ImProver 2: Iteratively Self-Improving LMs for Neurosymbolic Proof Optimization
Pith reviewed 2026-05-25 06:08 UTC · model grok-4.3
The pith
A 7B model trained via ImProver 2 outperforms much larger models at optimizing Lean 4 proofs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
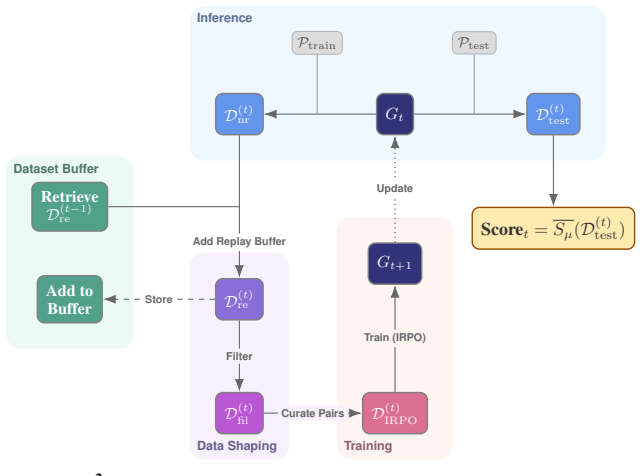
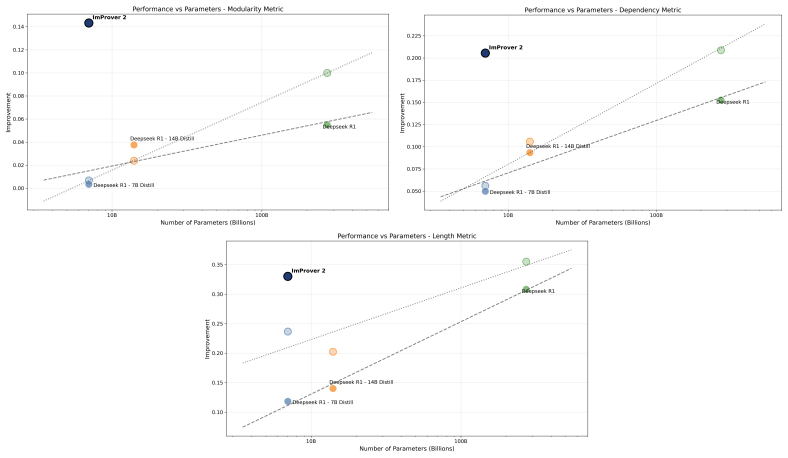
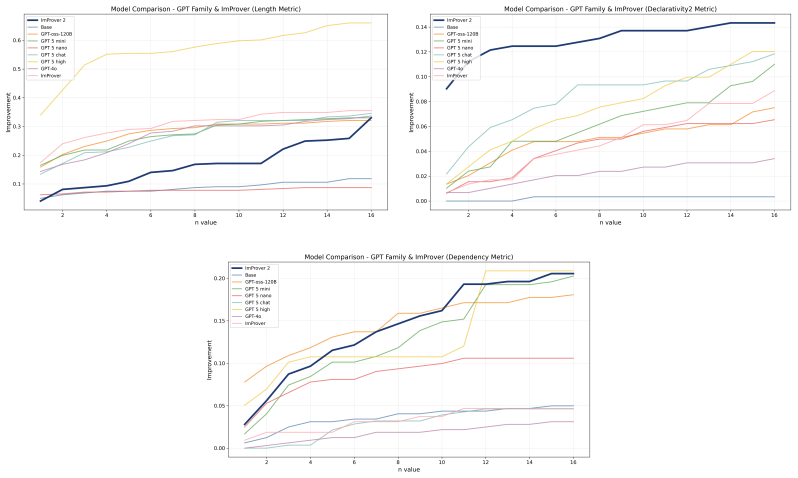
ImProver 2 combines data-efficient expert iteration with a neurosymbolic scaffold to train language models for automated proof optimization in Lean 4. This produces a 7B model that outperforms larger models within its family and competes with mid-tier frontier models on a suite of structural proof metrics. The same scaffold improves results across model scales, establishing that small models can restructure research-level proofs when given appropriate structure and training.
What carries the argument
The neurosymbolic scaffold exposing formal Lean structure alongside lightweight informal abstractions, used inside an expert-iteration pipeline.
If this is right
- Small models can restructure complex, research-level proofs effectively.
- The neurosymbolic scaffold raises performance for both small and frontier-scale models.
- Proof optimization becomes a scalable, learnable task rather than a purely heuristic one.
- Optimized proofs improve both library maintainability and the quality of training data for neural provers.
Where Pith is reading between the lines
- The same scaffold-and-iteration pattern could be tested on proof libraries in other formal systems.
- Iteratively improved proof data might accelerate training of future neural provers beyond the metrics reported here.
- The structural metrics could serve as an automated filter or ranking signal inside existing proof libraries.
Load-bearing premise
The suite of structural proof metrics accurately reflects the goals of maintainability and training-data quality without introducing unmeasured biases or omissions.
What would settle it
Human experts rating the actual maintainability and readability of proofs produced by the 7B model versus the original proofs and versus outputs from larger models.
Figures














read the original abstract
Formal mathematics libraries are rapidly expanding, creating a growing need to refactor verified proofs for maintainability and to improve training data quality for neural provers. However, scalable proof optimization is hindered by heterogeneous and heuristically specified objectives, scarce data, and high training and inference costs. To overcome these challenges, we introduce ImProver 2, a neurosymbolic framework for automated proof optimization in Lean 4. ImProver 2 combines a data-efficient expert-iteration pipeline with a scaffold that exposes formal structure alongside lightweight informal abstractions. We further introduce a suite of metrics capturing structural proof properties. Using ImProver 2, we train a 7B-parameter model that outperforms orders-of-magnitude larger models within the same model family, and is competitive with mid-tier frontier models across metrics. We additionally demonstrate that our neurosymbolic scaffold significantly improves performance across both small and frontier models. We show that with proper scaffolding and training, small models can effectively restructure research-level proofs over complex and varied metrics, matching substantially larger systems and establishing proof optimization as a scalable, learnable task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ImProver 2, a neurosymbolic framework for automated proof optimization in Lean 4. It combines a data-efficient expert-iteration pipeline with a scaffold exposing formal structure alongside lightweight informal abstractions, introduces a suite of metrics for structural proof properties, and reports that a 7B-parameter model trained via this method outperforms orders-of-magnitude larger models in the same family while remaining competitive with mid-tier frontier models; the scaffold is shown to improve performance across both small and frontier models.
Significance. If the empirical claims hold under rigorous verification, the work would be significant for formal mathematics and neural theorem proving: it positions proof optimization (refactoring for maintainability and training-data improvement) as a scalable, learnable task rather than a purely heuristic one, and demonstrates that modest-sized models can restructure research-level proofs across heterogeneous objectives when given appropriate neurosymbolic scaffolding.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for acknowledging the potential significance of positioning proof optimization as a scalable, learnable task with neurosymbolic scaffolding. We note the 'uncertain' recommendation and are happy to provide any additional verification, code, or experimental details that would help resolve concerns about the empirical claims.
Circularity Check
No significant circularity in empirical training pipeline
full rationale
The abstract and description present ImProver 2 as an empirical neurosymbolic training framework that produces performance gains on introduced metrics. No equations, derivations, or self-citations are shown that would make any reported result equivalent to its inputs by construction. The central claims (model training and metric improvements) are outcomes of an external training process rather than reductions to fitted parameters or self-referential definitions. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Simon Frieder, Jonas Bayer, Sam Looi, Jacob Loader, Julius Berner, Katherine M. Collins, András Juhász, Fabian Ruehle, Sean Welleck, Gabriel Poesia, Ryan-Rhys Griffiths, Adrian Weller, Anirudh Goyal, Cameron Freer, Thomas Lukasiewicz, and Timothy Gowers. Data for mathematical copilots: Better ways of presenting proofs ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
URL https://aclanthology.org/2025
Association for Computational Linguistics. URL https://aclanthology.org/2025. inlg-main.23/. Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z. Horváth, Goran Žuži´c, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, Ottavia Bertolli, Tom Zahavy, Amol Mandhane, Jessica Yung, Iuliya Beloshapka, Borja Ibarz, Vivek Veeriah...
-
[3]
Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si
URLhttps://doi.org/10.48550/arXiv.2210.12283. Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si. A survey on deep learning for theorem proving. InFirst Conference on Language Modeling,
-
[4]
URLhttps://openreview.net/forum?id=zlw6AHwukB. 14 Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, Ximing Lu, David Acuna, Kaiyu Yang, Hongzhou Lin, Yejin Choi, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-Prover-V2: Scaling formal theorem proving with scaffolde...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.acl-long.817 2025
-
[5]
Generative Language Modeling for Automated Theorem Proving
URLhttps://arxiv.org/abs/2009.03393. Shogo Saito and Mashu Noguchi. Foundation, 2026. URL https://github.com/ FormalizedFormalLogic/Foundation. Ivan Sergeev, Martin Dvorak, Tristan Figueroa-Reid, Rida Hamadani, Byung-Hak Hwang, Evgenia Karunus, Vladimir Kolmogorov, Alex Meiburg, Peter Nelson, and Mark Sandey. Regularity of 1-, 2-, and 3-sums of matroids, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-024-07566-y 2009
-
[6]
Focuses a goal?m i ∈ A i,
-
[7]
Produces an assignmentσ i+1(?mi) =t i,
-
[8]
Potentially introduces new metavariables corresponding to subgoals. The set of newly created metavariables is exactly the set of free metavariables occurring inti after assignment. A.2 Direct Children vs. Spawned Goals Let Children(τi) denote the set of metavariables that occur free in ti and therefore representdirect subgoalsof the focused goal?m i. Howe...
-
[9]
Its sequent variant hash matches any previously seen goal (global duplicate), or
-
[10]
Its target is a definitional wrapper of its parent goal, i.e.target(gchild)∈targetVariants(g parent) or vice versa. This eliminates the potential for many types of reward hacking cases, such as trivial ∀-introductions, restatements of the parent goal, and redundant lemma spawning. A.6 Nontriviality Filter LetT g be the subtree of steps rooted at a spawned...
-
[11]
the “easiest”) until the replay fraction isρ(cap atπ max)
Mark:We first mark problems in D(t) nr asREPLAYorFRONTIERso that the fraction of replay equalsρ: (a) Start with the subset of problems that are replay-eligible; if their fraction exceeds ρ, downsample them by removing highest-πT items (i.e. the “easiest”) until the replay fraction isρ(cap atπ max). (b) If their fraction is below ρ, replace uniformly chose...
work page 2024
-
[12]
The optimized proof removes a discarded intermediate lemma and folds repeated divisibility and 30 Euler-theorem reasoning into the main argument. The resulting proof is still dense, but it is materially shorter while preserving the same number-theoretic spine: prove the singleton characterization, force divisibility byab+ 1, and derivea=b= 1. F.2.3 Modula...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.