Tempered Self-Similarity Alignment for Physically Plausible Video Generation
Pith reviewed 2026-06-30 11:36 UTC · model grok-4.3
The pith
Aligning spatio-temporal self-similarity from foundation models makes generated videos more physically plausible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
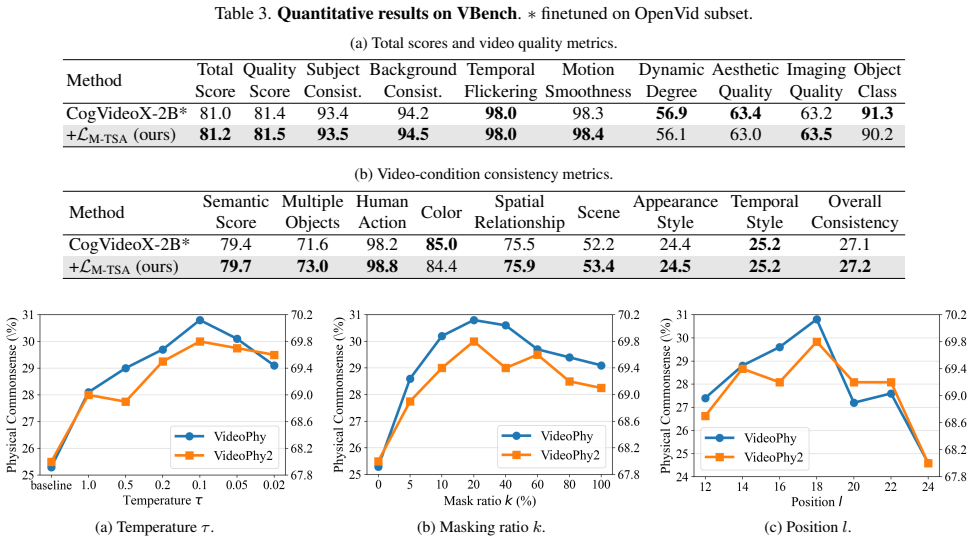
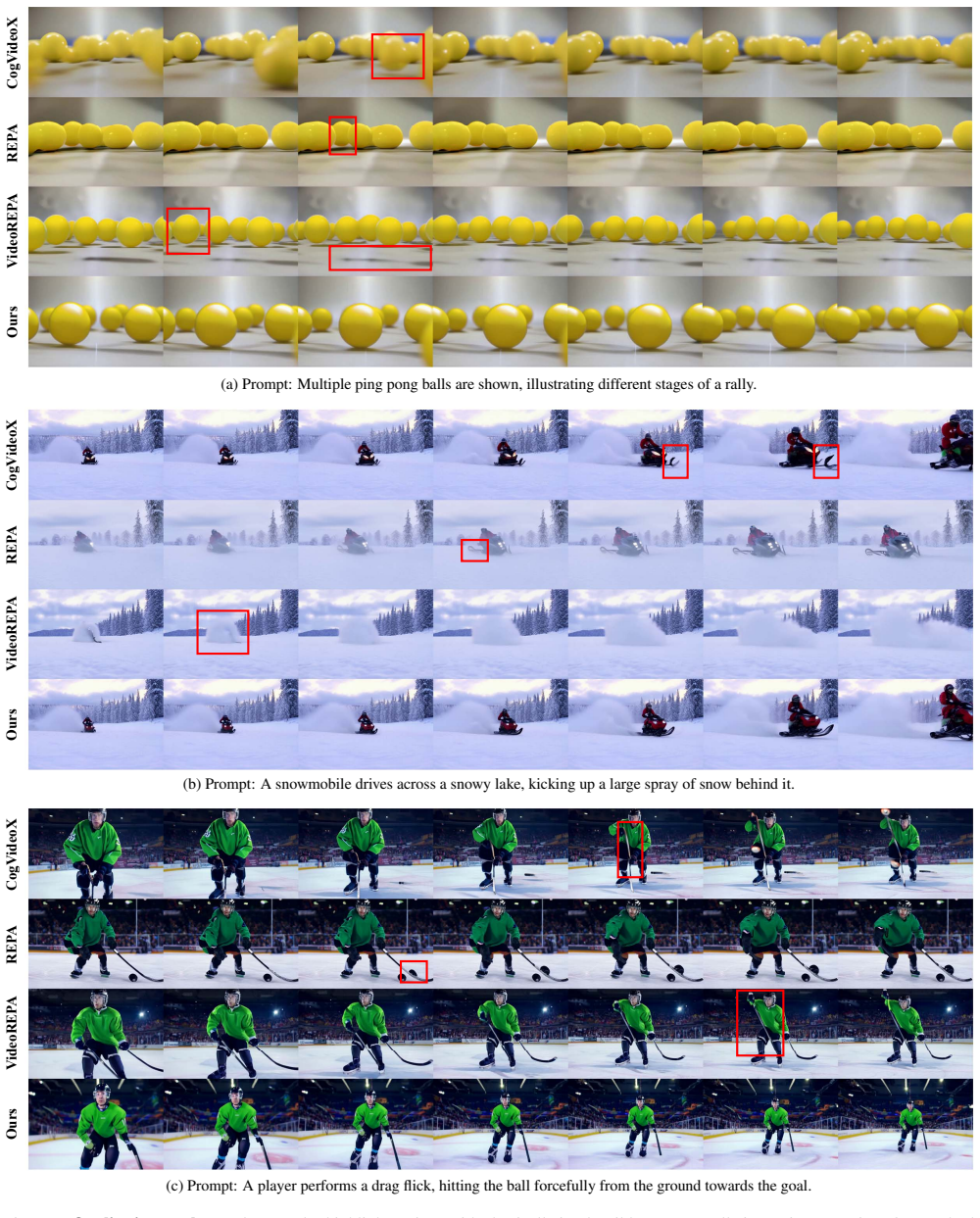
Transferring relational knowledge encoded in spatio-temporal self-similarity from visual foundation models into video generative models via TSA loss produces substantial improvements in physical plausibility across diverse interaction scenarios on VideoPhy and VideoPhy2.
What carries the argument
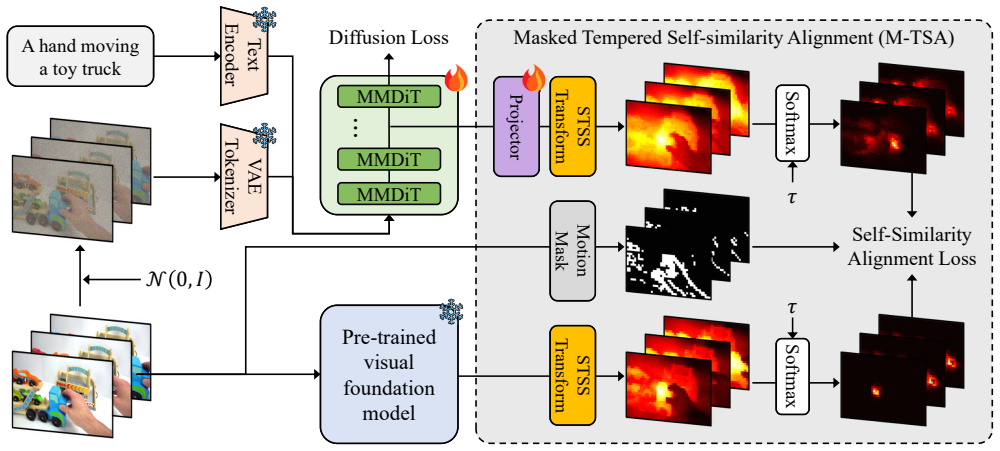
Tempered Self-similarity Alignment (TSA) loss, which transforms pairwise feature similarities into probabilistic correspondence distributions and aligns the generative model on dynamically changing regions.
If this is right
- Substantial improvements in physical plausibility occur on VideoPhy and VideoPhy2 benchmarks.
- The method applies across diverse interaction scenarios without explicit physics modeling.
- Appearance drift, implausible motion, and temporal inconsistencies decrease when correspondence distributions are matched.
- Relational knowledge transfers from foundation models suffice to enforce real-world dynamics inside generative models.
Where Pith is reading between the lines
- Self-similarity patterns may implicitly encode dynamics that could be reused in other generative domains such as 3D or audio synthesis.
- The alignment technique might be combined with existing motion or consistency losses for additive gains.
- Testing on longer video sequences could reveal whether the relational transfer scales beyond short clips.
Load-bearing premise
Pairwise feature similarities computed by an off-the-shelf visual foundation model on real video already encode the physical interaction rules needed for plausible generation.
What would settle it
Generate videos with and without the TSA loss on the same set of prompts involving object interactions, then measure whether the rate of physical violations remains unchanged.
Figures



read the original abstract
Despite remarkable advances in video generative models, they still struggle to generate physically realistic videos, frequently exhibiting appearance drift, implausible motion, and temporal inconsistencies. In this work, we address this limitation by transferring relational knowledge encoded in spatio-temporal self-similarity (STSS) from visual foundation models into video generative models. STSS represents pairwise similarities among features across space and time, revealing the relational structure of how objects interact with other entities throughout a video, effectively capturing real-world dynamics, including object motion and semantic transformations. To transfer this relational knowledge, we propose Tempered Self-similarity Alignment (TSA) loss, which transforms STSS into probabilistic correspondence distributions and trains the video generative model to align its correspondence distributions with those of the visual foundation model on dynamically changing regions. Evaluated on VideoPhy and VideoPhy2 benchmarks, our method demonstrates substantial improvements in physical plausibility across diverse interaction scenarios, validating the effectiveness of transferring relational knowledge for physically realistic video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transferring relational knowledge encoded in spatio-temporal self-similarity (STSS) from visual foundation models into video generative models via a Tempered Self-Similarity Alignment (TSA) loss produces substantial improvements in physical plausibility across diverse interaction scenarios on the VideoPhy and VideoPhy2 benchmarks.
Significance. If the central claim holds and the TSA loss demonstrably enforces physical interaction rules (rather than merely appearance consistency), the work would offer a practical mechanism for improving dynamics in video generation without requiring explicit physics simulators.
major comments (2)
- [Abstract] Abstract: the claim of 'substantial improvements' is presented without any quantitative metrics, ablation results, or description of how the TSA loss is implemented or regularized, so the data-to-claim link cannot be verified.
- [Method] Method (TSA loss definition): no evidence is provided that the correspondence distributions derived from off-the-shelf VFM features on dynamically changing regions differ systematically between physically valid and invalid videos, leaving open the possibility that alignment primarily suppresses appearance drift rather than correcting implausible dynamics such as collisions or conservation violations.
minor comments (1)
- The abstract and method would benefit from explicit equations for the transformation of STSS into probabilistic correspondence distributions and the precise form of the tempered alignment objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantial improvements' is presented without any quantitative metrics, ablation results, or description of how the TSA loss is implemented or regularized, so the data-to-claim link cannot be verified.
Authors: We agree that the abstract would be strengthened by including supporting details. In the revised version, we will incorporate key quantitative metrics from the VideoPhy and VideoPhy2 evaluations, reference main ablation findings, and add a brief description of the TSA loss formulation and regularization approach. revision: yes
-
Referee: [Method] Method (TSA loss definition): no evidence is provided that the correspondence distributions derived from off-the-shelf VFM features on dynamically changing regions differ systematically between physically valid and invalid videos, leaving open the possibility that alignment primarily suppresses appearance drift rather than correcting implausible dynamics such as collisions or conservation violations.
Authors: The TSA loss is deliberately restricted to dynamically changing regions to emphasize relational structures tied to motion and interactions. The consistent gains on VideoPhy and VideoPhy2 benchmarks—which explicitly measure physical plausibility aspects such as collisions and conservation—indicate that the alignment improves dynamics rather than only suppressing appearance changes. We will add a supporting analysis of correspondence distribution differences between valid and invalid videos in the revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present TSA as an alignment loss that transforms STSS into correspondence distributions and matches them between a frozen VFM and the generative model on dynamic regions. No equations, fitting procedures, or self-citations appear in the text that would reduce any claimed result to an input by construction. The method is defined directly as the proposed transfer mechanism and evaluated on external benchmarks (VideoPhy, VideoPhy2), with no self-definitional loops, renamed known results, or load-bearing self-citations. The derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Tempered Self-similarity Alignment (TSA) loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai- Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024. 1, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Golden- berg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025. 1, 2, 5
-
[4]
Aritra Bhowmik, Denis Korzhenkov, Cees GM Snoek, Amirhossein Habibian, and Mohsen Ghafoorian. Moalign: Motion-centric representation alignment for video diffusion models.arXiv preprint arXiv:2510.19022, 2025. 1
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 1, 2
2024
-
[7]
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for en- hanced motion generation in video models.arXiv preprint arXiv:2502.02492, 2025. 1, 2
-
[8]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, pages 7310–7320, 2024. 6
2024
-
[9]
A semi- implicit material point method for the continuum simula- tion of granular materials.ACM Transactions on Graphics (TOG), 35(4):1–13, 2016
Gilles Daviet and Florence Bertails-Descoubes. A semi- implicit material point method for the continuum simula- tion of granular materials.ACM Transactions on Graphics (TOG), 35(4):1–13, 2016. 2
2016
-
[10]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation with- out vector quantization.arXiv preprint arXiv:2412.14169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning,
-
[12]
Relational rep- resentation distillation.arXiv preprint arXiv:2407.12073,
Nikolaos Giakoumoglou and Tania Stathaki. Relational rep- resentation distillation.arXiv preprint arXiv:2407.12073,
-
[13]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 6
2024
-
[15]
Sungwon Hwang, Hyojin Jang, Kinam Kim, Minho Park, and Jaegul Choo. Cross-frame representation alignment for fine-tuning video diffusion models.arXiv preprint arXiv:2506.09229, 2025. 2, 3
-
[16]
Track4gen: Teaching video dif- fusion models to track points improves video generation
Hyeonho Jeong, Chun-Hao P Huang, Jong Chul Ye, Niloy J Mitra, and Duygu Ceylan. Track4gen: Teaching video dif- fusion models to track points improves video generation. In CVPR, pages 7276–7287, 2025. 1, 2
2025
-
[17]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954,
-
[18]
Cross-view action recognition from temporal self- similarities
Imran N Junejo, Emilie Dexter, Ivan Laptev, and Patrick P ´Urez. Cross-view action recognition from temporal self- similarities. InECCV, 2008. 2
2008
-
[19]
View-independent action recognition from temporal self-similarities.IEEE TPAMI, 2010
Imran N Junejo, Emilie Dexter, Ivan Laptev, and Patrick Perez. View-independent action recognition from temporal self-similarities.IEEE TPAMI, 2010. 2
2010
-
[20]
Relational embedding for few-shot classification
Dahyun Kang, Heeseung Kwon, Juhong Min, and Minsu Cho. Relational embedding for few-shot classification. In ICCV, pages 8822–8833, 2021. 2
2021
-
[21]
Relational self-attention: What’s missing in attention for video understanding.NeurIPS, 34:8046–8059,
Manjin Kim, Heeseung Kwon, Chunyu Wang, Suha Kwak, and Minsu Cho. Relational self-attention: What’s missing in attention for video understanding.NeurIPS, 34:8046–8059,
-
[22]
Learning correlation structures for vision trans- formers
Manjin Kim, Paul Hongsuck Seo, Cordelia Schmid, and Minsu Cho. Learning correlation structures for vision trans- formers. InCVPR, pages 18941–18951, 2024. 2
2024
-
[23]
Fcss: Fully con- volutional self-similarity for dense semantic correspondence
Seungryong Kim, Dongbo Min, Bumsub Ham, Sangryul Jeon, Stephen Lin, and Kwanghoon Sohn. Fcss: Fully con- volutional self-similarity for dense semantic correspondence. InCVPR, 2017. 2
2017
-
[24]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 1, 2, 3, 6, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Heeseung Kwon, Manjin Kim, Suha Kwak, and Minsu Cho. Motionsqueeze: Neural motion feature learning for video understanding.arXiv preprint arXiv:2007.09933, 2020. 2
-
[26]
Heeseung Kwon, Manjin Kim, Suha Kwak, and Minsu Cho. Learning self-similarity in space and time as gen- eralized motion for action recognition.arXiv preprint arXiv:2102.07092, 2021. 2
-
[27]
REPA-E: Unlocking V AE for end-to-end tuning with latent diffusion transformers,
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers. arXiv preprint arXiv:2504.10483, 2025. 3
-
[28]
Jiajing Lin, Zhenzhong Wang, Yongjie Hou, Yuzhou Tang, and Min Jiang. Phy124: Fast physics-driven 4d con- tent generation from a single image.arXiv preprint arXiv:2409.07179, 2024. 1, 2
-
[29]
Phys4dgen: A physics-driven framework for con- trollable and efficient 4d content generation from a single image.arXiv e-prints, pages arXiv–2411, 2024
Jiajing Lin, Zhenzhong Wang, Shu Jiang, Yongjie Hou, and Min Jiang. Phys4dgen: A physics-driven framework for con- trollable and efficient 4d content generation from a single image.arXiv e-prints, pages arXiv–2411, 2024. 1, 2
2024
-
[30]
Physgen: Rigid-body physics-grounded image- to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shen- long Wang. Physgen: Rigid-body physics-grounded image- to-video generation. InECCV, pages 360–378. Springer, 2024
2024
-
[31]
Unleashing the potential of multi-modal foun- dation models and video diffusion for 4d dynamic physical scene simulation
Zhuoman Liu, Weicai Ye, Yan Luximon, Pengfei Wan, and Di Zhang. Unleashing the potential of multi-modal foun- dation models and video diffusion for 4d dynamic physical scene simulation. InCVPR, pages 11016–11025, 2025. 1, 2
2025
-
[32]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Dream machine — ai video generator, 2024
Luma AI. Dream machine — ai video generator, 2024. 6
2024
-
[34]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quan- feng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Motioncraft: Physics- based zero-shot video generation.Advances in Neural In- formation Processing Systems, 37:123155–123181, 2024
Antonio Montanaro, Luca Savant Aira, Emanuele Aiello, Diego Valsesia, and Enrico Magli. Motioncraft: Physics- based zero-shot video generation.Advances in Neural In- formation Processing Systems, 37:123155–123181, 2024. 1, 2
2024
-
[36]
Do generative video models understand physical principles?
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models learn physical principles from watching videos?, 2025.URL https://arxiv. org/abs/2501.09038, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Relational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3967–3976, 2019. 2
2019
-
[40]
A material point method for viscoelastic fluids, foams and sponges
Daniel Ram, Theodore Gast, Chenfanfu Jiang, Craig Schroeder, Alexey Stomakhin, Joseph Teran, and Pirouz Kavehpour. A material point method for viscoelastic fluids, foams and sponges. InProceedings of the 14th ACM SIG- GRAPH/Eurographics Symposium on Computer Animation, pages 157–163, 2015. 2
2015
-
[41]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 3
2022
-
[42]
Space-time behavior based correlation
Eli Shechtman and Michal Irani. Space-time behavior based correlation. InCVPR, pages 405–412. IEEE, 2005. 2
2005
-
[43]
Matching local self- similarities across images and videos
Eli Shechtman and Michal Irani. Matching local self- similarities across images and videos. InCVPR, 2007. 2
2007
-
[44]
A material point method for snow simulation.ACM Transactions on Graphics (TOG), 32(4): 1–10, 2013
Alexey Stomakhin, Craig Schroeder, Lawrence Chai, Joseph Teran, and Andrew Selle. A material point method for snow simulation.ACM Transactions on Graphics (TOG), 32(4): 1–10, 2013. 2
2013
-
[45]
Local self-similarity-based registration of human rois in pairs of stereo thermal-visible videos.Pattern Recognition, 46(2): 578–589, 2013
Atousa Torabi and Guillaume-Alexandre Bilodeau. Local self-similarity-based registration of human rois in pairs of stereo thermal-visible videos.Pattern Recognition, 46(2): 578–589, 2013. 2
2013
-
[46]
Similarity-preserving knowl- edge distillation
Frederick Tung and Greg Mori. Similarity-preserving knowl- edge distillation. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1365–1374,
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Video modeling with correlation networks
Heng Wang, Du Tran, Lorenzo Torresani, and Matt Feiszli. Video modeling with correlation networks. InCVPR, 2020. 2
2020
-
[49]
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, et al. Wisa: World simulator assistant for physics-aware text-to-video generation.arXiv preprint arXiv:2503.08153, 2025. 1, 2
-
[50]
Videomae v2: Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae v2: Scaling video masked autoencoders with dual masking. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14549–14560, 2023. 5
2023
-
[51]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Geometry forcing: Marrying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
What can simple arithmetic opera- tions do for temporal modeling? InICCV, pages 13712– 13722, 2023
Wenhao Wu, Yuxin Song, Zhun Sun, Jingdong Wang, Chang Xu, and Wanli Ouyang. What can simple arithmetic opera- tions do for temporal modeling? InICCV, pages 13712– 13722, 2023. 2
2023
-
[53]
Physgaussian: Physics- integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics- integrated 3d gaussians for generative dynamics. InCVPR, pages 4389–4398, 2024. 1, 2
2024
-
[54]
Physanimator: Physics-guided generative cartoon animation
Tianyi Xie, Yiwei Zhao, Ying Jiang, and Chenfanfu Jiang. Physanimator: Physics-guided generative cartoon animation. InCVPR, pages 10793–10804, 2025. 1, 2
2025
-
[55]
Phyt2v: Llm-guided iterative self-refinement for physics- grounded text-to-video generation
Qiyao Xue, Xiangyu Yin, Boyuan Yang, and Wei Gao. Phyt2v: Llm-guided iterative self-refinement for physics- grounded text-to-video generation. InCVPR, pages 18826– 18836, 2025. 1, 2, 6
2025
-
[56]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1, 2, 3, 5, 6, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
From slow bidirectional to fast causal video generators.arXiv e- prints, pages arXiv–2412, 2024
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast causal video generators.arXiv e- prints, pages arXiv–2412, 2024. 1, 2
2024
-
[58]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffu- sion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 2, 3, 6, 7, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Sergey Zagoruyko and Nikos Komodakis. Paying more at- tention to attention: Improving the performance of convolu- tional neural networks via attention transfer.arXiv preprint arXiv:1612.03928, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[60]
Physdreamer: Physics-based interac- tion with 3d objects via video generation
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T Freeman. Physdreamer: Physics-based interac- tion with 3d objects via video generation. InECCV, pages 388–406. Springer, 2024. 1, 2
2024
-
[61]
Vrm: Knowledge distillation via virtual relation matching
Weijia Zhang, Fei Xie, Weidong Cai, and Chao Ma. Vrm: Knowledge distillation via virtual relation matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2707–2717, 2025. 2
2025
-
[62]
arXiv preprint arXiv:2505.23656 (2025)
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. Vide- orepa: Learning physics for video generation through re- lational alignment with foundation models.arXiv preprint arXiv:2505.23656, 2025. 2, 3, 4, 5, 6, 7, 12 A. Additional Qualitative Results In Fig. 7, we provide additional qualitative comparisons o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.