Attention-guided Fine-tuning of Multimodal Large Language Models Improves Chain-of-Thought Reasoning
Pith reviewed 2026-06-28 15:43 UTC · model grok-4.3
The pith
Attention-guided fine-tuning improves chain-of-thought reasoning in multimodal models by fixing two failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
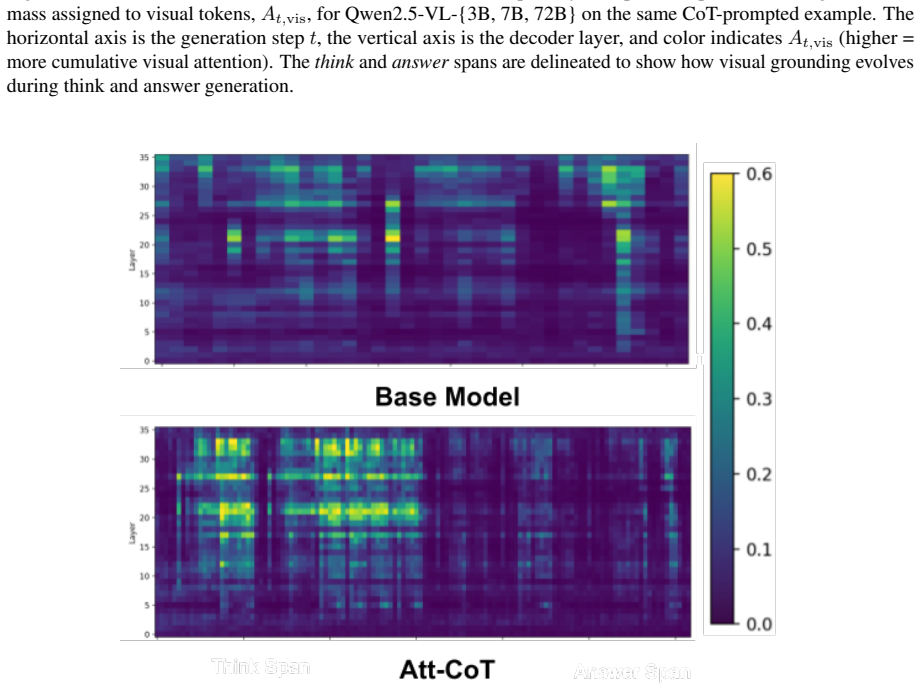
The paper establishes that Attentive-CoT (Att-CoT) is an attention-guided fine-tuning objective which encourages CoT trajectories to delay answer commitment while maintaining sustained visual-token access. This approach can be added to any CoT-SFT run without architectural changes, and experiments on three visual reasoning benchmarks across six MLLMs demonstrate enhanced CoT performance over standard fine-tuning.
What carries the argument
Attentive-CoT (Att-CoT): an attention-guided fine-tuning objective that encourages CoT trajectories to delay answer commitment while maintaining sustained visual-token access.
If this is right
- Att-CoT plugs directly into existing CoT-SFT training without any model architecture modifications.
- It improves CoT performance on three visual reasoning benchmarks.
- The gains hold across six MLLMs from three families at different scales.
- Unlike standard CoT-SFT, it avoids increasing reliance on textual priors and maintains counterfactual visual dependence.
Where Pith is reading between the lines
- Attention guidance during fine-tuning could be adapted to address similar reasoning issues in text-only language models.
- The approach might extend to other multimodal tasks that require step-by-step visual analysis beyond the three benchmarks tested.
Load-bearing premise
The identified failure modes of premature answer commitment and limited direct visual-token access are the primary causes of CoT degradation in MLLMs, and guiding attention during fine-tuning will reliably mitigate them without introducing new issues or reducing performance on other tasks.
What would settle it
If experiments on the three visual reasoning benchmarks across the six MLLMs show no improvement or even degradation in CoT performance when using Att-CoT compared to standard fine-tuning, the central claim would be falsified.
Figures



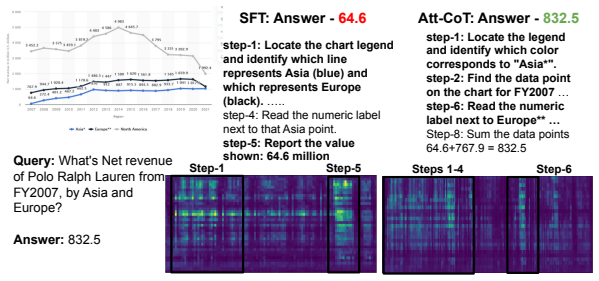



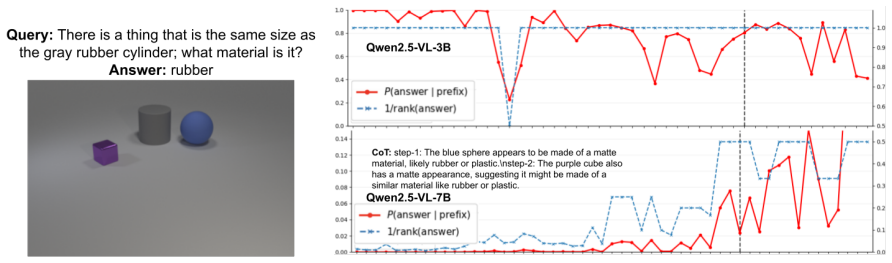
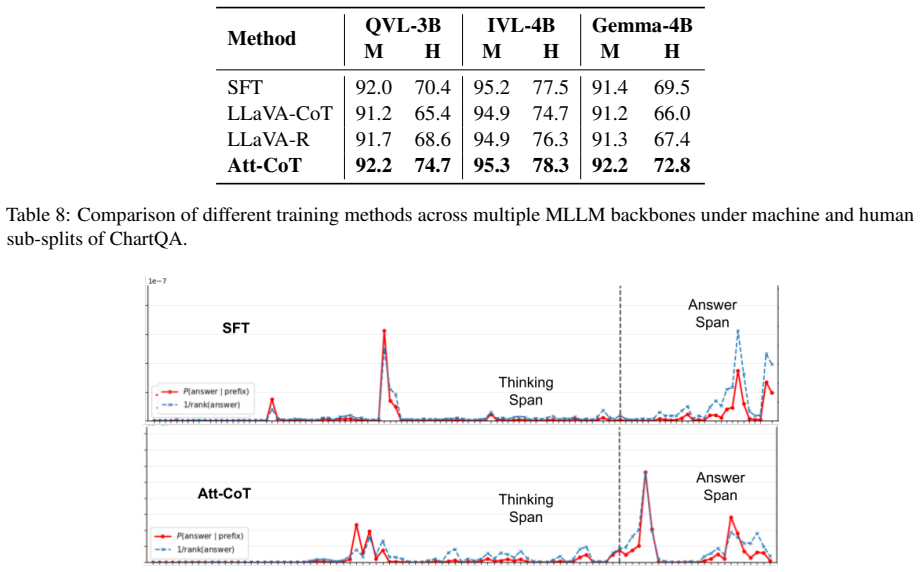
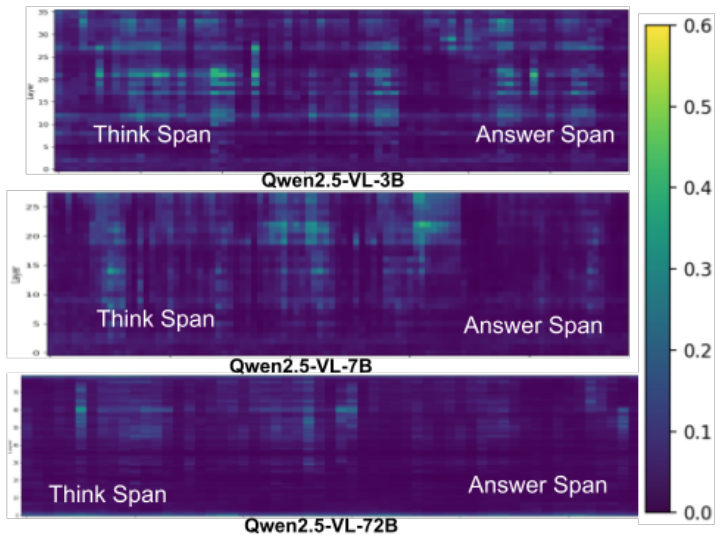



read the original abstract
The effectiveness of Chain-of-Thought (CoT) prompting in Multimodal Large Language Models (MLLMs) remains uncertain: across several visual reasoning benchmarks, CoT prompting often degrades performance compared to direct prompting. In this paper, we provide a systematic analysis of CoT behavior in three modern MLLM families across model scales on datasets requiring step-wise visual evidence. Our analysis identifies two recurring failure modes: premature answer commitment and limited direct visual-token access during rationale generation. We further find that standard CoT-style Supervised Fine-Tuning (CoT-SFT) can mitigate these issues only partially, while often increasing reliance on textual priors and reducing counterfactual visual dependence. Motivated by these findings, we propose Attentive-CoT (Att-CoT), an attention-guided fine-tuning objective that encourages CoT trajectories to delay answer commitment while maintaining sustained visual-token access. Att-CoT can be plugged into any CoT-SFT training run without architectural changes. Experiments on three visual reasoning benchmarks across six MLLMs show that Att-CoT enhances CoT performance over standard fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes CoT prompting behavior in MLLMs, identifying two failure modes (premature answer commitment and limited direct visual-token access) that cause performance degradation on visual reasoning tasks. It shows that standard CoT-SFT only partially mitigates these issues and can increase reliance on textual priors. Motivated by this, the authors propose Attentive-CoT (Att-CoT), a plug-in attention-guided fine-tuning objective that encourages delayed answer commitment and sustained visual-token access during rationale generation. Experiments across three visual reasoning benchmarks and six MLLMs demonstrate that Att-CoT improves CoT performance relative to standard fine-tuning without requiring architectural modifications.
Significance. If the empirical results hold after addressing experimental details, the work offers a practical, architecture-agnostic technique for improving multimodal chain-of-thought reasoning. The systematic failure-mode analysis and multi-model/multi-benchmark evaluation provide a useful empirical foundation; the no-architecture-change property is a clear strength for adoption.
major comments (1)
- [Experiments / abstract] Experimental results (as described in the abstract and implied evaluation sections): performance gains are reported without statistical significance tests, error bars, run-to-run variance, or ablation studies isolating the attention-guidance components from other training differences. This is load-bearing for the central claim that Att-CoT specifically mitigates the identified failure modes rather than arising from uncontrolled factors such as data selection or optimization details.
minor comments (2)
- [Method] The abstract and method description would benefit from an explicit equation or pseudocode formalizing the attention-guided loss term in Att-CoT.
- [Experiments] Clarify the exact visual reasoning benchmarks and model scales used in the six-MLLM evaluation to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. The concern regarding experimental rigor is valid and we will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments / abstract] Experimental results (as described in the abstract and implied evaluation sections): performance gains are reported without statistical significance tests, error bars, run-to-run variance, or ablation studies isolating the attention-guidance components from other training differences. This is load-bearing for the central claim that Att-CoT specifically mitigates the identified failure modes rather than arising from uncontrolled factors such as data selection or optimization details.
Authors: We agree that the absence of statistical tests, error bars, variance reporting, and targeted ablations weakens the ability to isolate the contribution of the attention-guidance objective. The manuscript demonstrates consistent gains across six MLLMs and three benchmarks, but this does not substitute for the requested controls. In the revised version we will add: multiple random seeds with error bars and run-to-run variance; statistical significance testing (e.g., paired t-tests against CoT-SFT baselines); and ablations that hold data, optimizer, and schedule fixed while varying only the attention-guidance term. These results will be incorporated into the experiments section and abstract where appropriate. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical analysis of CoT failure modes in MLLMs followed by a proposed attention-guided fine-tuning objective (Att-CoT) that is evaluated on external visual reasoning benchmarks across six models. No equations, fitted parameters, or self-citations are used to derive the central performance claim; the improvement is demonstrated directly via controlled experiments rather than by construction from the paper's own inputs or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised fine-tuning loss functions and attention mechanisms in transformer-based MLLMs behave as expected under the proposed objective.
Reference graph
Works this paper leans on
-
[1]
Bring reason to vision: Understanding perception and reasoning through model merging , author=. arXiv preprint arXiv:2505.05464 , year=
-
[2]
URL https: //aclanthology.org/2025.acl-long.257/
Sun, Hai-Long and Sun, Zhun and Peng, Houwen and Ye, Han-Jia. Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long C o T Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.257
-
[3]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
When Big Models Train Small Ones: Label-Free Model Parity Alignment for Efficient Visual Question Answering using Small VLMs , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[4]
Lora vs full fine-tuning: An illusion of equivalence
Lora vs full fine-tuning: An illusion of equivalence , author=. arXiv preprint arXiv:2410.21228 , year=
-
[5]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Llava-o1: Let vision language models reason step-by-step , author=. arXiv preprint arXiv:2411.10440 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning
Islam, Mohammed Saidul and Rahman, Raian and Masry, Ahmed and Laskar, Md Tahmid Rahman and Nayeem, Mir Tafseer and Hoque, Enamul. Are Large Vision Language Models up to the Challenge of Chart Comprehension and Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.191
-
[7]
C hart G emma: Visual Instruction-tuning for Chart Reasoning in the Wild
Masry, Ahmed and Thakkar, Megh and Bajaj, Aayush and Kartha, Aaryaman and Hoque, Enamul and Joty, Shafiq. C hart G emma: Visual Instruction-tuning for Chart Reasoning in the Wild. Proceedings of the 31st International Conference on Computational Linguistics: Industry Track. 2025
2025
-
[8]
Forty-second International Conference on Machine Learning , year=
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding , author=. Forty-second International Conference on Machine Learning , year=
-
[9]
Chart-based Reasoning: Transferring Capabilities from LLM s to VLM s
Carbune, Victor and Mansoor, Hassan and Liu, Fangyu and Aralikatte, Rahul and Baechler, Gilles and Chen, Jindong and Sharma, Abhanshu. Chart-based Reasoning: Transferring Capabilities from LLM s to VLM s. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.62
-
[10]
Xie, Yuxi and Li, Guanzhen and Xu, Xiao and Kan, Min-Yen. V - DPO : Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.775
-
[11]
arXiv preprint arXiv:2503.16188 , year=
Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.16188 , year=
-
[12]
arXiv preprint arXiv:2503.08525 , year=
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training , author=. arXiv preprint arXiv:2503.08525 , year=
-
[13]
arXiv preprint arXiv:2203.08788 , year=
Are shortest rationales the best explanations for human understanding? , author=. arXiv preprint arXiv:2203.08788 , year=
-
[14]
Visual-RFT: Visual Reinforcement Fine-Tuning
Visual-rft: Visual reinforcement fine-tuning , author=. arXiv preprint arXiv:2503.01785 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Evochart: A benchmark and a self-training approach towards real-world chart understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
International Conference on Learning Representations (ICLR) , year=
React: Synergizing reasoning and acting in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Question Answering
Masry, Ahmed and Islam, Mohammed Saidul and Ahmed, Mahir and Bajaj, Aayush and Kabir, Firoz and Kartha, Aaryaman and Laskar, Md Tahmid Rahman and Rahman, Mizanur and Rahman, Shadikur and Shahmohammadi, Mehrad and Thakkar, Megh and Parvez, Md Rizwan and Hoque, Enamul and Joty, Shafiq. C hart QAP ro: A More Diverse and Challenging Benchmark for Chart Questi...
-
[19]
arXiv preprint arXiv:2312.15915 , year=
Chartbench: A benchmark for complex visual reasoning in charts , author=. arXiv preprint arXiv:2312.15915 , year=
-
[20]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
2022
-
[24]
GitHub repository , publisher =
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou. GitHub repository , publisher =
-
[25]
and Kumar, Pratyush , title =
Methani, Nitesh and Ganguly, Pritha and Khapra, Mitesh M. and Kumar, Pratyush , title =. The IEEE Winter Conference on Applications of Computer Vision (WACV) , month =
-
[26]
Findings of the Association for Computational Linguistics: EACL 2023 , pages=
Reading and Reasoning over Chart Images for Evidence-based Automated Fact-Checking , author=. Findings of the Association for Computational Linguistics: EACL 2023 , pages=
2023
-
[27]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[29]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
International Conference on Machine Learning , pages=
Pix2struct: Screenshot parsing as pretraining for visual language understanding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[31]
arXiv preprint arXiv:2504.13275 , year=
ChartQA-X: Generating Explanations for Charts , author=. arXiv preprint arXiv:2504.13275 , year=
-
[32]
arXiv preprint arXiv:2504.06637 , year=
SCI-Reason: A Dataset with Chain-of-Thought Rationales for Complex Multimodal Reasoning in Academic Areas , author=. arXiv preprint arXiv:2504.06637 , year=
-
[33]
The Exploration in AI Today Workshop at ICML 2025 , year=
Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models , author=. The Exploration in AI Today Workshop at ICML 2025 , year=
2025
-
[34]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
ChartAssistant: A Universal Chart Multimodal Language Model via Chart-to-Table Pre-training and Multitask Instruction Tuning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[35]
Zhang, Liang and Hu, Anwen and Xu, Haiyang and Yan, Ming and Xu, Yichen and Jin, Qin and Zhang, Ji and Huang, Fei. T iny C hart: Efficient Chart Understanding with Program-of-Thoughts Learning and Visual Token Merging. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.112
-
[36]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Graph-Based Multimodal Contrastive Learning for Chart Question Answering , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[37]
C hart I nsights: Evaluating Multimodal Large Language Models for Low-Level Chart Question Answering
Wu, Yifan and Yan, Lutao and Shen, Leixian and Wang, Yunhai and Tang, Nan and Luo, Yuyu. C hart I nsights: Evaluating Multimodal Large Language Models for Low-Level Chart Question Answering. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.710
-
[38]
arXiv preprint arXiv:2502.12289 , year=
Evaluating step-by-step reasoning traces: A survey , author=. arXiv preprint arXiv:2502.12289 , year=
-
[39]
arXiv preprint arXiv:2505.20777 , year=
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs , author=. arXiv preprint arXiv:2505.20777 , year=
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2504.02906 , year=
Boosting Chart-to-Code Generation in MLLM via Dual Preference-Guided Refinement , author=. arXiv preprint arXiv:2504.02906 , year=
-
[44]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[46]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2505.21523 , year=
More Thinking, Less Seeing? Assessing Amplified Hallucination in Multimodal Reasoning Models , author=. arXiv preprint arXiv:2505.21523 , year=
-
[49]
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling , author=. arXiv preprint arXiv:2412.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
BigCharts-R1: Enhanced Chart Reasoning with Visual Reinforcement Finetuning , author=
-
[53]
Advances in Neural Information Processing Systems , volume=
Charxiv: Charting gaps in realistic chart understanding in multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[55]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improve vision language model chain-of-thought reasoning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[56]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal chain-of-thought reasoning in language models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Measuring and improving chain-of-thought reasoning in vision-language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[58]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A fully open, vision-centric exploration of multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
On the impact of fine-tuning on chain-of-thought reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[60]
arXiv preprint arXiv:2407.10490 , year=
Learning dynamics of llm finetuning , author=. arXiv preprint arXiv:2407.10490 , year=
-
[61]
arXiv preprint arXiv:2512.12218 , year=
Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking , author=. arXiv preprint arXiv:2512.12218 , year=
-
[62]
Benchmark Designers Should" Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts , author=. arXiv preprint arXiv:2511.04655 , year=
-
[63]
arXiv preprint arXiv:2507.03019 , year=
Look-back: Implicit visual re-focusing in mllm reasoning , author=. arXiv preprint arXiv:2507.03019 , year=
-
[64]
arXiv preprint arXiv:2503.01773 , year=
Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas , author=. arXiv preprint arXiv:2503.01773 , year=
-
[65]
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Li, Yong Jae , journal=
-
[66]
8th Annual Conference on Robot Learning , year=
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models , author =. 8th Annual Conference on Robot Learning , year=
-
[67]
European Conference on Computer Vision (ECCV) , year =
Chonghao Sima and Katrin Renz and Kashyap Chitta and Li Chen and Hanxue Zhang and Chengen Xie and Ping Luo and Andreas Geiger and Hongyang Li , title =. European Conference on Computer Vision (ECCV) , year =
-
[68]
2025 , eprint =
Distilling Multi-modal Large Language Models for Autonomous Driving , author =. 2025 , eprint =
2025
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Hua, Hang and Liu, Qing and Zhang, Lingzhi and Shi, Jing and Kim, Soo Ye and Zhang, Zhifei and Wang, Yilin and Zhang, Jianming and Lin, Zhe and Luo, Jiebo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[70]
2025 , eprint =
Patch Matters: Training-free Fine-grained Image Caption Enhancement via Local Perception , author =. 2025 , eprint =
2025
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Sheng and Li, Yilei and Yuan, Jiayi and Zhou, Pan and Chen, Xinyuan and Fu, Jingjing and Xu, Jie and Jiang, Lijuan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[72]
2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE) , pages=
On Large Visual Language Models for Medical Imaging Analysis: An Empirical Study , author=. 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE) , pages=. 2024 , organization=
2024
-
[73]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[74]
Advances in Neural Information Processing Systems , editor =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , editor =
-
[75]
Advances in Neural Information Processing Systems , editor =
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems , editor =
-
[76]
and Girshick, Ross , title =
Johnson, Justin and Hariharan, Bharath and van der Maaten, Laurens and Fei-Fei, Li and Lawrence Zitnick, C. and Girshick, Ross , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[77]
and Manning, Christopher D
Hudson, Drew A. and Manning, Christopher D. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[78]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zellers, Rowan and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[79]
arXiv preprint arXiv:2404.18624 , year=
Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations? , author=. arXiv preprint arXiv:2404.18624 , year=
-
[80]
arXiv preprint arXiv:2010.13984 , year=
Interpretation of NLP models through input marginalization , author=. arXiv preprint arXiv:2010.13984 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.