VGGT-Occ: Geometry-Grounded and Density-Aware Gated Fusion for 3D Occupancy Prediction
Pith reviewed 2026-05-19 21:15 UTC · model grok-4.3
pith:3BCWRAFN Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{3BCWRAFN}
Prints a linked pith:3BCWRAFN badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Embedding camera geometry into every attention and fusion step produces more accurate 3D semantic occupancy from multi-view images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
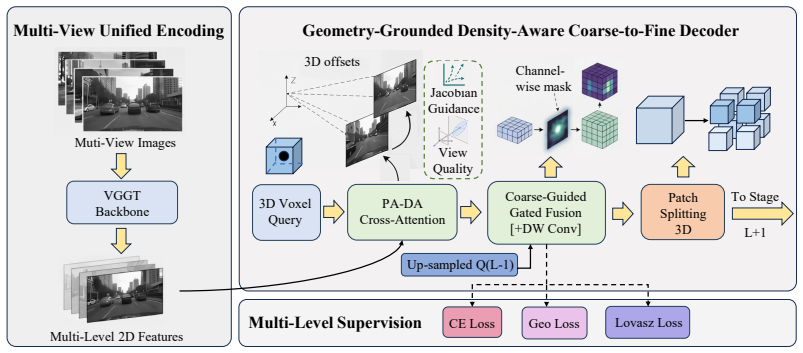
VGGT-Occ embeds geometric tokens throughout the pipeline by means of Projection-Aware Deformable Attention that projects 3D offsets to image planes and uses the projection Jacobian as an additive bias, followed by a view-quality semantic gate and sequential coarse-to-fine gated fusion that refines low-resolution features while respecting information density.
What carries the argument
Projection-Aware Deformable Attention (PA-DA), which projects learned 3D offsets back to image planes and adds the projection Jacobian as a bias to suppress unreliable observations during attention.
If this is right
- The occupancy head uses only about 41 million trainable parameters while reaching 33.00 percent IoU and 21.08 percent mIoU on SurroundOcc-nuScenes with one frame.
- Two-frame inference raises the scores to 33.64 percent IoU and 21.43 percent mIoU.
- Low-resolution features are refined into higher resolutions only where information density justifies the cost, lowering overall decoder computation.
- Cross-view consistency is enforced by the view-quality semantic gate before final fusion.
Where Pith is reading between the lines
- The same projection-and-Jacobian bias could be inserted into other multi-view tasks such as depth completion or 3D object detection to enforce geometric consistency without extra supervision.
- If the density-aware gating generalizes, similar coarse-to-fine schedules might reduce memory use in other dense prediction networks that currently process full-resolution volumes.
- Testing whether the view-quality gate still works under strong lighting changes or partial camera failure would show how far the cross-view consistency claim extends beyond the nuScenes recording conditions.
Load-bearing premise
That projecting 3D offsets to image planes and adding the Jacobian as a bias term will reliably down-weight unreliable observations without introducing new inconsistencies across views.
What would settle it
An ablation on the SurroundOcc-nuScenes validation set in which the Jacobian bias is removed from PA-DA and the IoU and mIoU scores remain unchanged or improve.
Figures





read the original abstract
3D semantic occupancy prediction requires accurate 2D-to-3D feature lifting, yet current methods restrict camera geometry to initial projections. Subsequent operations like offset learning, attention weighting, and cross-camera aggregation remain geometry-agnostic, ignoring essential physical constraints. We propose VGGT-Occ, a framework that embeds geometric tokens throughout the entire pipeline. We introduce Projection-Aware Deformable Attention (PA-DA) to inject geometry into all attention stages. PA-DA projects 3D offsets back to image planes and leverages the projection Jacobian as an additive bias to suppress unreliable observations. Features are then integrated through a view-quality semantic gate for cross-view consistency. To optimize both efficiency and performance, we employ a sequential coarse-to-fine decoder with gated fusion, where low-resolution features are refined into higher resolutions, allocating computation by information density while substantially reducing decoder cost. Extensive evaluations demonstrate the effectiveness and accuracy of our approach. On SurroundOcc-nuScenes, VGGT-Occ achieves 33.00\% IoU and 21.08\% mIoU ($T{=}1$), and 33.64\% IoU and 21.43\% mIoU with $T{=}2$ inference, outperforming existing methods, with only ${\sim}41$M trainable parameters in the occupancy head. Code will be released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VGGT-Occ, a 3D semantic occupancy prediction framework that embeds geometric tokens throughout the pipeline. It introduces Projection-Aware Deformable Attention (PA-DA) which projects 3D offsets back to image planes and adds the projection Jacobian as an additive bias to suppress unreliable observations, a view-quality semantic gate for cross-view consistency, and a sequential coarse-to-fine decoder with gated fusion that allocates computation according to information density. On the SurroundOcc-nuScenes benchmark the method reports 33.00% IoU and 21.08% mIoU (T=1) and 33.64% IoU and 21.43% mIoU (T=2) while using only ~41 M trainable parameters in the occupancy head, outperforming prior approaches.
Significance. If the geometry-grounded mechanisms and efficiency gains hold under rigorous verification, the work could meaningfully advance camera-based 3D occupancy prediction for autonomous driving and robotics. The explicit performance numbers, parameter-efficiency claim, and stated intention to release code publicly are concrete strengths that support potential impact.
major comments (2)
- [Method (PA-DA)] Method section (PA-DA): the central claim that projecting 3D offsets and adding the projection Jacobian as an additive bias reliably suppresses unreliable 2D observations lacks any explicit formulation, normalization details, or derivation showing how the bias term alters attention weights relative to standard deformable attention. This mechanism is load-bearing for attributing the reported IoU/mIoU gains to geometry grounding rather than other factors.
- [Experiments] Experiments section: no ablations isolate the contribution of the Jacobian bias versus the view-quality gate or the coarse-to-fine fusion, and no error bars or statistical significance tests are reported for the 33.00% IoU / 21.08% mIoU figures. Without these, the performance advantage over prior methods cannot be confidently linked to the proposed components.
minor comments (2)
- [Abstract / Method] The abstract and method description refer to T=1 and T=2 inference without defining T or explaining its relation to the sequential decoder in the main text.
- [Method] Notation for the Jacobian bias term and the view-quality semantic gate should be introduced with explicit equations rather than descriptive prose only.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We appreciate the acknowledgment of the potential impact of our geometry-grounded approach for camera-based 3D occupancy prediction. We address each major comment point by point below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Method (PA-DA)] Method section (PA-DA): the central claim that projecting 3D offsets and adding the projection Jacobian as an additive bias reliably suppresses unreliable 2D observations lacks any explicit formulation, normalization details, or derivation showing how the bias term alters attention weights relative to standard deformable attention. This mechanism is load-bearing for attributing the reported IoU/mIoU gains to geometry grounding rather than other factors.
Authors: We agree that the manuscript would benefit from a more rigorous and explicit mathematical treatment of the PA-DA mechanism. While the current text describes the high-level operation of projecting 3D offsets and using the Jacobian as an additive bias, it does not include the full formulation, normalization procedure, or derivation of its effect on attention weights. In the revised version we will expand the Method section to provide these details, including the precise equations for the bias term, its normalization relative to standard deformable attention, and a short derivation showing how it modulates attention scores to down-weight unreliable projections. This addition will clarify the geometry-grounding contribution. revision: yes
-
Referee: [Experiments] Experiments section: no ablations isolate the contribution of the Jacobian bias versus the view-quality gate or the coarse-to-fine fusion, and no error bars or statistical significance tests are reported for the 33.00% IoU / 21.08% mIoU figures. Without these, the performance advantage over prior methods cannot be confidently linked to the proposed components.
Authors: We acknowledge that the current experimental section does not contain component-wise ablations or statistical analysis of the reported metrics. We will add a dedicated ablation study that isolates the Jacobian bias term, the view-quality semantic gate, and the sequential coarse-to-fine gated fusion. In addition, we will rerun the main experiments with multiple random seeds and report mean IoU/mIoU values together with standard deviations; we will also include a brief statistical significance assessment (e.g., paired t-test) against the strongest baseline. These changes will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces VGGT-Occ as a new architecture that embeds geometric tokens via Projection-Aware Deformable Attention (PA-DA), which projects 3D offsets and adds the projection Jacobian as a bias term, followed by a view-quality semantic gate and coarse-to-fine gated fusion. These components are described as novel integrations grounded in standard camera projection geometry rather than derived from prior fitted parameters or self-citations within the paper. The abstract and method description present the approach as an empirical proposal with reported benchmark results (33.00% IoU, 21.08% mIoU), without any equations or steps that reduce the claimed performance gains to quantities defined by construction from the inputs. No self-definitional loops, fitted-input-as-prediction patterns, or load-bearing self-citations are evident in the provided text. The derivation chain remains self-contained as a proposed method evaluated externally on SurroundOcc-nuScenes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The standard pinhole camera projection model accurately maps 3D points to image planes.
invented entities (2)
-
Projection-Aware Deformable Attention (PA-DA)
no independent evidence
-
view-quality semantic gate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PA-DA projects 3D offsets back to image planes and leverages the projection Jacobian as an additive bias to suppress unreliable observations... view-quality semantic gate for cross-view consistency
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sequential coarse-to-fine decoder with gated fusion... allocating computation by information density
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InCVPR, 2020
work page 2020
-
[3]
MonoScene: Monocular 3D semantic scene completion
Anh-Quan Cao and Raoul de Charette. MonoScene: Monocular 3D semantic scene completion. InCVPR, 2022
work page 2022
-
[4]
Gauss- Render: Learning 3D occupancy with Gaussian rendering
Loïck Chambon, Eloi Zablocki, Alexandre Boulch, Mickaël Chen, and Matthieu Cord. Gauss- Render: Learning 3D occupancy with Gaussian rendering. InICCV, 2025
work page 2025
-
[5]
Compact 3D Gaussian Splatting For Dense Visual SLAM
Tianchen Deng, Yaohui Chen, Leyan Zhang, Jianfei Yang, Shenghai Yuan, Jiuming Liu, Danwei Wang, Hesheng Wang, and Weidong Chen. Compact 3D Gaussian splatting for dense visual SLAM.arXiv preprint arXiv:2403.11247, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Tianchen Deng, Xun Chen, Ziming Li, Hongming Shen, Danwei Wang, Javier Civera, and Hesheng Wang. UniPR-3D: Towards universal visual place recognition with visual geometry grounded transformer.arXiv preprint arXiv:2512.21078, 2025
-
[7]
Tianchen Deng, Yue Pan, Shenghai Yuan, Dong Li, Chen Wang, Mingrui Li, Long Chen, Lihua Xie, Danwei Wang, Jingchuan Wang, Javier Civera, Hesheng Wang, and Weidong Chen. What is the best 3D scene representation for robotics? from geometric to foundation models.arXiv preprint arXiv:2512.03422, 2025
-
[8]
Tianchen Deng, Wenhua Wu, Kunzhen Wu, Guangming Wang, Siting Zhu, Shenghai Yuan, Xun Chen, Guole Shen, Zhe Liu, and Hesheng Wang. Reloc-VGGT: Visual re-localization with geometry grounded transformer.arXiv preprint arXiv:2512.21883, 2025
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
work page 2021
-
[10]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. BEVDet: High-performance multi-camera 3D object detection in bird-eye-view.arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Tri-perspective view for vision-based 3D semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision-based 3D semantic occupancy prediction. InCVPR, 2023
work page 2023
-
[12]
SelfOcc: Self- supervised vision-based 3D occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Borui Zhang, Jie Zhou, and Jiwen Lu. SelfOcc: Self- supervised vision-based 3D occupancy prediction. InCVPR, 2024
work page 2024
-
[13]
GaussianFormer: Scene as Gaussians for vision-based 3D semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. GaussianFormer: Scene as Gaussians for vision-based 3D semantic occupancy prediction. InECCV, 2024
work page 2024
-
[14]
GaussianFormer-2: Probabilistic Gaussian superposition for efficient 3D occupancy prediction
Yuanhui Huang, Amonnut Thammatadatrakoon, Wenzhao Zheng, Yunpeng Zhang, Dalong Du, and Jiwen Lu. GaussianFormer-2: Probabilistic Gaussian superposition for efficient 3D occupancy prediction. InCVPR, 2025
work page 2025
-
[15]
Far3D: Expanding the horizon for surround-view 3D object detection
Xiaohui Jiang, Shuailin Li, Yingfei Liu, Shihao Wang, Fan Jia, Tiancai Wang, Lijin Han, and Xiangyu Zhang. Far3D: Expanding the horizon for surround-view 3D object detection. InAAAI, 2024
work page 2024
-
[16]
3D Gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4), 2023
work page 2023
-
[17]
Yiming Li, Sihang Li, Xinhao Liu, Moonjun Gong, Kenan Li, Nuo Chen, Zijun Wang, Zhiheng Li, Tao Jiang, Fisher Yu, Yue Wang, Hang Zhao, Zhiding Yu, and Chen Feng. SSCBench: A large-scale 3D semantic scene completion benchmark for autonomous driving.arXiv preprint arXiv:2306.09001, 2023. 15
-
[18]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. InECCV, 2022
work page 2022
-
[19]
FB-OCC: 3D occupancy prediction based on forward-backward view transformation
Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, and Jose M Alvarez. FB-OCC: 3D occupancy prediction based on forward-backward view transformation. InCVPR Workshop on End-to-End Autonomous Driving, 2023
work page 2023
-
[20]
Xuewu Lin, Tianwei Lin, Zixiang Pei, Lichao Huang, and Zhizhong Su. Sparse4D: Multi-view 3D object detection with sparse spatial-temporal fusion.arXiv preprint arXiv:2211.10581, 2022
-
[21]
Fully sparse 3D occupancy prediction
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, and Limin Wang. Fully sparse 3D occupancy prediction. InECCV, 2024
work page 2024
-
[22]
PETR: Position embedding transfor- mation for multi-view 3D object detection
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. PETR: Position embedding transfor- mation for multi-view 3D object detection. InECCV, 2022
work page 2022
-
[23]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s. InCVPR, 2022
work page 2022
-
[24]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[25]
Cam4DOcc: Benchmark for camera-only 4D occupancy forecasting in autonomous driving applications
Junyi Ma, Xieyuanli Chen, Jiawei Huang, Jingyi Xu, Zhen Luo, Jintao Xu, Weihao Gu, Rui Ai, and Hesheng Wang. Cam4DOcc: Benchmark for camera-only 4D occupancy forecasting in autonomous driving applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21486–21495, 2024
work page 2024
-
[26]
3D occupancy prediction with low-resolution queries via prototype-aware view transformation
Gyeongrok Oh, Sungjune Kim, Heeju Ko, Hyung-gun Chi, Jinkyu Kim, Dongwook Lee, Daehyun Ji, Sungjoon Choi, Sujin Jang, and Sangpil Kim. 3D occupancy prediction with low-resolution queries via prototype-aware view transformation. InCVPR, 2025
work page 2025
-
[27]
DINOv2: Learning robust visual features without supervision.TMLR, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.TMLR, 2024
work page 2024
-
[28]
RenderOcc: Vision-centric 3D occupancy prediction with 2D rendering supervision
Mingjie Pan, Jiaming Liu, Renrui Zhang, Peixiang Huang, Xiaoqi Li, Hongwei Xie, Bing Wang, Li Liu, and Shanghang Zhang. RenderOcc: Vision-centric 3D occupancy prediction with 2D rendering supervision. InICRA, 2024
work page 2024
-
[29]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D. InECCV, 2020
work page 2020
-
[30]
Rui Qian, Haozhi Cao, Tianchen Deng, Tianxin Hu, Weixiang Guo, Shenghai Yuan, and Lihua Xie. TGSFormer: Scalable temporal Gaussian splatting for embodied semantic scene completion.arXiv preprint arXiv:2512.00300, 2025
-
[31]
SplatSSC: Decoupled depth-guided Gaussian splatting for semantic scene completion
Rui Qian, Haozhi Cao, Tianchen Deng, Shenghai Yuan, and Lihua Xie. SplatSSC: Decoupled depth-guided Gaussian splatting for semantic scene completion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 8520–8528, 2026
work page 2026
-
[32]
Orthographic feature transform for monocular 3D object detection
Thomas Roddick, Alex Kendall, and Roberto Cipolla. Orthographic feature transform for monocular 3D object detection. InBMVC, 2019
work page 2019
-
[33]
BePo: Dual representation for 3D occupancy prediction
Yunxiao Shi, Hong Cai, Jisoo Jeong, Yinhao Zhu, Shizhong Han, Amin Ansari, and Fatih Porikli. BePo: Dual representation for 3D occupancy prediction. InCVPR Workshop on Autonomous Driving, 2026
work page 2026
-
[34]
CTF-Occ: Coarse-to-fine 3D occupancy prediction
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yucheng Mao, Huitong Yang, Yue Wang, Yilun Wang, and Hang Zhao. CTF-Occ: Coarse-to-fine 3D occupancy prediction. InNeurIPS, 2023
work page 2023
-
[35]
Occ3D: A large-scale 3D occupancy prediction benchmark for autonomous driving
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yue Wang, Yilun Wang, and Hang Zhao. Occ3D: A large-scale 3D occupancy prediction benchmark for autonomous driving. InNeurIPS, 2023. 16
work page 2023
-
[36]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InCVPR, 2025
work page 2025
-
[37]
DETR3D: 3D object detection from multi-view images via 3D-to-2D queries
Yue Wang, Vitor Campagnolo Guizilini, Tianyuan Zhang, Yilun Wang, Hang Zhao, and Justin Solomon. DETR3D: 3D object detection from multi-view images via 3D-to-2D queries. In CoRL, 2021
work page 2021
-
[38]
PanoOcc: Unified occupancy representation for camera-based 3D panoptic segmentation
Yuqi Wang, Yuntao Chen, Xingyu Liao, Lue Fan, and Zhaoxiang Zhang. PanoOcc: Unified occupancy representation for camera-based 3D panoptic segmentation. InCVPR, 2024
work page 2024
-
[39]
SurroundOcc: Multi-camera 3D occupancy prediction for autonomous driving
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. SurroundOcc: Multi-camera 3D occupancy prediction for autonomous driving. InICCV, 2023
work page 2023
-
[40]
Huaiyuan Xu, Junliang Chen, Shiyu Meng, Yi Wang, and Lap-Pui Chau. A survey on occupancy perception for autonomous driving: The information fusion perspective.Information Fusion, 114:102671, 2025
work page 2025
-
[41]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
work page 2024
-
[42]
Zichen Yu, Changyong Shu, Jiajun Deng, Kangjie Lu, Zongdai Liu, Jiangyong Yu, Dawei Yang, Hui Li, and Yan Chen. FlashOcc: Fast and memory-efficient occupancy prediction via channel-to-height plugin.arXiv preprint arXiv:2311.12058, 2023
-
[43]
SQS: Enhancing sparse perception models via query-based splatting in autonomous driving
Haiming Zhang, Yiyao Zhu, Wending Zhou, Xu Yan, Yingjie Cai, Bingbing Liu, Shuguang Cui, and Zhen Li. SQS: Enhancing sparse perception models via query-based splatting in autonomous driving. InNeurIPS, 2025
work page 2025
-
[44]
Yanan Zhang, Jinqing Zhang, Zengran Wang, Junhao Xu, and Di Huang. Vision-based 3D occupancy prediction in autonomous driving: a review and outlook.Frontiers of Computer Science, 20:2001301, 2026
work page 2026
-
[45]
OccFormer: Dual-path transformer for vision- based 3D semantic occupancy prediction
Yunpeng Zhang, Zheng Zhu, and Dalong Du. OccFormer: Dual-path transformer for vision- based 3D semantic occupancy prediction. InICCV, 2023
work page 2023
-
[46]
Lingjun Zhao, Sizhe Wei, James Hays, and Lu Gan. GaussianFormer3D: Multi-modal Gaussian- based semantic occupancy prediction with 3D deformable attention. InICRA, 2026
work page 2026
-
[47]
Deformable DETR: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: Deformable transformers for end-to-end object detection. InICLR, 2021
work page 2021
-
[48]
Dr.Occ: Depth- and region-guided 3D occupancy from surround-view cameras for autonomous driving
Xubo Zhu, Haoyang Zhang, Fei He, Rui Wu, Yanhu Shan, Wen Yang, and Huai Yu. Dr.Occ: Depth- and region-guided 3D occupancy from surround-view cameras for autonomous driving. InCVPR, 2026
work page 2026
-
[49]
QuadricFormer: Scene as superquadrics for 3D semantic occupancy prediction
Sicheng Zuo, Wenzhao Zheng, Xiaoyong Han, Longchao Yang, Yong Pan, and Jiwen Lu. QuadricFormer: Scene as superquadrics for 3D semantic occupancy prediction. InNeurIPS, 2025
work page 2025
-
[50]
GaussianWorld: Gaussian world model for streaming 3D occupancy prediction
Sicheng Zuo, Wenzhao Zheng, Yuanhui Huang, Jie Zhou, and Jiwen Lu. GaussianWorld: Gaussian world model for streaming 3D occupancy prediction. InCVPR, 2025. 17
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.