Geometric Dyson Brownian Motions and the Free Log-Normal Limit for a Non-Square Product of Random Matrices
Pith reviewed 2026-07-01 01:39 UTC · model grok-4.3
The pith
The squared singular value spectrum of non-square random matrix products converges to the free log-normal law after two sequential mean-field limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the first proportional limit the eigenvalue process obeys geometric Dyson Brownian motion. In the second sequential mean-field limit the T-transform satisfies a Burgers equation whose solution is the free log-normal law when the process starts from the identity, or the free multiplicative convolution of that law with the initial measure in general.
What carries the argument
Geometric Dyson Brownian motion of the squared singular value process, whose T-transform satisfies a Burgers equation in the mean-field limit.
If this is right
- The limiting spectral law is exactly the free log-normal distribution in the identity-start case.
- The general limiting law is obtained by free multiplicative convolution with the free log-normal.
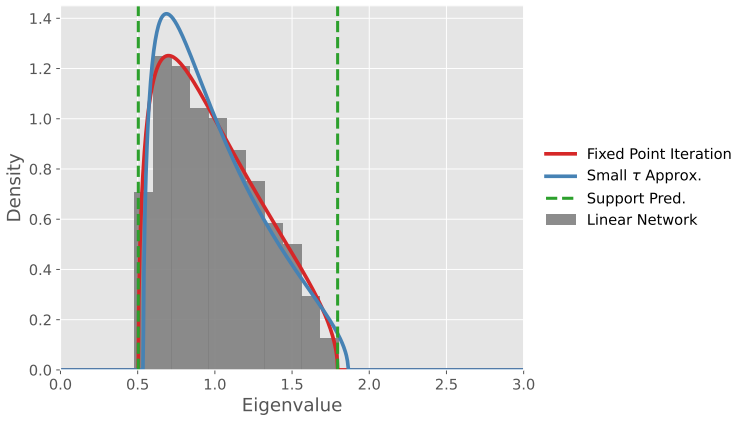
- An explicit support formula and a fixed-point iteration for numerical evaluation are available for the free log-normal.
- A formal small-time approximation by the Marchenko-Pastur law holds.
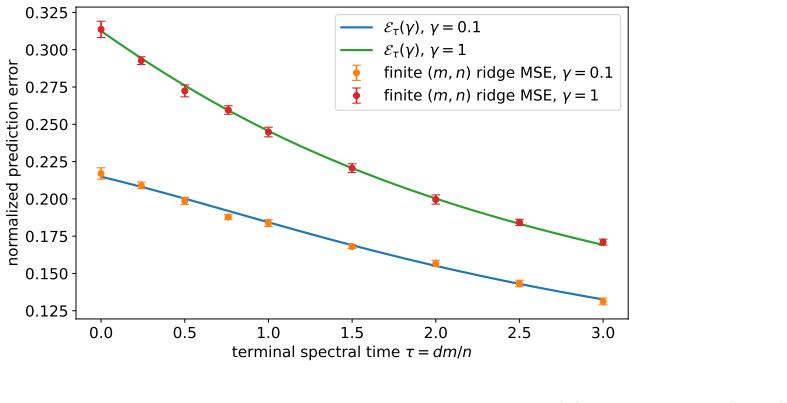
- The limiting law predicts toy random-feature regression risk in close agreement with finite-dimensional simulations.
Where Pith is reading between the lines
- The same double-limit procedure could be applied to products involving nonlinear activations to obtain analogous limiting spectral laws.
- The Burgers-equation description may connect to other free-probability limits arising from different matrix product constructions.
- The regression-risk prediction indicates that the free log-normal law can serve as an input for analyzing generalization in high-dimensional random-feature models beyond the toy linear case.
Load-bearing premise
The second sequential mean-field limit dm/n to a constant exists and allows the T-transform of the spectrum to satisfy the stated Burgers equation.
What would settle it
A large-scale numerical simulation of the non-square matrix product with dm/n held fixed, followed by direct comparison of the empirical T-transform against the Burgers-equation solution or the explicit free log-normal density.
Figures
read the original abstract
We study the squared singular value spectrum of a product of non-square random matrices, a setting that also corresponds to the feature covariance eigenvalues of a deep linear neural network at initialization. We first take a proportional depth-width $d,n$ limit with the number of data points $m$ held fixed, and show that the resulting covariance eigenvalue process satisfies a geometric version of Dyson Brownian motion. We then take a second, sequential mean-field limit corresponding to the scaling $dm/n\to\bar\tau$, and show that the limiting $T$-transform of the spectrum solves a Burgers equation. In the identity-start case this equation yields the free log-normal law, and the general limit is obtained by free multiplicative convolution with the free log-normal. We further obtain the free log-normal support formula, a fixed-point iteration for numerical evaluation, and a formal small-time Marchenko--Pastur approximation. We also use the limiting spectral law to predict a toy random-feature regression risk, finding close agreement with a finite-dimensional simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the squared singular values of a non-square product of random matrices satisfy a geometric Dyson Brownian motion under the proportional limit d, n → ∞ with m fixed. A subsequent sequential mean-field limit dm/n → τ-bar produces a deterministic Burgers equation for the T-transform of the empirical spectral measure. In the identity-initial case this recovers the free log-normal law by free multiplicative convolution; the general case follows by convolution with the free log-normal. The paper also supplies an explicit support formula, a fixed-point iteration for numerical evaluation, a formal small-time Marchenko-Pastur approximation, and a toy random-feature regression risk prediction that matches finite-dimensional simulations.
Significance. If the derivations hold, the work supplies a rigorous bridge between geometric Dyson processes, free probability, and high-dimensional covariance spectra arising in deep linear networks. The explicit Burgers equation, its closed-form solution in the identity case, and the free-multiplicative-convolution representation are technically valuable. Credit is due for the Itô-calculus-plus-mean-field-closure route to the PDE, the parameter-free character of the limiting law, the consistency of the small-time approximation with the PDE, and the direct simulation check on the regression risk. The sequential limits are handled without evident circularity or unjustified interchange.
minor comments (3)
- [§2] §2 (definition of geometric DBM): the Itô correction term arising from the squared-singular-value map should be written explicitly alongside the standard Dyson drift to make the geometric character immediate.
- [Introduction] Introduction, paragraph 3: the T-transform is introduced without a one-line recall of its relation to the Stieltjes transform; a parenthetical reference to the free-probability literature would improve readability.
- [Figure 1] Figure 1 caption: the plotted support boundaries are obtained from the fixed-point iteration; a brief sentence confirming that the iteration converges for the displayed parameter values would strengthen the figure.
Simulated Author's Rebuttal
We thank the referee for the careful reading, accurate summary of our contributions, and the recommendation for minor revision. The positive assessment of the technical value of the Burgers equation, free-multiplicative-convolution representation, and simulation checks is appreciated. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The derivation begins with Itô calculus applied to the squared singular values of the non-square matrix product under the first proportional limit (d,n→∞, m fixed), yielding geometric Dyson Brownian motion. A subsequent sequential mean-field limit dm/n→τ-bar produces a deterministic Burgers equation for the T-transform of the empirical spectral measure. In the identity-initial case the PDE is solved explicitly to recover the free log-normal law, with the general case obtained by free multiplicative convolution; neither the Burgers equation nor the free log-normal is presupposed or fitted to the target quantity. No load-bearing self-citation, ansatz smuggled via prior work, or renaming of a known result occurs; all steps are obtained from the model equations and standard free-probability operations without reducing to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Products of Many Large Random Matrices and Gradients in Deep Neural Networks
B. Hanin and M. Nica. “Products of Many Large Random Matrices and Gradients in Deep Neural Networks.” In:Communications in Mathematical Physics376.1 (2020), pp. 287–322. doi:10.1007/s00220-019-03624-z
-
[2]
Finite Depth and Width Corrections to the Neural Tangent Kernel
B. Hanin and M. Nica. “Finite Depth and Width Corrections to the Neural Tangent Kernel.” International Conference on Learning Representations. 2020.url:https://openreview.net/ forum?id=SJgndT4KwB
2020
-
[3]
A random matrix approach to neural networks
C. Louart, Z. Liao, and R. Couillet. “A random matrix approach to neural networks.” In:The Annals of Applied Probability28.2 (2018), pp. 1190–1248
2018
-
[4]
The generalization error of random features regression: Precise asymptotics and the double descent curve
S. Mei and A. Montanari. “The generalization error of random features regression: Precise asymptotics and the double descent curve.” In:Communications on Pure and Applied Mathe- matics75.4 (2022), pp. 667–766
2022
-
[5]
Deterministic equivalent and error universality of deep random features learning
D. Schröder, H. Cui, D. Dmitriev, and B. Loureiro. “Deterministic equivalent and error universality of deep random features learning.”International Conference on Machine Learning. PMLR. 2023, pp. 30285–30320. 21
2023
-
[6]
Precise asymptotic analysis of deep random feature models
D. Bosch, A. Panahi, and B. Hassibi. “Precise asymptotic analysis of deep random feature models.”The Thirty Sixth Annual Conference on Learning Theory. PMLR. 2023, pp. 4132– 4179
2023
-
[7]
Linearized Two-Layers Neural Networks in High Dimension
B. Ghorbani, S. Mei, T. Misiakiewicz, and A. Montanari. “Linearized Two-Layers Neural Networks in High Dimension.” In:The Annals of Statistics49.2 (2021), pp. 1029–1054.doi: 10.1214/20-AOS1990
-
[8]
Precise learning curves and higher-order scalings for dot-product kernel regression
L. Xiao, H. Hu, T. Misiakiewicz, Y. Lu, and J. Pennington. “Precise learning curves and higher-order scalings for dot-product kernel regression.” In:Advances in Neural Information Processing Systems35 (2022), pp. 4558–4570
2022
-
[9]
The neural covariance SDE: Shaped infinite depth-and-width networks at initialization
M. Li, M. Nica, and D. Roy. “The neural covariance SDE: Shaped infinite depth-and-width networks at initialization.” In:Advances in Neural Information Processing Systems35 (2022), pp. 10795–10808
2022
-
[10]
Potters and J.-P
M. Potters and J.-P. Bouchaud.A First Course in Random Matrix Theory: For Physicists, Engineers and Data Scientists. Cambridge University Press, 2020
2020
-
[11]
Brownian motions of ellipsoids
J. Norris, L. Rogers, and D. Williams. “Brownian motions of ellipsoids.” In:Transactions of the American Mathematical Society294.2 (1986), pp. 757–765
1986
-
[12]
Diffusions of perturbed principal component analysis
M.-F. Bru. “Diffusions of perturbed principal component analysis.” In:Journal of multivariate analysis29.1 (1989), pp. 127–136
1989
-
[13]
Multidimensional Yamada-Watanabe theorem and its applications to particle systems
P. Graczyk and J. Małecki. “Multidimensional Yamada-Watanabe theorem and its applications to particle systems.” In:Journal of Mathematical Physics54.2 (2013), p. 021503
2013
-
[14]
G. Menon and T. Yu. “Siegel Brownian motion.” In:arXiv preprint arXiv:2309.04299(2023)
-
[15]
Lévy-Hinčin type theorems for multiplicative and additive free convolution
H. Bercovici and D.-V. Voiculescu. “Lévy-Hinčin type theorems for multiplicative and additive free convolution.” In:Pacific journal of mathematics153.2 (1992), pp. 217–248
1992
-
[16]
M. Auer. “Free Positive Multiplicative Brownian Motion and the Free Additive Convolution of Semicircle and Uniform Distributions.” In:Journal of Theoretical Probability39, 51 (2026). doi:10.1007/s10959-026-01515-3
-
[17]
An explicit formula for free multiplicative Brownian motions via spherical functions
M. Auer and M. Voit. “An explicit formula for free multiplicative Brownian motions via spherical functions.” In:Indagationes Mathematicae36.6 (2025), pp. 1695–1716.doi:10.1016/ j.indag.2025.03.010
2025
-
[18]
R. M. Neal.Bayesian Learning for Neural Networks. Vol. 118. Lecture Notes in Statistics. Springer New York, 1996.doi:10.1007/978-1-4612-0745-0
-
[19]
Deep Neural Networks as Gaussian Processes
J. Lee, Y. Bahri, R. Novak, S. S. Schoenholz, J. Pennington, and J. Sohl-Dickstein. “Deep Neural Networks as Gaussian Processes.”Int. Conf. Learning Representations (ICLR). 2018
2018
-
[20]
Gradient descent finds global minima of deep neural networks
S. Du, J. Lee, H. Li, L. Wang, and X. Zhai. “Gradient descent finds global minima of deep neural networks.”Int. Conf. Machine Learning (ICML). PMLR. 2019, pp. 1675–1685
2019
-
[21]
Aconvergencetheoryfordeeplearningviaover-parameterization
Z.Allen-Zhu,Y.Li,andZ.Song.“Aconvergencetheoryfordeeplearningviaover-parameterization.” Int. Conf. Machine Learning (ICML). PMLR. 2019, pp. 242–252
2019
-
[22]
Gradient descent optimizes over-parameterized deep ReLU networks
D. Zou, Y. Cao, D. Zhou, and Q. Gu. “Gradient descent optimizes over-parameterized deep ReLU networks.” In:Machine Learning109.3 (2020), pp. 467–492
2020
-
[23]
On Lazy Training in Differentiable Programming
L. Chizat, E. Oyallon, and F. Bach. “On Lazy Training in Differentiable Programming.” In: Advances in Neural Information Processing Systems32 (2019), pp. 2937–2947
2019
- [24]
-
[25]
G. Yang.Scaling limits of wide neural networks with weight sharing: Gaussian process behavior, gradient independence, and neural tangent kernel derivation. 2019. arXiv:1902.04760
-
[26]
Yang.Tensor programs ii: Neural tangent kernel for any architecture
G. Yang.Tensor programs ii: Neural tangent kernel for any architecture. 2020. arXiv:2006. 14548. 22
2020
-
[27]
On exact computation with an infinitely wide neural net
S. Arora, S. S. Du, W. Hu, Z. Li, R. Salakhutdinov, and R. Wang. “On exact computation with an infinitely wide neural net.”Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019, pp. 8141–8150
2019
-
[28]
How Much Over-parameterization Is Sufficient to Learn Deep Re{LU} Networks?
Z. Chen, Y. Cao, D. Zou, and Q. Gu. “How Much Over-parameterization Is Sufficient to Learn Deep Re{LU} Networks?”International Conference on Learning Representations. 2021.url: https://openreview.net/forum?id=fgd7we_uZa6
2021
-
[29]
Z. Ji and M. Telgarsky. “Polylogarithmic width suffices for gradient descent to achieve arbitrarily small test error with shallow ReLU networks.” In:arXiv preprint arXiv:1909.12292(2019)
-
[30]
Generalization of Two-Layer Neural Networks: An Asymptotic Viewpoint
J. Ba, M. A. Erdogdu, T. Suzuki, D. Wu, and T. Zhang. “Generalization of Two-Layer Neural Networks: An Asymptotic Viewpoint.”International Conference on Learning Representations. 2020.url:https://openreview.net/forum?id=H1gBsgBYwH
2020
-
[31]
Deep learning: a statistical viewpoint
P. L. Bartlett, A. Montanari, and A. Rakhlin. “Deep learning: a statistical viewpoint.” In:Acta numerica30 (2021), pp. 87–201
2021
-
[32]
Quantitative Gaussian Approximation of Randomly Initialized Deep Neural Networks
A. Basteri and D. Trevisan. “Quantitative Gaussian Approximation of Randomly Initialized Deep Neural Networks.” In:Machine Learning113.9 (2024), pp. 6373–6393.doi:10.1007/ s10994-024-06578-z. arXiv:2203.07379 [cs.LG]
-
[33]
Non-asymptotic Approximations of Gaussian Neural Networks via Second-Order Poincaré Inequalities
A. Bordino, S. Favaro, and S. Fortini. “Non-asymptotic Approximations of Gaussian Neural Networks via Second-Order Poincaré Inequalities.”Proceedings of the 6th Symposium on Advances in Approximate Bayesian Inference. Vol. 253. Proceedings of Machine Learning Research. PMLR, 2024, pp. 45–78. arXiv:2304.04010 [stat.ML]
-
[34]
Trevisan.Wide Deep Neural Networks with Gaussian Weights are Very Close to Gaussian Processes
D. Trevisan.Wide Deep Neural Networks with Gaussian Weights are Very Close to Gaussian Processes. 2023. arXiv:2312.11737 [math.ST]
-
[35]
Normal Approximation of Random Gaussian Neural Networks
N. Apollonio, D. De Canditiis, G. Franzina, P. Stolfi, and G. L. Torrisi. “Normal Approximation of Random Gaussian Neural Networks.” In:Stochastic Systems15.1 (2024), pp. 88–110.doi: 10.1287/stsy.2023.0033. arXiv:2307.04486 [math.PR]
-
[36]
Quantitative CLTs in Deep Neural Networks
S. Favaro, B. Hanin, D. Marinucci, I. Nourdin, and G. Peccati. “Quantitative CLTs in Deep Neural Networks.” In:Probability Theory and Related Fields191.3–4 (2025), pp. 933–977.doi: 10.1007/s00440-025-01360-1. arXiv:2307.06092 [cs.LG]
-
[37]
L. Celli and G. Peccati.Entropic Bounds for Conditionally Gaussian Vectors and Applications to Neural Networks. 2025. arXiv:2504.08335 [math.PR]
-
[38]
K. Balasubramanian, L. Goldstein, N. Ross, and A. Salim. “Gaussian Random Field Approxima- tion via Stein’s Method with Applications to Wide Random Neural Networks.” In:Applied and Computational Harmonic Analysis72 (2024), p. 101668.doi: 10.1016/j.acha.2024.101668. arXiv:2306.16308 [math.PR]
-
[39]
K. Balasubramanian and N. Ross.Finite-Dimensional Gaussian Approximation for Deep Neural Networks: Universality in Random Weights. To appear in Bernoulli. 2026. arXiv:2507.12686 [stat.ML]
-
[40]
L. Celli.Wide Neural Networks with General Weights: Convergence Rate and Explicit Depen- dence on the Hyper-Parameters. 2026. arXiv:2601.21539 [math.PR]
-
[41]
Universality in Deep Neural Networks: An approach via the Lindeberg exchange principle
F. Giovagnini, S. Kotitsas, and M. Romito.Universality in Deep Neural Networks: An Approach via the Lindeberg Exchange Principle. 2026. arXiv:2605.02771 [math.PR]
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [42]
-
[43]
On the Global Convergence of Gradient Descent for Over-parameterized Models using Optimal Transport
L. Chizat and F. Bach.On the Global Convergence of Gradient Descent for Over-parameterized Models using Optimal Transport. 2018. arXiv:1805.09545
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
J. Sirignano and K. Spiliopoulos.Mean Field Analysis of Neural Networks: A Law of Large Numbers. 2018. arXiv:1805.01053. 23
-
[45]
A mean field view of the landscape of two-layer neural networks
S. Mei, A. Montanari, and P.-M. Nguyen. “A mean field view of the landscape of two-layer neural networks.” In:Proceedings of the National Academy of Sciences115.33 (2018), E7665– E7671.issn: 0027-8424.doi: 10.1073/pnas.1806579115. eprint: https://www.pnas.org/ content/115/33/E7665.full.pdf
-
[46]
Feature Learning in Infinite-Width Neural Networks
G. Yang and E. J. Hu. “Feature Learning in Infinite-Width Neural Networks.”Int. Conf. Machine Learning (ICML). 2021. arXiv:2011.14522
-
[47]
arXiv preprint arXiv:2203.03466 , year=
G. Yang, E. J. Hu, I. Babuschkin, S. Sidor, X. Liu, D. Farhi, N. Ryder, J. Pachocki, W. Chen, and J. Gao. “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.” In:arXiv preprint arXiv:2203.03466(2022)
-
[48]
Self-consistent dynamical field theory of kernel evolution in wide neural networks
B. Bordelon and C. Pehlevan. “Self-consistent dynamical field theory of kernel evolution in wide neural networks.” In:Advances in Neural Information Processing Systems35 (2022), pp. 32240–32256
2022
-
[49]
The future is log-Gaussian: ResNets and their infinite-depth- and-width limit at initialization
M. Li, M. Nica, and D. Roy. “The future is log-Gaussian: ResNets and their infinite-depth- and-width limit at initialization.” In:Advances in Neural Information Processing Systems34 (2021)
2021
-
[50]
Neural Tangent Kernel Beyond the Infinite-Width Limit: Ef- fects of Depth and Initialization
M. Seleznova and G. Kutyniok. “Neural Tangent Kernel Beyond the Infinite-Width Limit: Ef- fects of Depth and Initialization.”Proceedings of the 39th International Conference on Machine Learning. Vol. 162. Proceedings of Machine Learning Research. PMLR, 2022, pp. 19522–19560. url:https://proceedings.mlr.press/v162/seleznova22a.html
2022
-
[51]
Differential Equation Scaling Limits of Shaped and Unshaped Neural Networks
M. B. Li and M. Nica. “Differential Equation Scaling Limits of Shaped and Unshaped Neural Networks.” In:Transactions on Machine Learning Research(2024)
2024
-
[52]
The Shaped Transformer: Attention Models in the Infinite Depth-and-Width Limit
L. Noci, C. Li, M. B. Li, B. He, T. Hofmann, C. J. Maddison, and D. M. Roy. “The Shaped Transformer: Attention Models in the Infinite Depth-and-Width Limit.”Advances in Neu- ral Information Processing Systems. Vol. 36. 2023.url:https://proceedings.neurips. cc / paper _ files / paper / 2023 / hash / aa31dc84098add7dd2ffdd20646f2043 - Abstract - Conference.html
2023
-
[53]
Stable ResNet
S. Hayou, E. Clerico, B. He, G. Deligiannidis, A. Doucet, and J. Rousseau. “Stable ResNet.” Int. Conf. Artificial Intelligence and Statistics (AISTATS). PMLR. 2021, pp. 1324–1332
2021
-
[54]
Commutative Scaling of Width and Depth in Deep Neural Networks
S. Hayou. “Commutative Scaling of Width and Depth in Deep Neural Networks.” In:Journal of Machine Learning Research25.299 (2024), pp. 1–41.url:https://www.jmlr.org/papers/ v25/23-1163.html
2024
-
[55]
Width and depth limits commute in residual networks
S. Hayou and G. Yang. “Width and depth limits commute in residual networks.”International Conference on Machine Learning. PMLR. 2023, pp. 12700–12723
2023
-
[56]
Depthwise Hyperparameter Transfer in Residual Networks: Dynamics and Scaling Limit
B. Bordelon, L. Noci, M. B. Li, B. Hanin, and C. Pehlevan. “Depthwise Hyperparameter Transfer in Residual Networks: Dynamics and Scaling Limit.”The Twelfth International Conference on Learning Representations. 2024
2024
-
[57]
Tensor Programs VI: Feature Learning in Infinite Depth Neural Networks
G. Yang, D. Yu, C. Zhu, and S. Hayou. “Tensor Programs VI: Feature Learning in Infinite Depth Neural Networks.”The Twelfth International Conference on Learning Representations. 2024
2024
-
[58]
Bayesian interpolation with deep linear networks
B. Hanin and A. Zlokapa. “Bayesian interpolation with deep linear networks.” In:Proceedings of the National Academy of Sciences120.23 (2023), e2301345120
2023
-
[59]
arXiv preprint arXiv:2405.16630 , year=
B. Hanin and A. Zlokapa. “Bayesian Inference with Deep Weakly Nonlinear Networks.” In: arXiv preprint arXiv:2405.16630(2024)
-
[60]
Proportional infinite-width infinite-depth limit for deep linear neural networks
F. Bassetti, L. Ladelli, and P. Rotondo. “Proportional infinite-width infinite-depth limit for deep linear neural networks.” In:arXiv preprint arXiv:2411.15267(2024)
-
[61]
Bayesian Inference with Shaped Deep Non-linear MLPs
B. Hanin and T. Jiang.Bayesian Inference with Shaped Deep Non-linear MLPs. 2026.doi: 10.48550/arXiv.2605.30860. arXiv:2605.30860 [math.ST]. 24
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.30860 2026
-
[62]
Nonlinear random matrix theory for deep learning
J. Pennington and P. Worah. “Nonlinear random matrix theory for deep learning.” In:Advances in neural information processing systems30 (2017)
2017
-
[63]
A Note on the Pennington–Worah Distribution
S. Péché. “A Note on the Pennington–Worah Distribution.” In:Electronic Communications in Probability24 (2019). Paper No. 66, pp. 1–7.doi:10.1214/19-ECP262
-
[64]
Spectra of the conjugate kernel and neural tangent kernel for linear- width neural networks
Z. Fan and Z. Wang. “Spectra of the conjugate kernel and neural tangent kernel for linear- width neural networks.” In:Advances in neural information processing systems33 (2020), pp. 7710–7721
2020
-
[65]
arXiv preprint arXiv:2402.10127 , year=
Z. Wang, D. Wu, and Z. Fan. “Nonlinear spiked covariance matrices and signal propagation in deep neural networks.” In:arXiv preprint arXiv:2402.10127(2024)
-
[66]
Universality of kernel random matrices and kernel regression in the quadratic regime
P. Pandit, Z. Wang, and Y. Zhu. “Universality of kernel random matrices and kernel regression in the quadratic regime.” In:arXiv preprint arXiv:2408.01062(2024)
-
[67]
Lyapunov exponent, universality and phase transition for products of random matrices
D.-Z. Liu, D. Wang, and Y. Wang. “Lyapunov exponent, universality and phase transition for products of random matrices.” In:Communications in Mathematical Physics399 (2023), pp. 1811–1855.doi:10.1007/s00220-022-04584-7
-
[68]
Phase transitions for infinite products of large non-Hermitian random matrices
D.-Z. Liu and Y. Wang. “Phase transitions for infinite products of large non-Hermitian random matrices.”Annales de l’Institut Henri Poincare (B) Probabilites et statistiques. Vol. 60. 4. Institut Henri Poincaré. 2024, pp. 2813–2848
2024
-
[69]
Gaussian fluctuations for products of random matrices
V. Gorin and Y. Sun. “Gaussian fluctuations for products of random matrices.” In:American Journal of Mathematics144.2 (2022), pp. 287–393
2022
-
[70]
Fluctuations ofβ-Jacobi product processes
A. Ahn. “Fluctuations ofβ-Jacobi product processes.” In:Probability Theory and Related Fields183.1 (2022), pp. 57–123
2022
-
[71]
Non-asymptotic results for singular values of Gaussian matrix products
B. Hanin and G. Paouris. “Non-asymptotic results for singular values of Gaussian matrix products.” In:Geometric and Functional Analysis31.2 (2021), pp. 268–324
2021
-
[72]
Universal microscopic correlation functions for products of independent Ginibre matrices
G. Akemann and Z. Burda. “Universal microscopic correlation functions for products of independent Ginibre matrices.” In:Journal of Physics A: Mathematical and Theoretical45.46 (2012), p. 465201
2012
-
[73]
Universal distribution of Lyapunov exponents for products of Ginibre matrices
G. Akemann, Z. Burda, and M. Kieburg. “Universal distribution of Lyapunov exponents for products of Ginibre matrices.” In:Journal of Physics A: Mathematical and Theoretical47.39 (2014), p. 395202
2014
-
[74]
Recent exact and asymptotic results for products of independent random matrices
G. Akemann and J. R. Ipsen. “Recent exact and asymptotic results for products of independent random matrices.” In:Acta Physica Polonica B46.9 (2015), pp. 1747–1784.doi:10.5506/ APhysPolB.46.1747
2015
-
[75]
From integrable to chaotic systems: Universal local statistics of Lyapunov exponents
G. Akemann, Z. Burda, and M. Kieburg. “From integrable to chaotic systems: Universal local statistics of Lyapunov exponents.” In:Europhysics Letters126.4 (2019), p. 40001
2019
-
[76]
Universal microscopic correlation functions for products of truncated unitary matrices
G. Akemann, Z. Burda, M. Kieburg, and T. Nagao. “Universal microscopic correlation functions for products of truncated unitary matrices.” In:Journal of Physics A: Mathematical and Theoretical47.25 (2014), p. 255202
2014
-
[77]
Tao.Topics in random matrix theory
T. Tao.Topics in random matrix theory. Vol. 132. American Mathematical Soc., 2012
2012
-
[78]
Bloemendal.Doob’s h-transform: Theory and Examples
A. Bloemendal.Doob’s h-transform: Theory and Examples. Lecture notes. 2010
2010
-
[79]
G. W. Anderson, A. Guionnet, and O. Zeitouni.An introduction to random matrices. 118. Cambridge university press, 2010
2010
-
[80]
Lower bounds for the density of locally elliptic Itô processes
V. Bally. “Lower bounds for the density of locally elliptic Itô processes.” In:The Annals of Probability34.6 (2006), pp. 2406–2440
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.