NL2Scratch: An Executable Benchmark and Evaluation for Block-Based Programming
Pith reviewed 2026-06-26 11:54 UTC · model grok-4.3
The pith
NL2Scratch benchmark shows LLMs often fail semantic alignment on Scratch programs despite high lexical scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
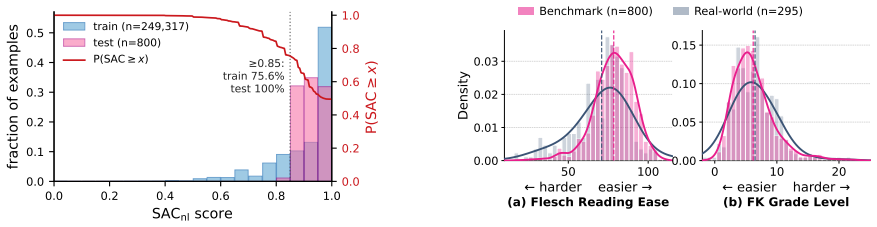
The paper establishes that lexical metrics such as token-level F1 do not reliably indicate semantic correctness in natural-language-to-Scratch generation; models can score above 0.93 F1 yet still produce programs that mismatch on operational slots, and this discrepancy is measured by the new Semantic Alignment Consistency metric on an executable benchmark of 311,648 parser-valid pairs.
What carries the argument
NL2Scratch executable benchmark of 311,648 NL-program pairs together with the Semantic Alignment Consistency (SAC) slot-level metric that scores agreement on individual program elements such as actions, conditions, and arguments.
If this is right
- Evaluation of NL-to-block-code models must move beyond token overlap to slot-level semantic checks.
- Operational slots such as actions, conditions, and numeric arguments require targeted model improvements.
- Longer Scratch scripts expose larger semantic gaps that short-example benchmarks would miss.
- The 23,594 semantically validated examples provide a cleaner test set for future work.
- Executable benchmarks are needed for other visual programming languages where conventional metrics fall short.
Where Pith is reading between the lines
- Similar semantic slot metrics could be adapted for other event-driven or concurrent languages used in education.
- Focusing training data on operational elements might close the observed lexical-semantic gap.
- The benchmark could support automatic repair systems that fix only the mismatched slots rather than regenerating entire programs.
Load-bearing premise
The 311,648 parser-valid pairs are semantically aligned with their natural-language descriptions and the SAC metric correctly captures that alignment.
What would settle it
Human raters independently scoring a sample of model outputs on the same slot categories used by SAC and finding that high-F1 models achieve near-perfect slot agreement on the validated subset.
Figures




read the original abstract
Block-based programming environments such as Scratch are widely used in early programming education, yet natural-language-to-code (NL2Code) research has focused primarily on text-based languages. Scratch programs are event-driven, visually compositional, and distributed across concurrent scripts, making conventional NL2Code assumptions and evaluation insufficient. We introduce NL2Scratch, an executable benchmark for natural-language-to-Scratch generation comprising 311,648 parser-valid NL--program pairs, whose program side is extracted from real Scratch projects and paired with semantically aligned NL descriptions. For reliable evaluation beyond surface overlap, we propose Semantic Alignment Consistency (SAC), an interpretable slot-level metric for measuring semantic agreement between descriptions and programs. With SAC, we construct a semantically validated pool of 23,594 examples, and a slot-balanced 800 diagnostic benchmark. Experiments across instruction-tuned and fine-tuned LLMs reveal a notable gap between lexical similarity and semantic alignment: models achieving token-level F1 above 0.93 often fail to attain perfect SAC, particularly on longer examples. Errors concentrate on operational slots like actions, conditions, and numeric arguments, exposing failure modes largely invisible under conventional metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NL2Scratch, an executable benchmark for NL-to-Scratch generation with 311,648 parser-valid NL-program pairs extracted from real projects and paired with semantically aligned descriptions. It proposes the slot-level Semantic Alignment Consistency (SAC) metric, constructs a validated pool of 23,594 examples plus a slot-balanced 800-example diagnostic set, and reports experiments showing that LLMs with token F1 >0.93 often fail to reach perfect SAC, with errors concentrated on actions, conditions, and numeric arguments.
Significance. If the validation protocol and SAC metric prove reliable, the work supplies a needed executable benchmark for block-based languages that are central to early CS education but absent from most NL2Code research. The emphasis on executable semantics and slot-level errors offers a concrete way to expose limitations of lexical metrics.
major comments (2)
- [Abstract] Abstract: the claim that the 23,594-example pool is 'semantically validated' and that the observed F1-SAC gap reflects genuine model failure modes is load-bearing, yet the abstract supplies no information on the validation protocol (annotator count, instructions, IAA, adjudication rules, or exclusion criteria). Without these details the interpretability of SAC and the headline result cannot be assessed.
- [Abstract] Abstract: the extraction and semantic-alignment procedure for the full 311,648 parser-valid pairs is described only at the level of 'extracted from real Scratch projects and paired with semantically aligned NL descriptions,' with no further specification of how alignment was established or verified; this underpins every downstream claim about model performance.
minor comments (1)
- [Abstract] The abstract states that a 'slot-balanced 800-example diagnostic benchmark' was derived but does not define the slot inventory, balancing procedure, or selection criteria.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater specificity is needed there to support the interpretability of our claims and will revise the abstract accordingly while ensuring the body of the paper already contains the supporting details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 23,594-example pool is 'semantically validated' and that the observed F1-SAC gap reflects genuine model failure modes is load-bearing, yet the abstract supplies no information on the validation protocol (annotator count, instructions, IAA, adjudication rules, or exclusion criteria). Without these details the interpretability of SAC and the headline result cannot be assessed.
Authors: We agree that the abstract should briefly indicate the validation protocol to allow readers to assess the claims without immediately consulting the body. The full protocol (including annotator procedures, instructions, agreement metrics, adjudication, and exclusion rules) is described in Section 3.2. We will revise the abstract to include a concise clause summarizing the validation approach and will ensure the revised abstract remains within length limits. revision: yes
-
Referee: [Abstract] Abstract: the extraction and semantic-alignment procedure for the full 311,648 parser-valid pairs is described only at the level of 'extracted from real Scratch projects and paired with semantically aligned NL descriptions,' with no further specification of how alignment was established or verified; this underpins every downstream claim about model performance.
Authors: We acknowledge that the abstract's phrasing is high-level and does not specify the alignment verification steps. The extraction pipeline, parser validation, and semantic-alignment method (including how descriptions were generated and checked for fidelity to the programs) are detailed in Section 3.1. We will revise the abstract to add a short clause indicating that alignment was established via the procedure described in the methods, thereby making the foundation of the benchmark clearer at the abstract level. revision: yes
Circularity Check
No circularity; benchmark construction with independent empirical claims
full rationale
The paper constructs a dataset of NL-program pairs and proposes the SAC metric for evaluation. No derivations, equations, fitted parameters, or predictions are described that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked. The central result (gap between F1 and SAC) is an empirical observation on the constructed benchmark rather than a self-referential derivation. This matches the default expectation of no significant circularity for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)
Litterbox+: An extensible framework for llm- enhanced scratch static code analysis. InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE. Tool Demonstration Track. James Finnie-Ansley, Paul Denny, Brett A Becker, An- drew Luxton-Reilly, and James Prather. 2022. The robots are coming: Exploring the impli...
Pith/arXiv arXiv 2022
-
[2]
InProceedings of the 2023 CHI conference on human factors in computing systems, pages 1–23
Studying the effect of ai code generators on supporting novice learners in introductory program- ming. InProceedings of the 2023 CHI conference on human factors in computing systems, pages 1–23. Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii...
2023
-
[3]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297. Mitchel Resnick, John Maloney, Andrés Monroy- Hernández, Natalie Rusk, Evel...
Pith/arXiv arXiv 2020
-
[4]
arXiv preprint arXiv:2509.11065
Viscratch: Using large language models and gameplay videos for automated feedback in scratch. arXiv preprint arXiv:2509.11065. Jake Trower and Jeff Gray. 2015. Blockly language creation and applications: Visual programming for media computation and bluetooth robotics control. InProceedings of the 46th ACM Technical Sympo- sium on Computer Science Educatio...
arXiv 2015
-
[5]
Output only Scratch pseudocode, with one block per line and no markdown
-
[6]
Do not output opcode keys
Use exact Scratch-style block text from the exam- ples. Do not output opcode keys
-
[7]
move (10) steps
Stack/command blocks are plain lines, e.g. move (10) steps
-
[8]
(x position),((score) + (1))
Reporter inputs must be wrapped in parentheses, e.g. (x position),((score) + (1))
-
[9]
Boolean conditions must be wrapped in angle brack- ets, e.g.<mouse down?>,<touching (edge v)?>
-
[10]
[message1],[costume1],[score v]
Text/name inputs use square brackets, e.g. [message1],[costume1],[score v]
-
[11]
(space v),(random position v),[all v]
Menu/dropdown inputs include the v marker, e.g. (space v),(random position v),[all v]
-
[12]
Control blocks use exact forms such asrepeat (10) , forever, if <condition> then , if <condition> then else,wait until <condition>
-
[13]
Indent nested blocks with exactly 4 spaces and close every C-block withend
-
[14]
For if else, use: if <condition> then , true branch,else, false branch,end
-
[15]
Preserve names, messages, numbers, signs, decimal values, and action order from the natural language
-
[16]
If no event is described, do not invent one. [Retrieved Examples]Here are some examples: 20 * Example (Natural Language, Pseudocode) [Test Item]Now, please generate the Scratch pseu- docode for the following description: Natural Language:{natrual_language_query} Pseudocode:[To be generated] Natural-Language Rewriting Prompt used for Dataset Construction [...
-
[17]
Keep the meaning exactly the same
-
[18]
Do not add or remove any steps
-
[19]
Keep all numbers exactly the same
-
[20]
Keep triggers and conditions explicit
-
[21]
Keep variable, sprite, costume, backdrop, and message names unchanged
-
[22]
Remove awkward menu markers and quoting when possible
-
[23]
q key” instead of “q v
For key names, say things like “q key” instead of “q v”
-
[24]
Do not output pseudocode
-
[25]
Output only the rewritten natural-language in- struction. [User Prompt Template] Scratchblocks pseudocode: {pseudocode} Base instruction: {base_nl} Rewrite it as one natural child-like instruction: 11 B Additional Dataset Statistics Table 3 reports SAC-slot coverage across the full parser-valid corpus, the SAC-filtered high- confidence pool, and the final...
-
[26]
extract a structured slot representation from the pseudocode
-
[27]
extract a corresponding slot representation from the natural language
-
[28]
forever”, “keep
compare the extracted slots with slot-specific similarity functions. The output includes per-slot scores, an overall alignment score, a binary perfect-alignment flag, a binary high-confidence-alignment flag, and a list of mismatched slots. We define perfect alignment as SAC = 1.0 and high-confidence alignment as SAC≥0.85. Slot schema.SAC uses the ordered ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.