Probing for Representation Manifolds in Superposition
Pith reviewed 2026-05-20 11:43 UTC · model grok-4.3
The pith
The Manifold Probe discovers representation manifolds in superposition for concepts like time and space, enabling causal steering of model behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The author establishes that a generalized linear probe can recover manifolds encoding concepts in superposition by first determining the linearly predictable feature space for the concept and then learning the encoding directions, with evidence from successful steering interventions on time-related outputs in a large language model.
What carries the argument
The Manifold Probe, which identifies both the feature space of a concept predictable from representations and the linear directions encoding those features.
If this is right
- Interpretable manifolds for time and space exist in the representations of Llama 2-7b.
- Steering along the time manifold influences completions about release years of media.
- The discovered manifolds are causally involved in the model's behavior.
- The approach extends standard linear probes to handle superposition.
Where Pith is reading between the lines
- Applying the probe to additional concepts could map out more of the model's internal knowledge structure.
- This method might be adapted to test whether other behavioral influences arise from similar manifold encodings.
- Future work could examine if these manifolds persist across different model scales or training regimes.
Load-bearing premise
The assumption that the probe identifies the model's true encoding directions for the concept instead of incidental correlations.
What would settle it
A finding that steering along the manifold does not produce the expected changes in the model's year predictions for the tested items, or that the linear feature predictions do not match model behavior under perturbation.
Figures






read the original abstract
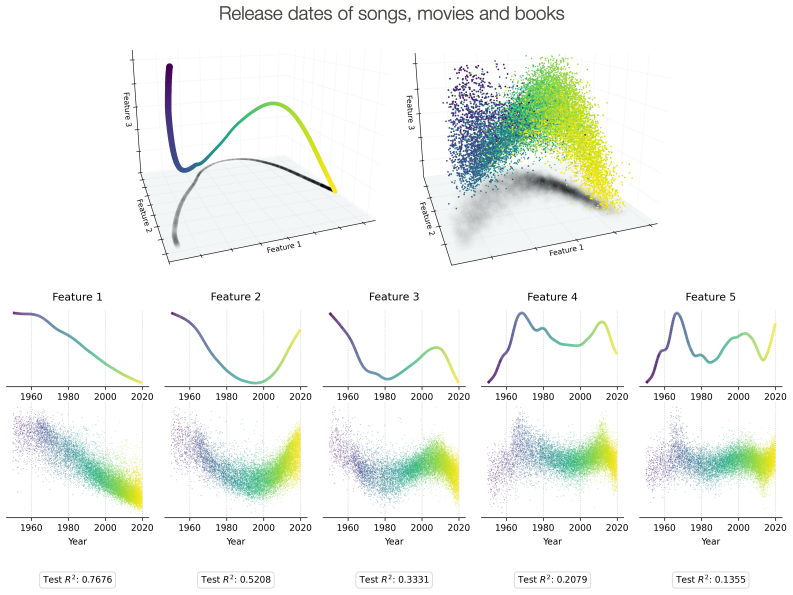
This paper introduces the Manifold Probe, a supervised method for discovering representation manifolds in superposition. The method generalizes linear regression probes by learning the space of features of a concept that can be linearly predicted from the representations, and then learning the directions used to encode them. We demonstrate the probe on representations of time and space in Llama 2-7b, finding manifolds which linearly represent an interpretable set of features in each case. In the case of time, we show that by steering along the manifold, we can influence the model's completions about the years in which famous songs, movies and books were released, providing evidence that the Manifold Probe can discover manifolds which are causally involved in model behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Manifold Probe, a supervised method that generalizes linear regression probes to discover representation manifolds in superposition. It learns the space of features of a concept that can be linearly predicted from model representations and then identifies the directions used to encode those features. The method is demonstrated on time and space representations in Llama 2-7b, yielding manifolds with interpretable features; steering along the time manifold is shown to influence model completions about release years of songs, movies, and books, supporting the claim that the probe identifies causally relevant manifolds.
Significance. If validated with appropriate controls and metrics, the Manifold Probe could offer a useful extension of probing techniques for handling superposition in high-dimensional representations, with the steering intervention providing a direct test of causal involvement in model behavior. The work attempts to bridge discovery and intervention, which is a positive direction for mechanistic interpretability, though the current presentation leaves the strength of this bridge unclear.
major comments (2)
- [Abstract] Abstract: the steering result on Llama 2-7b is presented without any reported validation metrics, error analysis, or controls (such as orthogonal steering vectors, norm-matched random directions, or post-steering performance on unrelated tasks). This is load-bearing for the central causal claim that the discovered manifold is specifically involved in year-related behavior rather than producing effects through off-manifold side effects or incidental changes.
- [Method] Method description (as summarized in the abstract): the generalization of linear probes to manifolds is stated at a high level without equations or pseudocode specifying how the feature space is learned or how encoding directions are optimized. This absence makes it impossible to assess whether the procedure avoids self-referential fitting or normalization artifacts that could force the reported manifolds.
minor comments (1)
- [Abstract] The abstract refers to 'an interpretable set of features' for both time and space without specifying what those features are or how interpretability was quantified.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each major comment below and have updated the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the steering result on Llama 2-7b is presented without any reported validation metrics, error analysis, or controls (such as orthogonal steering vectors, norm-matched random directions, or post-steering performance on unrelated tasks). This is load-bearing for the central causal claim that the discovered manifold is specifically involved in year-related behavior rather than producing effects through off-manifold side effects or incidental changes.
Authors: We agree that the steering experiments would benefit from additional controls to strengthen the causal interpretation. In the revised manuscript, we will report validation metrics for the steering interventions, include error analysis, and add controls using orthogonal steering vectors, norm-matched random directions, and assessments of post-steering performance on unrelated tasks. These additions will help demonstrate that the effects are specific to the time manifold rather than off-manifold artifacts. revision: yes
-
Referee: [Method] Method description (as summarized in the abstract): the generalization of linear probes to manifolds is stated at a high level without equations or pseudocode specifying how the feature space is learned or how encoding directions are optimized. This absence makes it impossible to assess whether the procedure avoids self-referential fitting or normalization artifacts that could force the reported manifolds.
Authors: The full method section in the manuscript provides a more detailed description, but we acknowledge that the abstract summarizes it at a high level. To address this, we will include explicit equations and pseudocode in a new subsection of the Methods to specify the optimization procedure for the feature space and encoding directions. This will allow readers to evaluate potential issues such as self-referential fitting or normalization artifacts. revision: yes
Circularity Check
Manifold Probe method and steering validation are self-contained without circular reduction
full rationale
The paper introduces the Manifold Probe as a supervised generalization of linear regression probes: it learns the space of linearly predictable features for a concept from representations and then identifies the encoding directions. This is applied to time and space manifolds in Llama 2-7b, with steering along the learned manifold used to causally influence year-related completions as external evidence of involvement in model behavior. No derivation step reduces a claimed result to its own fitted inputs by construction, nor relies on self-citation chains, uniqueness theorems from prior author work, or ansatzes imported via citation. The steering test functions as an independent intervention check rather than a tautological prediction. The derivation chain remains non-circular and externally falsifiable via the reported behavioral changes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Journal of Machine Learning Research , volume=
Minimax manifold estimation , author=. The Journal of Machine Learning Research , volume=. 2012 , publisher=
work page 2012
-
[2]
A global geometric framework for nonlinear dimensionality reduction , author=. science , volume=. 2000 , publisher=
work page 2000
-
[3]
Learning with kernels: support vector machines, regularization, optimization, and beyond , author=. 2002 , publisher=
work page 2002
-
[4]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
The ‘strong’ feature hypothesis could be wrong , url =. AI Alignment Forum , author =
- [7]
- [8]
-
[9]
AI Alignment Forum , author =
- [10]
- [11]
- [12]
- [13]
- [14]
- [15]
-
[16]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
URL https: //doi.org/10.1038/s41586-023-06221-2
Scientific discovery in the age of artificial intelligence , volume =. Nature , author =. 2023 , pages =. doi:10.1038/s41586-023-06221-2 , number =
- [18]
-
[19]
Soares, Nate and Fallenstein, Benya , year =. Agent foundations for aligning machine intelligence with human interests: a technical research agenda , journal =
-
[20]
Understanding intermediate layers using linear classifier probes , url =
Alain, Guillaume and Bengio, Yoshua , year =. Understanding intermediate layers using linear classifier probes , url =. 5th
-
[21]
Finding. Trans. Mach. Learn. Res. , author =
-
[22]
A course in metric geometry , publisher =
Burago, Dmitri and Burago, Yuri and Ivanov, Sergei and. A course in metric geometry , publisher =
-
[23]
Gorton, Liv , month = aug, year =. Curve
-
[24]
Munroe, Randall , year =
-
[25]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi , editor =. 2021 , pages =. doi:10.18653/V1/2021.EMNLP-MAIN.552 , booktitle =
-
[26]
Li, Bohan and Zhou, Hao and He, Junxian and Wang, Mingxuan and Yang, Yiming and Li, Lei , editor =. On the. 2020 , pages =. doi:10.18653/V1/2020.EMNLP-MAIN.733 , booktitle =
- [27]
-
[28]
Journal of the American Statistical Association , author =
A new coefficient of correlation , volume =. Journal of the American Statistical Association , author =. 2021 , note =
work page 2021
- [29]
-
[30]
and Balestriero, Randall and Brendel, Wieland and Klindt, David A
Reizinger, Patrik and Bizeul, Alice and Juhos, Attila and Vogt, Julia E. and Balestriero, Randall and Brendel, Wieland and Klindt, David A. , year =. Cross-. The
-
[31]
and Teixeira, Lucas and Oldenziel, Alexander Gietelink and Marzen, Sarah and Riechers, Paul M
Shai, Adam S. and Teixeira, Lucas and Oldenziel, Alexander Gietelink and Marzen, Sarah and Riechers, Paul M. , editor =. Transformers. Advances in
-
[32]
Progress measures for grokking via mechanistic interpretability , url =
Nanda, Neel and Chan, Lawrence and Lieberum, Tom and Smith, Jess and Steinhardt, Jacob , year =. Progress measures for grokking via mechanistic interpretability , url =. The
-
[33]
Chang, Zhuowen Tu, and Benjamin K
Chang, Tyler A. and Tu, Zhuowen and Bergen, Benjamin K. , editor =. The. 2022 , pages =. doi:10.18653/V1/2022.EMNLP-MAIN.9 , booktitle =
-
[34]
and Liao, Isaac and Gurnee, Wes and Tegmark, Max , year =
Engels, Joshua and Michaud, Eric J. and Liao, Isaac and Gurnee, Wes and Tegmark, Max , year =. Not. The
-
[35]
Sparse autoencoders find highly interpretable features in language models , journal =
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , year =. Sparse autoencoders find highly interpretable features in language models , journal =
-
[36]
Towards a definition of disentangled representations , journal =
Higgins, Irina and Amos, David and Pfau, David and Racaniere, Sebastien and Matthey, Loic and Rezende, Danilo and Lerchner, Alexander , year =. Towards a definition of disentangled representations , journal =
-
[37]
Advances in Neural Information Processing Systems , author =
Disentangling by subspace diffusion , volume =. Advances in Neural Information Processing Systems , author =. 2020 , pages =
work page 2020
-
[38]
Elad, Michael , year =. Sparse and redundant representations: from theory to applications in signal and image processing , publisher =
-
[39]
Contrastive learning inverts the data generating process , booktitle =
Zimmermann, Roland S and Sharma, Yash and Schneider, Steffen and Bethge, Matthias and Brendel, Wieland , year =. Contrastive learning inverts the data generating process , booktitle =
-
[40]
Annals of the Institute of Statistical Mathematics , author =
Identifiability of latent-variable and structural-equation models: from linear to nonlinear , volume =. Annals of the Institute of Statistical Mathematics , author =. 2024 , note =
work page 2024
-
[41]
Independent component analysis: algorithms and applications , volume =. Neural networks , author =. 2000 , note =
work page 2000
-
[42]
Linguistic regularities in continuous space word representations , booktitle =
Mikolov, Tomáš and Yih, Wen-tau and Zweig, Geoffrey , year =. Linguistic regularities in continuous space word representations , booktitle =
-
[43]
Chi-Chih Chang, Chien-Yu Lin, Yash Akhauri, Wei-Cheng Lin, Kai-Chiang Wu, Luis Ceze, and Mohamed S
Learning. arXiv preprint arXiv:2503.17547 , author =
-
[44]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , journal =
A is for absorption:. arXiv preprint arXiv:2409.14507 , author =
- [45]
-
[46]
arXiv preprint arXiv:2407.14662 , author =
Relational composition in neural networks:. arXiv preprint arXiv:2407.14662 , author =
-
[47]
The Twelfth International Conference on Learning Representations , year=
Language Models Represent Space and Time , author=. The Twelfth International Conference on Learning Representations , year=
-
[48]
Advances in Neural Information Processing Systems , author =
The geometry of hidden representations of large transformer models , volume =. Advances in Neural Information Processing Systems , author =. 2023 , pages =
work page 2023
-
[49]
Advances in Neural Information Processing Systems , author =
Hierarchical nucleation in deep neural networks , volume =. Advances in Neural Information Processing Systems , author =. 2020 , pages =
work page 2020
-
[50]
Interpretability illusions in the generalization of simplified models , journal =
Friedman, Dan and Lampinen, Andrew and Dixon, Lucas and Chen, Danqi and Ghandeharioun, Asma , year =. Interpretability illusions in the generalization of simplified models , journal =
-
[51]
Advances in Neural Information Processing Systems , author =
Intrinsic dimension of data representations in deep neural networks , volume =. Advances in Neural Information Processing Systems , author =
-
[52]
International conference on learning representations , author =
Isotropy in the contextual embedding space:. International conference on learning representations , author =
-
[53]
Advances in neural information processing systems , author =
The clock and the pizza:. Advances in neural information processing systems , author =. 2023 , pages =
work page 2023
-
[54]
Advances in Neural Information Processing Systems , author =
Learning to grok:. Advances in Neural Information Processing Systems , author =. 2024 , pages =
work page 2024
-
[55]
Advances in Neural Information Processing Systems , author =
Towards understanding grokking:. Advances in Neural Information Processing Systems , author =. 2022 , pages =
work page 2022
-
[56]
Michaud, Eric J. and Liao, Isaac and Lad, Vedang and Liu, Ziming and Mudide, Anish and Loughridge, Chloe and Guo, Zifan Carl and Kheirkhah, Tara Rezaei and Vukelić, Mateja and Tegmark, Max , month = feb, year =. Opening the. doi:10.48550/arXiv.2402.05110 , abstract =
-
[57]
The geometry of categorical and hierarchical concepts in large language models , journal =
Park, Kiho and Choe, Yo Joong and Jiang, Yibo and Veitch, Victor , year =. The geometry of categorical and hierarchical concepts in large language models , journal =
-
[58]
Advances in Neural Information Processing Systems , author =
Matrix factorisation and the interpretation of geodesic distance , volume =. Advances in Neural Information Processing Systems , author =. 2021 , pages =
work page 2021
-
[59]
Representation degeneration problem in training natural language generation models , journal =
Gao, Jun and He, Di and Tan, Xu and Qin, Tao and Wang, Liwei and Liu, Tie-Yan , year =. Representation degeneration problem in training natural language generation models , journal =
-
[60]
Random matrices: universality of local eigenvalue statistics , author =
- [61]
-
[62]
Emergent linear representations in world models of self-supervised sequence models , journal =
Nanda, Neel and Lee, Andrew and Wattenberg, Martin , year =. Emergent linear representations in world models of self-supervised sequence models , journal =
-
[63]
Advances in Neural Information Processing Systems , author =
Causal abstractions of neural networks , volume =. Advances in Neural Information Processing Systems , author =. 2021 , pages =
work page 2021
-
[64]
Advances in neural information processing systems , author =
Investigating gender bias in language models using causal mediation analysis , volume =. Advances in neural information processing systems , author =. 2020 , pages =
work page 2020
-
[65]
arXiv preprint arXiv:1808.08079 , author =
Under the hood:. arXiv preprint arXiv:1808.08079 , author =
-
[66]
The functional relevance of probed information:
Hanna, Michael and Zamparelli, Roberto and Mareček, David and. The functional relevance of probed information:. Proceedings of the 17th. 2023 , pages =
work page 2023
-
[67]
arXiv preprint arXiv:2005.00719 , author =
Probing the probing paradigm:. arXiv preprint arXiv:2005.00719 , author =
-
[68]
Transactions of the Association for Computational Linguistics , author =
Amnesic probing:. Transactions of the Association for Computational Linguistics , author =. 2021 , note =
work page 2021
-
[69]
O'Neill, Charles and Bui, Thang , year =. Sparse autoencoders enable scalable and reliable circuit identification in language models , journal =
-
[70]
Sparse autoencoders reveal universal feature spaces across large language models , journal =
Lan, Michael and Torr, Philip and Meek, Austin and Khakzar, Ashkan and Krueger, David and Barez, Fazl , year =. Sparse autoencoders reveal universal feature spaces across large language models , journal =
- [71]
-
[72]
Scaling and evaluating sparse autoencoders , url =
Gao, Leo and others , year =. Scaling and evaluating sparse autoencoders , url =
- [73]
-
[74]
Efficient estimation of word representations in vector space , journal =
Mikolov, Tomas and Chen, Kai and Corrado, Greg and Dean, Jeffrey , year =. Efficient estimation of word representations in vector space , journal =
-
[75]
Parallel distributed processing: Explorations in the microstructure of cognition , author =
A general framework for parallel distributed processing , volume =. Parallel distributed processing: Explorations in the microstructure of cognition , author =. 1986 , note =
work page 1986
-
[76]
Improving dictionary learning with gated sparse autoencoders , journal =
Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Lieberum, Tom and Varma, Vikrant and Kramár, János and Shah, Rohin and Nanda, Neel , year =. Improving dictionary learning with gated sparse autoencoders , journal =
-
[77]
Contemporary mathematics , author =
Extensions of. Contemporary mathematics , author =. 1984 , pages =
work page 1984
-
[78]
Pennington, Jeffrey and Socher, Richard and Manning, Christopher D , year =. Glove:. Proceedings of the 2014 conference on empirical methods in natural language processing (
work page 2014
-
[79]
Artificial intelligence , author =
Tensor product variable binding and the representation of symbolic structures in connectionist systems , volume =. Artificial intelligence , author =. 1990 , note =
work page 1990
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.