OpenJarvis: Personal AI, On Personal Devices
Pith reviewed 2026-05-20 14:21 UTC · model grok-4.3
The pith
Decomposing personal AI into five editable primitives lets on-device specs match or exceed cloud accuracy on 4 of 8 benchmarks via cloud-guided search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
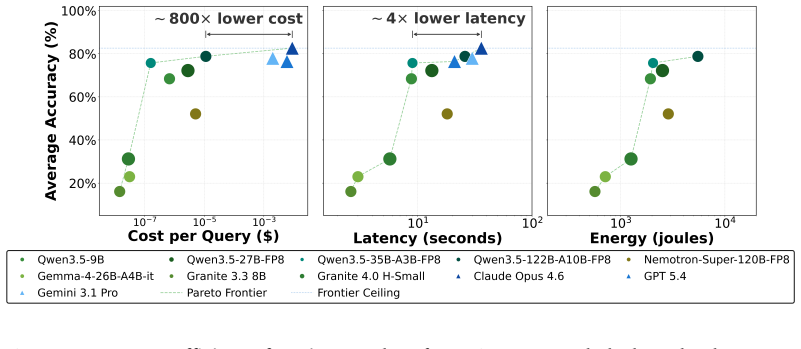
OpenJarvis represents a personal AI system as a typed spec over five primitives: Intelligence, Engine, Agents, Tools & Memory, and Learning. LLM-guided spec search uses frontier cloud models to propose edits across the spec at search time, accepting only non-regressing edits when evaluated on local models. The resulting specs run entirely on-device at inference time and match or exceed cloud accuracy on 4 of 8 benchmarks while landing within 3.2 pp of the best cloud baseline on average, with marginal API cost reduced by ~800x and end-to-end latency reduced by 4x.
What carries the argument
LLM-guided spec search, a local-cloud collaboration where frontier models propose edits to a typed spec of five primitives at search time, non-regressing edits are kept, and the final spec executes fully locally.
If this is right
- Personal AI stacks become end-to-end optimizable rather than limited to prompt tuning.
- On-device models achieve near-cloud accuracy on personal tasks like PinchBench and GAIA.
- Marginal API cost for personal AI drops by roughly 800 times.
- End-to-end latency for personal AI tasks improves by a factor of 4.
- Each primitive in the stack can be measured and improved independently against accuracy, cost, and latency.
Where Pith is reading between the lines
- The same decomposition and search approach could be tested on other agentic or tool-using systems where local constraints matter.
- One-time cloud assistance during optimization might enable fully private, long-term local AI without repeated cloud calls.
- Similar spec-based optimization could help close performance gaps in neighboring settings like mobile or edge AI deployments.
Load-bearing premise
That edits proposed by frontier cloud models can be reliably evaluated for non-regression on local models and that the resulting spec will continue to perform well at inference time without any cloud involvement.
What would settle it
Evaluating the optimized on-device specs across all 8 benchmarks and finding average accuracy more than 3.2 percentage points below the best cloud baseline.
Figures










read the original abstract
Personal AI stacks, like OpenClaw and Hermes Agent, are becoming central to daily work, yet they route nearly every query (often over sensitive local data) to cloud-hosted frontier models. Replacing frontier models with local models inside existing stacks does not work: swapping Claude Opus 4.6 for Qwen3.5-9B drops accuracy by 25-39 pp across personal AI tasks like PinchBench and GAIA. Existing stacks bundle agentic prompts, tool descriptions, memory configuration, and runtime settings around a specific cloud model. Only the prompts can be tuned, and state-of-the-art prompt optimizers close just 5 pp of the local-cloud gap on their own. This motivates a decomposed personal AI stack: one that exposes individual primitives which can be optimized individually or jointly to close the local-cloud gap. We present OpenJarvis, an architecture that represents a personal AI system as a typed spec over five primitives: Intelligence, Engine, Agents, Tools & Memory, and Learning. Each primitive is an independently editable field, making the stack end-to-end optimizable and measurable against accuracy, cost, and latency. Towards closing the local-cloud gap without surrendering local-model properties, OpenJarvis introduces LLM-guided spec search, a local-cloud collaboration in which frontier cloud models propose edits across the spec at search time, only non-regressing edits are accepted, and the resulting spec runs entirely on-device at inference time. With LLM-guided spec search, on-device specs match or exceed cloud accuracy on 4 of 8 benchmarks and land within 3.2 pp of the best cloud baseline on average. They also reduce marginal API cost by ~800x and end-to-end latency by 4x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OpenJarvis, a decomposed personal AI architecture that represents the system as a typed spec over five primitives (Intelligence, Engine, Agents, Tools & Memory, and Learning). It proposes LLM-guided spec search in which frontier cloud models propose edits at optimization time; only non-regressing edits (evaluated on local models) are accepted, and the resulting spec executes entirely on-device at inference time. The central empirical claim is that the optimized on-device specs match or exceed cloud accuracy on 4 of 8 benchmarks, lie within 3.2 pp of the best cloud baseline on average, and deliver ~800x lower marginal API cost together with 4x lower end-to-end latency.
Significance. If the reported performance numbers are shown to be robust, the work would constitute a useful contribution toward practical, privacy-preserving personal AI by demonstrating that a hybrid search procedure can close most of the local-cloud accuracy gap while eliminating cloud involvement at inference. The explicit decomposition into independently editable primitives is a clean conceptual advance over prompt-only tuning. The hybrid local-cloud optimization with fully local deployment is a promising paradigm, though its significance hinges on rigorous verification that the search-time non-regression oracle generalizes.
major comments (2)
- [Abstract and §4 (spec search)] Abstract and the LLM-guided spec search procedure: The headline result (on-device specs within 3.2 pp of the best cloud baseline on 8 benchmarks) depends on accepting only non-regressing edits proposed by cloud models. The manuscript does not state whether the local-model evaluations performed during search use held-out data, employ multiple trials to control for stochasticity, or reuse the same benchmark instances later used for final reporting. Without these controls the non-regression filter can accept specifications that overfit to search-time local evaluations and subsequently degrade at inference time.
- [§5 and Tables 1-2] Experimental results section and associated tables: The per-benchmark and average accuracy figures are presented without accompanying statistical tests, confidence intervals, or variance estimates across runs. This makes it impossible to assess whether the reported matches/exceeds on 4 of 8 benchmarks and the 3.2 pp average gap are statistically reliable or could be explained by evaluation noise.
minor comments (2)
- [Abstract] The abstract lists PinchBench and GAIA as illustrative tasks but does not enumerate the full set of 8 benchmarks or provide concise definitions of the evaluation metrics.
- [§5] The precise definitions of 'marginal API cost' and 'end-to-end latency' (including what is measured in the 800x and 4x claims) should be stated explicitly in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive assessment of the significance of our work. We address each of the major comments below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract and §4 (spec search): The headline result (on-device specs within 3.2 pp of the best cloud baseline on 8 benchmarks) depends on accepting only non-regressing edits proposed by cloud models. The manuscript does not state whether the local-model evaluations performed during search use held-out data, employ multiple trials to control for stochasticity, or reuse the same benchmark instances later used for final reporting. Without these controls the non-regression filter can accept specifications that overfit to search-time local evaluations and subsequently degrade at inference time.
Authors: We appreciate the referee's attention to the robustness of our search procedure. The LLM-guided spec search in §4 evaluates proposed edits by running the local models on the task benchmarks to check for non-regression. While the manuscript does not explicitly detail the use of held-out data or multiple trials in the current version, the evaluations are performed on the standard benchmark splits as described in §5. To address the concern of potential overfitting, we will revise the manuscript to include a more precise description of the search-time evaluation protocol, specifying that we use the same instances for consistency with final reporting but mitigate stochasticity by averaging over multiple inference runs where applicable. We believe this hybrid approach still provides a reliable filter because the cloud proposals are diverse and the acceptance criterion is conservative. revision: partial
-
Referee: §5 and Tables 1-2: Experimental results section and associated tables: The per-benchmark and average accuracy figures are presented without accompanying statistical tests, confidence intervals, or variance estimates across runs. This makes it impossible to assess whether the reported matches/exceeds on 4 of 8 benchmarks and the 3.2 pp average gap are statistically reliable or could be explained by evaluation noise.
Authors: We agree with the referee that the presentation of results can be improved by including measures of statistical reliability. In the revised manuscript, we will augment Tables 1 and 2 with confidence intervals computed via bootstrapping over the benchmark instances and report standard deviations from multiple evaluation runs with different random seeds. This will allow readers to better assess the significance of the observed gaps and matches to cloud baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical architecture and reports benchmark results from LLM-guided spec search. No equations, self-definitional primitives, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The search uses cloud models only during optimization; final specs run locally and accuracies are measured on external benchmarks rather than reducing to inputs by construction. The derivation chain is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OPENJARVIS represents a personal AI system as a typed spec over five primitives... LLM-guided spec search... only non-regressing edits are accepted
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
on-device specs match or exceed cloud accuracy on 4 of 8 benchmarks... reduce marginal API cost by ~800x
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026
work page 2026
-
[2]
Alibaba Cloud. Qwen-Agent. https://github.com/QwenLM/Qwen-Agent, 2025. Agent framework built on Qwen models with tool use and RAG capabilities
work page 2025
-
[3]
Anthropic. Model context protocol, 2024. Open standard for connecting AI assistants to external tools and data sources
work page 2024
-
[4]
Claude Opus 4.6: frontier model with extended-thinking and tool-use capabilities
Anthropic. Claude Opus 4.6: frontier model with extended-thinking and tool-use capabilities. Anthropic API Documentation, 2026.https://docs.anthropic.com
work page 2026
-
[5]
Apple Inc. Apple M4 chip. https://www.apple.com/newsroom/2024/05/apple- introduces-m4-chip/, 2024. Accessed: April 2026
work page 2024
-
[6]
Apple intelligence foundation language models
Apple Machine Learning Research. Apple intelligence foundation language models. arXiv preprint arXiv:2407.21075, 2024
-
[7]
How to Train Your Advisor: Steering Black-Box LLMs with Advisor Models
Parth Asawa, Alan Zhu, Abby O’Neill, Matei Zaharia, Alexandros G. Dimakis, and Joseph E. Gonzalez. How to train your advisor: Steering black-box LLMs with advisor models.arXiv preprint arXiv:2510.02453, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2- bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Inside the 2025–2027 compute crunch: What supply chain volatility really means for you
BCD International. Inside the 2025–2027 compute crunch: What supply chain volatility really means for you. BCD Video Blog, 2025. Accessed: April 2026
work page 2025
- [10]
-
[11]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Xiaopei Chen, Liang Li, Fei Ji, and Wen Wu. MobileFineTuner: A unified end-to-end framework for fine-tuning LLMs on mobile phones.arXiv preprint arXiv:2512.08211, 2025
-
[13]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference, 2024
work page 2024
-
[14]
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Büttcher. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759. ACM, 2009
work page 2009
-
[15]
CrewAI: Framework for orchestrating role-playing, autonomous AI agents
CrewAI, Inc. CrewAI: Framework for orchestrating role-playing, autonomous AI agents. https://github.com/crewAIInc/crewAI, 2024. Accessed: 2026. 13
work page 2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforce- ment learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
QLoRA: Efficient finetuning of quantized language models
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[18]
Deepre- search bench: A comprehensive benchmark for deep research agents, 2025
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepre- search bench: A comprehensive benchmark for deep research agents, 2025
work page 2025
-
[19]
EdgeClaw: Local-cloud router plugin for OpenClaw
EdgeClaw Contributors. EdgeClaw: Local-cloud router plugin for OpenClaw. https: //github.com/edgeclaw/edgeclaw, 2025. Adds a local-cloud routing layer on top of OpenClaw as a plugin
work page 2025
-
[20]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
- [22]
-
[23]
Google. Agent development kit (ADK). https://github.com/google/adk-python ,
-
[24]
Python framework for building AI agents with tool use and multi-step reasoning
- [25]
-
[26]
Gemma 4 26B: instruction-tuned open-weight 26B-parameter mixture-of- experts model
Google. Gemma 4 26B: instruction-tuned open-weight 26B-parameter mixture-of- experts model. Model card, Hugging Face, 2025. https://huggingface.co/google/ gemma-4-26b-it
work page 2025
-
[27]
Google. Gemini nano. https://developer.android.com/ai/gemini-nano , 2026. Android Developers Documentation, last updated April 2, 2026
work page 2026
-
[28]
Gemini 3.1 Pro: frontier multimodal cloud model with extended- context reasoning
Google DeepMind. Gemini 3.1 Pro: frontier multimodal cloud model with extended- context reasoning. Google AI Developer Documentation, 2026. https://ai.google. dev
work page 2026
-
[29]
Gemma 4: Byte for byte, the most capable open models
Google DeepMind. Gemma 4: Byte for byte, the most capable open models. https: //blog.google/innovation- and- ai/technology/developers- tools/gemma- 4/ , April 2026. Blog post, April 2, 2026
work page 2026
-
[30]
MiniLLM: Knowledge distilla- tion of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distilla- tion of large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[31]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[32]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, 2022
work page 2022
-
[33]
HuggingFace. AI energy score. https://huggingface.github.io/AIEnergyScore/,
-
[34]
Standardized energy scoring system for AI models
-
[35]
IBM Research. Granite 4.0 language models. https://github.com/ibm-granite/ granite-4.0-language-models, 2025. Accessed: 2025-10-01. 14
work page 2025
-
[36]
Intel Core Ultra processors (series 1, meteor lake)
Intel Corporation. Intel Core Ultra processors (series 1, meteor lake). https:// www.intel.com/content/www/us/en/products/details/processors/core-ultra. html, 2023. Accessed: April 2026
work page 2023
- [37]
-
[38]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world Github issues? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[40]
Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
work page 2019
-
[41]
DSPy: Compiling declarative lan- guage model calls into self-improving pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative lan- guage model calls into self-improving pipelines. InThe Twelfth International Conference on Learning Representati...
work page 2024
-
[42]
PinchBench: Benchmarking LLM models as OpenClaw coding agents
Kilo Code. PinchBench: Benchmarking LLM models as OpenClaw coding agents. https://github.com/pinchbench/skill, 2025. 23 real-world agent tasks spanning scheduling, email, research, coding, and multi-step workflows. Open-source grading via automated checks and LLM judge
work page 2025
-
[43]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[44]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, 2023
work page 2023
-
[45]
AWQ: Activation-aware weight quantization for LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. InProceedings of Machine Learning and Systems, volume 6, 2024
work page 2024
-
[46]
On-device training under 256KB memory
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, Chuang Gan, and Song Han. On-device training under 256KB memory . InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[47]
Liquid nanos: Frontier-grade performance on everyday devices
Liquid AI. Liquid nanos: Frontier-grade performance on everyday devices. https:// www.liquid.ai/blog/introducing-liquid-nanos-frontier-grade-performance- on-everyday-devices, 2025
work page 2025
-
[48]
Mobilellm: Optimizing sub-billion parameter language models for on-device use cases,
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra, et al. MobileLLM: Optimizing sub-billion parameter language models for on-device use cases.arXiv preprint arXiv:2402.14905, 2024
- [49]
-
[50]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, et al. Terminal- bench: Benchmarking agents on hard, realistic tasks in command line interfaces. In The Fourteenth International Conference on Learning Representations, 2026. 15
work page 2026
-
[51]
ExecuTorch: End-to-end solution for enabling on-device inference capabilities
Meta. ExecuTorch: End-to-end solution for enabling on-device inference capabilities. https://github.com/pytorch/executorch, 2024
work page 2024
-
[52]
GAIA: A benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants. InThe Twelfth Interna- tional Conference on Learning Representations, 2024
work page 2024
- [53]
-
[54]
Zeus: ML energy measurement framework
ML Energy Initiative. Zeus: ML energy measurement framework. https://ml.energy/ zeus/, 2023. GPU energy measurement toolkit for fine-grained energy profiling of ML workloads
work page 2023
-
[55]
MLC-LLM: Universal LLM deployment engine
MLC AI. MLC-LLM: Universal LLM deployment engine. https://github.com/mlc- ai/mlc-llm, 2023
work page 2023
-
[56]
MLCommons. MLCommons inference benchmark. https://github.com/mlcommons/ inference, 2024. Industry-standard inference benchmarking suite covering latency, throughput, and accuracy across hardware platforms
work page 2024
-
[57]
Ludwig: a type-based declara- tive deep learning toolbox, 2019
Piero Molino, Yaroslav Dudin, and Sai Sumanth Miryala. Ludwig: a type-based declara- tive deep learning toolbox, 2019
work page 2019
-
[58]
LocalAI: Open-source self-hosted alternative to OpenAI API
Ettore Di Giacinto Mudler. LocalAI: Open-source self-hosted alternative to OpenAI API. https://github.com/mudler/LocalAI, 2024
work page 2024
-
[59]
NanoBot Contributors. NanoBot. https://github.com/nanobot-ai/nanobot, 2025. Minimalist personal AI agent in the OpenClaw ecosystem
work page 2025
-
[60]
Avanika Narayan, Dan Biderman, Sabri Eyuboglu, Avner May , Scott Linderman, James Zou, and Christopher Ré. Minions: Cost-efficient collaboration between on-device and cloud language models.arXiv preprint arXiv:2502.15964, 2025
-
[61]
Artificial intelligence risk manage- ment framework (AI RMF 1.0)
National Institute of Standards and Technology. Artificial intelligence risk manage- ment framework (AI RMF 1.0). Technical Report NIST AI 100-1, U.S. Department of Commerce, January 2023
work page 2023
-
[62]
Hermes agent: The agent that grows with you
Nous Research. Hermes agent: The agent that grows with you. https://github.com/ NousResearch/hermes-agent, 2025. Self-improving agent with FTS5 cross-session recall, Honcho user modeling, and autonomous skill creation. 40K+ GitHub stars as of April 2026
work page 2025
-
[63]
Nemotron-Flash: Towards latency-optimal hybrid small language models
NVIDIA. Nemotron-Flash: Towards latency-optimal hybrid small language models. arXiv preprint arXiv:2511.18890, 2025
-
[64]
NVIDIA. Nemotron-Super-49B-v1. https://huggingface.co/nvidia/Nemotron- Super-49B-v1, 2025
work page 2025
-
[65]
Ollama, Inc. Ollama. https://github.com/ollama/ollama, 2023. Local LLM serving platform. 162K+ GitHub stars as of March 2026
work page 2023
-
[66]
Symphony: Multi-agent orchestration framework
OpenAI. Symphony: Multi-agent orchestration framework. https://github.com/ openai/symphony, 2025. Multi-agent orchestration framework for coordinating agent workflows
work page 2025
-
[67]
GPT-5.4: frontier reasoning and multimodal model
OpenAI. GPT-5.4: frontier reasoning and multimodal model. OpenAI Platform Docu- mentation, 2026.https://platform.openai.com
work page 2026
-
[68]
OWASP top 10 for large language model applications, 2025
OWASP Foundation. OWASP top 10 for large language model applications, 2025. Version 2025. Accessed: April 2026. 16
work page 2025
-
[69]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-perfo...
work page 2019
- [70]
-
[71]
Pilz, Yusuf Mahmood, and Lennart Heim
Konstantin F. Pilz, Yusuf Mahmood, and Lennart Heim. AI’s power requirements under exponential growth: Extrapolating AI data center power demand and assessing its potential impact on U.S. competitiveness. Research Report RR-A3572-1, RAND Corporation, 2025
work page 2025
-
[72]
Qualcomm Hexagon neural processing unit
Qualcomm Technologies. Qualcomm Hexagon neural processing unit. https://www. qualcomm.com/products/technology/processors, 2024. Accessed: April 2026
work page 2024
-
[73]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[74]
Overton: A data system for monitoring and improving machine-learned products, 2019
Christopher Ré, Feng Niu, Pallavi Gudipati, and Charles Srisuwananukorn. Overton: A data system for monitoring and improving machine-learned products, 2019
work page 2019
-
[75]
GeneralThoughtArchive: A large-scale dataset of reasoning traces, 2025
RJT1990. GeneralThoughtArchive: A large-scale dataset of reasoning traces, 2025. 431K reasoning traces with verifier scores. MIT license
work page 2025
-
[76]
Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford
Stephen E. Robertson, Steve Walker, Susan Jones, Micheline Hancock-Beaulieu, and Mike Gatford. Okapi at TREC-3. InThe Third Text REtrieval Conference (TREC-3). NIST, 1994
work page 1994
-
[77]
Jon Saad-Falcon, Avanika Narayan, Hakki Orhun Akengin, J. Wes Griffin, Herumb Shandilya, Adrian Gamarra Lafuente, Medhya Goel, Rebecca Joseph, Shlok Natarajan, Etash Kumar Guha, Shang Zhu, Ben Athiwaratkun, John Hennessy , Azalia Mirhoseini, and Christopher Ré. Intelligence per watt: Measuring intelligence efficiency of local ai, 2026
work page 2026
-
[78]
ColBERTv2: Effective and efficient retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3715–3734. Association for Computation...
work page 2022
-
[79]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Will Sommer. Gartner predicts that by 2030, performing inference on an LLM with 1 trillion parameters will cost GenAI providers over 90% less than in 2025. Gartner Press Release, 2026. Accessed: April 2026
work page 2030
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.