Histogram-constrained Image Generation
Pith reviewed 2026-07-01 05:49 UTC · model grok-4.3
The pith
Histogram-constrained Image Generation enforces exact user-specified distributional constraints on diffusion models by applying optimal transport guidance at each sampling step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling control as an optimal transport problem, the framework applies explicit guidance transformations during the diffusion sampling process to drive trajectories toward user-specified histograms, achieving exact precision in distributional constraints while maintaining sample coherence.
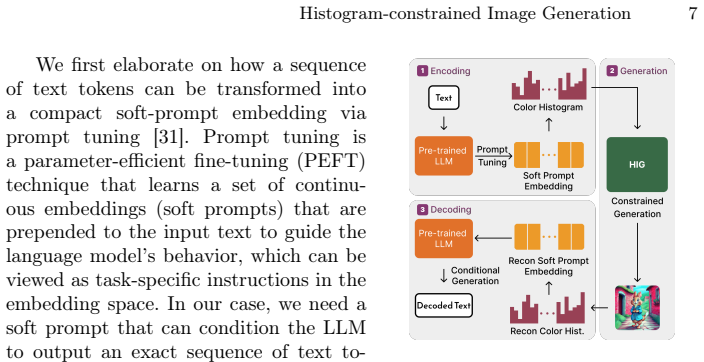
What carries the argument
Optimal transport guidance transformations applied at each diffusion step to enforce exact histogram matching.
Load-bearing premise
Explicit optimal-transport guidance transformations can be applied at each diffusion step to achieve exact histogram matching while preserving image coherence and sample quality.
What would settle it
Running the guided sampler on a target histogram and verifying that the final image histogram deviates from the target by more than numerical tolerance, or that perceptual quality metrics fall below the unconstrained baseline.
Figures













read the original abstract
Diffusion models have emerged as a dominant paradigm in generative modeling, enabling high-fidelity sampling from complex data distributions. Despite impressive capabilities, controlling diffusion models to produce outputs aligned with user intent remains an open challenge, especially when balancing global coherence with local precision. Existing control mechanisms vary in the granularity of their conditioning signals. For example, textual prompts guide generation globally through high-level semantics, while ControlNet-like approaches secure precise local structure via dense conditions. In this work, we introduce Histogram-constrained Image Generation (HIG), a novel control mechanism that falls into the middle ground of control granularity. Our framework enforces user-specified distributional constraints (e.g., color histograms or latent token distributions) during the generation process with exact precision. We model such control as an optimal transport (OT) problem and apply explicit guidance transformations during sampling, thereby driving the diffusion trajectory to align with the desired histogram. We demonstrate the versatility of HIG across diverse applications, including constrained generation via color/latent histograms and high-capacity information embedding through histogram-level encoding. Our findings underscore the promise of distributional control, a flexible and interpretable control scheme that is fully compatible with existing control mechanisms, diversifying the hybrid strategies for controllable image generation. Our project page is available at: https://maps-research.github.io/hig/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Histogram-constrained Image Generation (HIG), a control mechanism for diffusion models that enforces user-specified distributional constraints (e.g., color histograms or latent token distributions) with exact precision. Control is modeled as an optimal transport (OT) problem, with explicit guidance transformations applied during sampling to align the diffusion trajectory to the target histogram. The approach is positioned as a middle-granularity control compatible with existing methods and is demonstrated on constrained generation and high-capacity information embedding tasks.
Significance. If the exact histogram matching is achieved without degrading sample quality or coherence, HIG would provide a flexible, interpretable distributional control primitive that complements global (text) and local (dense) conditioning, enabling new hybrid strategies. The OT framing and claimed exactness are the core novelties.
major comments (1)
- [Abstract] Abstract: the central claim of 'exact precision' in histogram alignment is presented as following directly from the OT modeling and guidance transformations, yet no derivation, algorithm, or proof sketch is supplied to show how the per-step transformations preserve the diffusion marginals or avoid introducing artifacts; this is load-bearing for the 'exact' qualifier.
minor comments (2)
- [Abstract] Abstract: the phrase 'middle ground of control granularity' is used without a quantitative comparison (e.g., bits of control or spatial scale) to textual prompts or ControlNet-style methods.
- [Abstract] Abstract: the project page URL is given but no quantitative results, ablation tables, or failure cases are referenced in the text itself.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying a point that bears on the central claim of exactness. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'exact precision' in histogram alignment is presented as following directly from the OT modeling and guidance transformations, yet no derivation, algorithm, or proof sketch is supplied to show how the per-step transformations preserve the diffusion marginals or avoid introducing artifacts; this is load-bearing for the 'exact' qualifier.
Authors: The abstract is a high-level summary; the derivation that the per-step OT guidance map is the closed-form solution to the Wasserstein problem between the current empirical distribution and the target histogram, and that this map can be applied without changing the diffusion marginals outside the controlled dimensions, appears in Section 3.2 together with the explicit algorithm. We nevertheless agree that the abstract would be strengthened by a short clause indicating that the guidance is constructed to preserve the diffusion process marginals. We will revise the abstract accordingly in the next version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents HIG as a modeling choice that frames distributional control as an OT problem and applies explicit guidance transformations at sampling time. No equations, fitted parameters, or self-citations are shown that would reduce the claimed exact histogram alignment to a self-referential definition or input-by-construction. The abstract and description treat the OT formulation as an independent modeling decision whose validity rests on external validation rather than internal reduction. This is the common case of a self-contained proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimal transport provides a well-defined way to transform one distribution into another that can be applied step-wise during diffusion sampling.
Reference graph
Works this paper leans on
-
[1]
Naval Research Logistics Quarterly8(1), 41–54 (1961) 6
Balinski, M.L.: Fixed-cost transportation problems. Naval Research Logistics Quarterly8(1), 41–54 (1961) 6
1961
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bansal, A., Chu, H.M., Schwarzschild, A., Sengupta, S., Goldblum, M., Geiping, J., Goldstein, T.: Universal guidance for diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 843–852 (2023) 14
2023
-
[3]
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation (2024) 13
2024
-
[4]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=FsdB3I9Y2414
Christopher, J.K., Baek, S., Fioretto, F.: Constrained synthesis with projected diffusion models. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=FsdB3I9Y2414
2024
-
[5]
In: The Eleventh International Con- ference on Learning Representations (2023),https://openreview.net/forum?id= OnD9zGAGT0k14
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sampling for general noisy inverse problems. In: The Eleventh International Con- ference on Learning Representations (2023),https://openreview.net/forum?id= OnD9zGAGT0k14
2023
-
[6]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Chung, H., Sim, B., Ryu, D., Ye, J.C.: Improving diffusion models for inverse problems using manifold constraints. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022),https: //openreview.net/forum?id=nJJjv0JDJju14
2022
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chung, J., Hyun, S., Heo, J.P.: Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8795– 8805 (2024) 8, 13
2024
-
[8]
Ad- vances in neural information processing systems26(2013) 6
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. Ad- vances in neural information processing systems26(2013) 6
2013
-
[9]
Advances in neural information processing systems34, 8780–8794 (2021) 1
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021) 1
2021
-
[10]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=tplXNcHZs114
Dou, Z., Song, Y.: Diffusion posterior sampling for linear inverse problem solv- ing: A filtering perspective. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=tplXNcHZs114
2024
-
[11]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
In: Forty-first International Conference on Machine Learning (2024) 1, 13
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high- resolution image synthesis. In: Forty-first International Conference on Machine Learning (2024) 1, 13
2024
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021) 3, 12
2021
-
[14]
Transactions on Machine Learning Research (2023),https://openreview.net/forum?id=xuWTFQ4VGO, expert Certification 14
Fishman, N., Klarner, L., Bortoli, V.D., Mathieu, E., Hutchinson, M.J.: Diffu- sion models for constrained domains. Transactions on Machine Learning Research (2023),https://openreview.net/forum?id=xuWTFQ4VGO, expert Certification 14
2023
-
[15]
arXiv preprint arXiv:2407.01414 (2024) 8, 13
Gao, J., Liu, Y., Sun, Y., Tang, Y., Zeng, Y., Chen, K., Zhao, C.: Styleshot: A snapshot on any style. arXiv preprint arXiv:2407.01414 (2024) 8, 13
-
[16]
Gao, Y., Gong, L., Guo, Q., Hou, X., Lai, Z., Li, F., Li, L., Lian, X., Liao, C., Liu, L., et al.: Seedream 3.0 technical report. arXiv preprint arXiv:2504.11346 (2025) 13 Histogram-constrained Image Generation 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Advances in Neural Information Processing Systems38, 73343–73384 (2026) 14
Guo, Y., Yang, Y., Yuan, H., Wang, M.: Training-free guidance beyond differ- entiability: Scalable path steering with tree search in diffusion and flow models. Advances in Neural Information Processing Systems38, 73343–73384 (2026) 14
2026
-
[18]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=o3BxOLoxm18, 14
He, Y., Murata, N., Lai, C.H., Takida, Y., Uesaka, T., Kim, D., Liao, W.H., Mit- sufuji, Y., Kolter, J.Z., Salakhutdinov, R., Ermon, S.: Manifold preserving guided diffusion. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=o3BxOLoxm18, 14
2024
-
[19]
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- freeevaluationmetricforimagecaptioning.arXivpreprintarXiv:2104.08718(2021) 9
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020) 1, 3
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 1, 3
2020
-
[21]
In: International Conference on Learning Representations (2022) 1, 2, 13
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022) 1, 2, 13
2022
-
[22]
In: Proceedings of the 41st International Conference on Machine Learning
Huang,Y.,Ghatare,A.,Liu,Y.,Hu,Z.,Zhang,Q.,Sastry,C.S.,Gururani,S.,Oore, S.,Yue,Y.:Symbolicmusicgenerationwithnon-differentiableruleguideddiffusion. In: Proceedings of the 41st International Conference on Machine Learning. pp. 19772–19797 (2024) 14
2024
-
[23]
Advances in neural information processing systems35, 26565–26577 (2022) 13
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. Advances in neural information processing systems35, 26565–26577 (2022) 13
2022
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Karras, T., Aittala, M., Lehtinen, J., Hellsten, J., Aila, T., Laine, S.: Analyzing and improving the training dynamics of diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24174– 24184 (2024) 13
2024
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ke, Z., Liu, Y., Zhu, L., Zhao, N., Lau, R.W.: Neural preset for color style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14173–14182 (2023) 13
2023
-
[26]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013) 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[27]
Labs, B.F.: Flux (2023),https://github.com/black-forest-labs/flux1, 8, 13, 24
2023
-
[28]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025) 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Larchenko, M., Lobashev, A., Guskov, D., Palyulin, V.V.: Color transfer with mod- ulated flows. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4464–4472 (2025) 13
2025
-
[30]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Laria, H., Gomez-Villa, A., Qin, J., Butt, M.A., Raducanu, B., Vazquez-Corral, J., van de Weijer, J., Wang, K.: Leveraging semantic attribute binding for free- lunch color control in diffusion models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 7689–7698 (2026) 13
2026
-
[31]
In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t. (eds.) Proceed- ings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp.3045–3059.AssociationforComputationalLinguistics,OnlineandPuntaCana, Dominican Republic (Nov 2021) 3, 7, 10 ...
2021
-
[32]
In: European Conference on Computer Vision
Li, M., Yang, T., Kuang, H., Wu, J., Wang, Z., Xiao, X., Chen, C.: Controlnet++: Improving conditional controls with efficient consistency feedback. In: European Conference on Computer Vision. pp. 129–147. Springer (2025) 1, 2, 8, 13, 22
2025
-
[33]
arXiv preprint arXiv:2408.08252 (2024) 14
Li, X., Zhao, Y., Wang, C., Scalia, G., Eraslan, G., Nair, S., Biancalani, T., Ji, S., Regev, A., Levine, S., et al.: Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding. arXiv preprint arXiv:2408.08252 (2024) 14
-
[34]
arXiv preprint arXiv:2402.10855 (2024) 13
Liang, Z., Li, Z., Zhou, S., Li, C., Loy, C.C.: Control color: Multimodal diffusion- based interactive image colorization. arXiv preprint arXiv:2402.10855 (2024) 13
-
[35]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t3, 8, 13
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t3, 8, 13
2023
-
[36]
arXiv preprint arXiv:2412.04465 (2024) 13
Liu, C., Shah, V., Cui, A., Lazebnik, S.: Unziplora: Separating content and style from a single image. arXiv preprint arXiv:2412.04465 (2024) 13
-
[37]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z8, 13
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and trans- fer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z8, 13
2023
-
[38]
Advances in Neural Information Processing Systems38, 164572–164601 (2026) 13
Lobashev, A., Larchenko, M., Guskov, D.: Color conditional generation with sliced wasserstein guidance. Advances in Neural Information Processing Systems38, 164572–164601 (2026) 13
2026
-
[39]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2019) 8
2019
-
[40]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4296–4304 (2024) 13
2024
-
[41]
Naderiparizi, S., Liang, X., Zwartsenberg, B., Wood, F.: Don’t be so negative! score-based generative modeling with oracle-assisted guidance (2024),https:// openreview.net/forum?id=gJ7cHBHfBk14
2024
-
[42]
OpenAI: Introducing 4o image generation (2025),https://openai.com/index/ introducing-4o-image-generation/, accessed: 2025-05-15 8, 13
2025
-
[43]
Scalable Diffusion Models with Transformers
Peebles, W., Xie, S.: Scalable diffusion models with transformers. arXiv preprint arXiv:2212.09748 (2022) 13
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
In: Proceedings of the 31st ACM International Conference on Multimedia
Peng, Y., Hu, D., Wang, Y., Chen, K., Pei, G., Zhang, W.: Stegaddpm: Gen- erative image steganography based on denoising diffusion probabilistic model. In: Proceedings of the 31st ACM International Conference on Multimedia. p. 7143–7151. MM ’23, Association for Computing Machinery, New York, NY, USA (2023).https://doi.org/10.1145/3581783.3612514,https://d...
-
[45]
In: ACM Multimedia 2024 (2024),https://openreview.net/forum?id=kEqGgMgIlu 14
Peng, Y., Wang, Y., Hu, D., Chen, K., Rong, X., Zhang, W.: LDStega: Practical and robust generative image steganography based on latent diffusion models. In: ACM Multimedia 2024 (2024),https://openreview.net/forum?id=kEqGgMgIlu 14
2024
-
[46]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 1, 3, 8, 13, 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Qiu, Q., Mao, J., Wang, X.: Exploring palette based color guidance in diffusion models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10287–10295 (2025) 13 Histogram-constrained Image Generation 19
2025
-
[48]
arXiv preprint arXiv:2412.03069 (2024) 3, 12
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. arXiv preprint arXiv:2412.03069 (2024) 3, 12
-
[49]
Advances in neural information processing systems32(2019) 3
Razavi, A., Van den Oord, A., Vinyals, O.: Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems32(2019) 3
2019
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 1, 3, 13, 14
2022
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22500–22510 (June 2023) 1, 2, 8, 13, 22
2023
-
[52]
Advances in Neural Information Processing Systems35, 25278–25294 (2022) 9
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems35, 25278–25294 (2022) 9
2022
-
[53]
In: European Conference on Computer Vision
Shah, V., Ruiz, N., Cole, F., Lu, E., Lazebnik, S., Li, Y., Jampani, V.: Ziplora: Any subject in any style by effectively merging loras. In: European Conference on Computer Vision. pp. 422–438. Springer (2025) 13
2025
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shum, K.C., Hua, B.S., Nguyen, D.T., Yeung, S.K.: Color alignment in diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28446–28455 (2025) 13
2025
-
[55]
In: International conference on machine learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: International conference on machine learning. pp. 2256–2265. PMLR (2015) 1
2015
-
[56]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conferenceon LearningRepresentations(2021),https://openreview.net/forum? id=St1giarCHLP1, 3, 8
2021
-
[57]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[58]
Su, W., Ni, J., Sun, Y.: Stegastylegan: Towards generic and practical generative image steganography. Proceedings of the AAAI Conference on Artificial Intelli- gence38(1), 240–248 (Mar 2024).https://doi.org/10.1609/aaai.v38i1.27776 14
-
[59]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14940–14950 (2025) 13
2025
-
[60]
Advances in neural information processing systems30(2017) 3, 4
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017) 3, 4
2017
-
[61]
Springer (2009) 2, 4
Villani, C.: Optimal Transport: Old and New. Springer (2009) 2, 4
2009
-
[62]
arXiv preprint arXiv:2407.00788 (2024) 8, 13
Wang, H., Xing, P., Huang, R., Ai, H., Wang, Q., Bai, X.: Instantstyle-plus: Style transfer with content-preserving in text-to-image generation. arXiv preprint arXiv:2407.00788 (2024) 8, 13
-
[63]
arXiv preprint arXiv:2506.05083 (2025) 13
Wang, P., Shi, Y., Lian, X., Zhai, Z., Xia, X., Xiao, X., Huang, W., Yang, J.: Seededit 3.0: Fast and high-quality generative image editing. arXiv preprint arXiv:2506.05083 (2025) 13
-
[64]
Liu et al
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., Han, S.: Sana: Efficient high-resolution image synthesis with linear diffusion transformer (2024) 13 20 H. Liu et al
2024
-
[65]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id= NniXePXVXw14
Xu, Z., xu, D., Li, Z., Zhang, C.: MDDM: Practical message-driven generative image steganography based on diffusion models. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id= NniXePXVXw14
2025
-
[66]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Yan,L.,Li,X.,Zhang,J.,Guan,F.,Peng,K.,Li,P.:F-ddim:Afeaturizeddenoising diffusion implicit model for facial image steganography. In: Proceedings of the 33rd ACM International Conference on Multimedia. p. 8488–8496. MM ’25, Association for Computing Machinery, New York, NY, USA (2025).https://doi.org/10. 1145/3746027.3755517,https://doi.org/10.1145/3746027...
-
[67]
In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence
Yang, Y., Liu, Z., Jia, J., Gao, Z., Li, Y., Sun, W., Liu, X., Zhai, G.: Diffstega: to- wards universal training-free coverless image steganography with diffusion models. In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. pp. 1579–1587 (2024) 14
2024
-
[68]
Advances in Neural Information Processing Systems37, 22370–22417 (2024) 14
Ye, H., Lin, H., Han, J., Xu, M., Liu, S., Liang, Y., Ma, J., Zou, J.Y., Ermon, S.: Tfg: Unified training-free guidance for diffusion models. Advances in Neural Information Processing Systems37, 22370–22417 (2024) 14
2024
-
[69]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023) 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Advances in Neural Information Processing Systems36, 80730–80743 (2023) 14
Yu, J., Zhang, X., Xu, Y., Zhang, J.: Cross: Diffusion model makes controllable, ro- bust and secure image steganography. Advances in Neural Information Processing Systems36, 80730–80743 (2023) 14
2023
-
[71]
Advances in Neural Information Processing Systems37, 128940–128966 (2024) 3, 12
Yu, Q., Weber, M., Deng, X., Shen, X., Cremers, D., Chen, L.C.: An image is worth 32 tokens for reconstruction and generation. Advances in Neural Information Processing Systems37, 128940–128966 (2024) 3, 12
2024
-
[72]
arXiv preprint arXiv:2410.03021 (2024) 8, 13
Zamzam, O.: Pixelshuffler: A simple image translation through pixel rearrange- ment. arXiv preprint arXiv:2410.03021 (2024) 8, 13
-
[73]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3836–3847 (2023) 1, 2, 13
2023
-
[74]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)
Zhang, Y., Huang, N., Tang, F., Huang, H., Ma, C., Dong, W., Xu, C.: Inversion- based style transfer with diffusion models. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). pp. 10146–10156 (June 2023) 8, 13
2023
-
[75]
Zhao, S., Chen, D., Chen, Y.C., Bao, J., Hao, S., Yuan, L., Wong, K.Y.K.: Uni- controlnet:All-in-onecontroltotext-to-imagediffusionmodels.AdvancesinNeural Information Processing Systems36(2024) 13
2024
-
[76]
Zhou, Q., Wei, P., Qian, Z., Zhang, X., Li, S.: Improved generative steganography based on diffusion model. IEEE Transactions on Circuits and Systems for Video Technology35(7), 6494–6507 (2025).https://doi.org/10.1109/TCSVT.2025. 353983214
-
[77]
Zhou, Z., Dong, X., Meng, R., Wang, M., Yan, H., Yu, K., Choo, K.K.R.: Genera- tive steganography via auto-generation of semantic object contours. IEEE Trans- actions on Information Forensics and Security18, 2751–2765 (2023).https: //doi.org/10.1109/TIFS.2023.326884314
-
[78]
an artwork with intricate details, vibrant colors, high resolution, 8k
Zhou, Z., Su, Y., Li, J., Yu, K., Wu, Q.M.J., Fu, Z., Shi, Y.: Secret-to-Image Reversible Transformation for Generative Steganography . IEEE Transactions on Dependable and Secure Computing20(05), 4118–4134 (Sep 2023).https://doi. org/10.1109/TDSC.2022.321766114 Histogram-constrained Image Generation 21 A Pseudocode for HIG Algorithm1Text-to-ImageGeneratio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.