Disco-LoRA: Disentangled Composition of Content, Style, and Motion for Multi-concept Video Customization
Pith reviewed 2026-06-26 05:49 UTC · model grok-4.3
The pith
Disco-LoRA disentangles content, style, and motion to enable controllable multi-concept video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
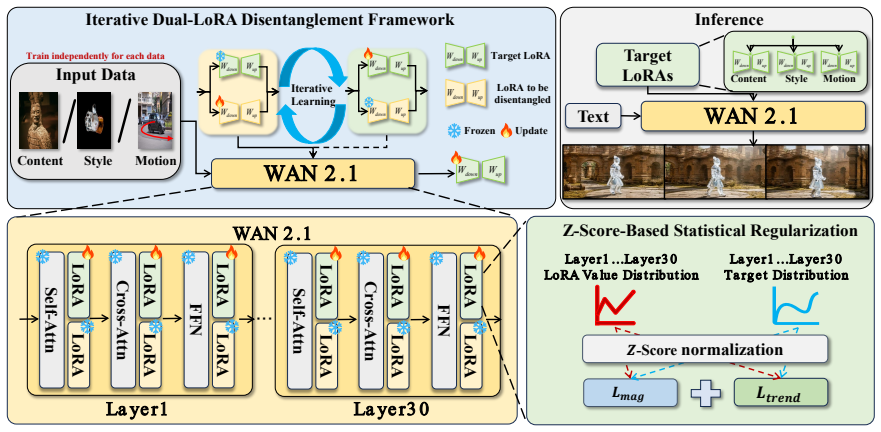
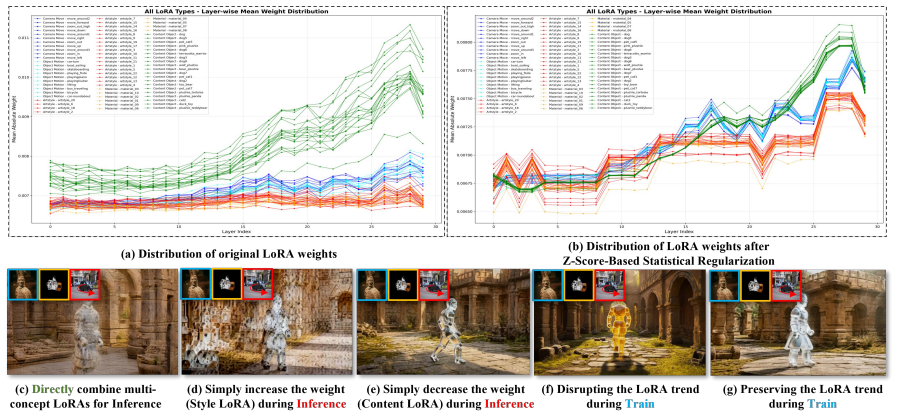
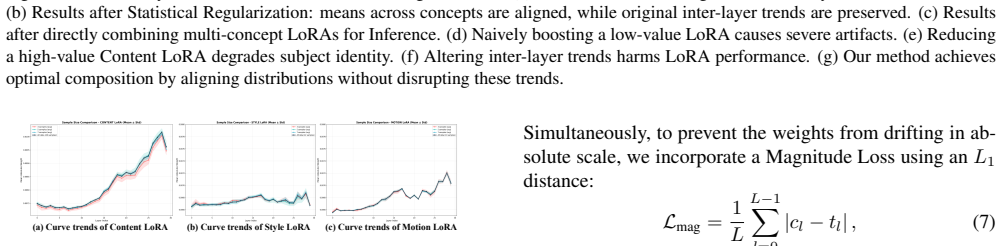
Disco-LoRA tackles multi-concept video customization by decomposing the objective into Content-Style and Content-Motion sub-tasks, each solved with an Iterative Dual-LoRA Disentanglement Framework that separates distinct concepts in the data. Layer-wise weight trends are identified as crucial for LoRA identity, with magnitudes dictating composability; a Z-score-based statistical regularization aligns weight distributions to preserve trends while minimizing interference between different LoRAs during recombination.
What carries the argument
Iterative Dual-LoRA Disentanglement Framework with Z-score-based statistical regularization on layer-wise weight trends.
If this is right
- Videos can be generated with independent control over appearance from one reference, style from another, and motion from a third.
- Reference features are preserved more accurately when multiple concepts are applied together.
- The same framework supports flexible recombination of concepts without retraining for each combination.
- A benchmark dataset now exists to measure success on joint content-style-motion control.
Where Pith is reading between the lines
- Similar decomposition and regularization might apply to multi-concept customization in image or audio diffusion models.
- The emphasis on statistical alignment of adaptation weights could inform modular fine-tuning in other parameter-efficient methods.
- If layer-wise trends prove general, they may guide selection of which layers to adapt in future LoRA designs for video tasks.
Load-bearing premise
Decomposing the multi-concept goal into separate Content-Style and Content-Motion sub-tasks plus using layer-wise weight trends for identity is enough to achieve disentanglement and recombination without major interference.
What would settle it
A set of reference videos where recombined LoRAs produce output that mixes or loses distinct style elements and motion patterns despite correct text prompts.
Figures













read the original abstract
Video customization based on Text-to-Video (T2V) models aims to learn specific features from reference data to generate controllable videos. While significant strides have been made in image stylization and video motion customization, simultaneously controlling multiple concepts, such as content, style, and motion, remains a major challenge. In this work, we systematically define the task of multi-concept video customization, which requires the joint control of content, style, and motion. To facilitate research in this area, we construct a comprehensive benchmark and propose Disco-LoRA, a unified framework designed to tackle this problem by disentangling and flexibly recombining different concepts in two stages: (1) We decompose the objective into two sub-tasks: Content-Style and Content-Motion. Each sub-task is addressed using our Iterative Dual-LoRA Disentanglement Framework, which effectively disentangles distinct concepts within the data. (2) We identify layer-wise weight trends as crucial for LoRA identity, while weight magnitudes dictate composability. To harmonize these scales, we propose a Z-score-based statistical regularization that aligns weight distributions, preserving layer-wise trends while minimizing interference between different LoRAs. Extensive experiments show that Disco-LoRA excels in multi-concept video customization, effectively preserving appearance, style, and motion for controllable text-to-video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Disco-LoRA for multi-concept video customization in text-to-video (T2V) models. It defines the task of jointly controlling content, style, and motion, constructs a benchmark, and proposes a two-stage framework: (1) decomposition into Content-Style and Content-Motion sub-tasks solved via an Iterative Dual-LoRA Disentanglement Framework, and (2) identification of layer-wise weight trends for LoRA identity combined with Z-score-based statistical regularization to align magnitudes and enable recombination with minimal interference. Experiments claim superior preservation and controllability over baselines.
Significance. If the empirical claims hold, the work would provide a practical advance in controllable T2V generation by enabling flexible recombination of multiple concepts from reference videos. The benchmark construction and the observation that layer-wise trends plus magnitude alignment aid LoRA composability could inform future parameter-efficient adaptation methods. The two-stage decomposition offers a concrete recipe that may generalize beyond the reported setting.
major comments (3)
- [§3.2] §3.2 (Iterative Dual-LoRA Disentanglement Framework): The central claim that decomposing into Content-Style and Content-Motion sub-tasks removes style-motion coupling rests on an empirical premise that is not shown by construction. The manuscript should report quantitative metrics (e.g., style leakage scores or motion fidelity under cross-concept prompts) comparing coupled vs. decoupled training to verify that residual interference is negligible.
- [§4.3] §4.3 (Z-score regularization and recombination): The assertion that Z-score alignment preserves layer-wise trends while minimizing interference is load-bearing for the disentanglement guarantee, yet no ablation isolates the contribution of the regularization (e.g., before/after interference metrics or failure cases when magnitudes are unaligned). Without these controls, the recombination step's effectiveness remains unverified.
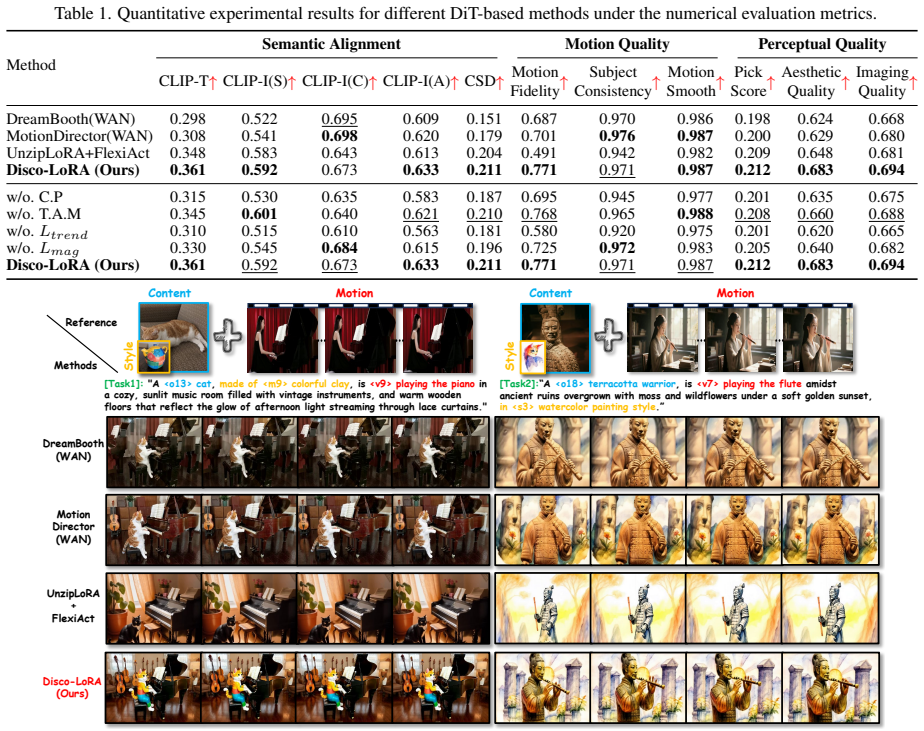
- [Table 2 / Figure 5] Table 2 / Figure 5 (quantitative results): The reported gains in preservation and controllability are presented without error bars or statistical significance tests across multiple seeds; given the stochastic nature of T2V fine-tuning, this weakens the claim that Disco-LoRA 'excels' relative to baselines.
minor comments (2)
- [§4.1] The benchmark construction details (number of reference videos per concept, diversity metrics) are only summarized; an appendix table listing exact dataset statistics would improve reproducibility.
- [§3.3] Notation for the Z-score regularization (mean and std computation across which dimensions?) is introduced without an explicit equation; adding Eq. (X) would clarify the procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Iterative Dual-LoRA Disentanglement Framework): The central claim that decomposing into Content-Style and Content-Motion sub-tasks removes style-motion coupling rests on an empirical premise that is not shown by construction. The manuscript should report quantitative metrics (e.g., style leakage scores or motion fidelity under cross-concept prompts) comparing coupled vs. decoupled training to verify that residual interference is negligible.
Authors: We agree that a direct quantitative comparison would provide stronger validation. The current manuscript relies on the final task performance and qualitative disentanglement results to support the decomposition. We will add a new ablation study reporting style leakage scores and motion fidelity metrics under cross-concept prompts for coupled versus decoupled training. revision: yes
-
Referee: [§4.3] §4.3 (Z-score regularization and recombination): The assertion that Z-score alignment preserves layer-wise trends while minimizing interference is load-bearing for the disentanglement guarantee, yet no ablation isolates the contribution of the regularization (e.g., before/after interference metrics or failure cases when magnitudes are unaligned). Without these controls, the recombination step's effectiveness remains unverified.
Authors: We acknowledge the value of isolating the regularization's effect. We will add an ablation study with before/after interference metrics and failure cases for unaligned magnitudes to verify the contribution of Z-score alignment. revision: yes
-
Referee: [Table 2 / Figure 5] Table 2 / Figure 5 (quantitative results): The reported gains in preservation and controllability are presented without error bars or statistical significance tests across multiple seeds; given the stochastic nature of T2V fine-tuning, this weakens the claim that Disco-LoRA 'excels' relative to baselines.
Authors: We agree that variability across seeds should be reported. We will rerun the experiments with multiple seeds, add error bars (mean ± std) to Table 2 and Figure 5, and include statistical significance tests. revision: yes
Circularity Check
No circularity: empirical method with no derivations reducing to inputs
full rationale
The paper proposes an empirical framework (Disco-LoRA) that decomposes the multi-concept task into Content-Style and Content-Motion sub-tasks, applies Iterative Dual-LoRA, and uses Z-score regularization based on observed layer-wise trends. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-citations. The central claims rest on experimental validation rather than any self-definitional or load-bearing self-referential step, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[2]
Yuxuan Bian, Xin Chen, Zenan Li, Tiancheng Zhi, Shen Sang, Linjie Luo, and Qiang Xu. Video-as-prompt: Uni- fied semantic control for video generation.arXiv preprint arXiv:2510.20888, 2025. 3
arXiv 2025
-
[3]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2, 3
Pith/arXiv arXiv 2023
-
[4]
Fangda Chen, Shanshan Zhao, Chuanfu Xu, and Long Lan. Jointtuner: Appearance-motion adaptive joint train- ing for customized video generation.arXiv preprint arXiv:2503.23951, 2025. 3, 7
arXiv 2025
-
[5]
Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7310– 7320, 2024. 2
2024
-
[6]
Conditional balance: Improving multi-conditioning trade-offs in image generation
Nadav Z Cohen, Oron Nir, and Ariel Shamir. Conditional balance: Improving multi-conditioning trade-offs in image generation. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 2641–2650, 2025. 3
2025
-
[7]
Vision transformers need registers, 2023
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers, 2023. 3
2023
-
[8]
Introducing veo 3, our video generation model with expanded creative controls – including native au- dio and extended videos
Google DeepMind. Introducing veo 3, our video generation model with expanded creative controls – including native au- dio and extended videos. [Online], 2025. 2, 9
2025
-
[9]
Implicit style-content separation using b-lora
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. Implicit style-content separation using b-lora. In European Conference on Computer Vision, pages 181–198. Springer, 2024. 3
2024
-
[10]
An image is worth one word: Personalizing text-to-image gener- ation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. InThe Eleventh International Conference on Learning Representations, 2022. 3
2022
-
[11]
Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113,
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xi- aojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113,
-
[12]
Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Sys- tems, 36:15890–15902, 2023
Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yun- peng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, et al. Mix-of-show: Decentralized low- rank adaptation for multi-concept customization of diffusion models.Advances in Neural Information Processing Sys- tems, 36:15890–15902, 2023. 3
2023
-
[13]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 7
Pith/arXiv arXiv 2022
-
[14]
Cogvideo: Large-scale pretraining for text-to-video generation via transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. InICLR, 2023. 2
2023
-
[15]
Lora: Low- rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low- rank adaptation of large language models. InInternational Conference on Learning Representations, 2021. 3
2021
-
[16]
Video- mage: Multi-subject and motion customization of text-to- video diffusion models
Chi-Pin Huang, Yen-Siang Wu, Hung-Kai Chung, Kai-Po Chang, Fu-En Yang, and Yu-Chiang Frank Wang. Video- mage: Multi-subject and motion customization of text-to- video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17603– 17612, 2025. 2, 3, 5
2025
-
[17]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 7, 4
2024
-
[18]
Visual style prompting with swapping self- attention.arXiv preprint arXiv:2402.12974, 2024
Jaeseok Jeong, Junho Kim, Yunjey Choi, Gayoung Lee, and Youngjung Uh. Visual style prompting with swapping self- attention.arXiv preprint arXiv:2402.12974, 2024. 3
arXiv 2024
-
[19]
Videobooth: Diffusion-based video generation with image prompts
Yuming Jiang, Tianxing Wu, Shuai Yang, Chenyang Si, Dahua Lin, Yu Qiao, Chen Change Loy, and Ziwei Liu. Videobooth: Diffusion-based video generation with image prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6689– 6700, 2024. 3
2024
-
[20]
Co- tracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker: It is better to track together. InEuropean conference on computer vision, pages 18–35. Springer, 2024. 4
2024
-
[21]
Text2video-zero: Text- to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text- to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023. 3
2023
-
[22]
Pick-a-pic: An open 10 dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: An open 10 dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023. 4
2023
-
[23]
Baolu Li, Yiming Zhang, Qinghe Wang, Liqian Ma, Xi- aoyu Shi, Xintao Wang, Pengfei Wan, Zhenfei Yin, Yun- zhi Zhuge, Huchuan Lu, et al. Vfxmaster: Unlocking dy- namic visual effect generation via in-context learning.arXiv preprint arXiv:2510.25772, 2025. 3
arXiv 2025
-
[24]
Reactid: Synchronizing realistic actions and identity in personalized video genera- tion
Wei Li, Yiheng Zhang, Fuchen Long, Zhaofan Qiu, Ting Yao, Xiaoyan Sun, and Tao Mei. Reactid: Synchronizing realistic actions and identity in personalized video genera- tion. InThe Fourteenth International Conference on Learn- ing Representations. 3
-
[25]
Create anything anywhere: Layout- controllable personalized diffusion model for multiple sub- jects
Wei Li, Hebei Li, Yansong Peng, Siying Wu, Yueyi Zhang, and Xiaoyan Sun. Create anything anywhere: Layout- controllable personalized diffusion model for multiple sub- jects. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2025. 3
2025
-
[26]
Ziqiang Li, Jun Li, Lizhi Xiong, Zhangjie Fu, and Zechao Li. A comprehensive survey on visual concept mining in text-to- image diffusion models.arXiv preprint arXiv:2503.13576,
-
[27]
Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 3
Pith/arXiv arXiv 2022
-
[28]
Unziplora: Separating content and style from a single image
Chang Liu, Viraj Shah, Aiyu Cui, and Svetlana Lazebnik. Unziplora: Separating content and style from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16776–16785, 2025. 2, 3, 7, 8
2025
-
[29]
Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yanhao Zheng, Jiayi Ji, Fan Zhou, Jiebo Luo, Ziwei Liu, Hao Fei, et al. Javisdit: Joint audio-video diffusion transformer with hierar- chical spatio-temporal prior synchronization.arXiv preprint arXiv:2503.23377, 2025. 3
arXiv 2025
-
[30]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4117–4125, 2024. 3
2024
-
[31]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024
2024
-
[32]
Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Xuanhua He, Chenyang Zhu, Hongyu Liu, Yingqing He, et al. Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
arXiv 2025
-
[33]
Yue Ma, Kunyu Feng, Xinhua Zhang, Hongyu Liu, David Junhao Zhang, Jinbo Xing, Yinhan Zhang, Ayden Yang, Zeyu Wang, and Qifeng Chen. Follow-your-creation: Empowering 4d creation through video inpainting.arXiv preprint arXiv:2506.04590, 2025
arXiv 2025
-
[34]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6018–6026, 2025. 3
2025
-
[35]
Yue Ma, Yulong Liu, Qiyuan Zhu, Ayden Yang, Kunyu Feng, Xinhua Zhang, Zhifeng Li, Sirui Han, Chenyang Qi, and Qifeng Chen. Follow-your-motion: Video motion transfer via efficient spatial-temporal decoupled finetuning.arXiv preprint arXiv:2506.05207, 2025. 3
arXiv 2025
-
[36]
Yue Ma, Zexuan Yan, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, et al. Follow-your-emoji-faster: To- wards efficient, fine-controllable, and expressive freestyle portrait animation.arXiv preprint arXiv:2509.16630, 2025. 3
arXiv 2025
-
[37]
Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026
Yue Ma, Xinyu Wang, Qianli Ma, Qinghe Wang, Mingzhe Zheng, Xiangpeng Yang, Hao Li, Chongbo Zhao, Jixuan Ying, Harry Yang, et al. Group editing: Edit multiple im- ages in one go.arXiv preprint arXiv:2603.22883, 2026. 3
arXiv 2026
-
[38]
Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026
Yue Ma, Zhikai Wang, Tianhao Ren, Mingzhe Zheng, Hongyu Liu, Jiayi Guo, Mark Fong, Yuxuan Xue, Zixi- ang Zhao, Konrad Schindler, et al. Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026. 3
arXiv 2026
-
[39]
Ziheng Ouyang, Zhen Li, and Qibin Hou. K-lora: Unlock- ing training-free fusion of any subject and style loras.arXiv preprint arXiv:2502.18461, 2025. 3
arXiv 2025
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[41]
Orthogonal adaptation for modular customization of diffusion models
Ryan Po, Guandao Yang, Kfir Aberman, and Gordon Wet- zstein. Orthogonal adaptation for modular customization of diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7964–7973, 2024. 3
2024
-
[42]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 3
Pith/arXiv arXiv 2023
-
[43]
The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 4
Pith/arXiv arXiv 2017
-
[44]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763. PMLR, 2021. 7, 4
2021
-
[45]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3
2022
-
[46]
Aniket Roy, Shubhankar Borse, Shreya Kadambi, Debas- mit Das, Shweta Mahajan, Risheek Garrepalli, Hyojin Park, Ankita Nayak, Rama Chellappa, Munawar Hayat, et al. 11 Duolora: Cycle-consistent and rank-disentangled content- style personalization.arXiv preprint arXiv:2504.13206,
-
[47]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 3, 4, 8
2023
-
[48]
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yan- fei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio- visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025. 9
Pith/arXiv arXiv 2025
-
[49]
Ziplora: Any subject in any style by effectively merging loras
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svet- lana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. In European Conference on Computer Vision, pages 422–438. Springer, 2024. 2, 3
2024
-
[50]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. InThe Eleventh International Con- ference on Learning Representations, 2023. 3
2023
-
[51]
Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, et al. Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
-
[52]
Measuring style similarity in diffusion models.arXiv preprint arXiv:2404.01292, 2024
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shra- may Palta, Micah Goldblum, Jonas Geiping, Abhinav Shri- vastava, and Tom Goldstein. Measuring style similarity in diffusion models.arXiv preprint arXiv:2404.01292, 2024. 7, 4
arXiv 2024
-
[53]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 7
2021
-
[54]
Save: Protagonist diversification with s tructure a gnostic v ideo e diting
Yeji Song, Wonsik Shin, Junsoo Lee, Jeesoo Kim, and No- jun Kwak. Save: Protagonist diversification with s tructure a gnostic v ideo e diting. InEuropean Conference on Com- puter Vision, pages 41–57. Springer, 2024. 3
2024
-
[55]
Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025. 9
Pith/arXiv arXiv 2025
-
[56]
Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 3, 7, 9
Pith/arXiv arXiv 2025
-
[57]
Haofan Wang, Peng Xing, Renyuan Huang, Hao Ai, Qixun Wang, and Xu Bai. Instantstyle-plus: Style transfer with content-preserving in text-to-image generation.arXiv preprint arXiv:2407.00788, 2024. 3
arXiv 2024
-
[58]
Stableidentity: Inserting anybody into anywhere at first sight.IEEE Transactions on Multimedia, 2025
Qinghe Wang, Xu Jia, Xiaomin Li, Taiqing Li, Liqian Ma, Yunzhi Zhuge, and Huchuan Lu. Stableidentity: Inserting anybody into anywhere at first sight.IEEE Transactions on Multimedia, 2025. 3
2025
-
[59]
Characterfactory: Sampling consis- tent characters with gans for diffusion models.IEEE Trans- actions on Image Processing, 2025
Qinghe Wang, Baolu Li, Xiaomin Li, Bing Cao, Liqian Ma, Huchuan Lu, and Xu Jia. Characterfactory: Sampling consis- tent characters with gans for diffusion models.IEEE Trans- actions on Image Processing, 2025. 3
2025
-
[60]
Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cinemaster: A 3d-aware and controllable frame- work for cinematic text-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, pages 1–10, 2025
2025
-
[61]
Multishotmaster: A controllable multi-shot video generation framework
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16268–16278, 2026. 3
2026
-
[62]
Wenchuan Wang, Mengqi Huang, Yijing Tu, and Zhen- dong Mao. Dualreal: Adaptive joint training for loss- less identity-motion fusion in video customization.arXiv preprint arXiv:2505.02192, 2025. 2, 3
arXiv 2025
-
[63]
Dreamvideo: Composing your dream videos with customized subject and motion
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhi- heng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, and Hong- ming Shan. Dreamvideo: Composing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6537–6549, 2024. 2, 3
2024
-
[64]
Mo- tionbooth: Motion-aware customized text-to-video genera- tion
Jianzong Wu, Xiangtai Li, Yanhong Zeng, Jiangning Zhang, Qianyu Zhou, Yining Li, Yunhai Tong, and Kai Chen. Mo- tionbooth: Motion-aware customized text-to-video genera- tion. InThe Thirty-eighth Annual Conference on Neural In- formation Processing Systems, 2024. 3
2024
-
[65]
Custom- crafter: Customized video generation with preserving mo- tion and concept composition abilities
Tao Wu, Yong Zhang, Xintao Wang, Xianpan Zhou, Guang- cong Zheng, Zhongang Qi, Ying Shan, and Xi Li. Custom- crafter: Customized video generation with preserving mo- tion and concept composition abilities. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8469– 8477, 2025. 3
2025
-
[66]
Infinite-id: Identity-preserved personalization via id- semantics decoupling paradigm
Yi Wu, Ziqiang Li, Heliang Zheng, Chaoyue Wang, and Bin Li. Infinite-id: Identity-preserved personalization via id- semantics decoupling paradigm. InEuropean Conference on Computer Vision, pages 279–296. Springer, 2024. 3
2024
-
[67]
Cookgalip: Recipe controllable generative adversarial clips with sequential ingredient prompts for food image generation.IEEE Transactions on Multimedia, 2024
Mengling Xu, Jie Wang, Ming Tao, Bing-Kun Bao, and Changsheng Xu. Cookgalip: Recipe controllable generative adversarial clips with sequential ingredient prompts for food image generation.IEEE Transactions on Multimedia, 2024. 3
2024
-
[68]
Chain-of- cooking: Cooking process visualization via bidirectional chain-of-thought guidance
Mengling Xu, Ming Tao, and Bing-Kun Bao. Chain-of- cooking: Cooking process visualization via bidirectional chain-of-thought guidance. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9287–9295, 2025
2025
-
[69]
Pro- cessmaker: A generalized process visualization framework with adaptive sequence steps on diffusion transformers
Mengling Xu, Sisi You, Yaning Li, and Bing-Kun Bao. Pro- cessmaker: A generalized process visualization framework with adaptive sequence steps on diffusion transformers. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 25699–25708, 2026. 3 12
2026
-
[70]
Clgc: Con- tinuous layout guidance for consistent text-to-video editing
Xuancheng Xu, Ming Tao, and Bing-Kun Bao. Clgc: Con- tinuous layout guidance for consistent text-to-video editing. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 7
2025
-
[71]
Smrabooth: Subject and motion representation alignment for customized video generation
Xuancheng Xu, Yaning Li, Sisi You, and Bing-Kun Bao. Smrabooth: Subject and motion representation alignment for customized video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16130–16141, 2026. 3
2026
-
[72]
B4m: Break- ing low-rank adapter for making content-style customiza- tion.ACM Transactions on Graphics, 44(2):1–17, 2025
Yu Xu, Fan Tang, Juan Cao, Yuxin Zhang, Oliver Deussen, Weiming Dong, Jintao Li, and Tong-Yee Lee. B4m: Break- ing low-rank adapter for making content-style customiza- tion.ACM Transactions on Graphics, 44(2):1–17, 2025. 3
2025
-
[73]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 3
Pith/arXiv arXiv 2025
-
[74]
Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation
Jiahui Yang, Yongjia Ma, Donglin Di, Jianxun Cui, Hao Li, Wei Chen, Yan Xie, Xun Yang, and Wangmeng Zuo. Qr-lora: Efficient and disentangled fine-tuning via qr decomposition for customized generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17587– 17597, 2025. 3
2025
-
[75]
Direct-a-video: Customized video generation with user- directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user- directed camera movement and object motion. InACM SIG- GRAPH 2024 Conference Papers, pages 1–12, 2024. 3
2024
-
[76]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
Pith/arXiv arXiv 2024
-
[77]
Space-time diffusion features for zero-shot text-driven motion transfer
Danah Yatim, Rafail Fridman, Omer Bar-Tal, Yoni Kasten, and Tali Dekel. Space-time diffusion features for zero-shot text-driven motion transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8466–8476, 2024. 4
2024
-
[78]
Flexiact: Towards flexible action control in heterogeneous scenarios
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 2, 8
2025
-
[79]
Meta-cot: Enhancing granularity and generaliza- tion in image editing
Shiyi Zhang, Yiji Cheng, Tiankai Hang, Zijin Yin, Runze He, Yu Xu, Wenxun Dai, Yunlong Lin, Chunyu Wang, Qinglin Lu, et al. Meta-cot: Enhancing granularity and generaliza- tion in image editing. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 38004–38015, 2026. 3
2026
-
[80]
Tar3d: Creating high-quality 3d assets via next-part prediction
Xuying Zhang, Yutong Liu, Yangguang Li, Renrui Zhang, Yufei Liu, Kai Wang, Wanli Ouyang, Zhiwei Xiong, Peng Gao, Qibin Hou, et al. Tar3d: Creating high-quality 3d assets via next-part prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5134– 5145, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.