lets tiny students train stably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
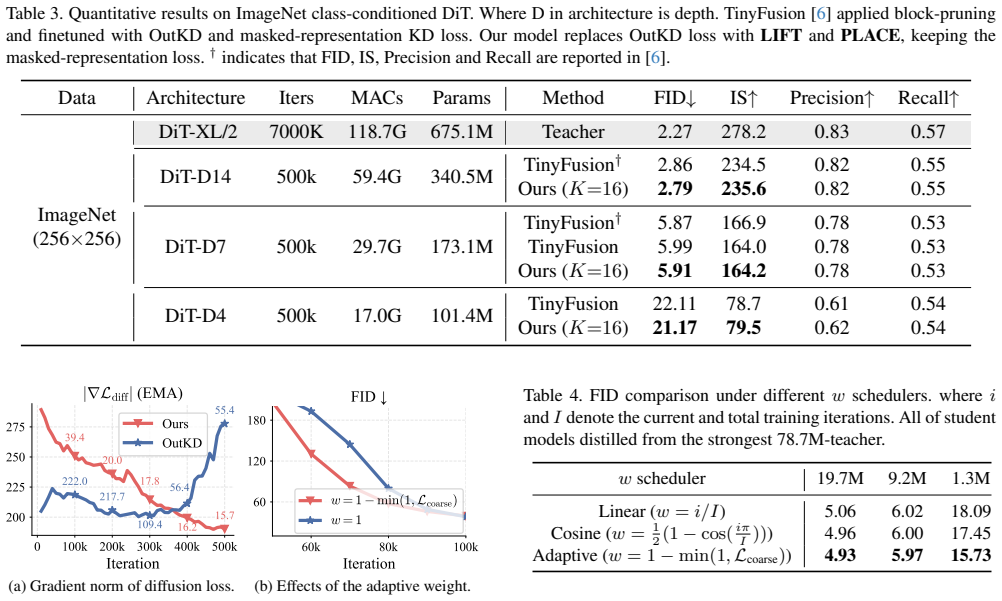
The teacher's complex denoising process can be decomposed into an initial coarse-alignment stage learned via linear fitting of outputs and a subsequent fine-refinement stage whose loss is locally re-weighted by error-based partitioning; training the student sequentially on these two stages yields stable optimization and high-quality generation even when the student capacity is reduced by more than 98 percent.
What carries the argument
LIFT performs linear-fitting-based distillation to separate coarse alignment from fine refinement; PLACE then partitions the output space by local error magnitude to compute spatially adaptive loss coefficients.
If this is right
- Stable training remains possible even when the student is only 1.6 percent of teacher size.
- The same procedure transfers across pixel versus latent diffusion spaces and across U-Net versus DiT architectures.
- The framework also improves distillation for flow-based generative models such as MMDiT.
- Performance holds for both unconditional and class-conditional generation tasks.
Where Pith is reading between the lines
- Edge devices could run high-quality diffusion sampling with far smaller memory footprints if the coarse-to-fine schedule is adopted.
- The error-partitioning idea may transfer to other teacher–student gaps in generative modeling beyond diffusion.
- A natural next test is whether the same staged guidance improves distillation for video or 3-D diffusion models.
Load-bearing premise
The teacher's denoising trajectory contains separable coarse and fine components that error-based local re-weighting can usefully expose to a much smaller student.
What would settle it
Train a 1.3 M-parameter student with the full LIFT-plus-PLACE pipeline on a standard benchmark; if the resulting FID exceeds 50 or training diverges, the claim that the decomposition supplies stable guidance is false.
Figures











read the original abstract
We demonstrate that in knowledge distillation for diffusion models, the teacher network's highly complex denoising process - stemming from its substantially larger capacity - poses a significant challenge for the student model to faithfully mimic. To address this problem, we propose a coarse-to-fine distillation framework with LInear FiTtingbased distillation (LIFT) and Piecewise Local Adaptive Coefficient Estimation (PLACE). First, LIFT decomposes the objective into a "coarse" alignment and a "fine" refinement. The student is then trained on coarse alignment before proceeding to hard refinement. Second, PLACE extends LIFT to address spatially non-uniform errors by partitioning outputs into error-based groups, providing locally adaptive guidance. Our experiments show that LIFT and PLACE is effective across diffusion spaces (image/latent), backbones (U-Net/DiT), tasks (unconditional/conditional), datasets, and even extends to flow-based models such as MMDiT (SD3). Furthermore, under extreme compression with a 1.3M-parameter student (only 1.6% of the teacher), conventional KD fails to provide sufficient guidance for stable training, with FID scores often degrading to 50-200+, but our method remains stably convergent and achieves an FID of 15.73.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LIFT (Linear Fitting-based distillation) and PLACE (Piecewise Local Adaptive Coefficient Estimation) as a coarse-to-fine knowledge distillation framework for lightweight diffusion models. LIFT decomposes the teacher's complex denoising into an initial coarse alignment stage followed by fine refinement, while PLACE partitions outputs into error-based groups to supply locally adaptive guidance. Experiments claim stable convergence and strong FID (15.73) for a 1.3M-parameter student (1.6% of teacher size) where conventional KD degrades to FID 50-200+, with demonstrations across image/latent spaces, U-Net/DiT backbones, unconditional/conditional tasks, and extension to flow-based models like MMDiT.
Significance. If the central stability claims hold under rigorous controls, the framework could meaningfully advance practical deployment of diffusion models on edge devices by enabling reliable extreme compression without training collapse. The cross-backbone and cross-task generality, plus the parameter-free flavor of the linear-fitting core, would be notable strengths.
major comments (2)
- [Experiments] Experiments section: the headline comparison treats direct denoising-output imitation as the sole conventional KD baseline. Stronger standard techniques (intermediate feature matching, attention transfer, or multi-scale losses) that are common in the diffusion KD literature are not shown to fail under the same 1.6% compression regime; without these controls the necessity of the LIFT/PLACE error-based decomposition for stability is not established.
- [§3.2] §3.2 (PLACE description): the partitioning into error-based groups relies on ad-hoc thresholds whose selection is not ablated or justified; it is unclear whether the reported stability is robust to reasonable variations in these thresholds or whether they must be tuned per dataset/backbone.
minor comments (2)
- [Abstract] The abstract states results 'across diffusion spaces (image/latent), backbones (U-Net/DiT), tasks (unconditional/conditional), datasets', yet the main text would benefit from a consolidated table summarizing FID/PSNR across all these axes rather than scattered figures.
- [Method] Notation for the linear-fitting coefficients in LIFT and the local adaptive coefficients in PLACE could be unified or given a single table of definitions to reduce reader effort when tracing the coarse-to-fine schedule.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concerns point by point below and will make the necessary revisions to improve the paper.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline comparison treats direct denoising-output imitation as the sole conventional KD baseline. Stronger standard techniques (intermediate feature matching, attention transfer, or multi-scale losses) that are common in the diffusion KD literature are not shown to fail under the same 1.6% compression regime; without these controls the necessity of the LIFT/PLACE error-based decomposition for stability is not established.
Authors: We agree that a more comprehensive set of baselines would strengthen the claims. While direct output imitation is a standard and direct approach for distilling diffusion models, we acknowledge that methods like feature matching and attention transfer are used in the broader KD literature. To establish the necessity of our LIFT/PLACE framework under extreme compression, we will include additional experiments comparing against these stronger baselines in the revised version. This will better demonstrate where conventional techniques fail and why our coarse-to-fine decomposition is beneficial. revision: yes
-
Referee: [§3.2] §3.2 (PLACE description): the partitioning into error-based groups relies on ad-hoc thresholds whose selection is not ablated or justified; it is unclear whether the reported stability is robust to reasonable variations in these thresholds or whether they must be tuned per dataset/backbone.
Authors: The thresholds in PLACE were selected empirically to partition the error distribution into groups of roughly equal size, ensuring that the local adaptive coefficients are meaningful. We appreciate the concern regarding robustness. In the revision, we will add an ablation study varying the thresholds and report performance across different datasets and backbones to show that the stability is not overly sensitive to exact threshold choices. revision: yes
Circularity Check
No significant circularity: LIFT/PLACE are defined algorithmic steps independent of target outputs or self-referential fits.
full rationale
The paper introduces LIFT as an explicit two-stage decomposition (coarse alignment then fine refinement) and PLACE as error-based partitioning for local coefficients. These are presented as new procedural choices rather than quantities fitted from the student-teacher outputs or derived via self-citation chains. The central claim (stable convergence at 1.6% compression) rests on empirical comparison to a conventional KD baseline, not on any equation that reduces to its own inputs by construction. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- error group thresholds in PLACE
axioms (1)
- domain assumption The denoising process admits a useful coarse-to-fine decomposition for student learning
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.