Spatial-Aware Reduction Framework: Towards Efficient and Faithful Visual State Space Models
Pith reviewed 2026-06-26 17:50 UTC · model grok-4.3
The pith
A spatial-aware token reduction method preserves accuracy in visual Mamba models by maintaining 2D structure during token pruning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
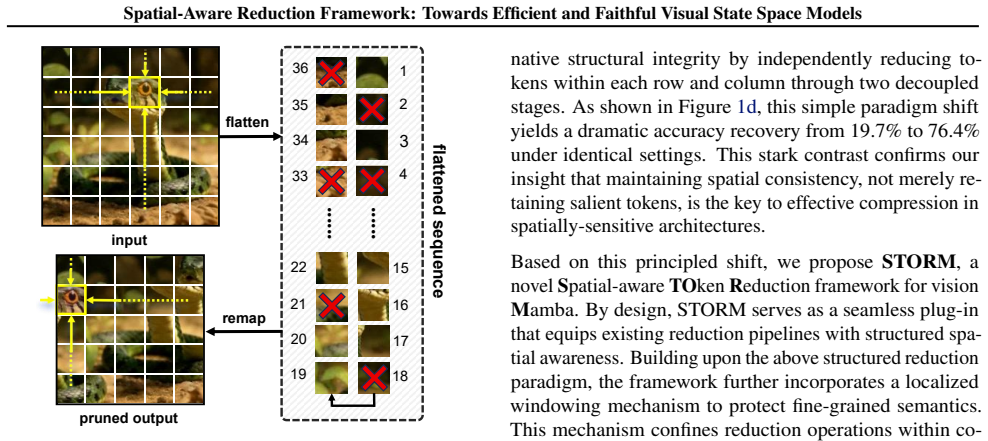
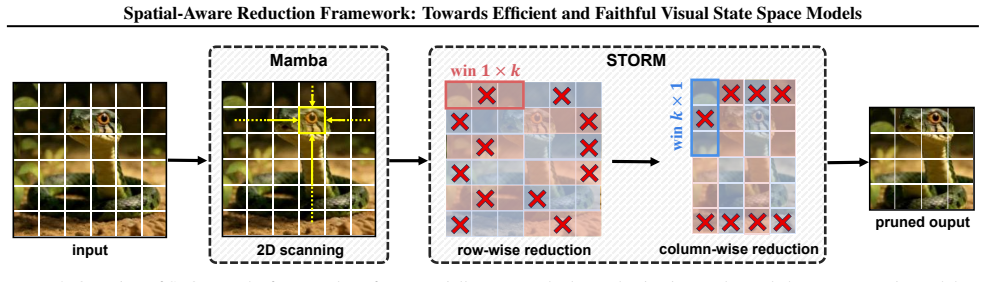
STORM reformulates token reduction as a structured operation on spatial units that enforces localized constraints, thereby maintaining the grid topology and neighborhood coherence required by the selective scanning mechanism in visual state space models, allowing faithful compression without training.
What carries the argument
STORM, a spatial-aware token reduction framework that operates on spatial units with localized constraints to preserve 2D structure.
If this is right
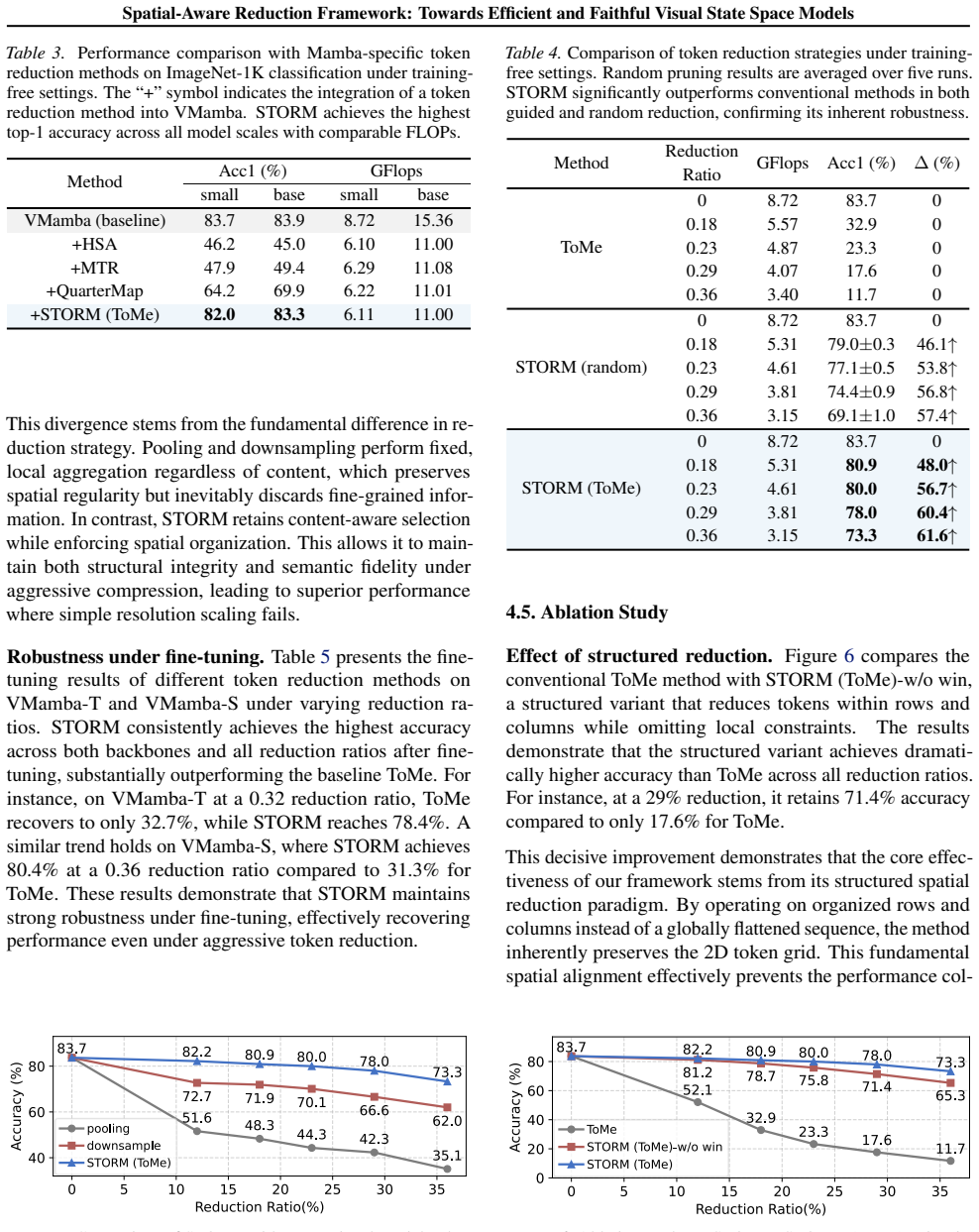
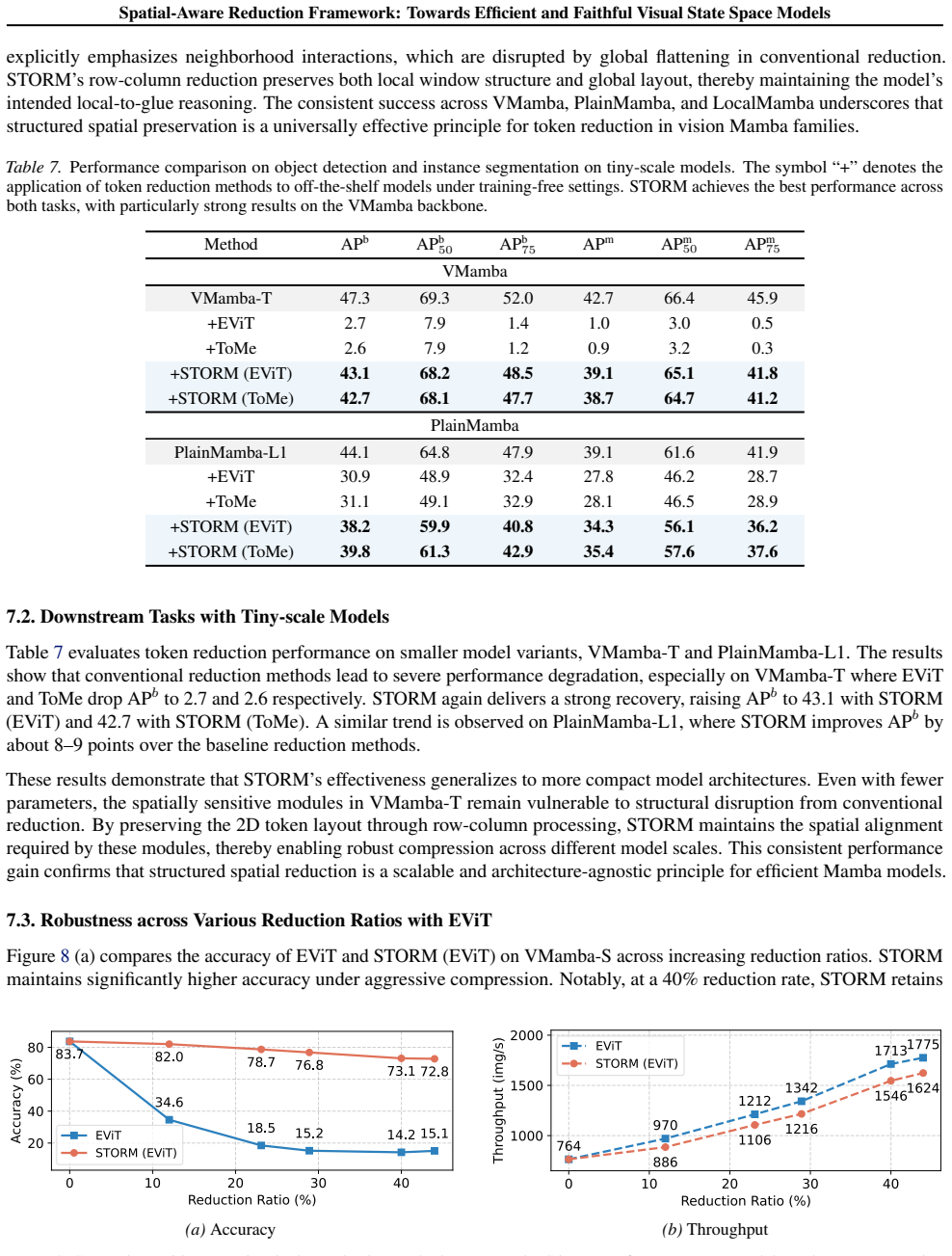
- STORM achieves state-of-the-art pruning accuracy across diverse vision Mamba backbones in training-free settings.
- It delivers up to 63.3% top-1 accuracy recovery on VMamba compared to prior methods.
- On PlainMamba, it results in only a 1.0% accuracy drop, reaching performance comparable to Vision Transformers.
- As a plug-and-play module, it can be added to existing reduction pipelines to add spatial awareness.
Where Pith is reading between the lines
- The spatial constraint idea might extend to other sequence models that rely on structured scanning in vision tasks.
- It suggests that future Mamba variants could incorporate built-in spatial awareness to make them more robust to compression.
- Testing on additional vision tasks like detection or segmentation could reveal broader applicability.
Load-bearing premise
The performance collapse during reduction stems from violating the two-dimensional structural premise of the selective scanning mechanism, and that localized spatial constraints can restore performance without interfering with internal state propagation.
What would settle it
A direct comparison showing that a non-spatial reduction method achieves similar accuracy recovery on the same Mamba backbones, or that adding spatial constraints fails to improve results on VMamba.
Figures



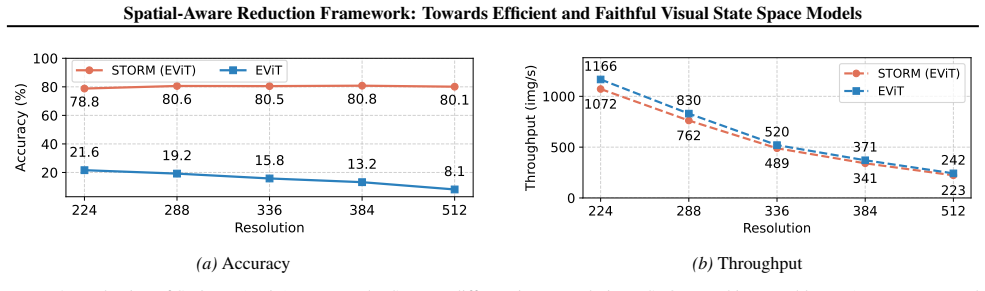



read the original abstract
Mamba demonstrates strong efficiency in modeling long visual sequences. However, when token reduction is applied to structurally enhanced Mamba variants, these models exhibit a severe performance collapse. We attribute this degradation to the spatially agnostic nature of existing reduction methods, which violate the two-dimensional structural premise required by the selective scanning mechanism. In this work, we propose STORM, a spatial-aware token reduction framework designed to maintain structural integrity throughout the compression process. STORM reformulates reduction into a structured operation on spatial units, enforcing localized constraints to maintain both grid topology and neighborhood coherence. As a plug-and-play module, STORM equips existing reduction pipelines with explicit spatial awareness without any training. Empirical results demonstrate that STORM achieves state-of-the-art pruning accuracy across diverse vision Mamba backbones under training-free settings. Notably, STORM delivers a substantial accuracy recovery on VMamba, outperforming prior methods by up to 63.3\% in top-1 accuracy. Meanwhile, STORM incurs only a 1.0\% accuracy drop on PlainMamba, achieving performance comparable to ViT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token reduction applied to structurally enhanced visual Mamba variants causes severe performance collapse because existing methods are spatially agnostic and violate the two-dimensional structural premise of the selective scanning mechanism. It proposes STORM, a training-free plug-and-play spatial-aware reduction framework that reformulates token reduction as a structured operation on spatial units to enforce grid topology and neighborhood coherence. Empirical results are reported to show state-of-the-art pruning accuracy across vision Mamba backbones, with up to 63.3% top-1 accuracy recovery on VMamba and only a 1.0% drop on PlainMamba, reaching performance comparable to ViT.
Significance. If the empirical recovery numbers hold and the spatial-awareness mechanism is shown to be the operative factor, the work would offer a practical route to compressing long-sequence vision SSMs without retraining, improving their deployability relative to ViTs while preserving the selective-scan efficiency advantages.
major comments (2)
- [Abstract and Methods] Abstract and Methods: The central attribution of performance collapse to violation of the 'two-dimensional structural premise' of selective scanning is presented without any derivation, ablation, or error analysis; no section isolates this factor from confounders such as token saliency or sequence length.
- [Experiments] Experiments: The claim that STORM restores performance 'without side effects on the model’s internal state propagation' rests solely on aggregate accuracy numbers; no mechanistic evidence (state-update trajectories, hidden-state propagation comparisons under spatial vs. non-spatial masks) is supplied to test the causal link.
minor comments (1)
- [Abstract] Abstract: The acronym 'STORM' is introduced without expansion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the attribution of performance collapse and the need for mechanistic validation. We address each major comment below with honest assessment of what the current manuscript supports and where revisions are feasible.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The central attribution of performance collapse to violation of the 'two-dimensional structural premise' of selective scanning is presented without any derivation, ablation, or error analysis; no section isolates this factor from confounders such as token saliency or sequence length.
Authors: The attribution stems from the empirical observation that spatially agnostic reductions cause severe collapse specifically in structurally enhanced variants (e.g., VMamba) while STORM recovers performance by enforcing spatial units. We acknowledge the absence of a formal derivation or isolating ablations controlling for saliency and length. In revision we will add a dedicated ablation subsection that varies reduction while holding saliency and sequence length fixed, to better isolate the spatial topology factor. revision: yes
-
Referee: [Experiments] Experiments: The claim that STORM restores performance 'without side effects on the model’s internal state propagation' rests solely on aggregate accuracy numbers; no mechanistic evidence (state-update trajectories, hidden-state propagation comparisons under spatial vs. non-spatial masks) is supplied to test the causal link.
Authors: The manuscript evaluates STORM via end-to-end accuracy under training-free settings and does not supply state-update trajectories or hidden-state propagation comparisons. We will revise the text to qualify all claims as performance-based rather than mechanistic, and will note the lack of internal-state analysis as a limitation. We cannot add the requested mechanistic evidence without new experiments outside the scope of the present work. revision: partial
- [Experiments] The claim that STORM restores performance 'without side effects on the model’s internal state propagation' rests solely on aggregate accuracy numbers; no mechanistic evidence (state-update trajectories, hidden-state propagation comparisons under spatial vs. non-spatial masks) is supplied to test the causal link.
Circularity Check
No circularity detected; central claims rest on empirical recovery without self-referential definitions or fitted inputs.
full rationale
The paper attributes degradation to violation of a 2D structural premise of selective scanning and presents STORM as an independent structural reformulation enforcing grid topology and neighborhood coherence. No equations, fitted parameters, or self-citations are shown that reduce the claimed accuracy recovery (e.g., 63.3% on VMamba) to a quantity defined by the method itself. The derivation is presented as a plug-and-play module validated by external benchmarks on multiple backbones, with no load-bearing step that collapses by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spatially agnostic reduction violates the two-dimensional structural premise required by the selective scanning mechanism
Reference graph
Works this paper leans on
-
[1]
Efficiently Modeling Long Sequences with Structured State Spaces , booktitle =
Albert Gu and Karan Goel and Christopher R. Efficiently Modeling Long Sequences with Structured State Spaces , booktitle =. 2022 , _url =
2022
-
[2]
arXiv preprint arXiv:2111.00396 , year=
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
-
[3]
Jimmy T. H. Smith and Andrew Warrington and Scott W. Linderman , title =. The Eleventh International Conference on Learning Representations,. 2023 , _url =
2023
-
[4]
arXiv preprint arXiv:2208.04933 , year=
Simplified state space layers for sequence modeling , author=. arXiv preprint arXiv:2208.04933 , year=
-
[5]
Albert Gu and Tri Dao , title =. CoRR , volume =. 2023 , _url =. 2312.00752 , timestamp =
Pith/arXiv arXiv 2023
-
[6]
First conference on language modeling , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. First conference on language modeling , year=
-
[8]
arXiv preprint arXiv:2401.04722 , year=
U-mamba: Enhancing long-range dependency for biomedical image segmentation , author=. arXiv preprint arXiv:2401.04722 , year=
-
[9]
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State Space Layers , booktitle =
Albert Gu and Isys Johnson and Karan Goel and Khaled Saab and Tri Dao and Atri Rudra and Christopher R. Combining Recurrent, Convolutional, and Continuous-time Models with Linear State Space Layers , booktitle =. 2021 , _url =
2021
-
[10]
Advances in neural information processing systems , volume=
Combining recurrent, convolutional, and continuous-time models with linear state space layers , author=. Advances in neural information processing systems , volume=
-
[11]
Fu and Tri Dao and Khaled Kamal Saab and Armin W
Daniel Y. Fu and Tri Dao and Khaled Kamal Saab and Armin W. Thomas and Atri Rudra and Christopher R. Hungry Hungry Hippos: Towards Language Modeling with State Space Models , booktitle =. 2023 , _url =
2023
-
[12]
arXiv preprint arXiv:2212.14052 , year=
Hungry hungry hippos: Towards language modeling with state space models , author=. arXiv preprint arXiv:2212.14052 , year=
-
[13]
Swin-UMamba: Mamba-Based UNet with ImageNet-Based Pretraining , booktitle =
Jiarun Liu and Hao Yang and Hong. Swin-UMamba: Mamba-Based UNet with ImageNet-Based Pretraining , booktitle =. 2024 , _url =
2024
-
[14]
International conference on medical image computing and computer-assisted intervention , pages=
Swin-umamba: Mamba-based unet with imagenet-based pretraining , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2024 , organization=
2024
-
[16]
arXiv preprint arXiv:2106.11297 , year=
Tokenlearner: What can 8 learned tokens do for images and videos? , author=. arXiv preprint arXiv:2106.11297 , year=
-
[17]
Adaptive Token Sampling for Efficient Vision Transformers , booktitle =
Mohsen Fayyaz and Soroush Abbasi Koohpayegani and Farnoush Rezaei Jafari and Sunando Sengupta and Hamid Reza Vaezi Joze and Eric Sommerlade and Hamed Pirsiavash and J. Adaptive Token Sampling for Efficient Vision Transformers , booktitle =. 2022 , _url =
2022
-
[18]
European conference on computer vision , pages=
Adaptive token sampling for efficient vision transformers , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[19]
Gomez and Lukasz Kaiser and Illia Polosukhin , _editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , _editor =. Attention is All you Need , booktitle =. 2017 , _url =
2017
-
[20]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[21]
EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba , booktitle =
Xiaohuan Pei and Tao Huang and Chang Xu , _editor =. EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba , booktitle =. 2025 , _url =
2025
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Efficientvmamba: Atrous selective scan for light weight visual mamba , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Smith and Albert Gu and Anushan Fernando and
Antonio Orvieto and Samuel L. Smith and Albert Gu and Anushan Fernando and. Resurrecting Recurrent Neural Networks for Long Sequences , booktitle =. 2023 , _url =
2023
-
[24]
International Conference on Machine Learning , pages=
Resurrecting recurrent neural networks for long sequences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[25]
Xuanhua He and Ke Cao and Jie Zhang and Keyu Yan and Yingying Wang and Rui Li and Chengjun Xie and Danfeng Hong and Man Zhou , title =. Inf. Fusion , volume =. 2025 , _url =
2025
-
[26]
Information Fusion , volume=
Pan-mamba: Effective pan-sharpening with state space model , author=. Information Fusion , volume=. 2025 , publisher=
2025
-
[27]
The Eleventh International Conference on Learning Representations,
Yuhong Li and Tianle Cai and Yi Zhang and Deming Chen and Debadeepta Dey , title =. The Eleventh International Conference on Learning Representations,. 2023 , _url =
2023
-
[28]
arXiv preprint arXiv:2210.09298 , year=
What makes convolutional models great on long sequence modeling? , author=. arXiv preprint arXiv:2210.09298 , year=
-
[29]
MambaIR:
Hang Guo and Jinmin Li and Tao Dai and Zhihao Ouyang and Xudong Ren and Shu. MambaIR:. Computer Vision -. 2024 , _url =
2024
-
[30]
European conference on computer vision , pages=
Mambair: A simple baseline for image restoration with state-space model , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[31]
2024 , _url =
Tianxiang Chen and Zi Ye and Zhentao Tan and Tao Gong and Yue Wu and Qi Chu and Bin Liu and Nenghai Yu and Jieping Ye , title =. 2024 , _url =
2024
-
[32]
IEEE Transactions on Geoscience and Remote Sensing , year=
Mim-istd: Mamba-in-mamba for efficient infrared small target detection , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[33]
PointMamba:
Dingkang Liang and Xin Zhou and Wei Xu and Xingkui Zhu and Zhikang Zou and Xiaoqing Ye and Xiao Tan and Xiang Bai , _editor =. PointMamba:. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024 , year =
2024
-
[34]
Advances in neural information processing systems , volume=
Pointmamba: A simple state space model for point cloud analysis , author=. Advances in neural information processing systems , volume=
-
[35]
VideoMamba: State Space Model for Efficient Video Understanding , booktitle =
Kunchang Li and Xinhao Li and Yi Wang and Yinan He and Yali Wang and Limin Wang and Yu Qiao , _editor =. VideoMamba: State Space Model for Efficient Video Understanding , booktitle =. 2024 , _url =
2024
-
[36]
European conference on computer vision , pages=
Videomamba: State space model for efficient video understanding , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[37]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model , booktitle =
Lianghui Zhu and Bencheng Liao and Qian Zhang and Xinlong Wang and Wenyu Liu and Xinggang Wang , _editor =. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model , booktitle =. 2024 , _url =
2024
-
[38]
arXiv preprint arXiv:2401.09417 , year=
Vision mamba: Efficient visual representation learning with bidirectional state space model , author=. arXiv preprint arXiv:2401.09417 , year=
-
[39]
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification , booktitle =
Yongming Rao and Wenliang Zhao and Benlin Liu and Jiwen Lu and Jie Zhou and Cho. DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification , booktitle =. 2021 , _url =
2021
-
[40]
Advances in neural information processing systems , volume=
Dynamicvit: Efficient vision transformers with dynamic token sparsification , author=. Advances in neural information processing systems , volume=
-
[41]
A-ViT: Adaptive Tokens for Efficient Vision Transformer , booktitle =
Hongxu Yin and Arash Vahdat and Jos. A-ViT: Adaptive Tokens for Efficient Vision Transformer , booktitle =. 2022 , _url =
2022
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A-vit: Adaptive tokens for efficient vision transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
SPViT: Enabling Faster Vision Transformers via Latency-Aware Soft Token Pruning , booktitle =
Zhenglun Kong and Peiyan Dong and Xiaolong Ma and Xin Meng and Wei Niu and Mengshu Sun and Xuan Shen and Geng Yuan and Bin Ren and Hao Tang and Minghai Qin and Yanzhi Wang , _editor =. SPViT: Enabling Faster Vision Transformers via Latency-Aware Soft Token Pruning , booktitle =. 2022 , _url =
2022
-
[44]
European conference on computer vision , pages=
Spvit: Enabling faster vision transformers via latency-aware soft token pruning , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[46]
arXiv preprint arXiv:2202.07800 , year=
Not all patches are what you need: Expediting vision transformers via token reorganizations , author=. arXiv preprint arXiv:2202.07800 , year=
-
[47]
Token Merging: Your ViT But Faster , booktitle =
Daniel Bolya and Cheng. Token Merging: Your ViT But Faster , booktitle =. 2023 , _url =
2023
-
[48]
arXiv preprint arXiv:2210.09461 , year=
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
-
[49]
Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo , title =. 2021. 2021 , _url =
2021
-
[50]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[51]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,. 2021 , _url =
2021
-
[52]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[53]
Training data-efficient image transformers
Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Herv. Training data-efficient image transformers. Proceedings of the 38th International Conference on Machine Learning,. 2021 , _url =
2021
-
[54]
International conference on machine learning , pages=
Training data-efficient image transformers & distillation through attention , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[55]
Advances in Neural Information Processing Systems , volume=
Pruning-Robust Mamba with Asymmetric Multi-Scale Scanning Paths , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
VMamba: Visual State Space Model , booktitle =
Yue Liu and Yunjie Tian and Yuzhong Zhao and Hongtian Yu and Lingxi Xie and Yaowei Wang and Qixiang Ye and Jianbin Jiao and Yunfan Liu , _editor =. VMamba: Visual State Space Model , booktitle =. 2024 , _url =
2024
-
[57]
Advances in neural information processing systems , volume=
Vmamba: Visual state space model , author=. Advances in neural information processing systems , volume=
-
[58]
Crowley , title =
Chenhongyi Yang and Zehui Chen and Miguel Espinosa and Linus Ericsson and Zhenyu Wang and Jiaming Liu and Elliot J. Crowley , title =. 35th British Machine Vision Conference,. 2024 , _url =
2024
-
[59]
arXiv preprint arXiv:2403.17695 , year=
Plainmamba: Improving non-hierarchical mamba in visual recognition , author=. arXiv preprint arXiv:2403.17695 , year=
-
[60]
LocalMamba: Visual State Space Model with Windowed Selective Scan , booktitle =
Tao Huang and Xiaohuan Pei and Shan You and Fei Wang and Chen Qian and Chang Xu , _editor =. LocalMamba: Visual State Space Model with Windowed Selective Scan , booktitle =. 2024 , _url =
2024
-
[61]
European Conference on Computer Vision , pages=
Localmamba: Visual state space model with windowed selective scan , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[62]
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model , booktitle =
Yuheng Shi and Minjing Dong and Chang Xu , _editor =. Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model , booktitle =. 2024 , _url =
2024
-
[63]
Advances in Neural Information Processing Systems , volume=
Multi-scale vmamba: Hierarchy in hierarchy visual state space model , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Exploring Token Pruning in Vision State Space Models , booktitle =
Zheng Zhan and Zhenglun Kong and Yifan Gong and Yushu Wu and Zichong Meng and Hangyu Zheng and Xuan Shen and Stratis Ioannidis and Wei Niu and Pu Zhao and Yanzhi Wang , _editor =. Exploring Token Pruning in Vision State Space Models , booktitle =. 2024 , _url =
2024
-
[65]
Advances in Neural Information Processing Systems , volume=
Exploring token pruning in vision state space models , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Rethinking Token Reduction for State Space Models , booktitle =
Zheng Zhan and Yushu Wu and Zhenglun Kong and Changdi Yang and Yifan Gong and Xuan Shen and Xue Lin and Pu Zhao and Yanzhi Wang , _editor =. Rethinking Token Reduction for State Space Models , booktitle =. 2024 , _url =
2024
-
[67]
arXiv preprint arXiv:2410.14725 , year=
Rethinking token reduction for state space models , author=. arXiv preprint arXiv:2410.14725 , year=
-
[69]
arXiv preprint arXiv:2507.14042 , year=
Training-free Token Reduction for Vision Mamba , author=. arXiv preprint arXiv:2507.14042 , year=
-
[70]
2025 , _url =
Ali Hatamizadeh and Jan Kautz , title =. 2025 , _url =
2025
-
[71]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mambavision: A hybrid mamba-transformer vision backbone , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[72]
The Eleventh International Conference on Learning Representations,
Harsh Mehta and Ankit Gupta and Ashok Cutkosky and Behnam Neyshabur , title =. The Eleventh International Conference on Learning Representations,. 2023 , _url =
2023
-
[73]
arXiv preprint arXiv:2206.13947 , year=
Long range language modeling via gated state spaces , author=. arXiv preprint arXiv:2206.13947 , year=
-
[74]
2023 , _url =
Jue Wang and Wentao Zhu and Pichao Wang and Xiang Yu and Linda Liu and Mohamed Omar and Raffay Hamid , title =. 2023 , _url =
2023
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Selective structured state-spaces for long-form video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[76]
Downs and Preey Shah and Tri Dao and Stephen Baccus and Christopher R
Eric Nguyen and Karan Goel and Albert Gu and Gordon W. Downs and Preey Shah and Tri Dao and Stephen Baccus and Christopher R. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022 , year =
2022
-
[77]
Advances in neural information processing systems , volume=
S4nd: Modeling images and videos as multidimensional signals with state spaces , author=. Advances in neural information processing systems , volume=
-
[78]
2023 , _url =
Mengzhao Chen and Wenqi Shao and Peng Xu and Mingbao Lin and Kaipeng Zhang and Fei Chao and Rongrong Ji and Yu Qiao and Ping Luo , title =. 2023 , _url =
2023
-
[79]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Diffrate: Differentiable compression rate for efficient vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[81]
arXiv preprint arXiv:2110.03860 , year=
Token pooling in vision transformers , author=. arXiv preprint arXiv:2110.03860 , year=
-
[82]
Breuel and Jan Kautz and Xiaolong Wang , title =
Jiarui Xu and Shalini De Mello and Sifei Liu and Wonmin Byeon and Thomas M. Breuel and Jan Kautz and Xiaolong Wang , title =. 2022 , _url =
2022
-
[83]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Groupvit: Semantic segmentation emerges from text supervision , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[84]
QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model , booktitle =
Fei Xie and Weijia Zhang and Zhongdao Wang and Chao Ma , _editor =. QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model , booktitle =. 2024 , _url =
2024
-
[85]
Advances in Neural Information Processing Systems , volume=
Quadmamba: Learning quadtree-based selective scan for visual state space model , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.