SimuScene: Simulation-Ready Compositional 3D Scene Reconstruction from a Single Image
Pith reviewed 2026-06-28 10:56 UTC · model grok-4.3
The pith
A physics engine run during single-image 3D reconstruction corrects object shapes and layouts so the resulting scene stays stable under simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
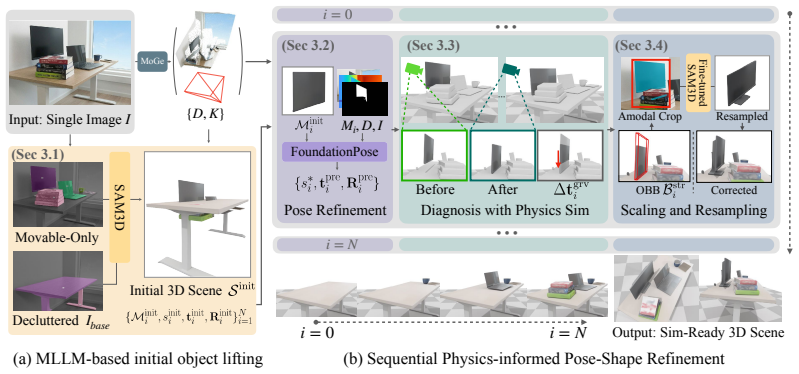
SimuScene places a physics engine inside the generative reconstruction pipeline itself. Diagnostic simulation of candidate objects under gravity converts observed penetration and support failures into correction signals that drive gravity-axis stretching and amodal shape resampling, thereby mitigating reconstruction errors and producing stable, simulation-ready compositional scenes.
What carries the argument
The physics-informed feedback loop that turns simulation failures into quantitative correction signals for shape and layout adjustment.
If this is right
- Reconstructed scenes remain stable under gravity-driven physical simulation without collapse or interpenetration.
- The same pipeline improves both physical stability metrics and geometric alignment to the input image.
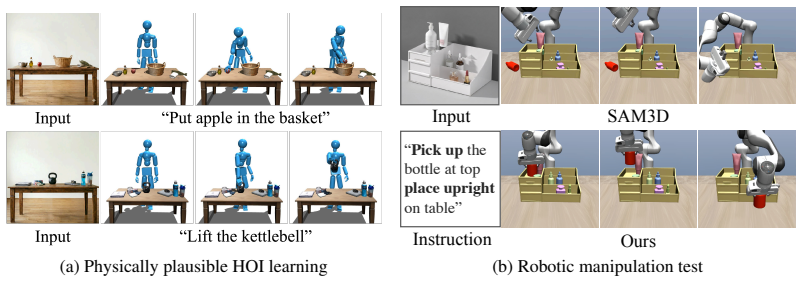
- Reconstructed environments transfer directly to downstream control tasks such as humanoid locomotion and robot-arm manipulation.
- Physics simulation serves as an active diagnostic rather than a post-hoc cleanup step.
Where Pith is reading between the lines
- The same feedback mechanism could be applied to video or multi-view inputs whose initial lifts already contain more geometric constraints.
- Extending the loop to additional physical constraints such as friction or contact forces would address failure modes beyond gravity alone.
- The approach may reduce the need for large-scale supervised 3D datasets if the physics signals supply sufficient self-supervision.
Load-bearing premise
Initial per-object shapes recovered from the single image are sufficiently close to physical plausibility that running a physics engine on them produces usable correction signals rather than divergence.
What would settle it
A dataset of single-image scenes where the corrected outputs still exhibit interpenetrations, hovering, or sinking when placed in an independent physics simulator would falsify the central claim.
Figures





read the original abstract
Reconstructing interactive, simulation-ready 3D scenes from a single image is a critical bottleneck for robotic manipulation. While recent single-image lifters recover plausible per-object shapes, composing them yields scenes that collapse under physical simulation due to interpenetrating, hovering, or sinking objects. Existing physics-aware methods address this strictly as a post-hoc layout correction, leaving the underlying geometric errors unresolved. To address this, we introduce SimuScene, a compositional 3D reconstruction pipeline that puts physics in the loop of shape and layout estimation. Rather than using physics merely for layout cleanup, we utilize the physics engine as a diagnostic measurement tool during the generative process itself. By diagnostically simulating reconstructed objects under gravity, we convert penetration and support failures into quantitative correction signals that drive gravity-axis stretching and amodal shape resampling. This physics-informed feedback loop mitigates accumulated reconstruction errors and produces a stable, simulation-ready compositional 3D scene. Extensive experiments demonstrate state-of-the-art performance on physical stability and geometric alignment benchmarks. We further highlight SimuScene's utility by deploying reconstructed environments in humanoid control and robot-arm manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SimuScene, a compositional 3D reconstruction pipeline from a single image that incorporates physics simulation directly into shape and layout estimation. Diagnostic simulations under gravity convert penetration and support failures into correction signals that drive gravity-axis stretching and amodal shape resampling, producing stable, simulation-ready scenes. The work reports state-of-the-art results on physical stability and geometric alignment benchmarks and demonstrates utility in humanoid control and robot-arm manipulation tasks.
Significance. If the central claims hold, the work provides a substantive advance over post-hoc physics correction methods by closing the loop with physics-derived signals during generation. This addresses a practical bottleneck for robotic applications and simulation. The explicit use of an external physics engine for diagnostic feedback, combined with reported empirical validation on benchmarks and downstream tasks, strengthens the contribution. The approach yields falsifiable predictions about scene stability that can be directly tested in simulation.
major comments (2)
- [§4] §4 (Method), feedback loop description: the claim that diagnostic simulation supplies quantitative correction signals for gravity-axis stretching assumes the initial per-object geometry is close enough to physical plausibility for the signals to be informative; the manuscript should include a quantitative analysis or failure-case study showing the basin of convergence for this assumption, as it is load-bearing for the central claim that accumulated reconstruction errors are mitigated.
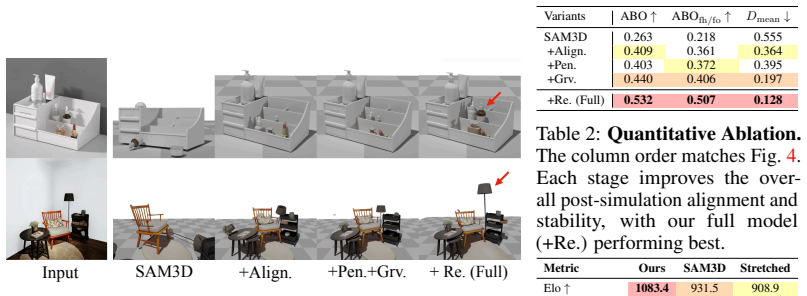
- [Table 2] Table 2 (physical stability benchmark): the reported SOTA margins on penetration and support metrics must be accompanied by per-scene breakdowns and variance across the test set; without this, it is unclear whether the physics-in-the-loop corrections consistently outperform post-hoc baselines or only succeed on easier subsets.
minor comments (3)
- [§3.1] §3.1: the notation for amodal shape resampling is introduced without an explicit equation relating the resampling distribution to the physics-derived support signal; adding this would improve reproducibility.
- [Figure 4] Figure 4: the before/after simulation visualizations would benefit from overlaid penetration depth heatmaps to make the quantitative correction signals visually verifiable.
- [Related Work] Related work section: the distinction between SimuScene and prior physics-aware layout methods could be sharpened by directly comparing the timing of physics usage (during vs. after generation) in a table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Method), feedback loop description: the claim that diagnostic simulation supplies quantitative correction signals for gravity-axis stretching assumes the initial per-object geometry is close enough to physical plausibility for the signals to be informative; the manuscript should include a quantitative analysis or failure-case study showing the basin of convergence for this assumption, as it is load-bearing for the central claim that accumulated reconstruction errors are mitigated.
Authors: We agree that the basin of convergence for the diagnostic feedback loop is a load-bearing assumption and that the current manuscript does not contain a quantitative analysis or dedicated failure-case study of this property. We will add such an analysis, including performance under controlled increases in initial geometric error, to the revised version. revision: yes
-
Referee: [Table 2] Table 2 (physical stability benchmark): the reported SOTA margins on penetration and support metrics must be accompanied by per-scene breakdowns and variance across the test set; without this, it is unclear whether the physics-in-the-loop corrections consistently outperform post-hoc baselines or only succeed on easier subsets.
Authors: We agree that aggregate SOTA margins alone leave open the question of consistency across scenes. We will revise Table 2 to include per-scene results together with variance or standard deviation statistics over the test set. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and high-level description present a feedback loop that applies an independent external physics engine to diagnose and correct per-object geometry recovered from a single image. No equations, fitted parameters, or self-citations are shown that would reduce the claimed correction signals (gravity-axis stretching, amodal resampling) to redefinitions of the input reconstructions. The method treats the physics simulator as an external diagnostic oracle whose outputs are not constructed from the reconstruction model itself; convergence depends on an explicit assumption about initial geometry quality rather than any definitional equivalence. This is a standard non-circular engineering pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 4, 19
Pith/arXiv arXiv 2023
-
[2]
Seeing through clutter: Structured 3d scene reconstruction via iterative object removal
Rio Aguina-Kang, Kevin James Blackburn-Matzen, Thibault Groueix, Vladimir Kim, and Matheus Gadelha. Seeing through clutter: Structured 3d scene reconstruction via iterative object removal. In3DV, 2026. 3
2026
-
[3]
Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert Özer, and Bernhard Egger. Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view. In3DV, 2025. 7, 8, 14, 21
2025
-
[4]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InAISTATS, 2024. 3
2024
-
[5]
Graspclutter6d: A large-scale real-world dataset for robust perception and grasping in cluttered scenes.RA-L, 2025
Seunghyeok Back, Joosoon Lee, Kangmin Kim, Heeseon Rho, Geonhyup Lee, Raeyoung Kang, Sangbeom Lee, Sangjun Noh, Youngjin Lee, Taeyeop Lee, et al. Graspclutter6d: A large-scale real-world dataset for robust perception and grasping in cluttered scenes.RA-L, 2025. 7, 14, 21, 22
2025
-
[6]
Text-guided 6d object pose rearrangement via closed-loop vlm agents.arXiv:2604.09781, 2026
Sangwon Baik, Gunhee Kim, Mingi Choi, and Hanbyul Joo. Text-guided 6d object pose rearrangement via closed-loop vlm agents.arXiv:2604.09781, 2026. 9, 21
Pith/arXiv arXiv 2026
-
[7]
Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023. 3
Pith/arXiv arXiv 2023
-
[8]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
Pith/arXiv arXiv 2023
-
[9]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 4
Pith/arXiv arXiv 2025
-
[10]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. InCVPR, 2025. 3
2025
-
[11]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, 2024. 2
2024
-
[12]
Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624,
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624,
-
[13]
1, 2, 3, 4, 7, 8, 14, 21
-
[14]
Luciddreamer: Domain-free generation of 3d gaussian splatting scenes.TVCG, 2025
Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, and Kyoung Mu Lee. Luciddreamer: Domain-free generation of 3d gaussian splatting scenes.TVCG, 2025. 2
2025
-
[15]
Hiscene: creating hierarchical 3d scenes with isometric view generation
Wenqi Dong, Bangbang Yang, Zesong Yang, Yuan Li, Tao Hu, Hujun Bao, Yuewen Ma, and Zhaopeng Cui. Hiscene: creating hierarchical 3d scenes with isometric view generation. InACMMM, 2025. 3
2025
-
[16]
Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024. 3
Pith/arXiv arXiv 2024
-
[17]
Graspnet-1billion: A large-scale benchmark for general object grasping
Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InICCV, 2020. 9, 21 10
2020
-
[18]
Cat3d: Create anything in 3d with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srini- vasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314, 2024. 2
Pith/arXiv arXiv 2024
-
[19]
Mediapipe solutions guide
Google AI Edge. Mediapipe solutions guide. https://developers.google.com/mediapipe, 2025. 21
2025
-
[20]
Reparo: Compositional 3d assets generation with differentiable 3d layout alignment
Haonan Han, Rui Yang, Huan Liao, Jiankai Xing, Zunnan Xu, Xiaoming Yu, Junwei Zha, Xiu Li, and Wanhua Li. Reparo: Compositional 3d assets generation with differentiable 3d layout alignment. InICCV,
-
[21]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InCVPR, 2025. 2
2025
-
[22]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. InNeurIPS, 2022. 2
2022
-
[23]
Orpo: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. InEMNLP, 2024. 3
2024
-
[24]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022. 6, 7, 19
2022
-
[25]
Flash sculptor: Modular 3d worlds from objects
Yujia Hu, Songhua Liu, Xingyi Yang, and Xinchao Wang. Flash sculptor: Modular 3d worlds from objects. arXiv preprint arXiv:2504.06178, 2025. 3
arXiv 2025
-
[26]
Holistic 3d scene parsing and reconstruction from a single rgb image
Siyuan Huang, Siyuan Qi, Yixin Zhu, Yinxue Xiao, Yuanlu Xu, and Song-Chun Zhu. Holistic 3d scene parsing and reconstruction from a single rgb image. InECCV, 2018. 3
2018
-
[27]
Open-set image tagging with multi-grained text supervision
Xinyu Huang, Yi-Jie Huang, Youcai Zhang, Weiwei Tian, Rui Feng, Yuejie Zhang, Yanchun Xie, Yaqian Li, and Lei Zhang. Open-set image tagging with multi-grained text supervision. InMM, 2025. 4
2025
-
[28]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InCVPR, 2025. 2, 3
2025
-
[29]
3d gaussian splatting for real-time radiance field rendering.TOG, 42(4):139–1, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.TOG, 42(4):139–1, 2023. 2
2023
-
[30]
Devi: Physics-based dexterous human-object interaction via synthetic video imitation
Hyeonwoo Kim, Jeonghwan Kim, Kyungwon Cho, and Hanbyul Joo. Devi: Physics-based dexterous human-object interaction via synthetic video imitation. InarXiv:2604.20841, 2026. 9
Pith/arXiv arXiv 2026
-
[31]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025. 19
2025
-
[32]
Qixuan Li, Chao Wang, Zongjin He, and Yan Peng. Phip-g: Physics-guided text-to-3d compositional scene generation.arXiv preprint arXiv:2502.00708, 2025. 3
arXiv 2025
-
[33]
Dso: Aligning 3d generators with simulation feedback for physical soundness
Ruining Li, Chuanxia Zheng, Christian Rupprecht, and Andrea Vedaldi. Dso: Aligning 3d generators with simulation feedback for physical soundness. InICCV, 2025. 2, 3, 6
2025
-
[34]
Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization
Zhanhao Liang, Yuhui Yuan, Shuyang Gu, Bohan Chen, Tiankai Hang, Mingxi Cheng, Ji Li, and Liang Zheng. Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization. InCVPR, 2025. 3
2025
-
[35]
Pat3d: Physics-augmented text-to-3d scene generation.arXiv preprint arXiv:2511.21978, 2025
Guying Lin, Kemeng Huang, Michael Liu, Ruihan Gao, Hanke Chen, Lyuhao Chen, Beijia Lu, Taku Komura, Yuan Liu, Jun-Yan Zhu, et al. Pat3d: Physics-augmented text-to-3d scene generation.arXiv preprint arXiv:2511.21978, 2025. 3
Pith/arXiv arXiv 2025
-
[36]
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: A language and vision agentic framework for 3d scene generation.arXiv preprint arXiv:2505.02836, 2025. 3
arXiv 2025
-
[37]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023. 6
2023
-
[38]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7 11
Pith/arXiv arXiv 2017
-
[39]
Simpo: Simple preference optimization with a reference-free reward.NeurIPS, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.NeurIPS, 2024. 3
2024
-
[40]
Scenegen: Single-image 3d scene generation in one feedforward pass
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Scenegen: Single-image 3d scene generation in one feedforward pass. In3DV, 2026. 2
2026
-
[41]
Phyrecon: Physically plausible neural scene reconstruction.NeurIPS, 2024
Junfeng Ni, Yixin Chen, Bohan Jing, Nan Jiang, Bin Wang, Bo Dai, Puhao Li, Yixin Zhu, Song-Chun Zhu, and Siyuan Huang. Phyrecon: Physically plausible neural scene reconstruction.NeurIPS, 2024. 3
2024
-
[42]
Training language models to follow instructions with human feedback.NeurIPS, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.NeurIPS, 2022. 3
2022
-
[43]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Peters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. InICCV, 2023. 7, 8, 14, 21, 22
2023
-
[44]
Corenet: Coherent 3d scene reconstruction from a single rgb image
Stefan Popov, Pablo Bauszat, and Vittorio Ferrari. Corenet: Coherent 3d scene reconstruction from a single rgb image. InECCV, 2020. 3
2020
-
[45]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023. 3, 6
2023
-
[46]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InCVPR, 2025. 2
2025
-
[47]
Tobias Sautter, Jan-Niklas Dihlmann, and Hendrik Lensch. 3d-re-gen: 3d reconstruction of indoor scenes with a generative framework.arXiv preprint arXiv:2512.17459, 2025. 7, 8, 14, 21
arXiv 2025
-
[48]
Dinov3.arXiv preprint arXiv:2508.10104, 2025
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 15
Pith/arXiv arXiv 2025
-
[49]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. InICLR,
-
[50]
The open motion planning library.RAM, 19(4):72–82,
Ioan A Sucan, Mark Moll, and Lydia E Kavraki. The open motion planning library.RAM, 19(4):72–82,
-
[51]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 4, 8, 14
Pith/arXiv arXiv 2023
-
[52]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012. 7, 8
2012
-
[53]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InCVPR, 2024. 3, 6
2024
-
[54]
Moge-2: Accurate monocular geometry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details. arXiv preprint arXiv:2507.02546, 2025. 4
Pith/arXiv arXiv 2025
-
[55]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InCVPR, 2024. 4, 15
2024
-
[56]
Gpt-4v(ision) is a human-aligned evaluator for text-to-3d generation
Tong Wu, Guandao Yang, Zhibing Li, Kai Zhang, Ziwei Liu, Leonidas Guibas, Dahua Lin, and Gordon Wetzstein. Gpt-4v(ision) is a human-aligned evaluator for text-to-3d generation. InCVPR, 2024. 8, 9
2024
-
[57]
Simrecon: Simready compositional scene reconstruction from real videos, 2026
Chong Xia, Kai Zhu, Zizhuo Wang, Fangfu Liu, Zhizheng Zhang, and Yueqi Duan. Simrecon: Simready compositional scene reconstruction from real videos, 2026. 3
2026
-
[58]
Physic: Physically plausible 3d human-scene interaction and contact from a single image
Pradyumna Yalandur Muralidhar, Yuxuan Xue, Xianghui Xie, Margaret Kostyrko, and Gerard Pons-Moll. Physic: Physically plausible 3d human-scene interaction and contact from a single image. InACM SIGGRAPH Asia, 2025. 3 12
2025
-
[59]
Han Yan, Mingrui Zhang, Yang Li, Chao Ma, and Pan Ji. Phycage: Physically plausible compositional 3d asset generation from a single image.arXiv preprint arXiv:2411.18548, 2024. 3
arXiv 2024
-
[60]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023. 14
Pith/arXiv arXiv 2023
-
[61]
Using human feedback to fine-tune diffusion models without any reward model
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. InCVPR, 2024. 3
2024
-
[62]
Cast: Component-aligned 3d scene reconstruction from an rgb image
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Wei Yang, Lan Xu, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruction from an rgb image. InSIGGRAPH, 2025. 2, 3
2025
-
[63]
Freeman, and Jiajun Wu
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T. Freeman, and Jiajun Wu. Wonderworld: Interactive 3d scene generation from a single image. InCVPR, 2025. 2
2025
-
[64]
Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.TPAMI, 2025
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.TPAMI, 2025. 2
2025
-
[65]
standing
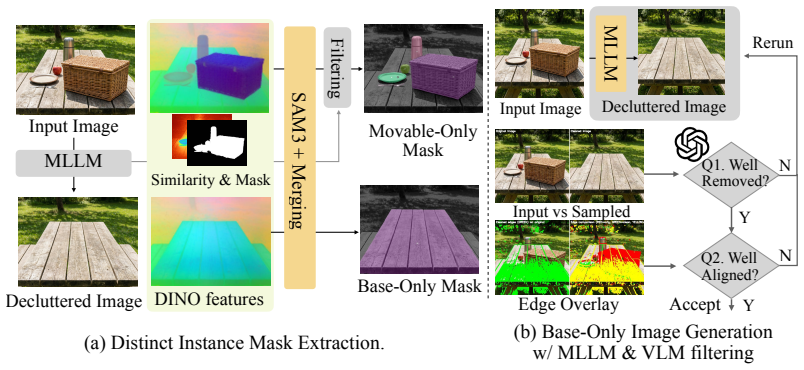
Jensen Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. InICCV, 2025. 2 13 Input Image Decluttered ImageDINO features Movable-Only Mask SAM3 + Merging Base-Only Mask Filtering MLLM Similarity & Mask (b) Ba...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.