Driving Video Retrieval for Complex Queries with Structured Grounding
Pith reviewed 2026-06-27 17:25 UTC · model grok-4.3
The pith
STRIVE-D retrieves driving videos for complex events by calibrating rules with weakly labeled data and fusing multiple signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
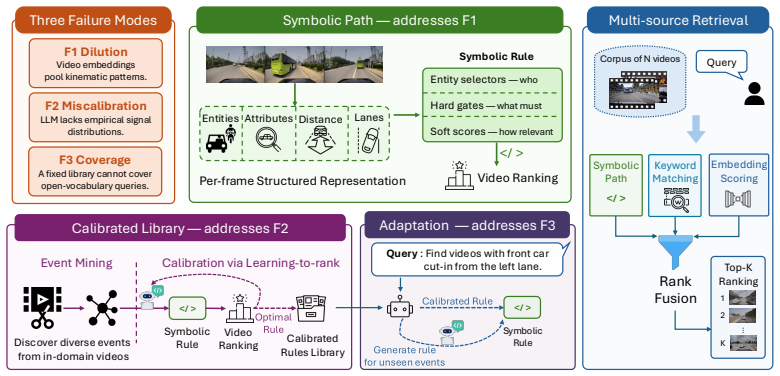
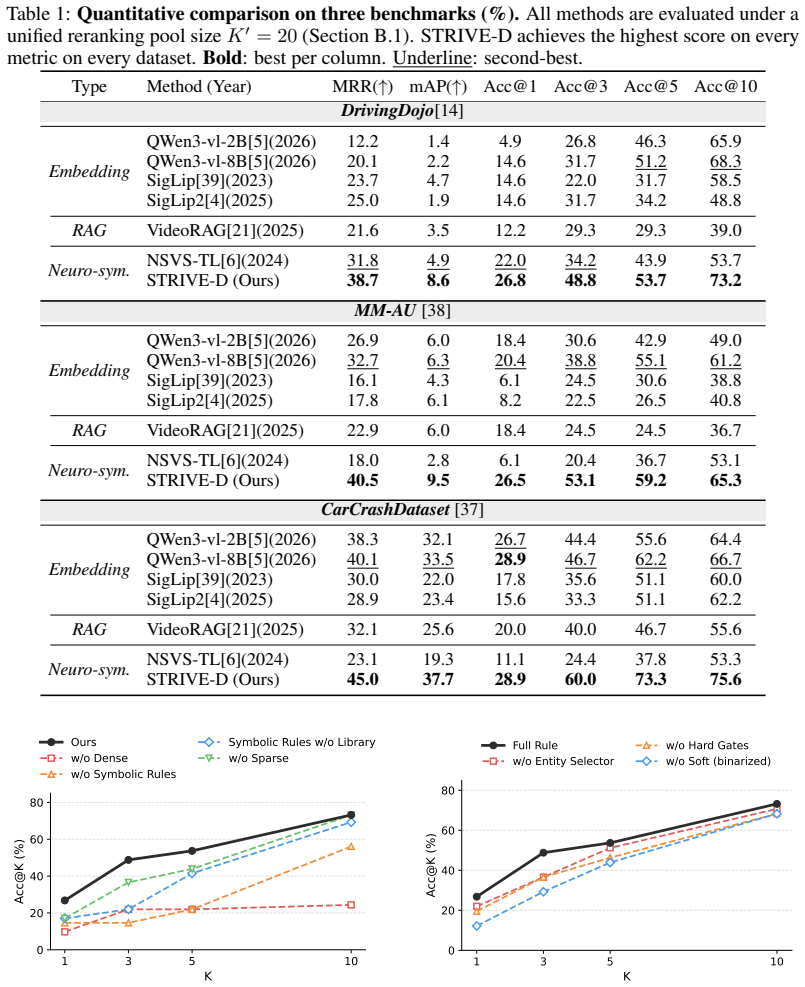
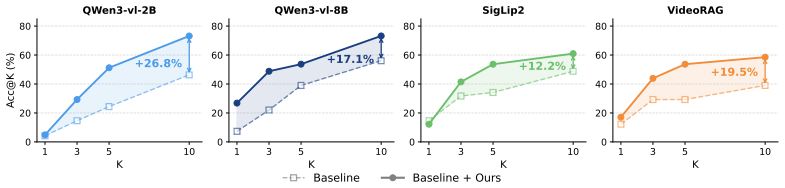
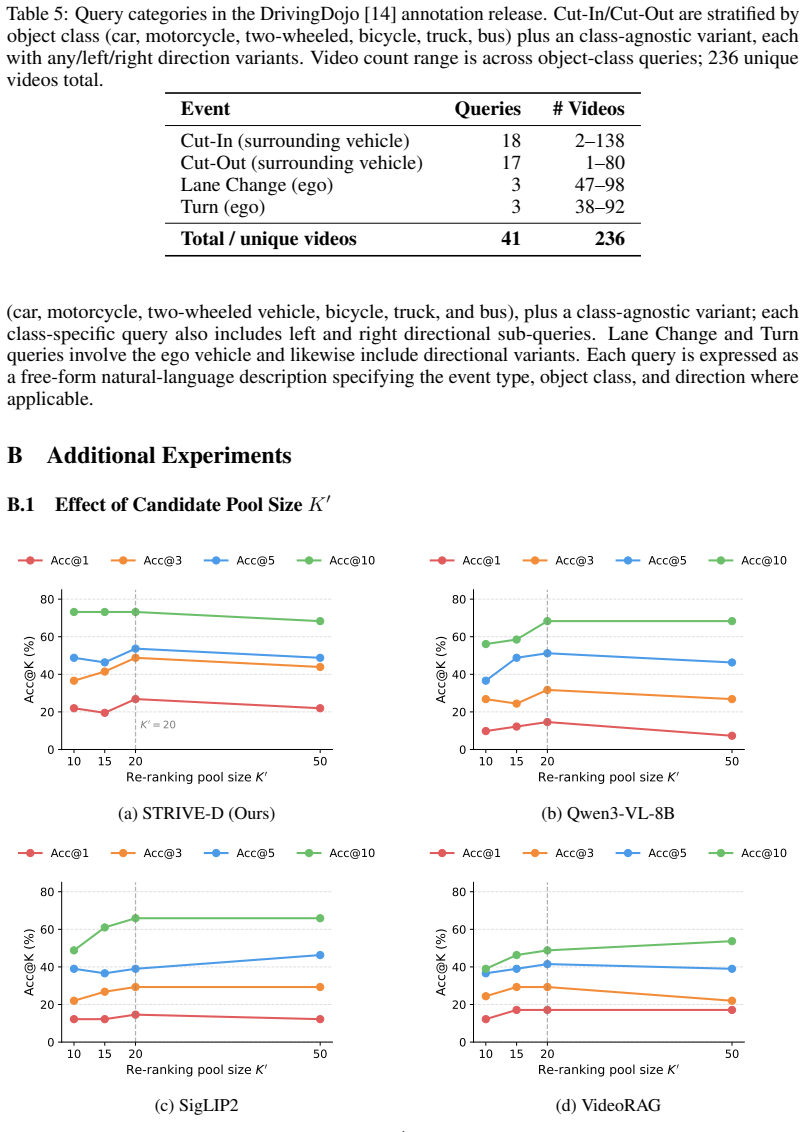
STRIVE-D is a retrieval framework that uses weakly labeled in-domain videos to estimate when a query rule is reliable, to adapt rules whose assumptions do not match observed data, and to fuse the resulting calibrated rule scores with vision-language and keyword-based signals, yielding up to 84 percent relative improvement in top-1 accuracy across three driving benchmarks.
What carries the argument
STRIVE-D, a data-calibrated retrieval framework that estimates rule reliability and adapts mismatched rules from weakly labeled videos before fusion with other retrieval signals.
If this is right
- Complex motion events that lack explicit text descriptions become retrievable at scale.
- Rule-based methods become usable in real driving data instead of remaining brittle.
- Fusion of calibrated rules with existing vision-language and keyword methods produces measurable accuracy gains on standard benchmarks.
- New human-annotated event data such as the DrivingDojo release can be searched more effectively.
Where Pith is reading between the lines
- The same calibration approach could be tested on non-driving video domains that rely on rule-based event detection.
- If the weak-label signal proves insufficient in some domains, the framework would need an explicit reliability threshold or additional supervision.
- The method suggests that structured grounding can be maintained even when initial rules are imperfect, provided an in-domain calibration set exists.
Load-bearing premise
Weakly labeled in-domain videos contain enough signal to determine when a query rule is reliable and to adapt rules that do not match the observed data.
What would settle it
Run the calibrated rules on a fresh set of driving videos whose event labels were collected independently of the weak labels used for calibration; if top-1 accuracy does not rise relative to the uncalibrated baselines, the central claim is false.
Figures




read the original abstract
Video retrieval at scale is central to data curation and safety validation in autonomous driving, where users want to find not only scenes but also dynamic events such as cut-ins and hard braking. Existing vision-language and keyword-based retrieval methods often miss these events because the relevant motion may not be explicitly described in text or captured by lexical overlap. Rule-based retrieval can encode such events more directly, but it is brittle: generated or hand-written rules often fail when their assumptions do not match real driving data. We propose STRIVE-D, a data-calibrated retrieval framework for driving videos. It uses weakly labeled in-domain videos to estimate when a query rule is reliable, adapt rules that mismatch observed data, and fuse calibrated rule scores with vision-language and keyword-based retrieval signals. Across three driving benchmarks, including newly released human-annotated event data on DrivingDojo, STRIVE-D delivers up to 84% relative improvement in top-1 accuracy over state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STRIVE-D, a data-calibrated retrieval framework for driving videos. It uses weakly labeled in-domain videos to estimate when a query rule is reliable, adapt rules that mismatch observed data via data-driven parameter updates, and fuse calibrated rule scores with vision-language and keyword-based retrieval signals. The method is evaluated on three driving benchmarks including newly released human-annotated event data on DrivingDojo, reporting up to 84% relative improvement in top-1 accuracy over state-of-the-art methods.
Significance. If the empirical results hold under the described calibration and fusion mechanisms, the work would meaningfully advance scalable video retrieval for autonomous driving data curation and safety validation by mitigating brittleness in rule-based event retrieval. The concrete mechanisms for reliability estimation and rule adaptation, together with the release of new annotated data, represent practical strengths that could influence downstream applications.
Simulated Author's Rebuttal
We thank the referee for their thorough reading and positive assessment of our work. We are encouraged by the recognition of STRIVE-D's practical contributions to reliable rule-based retrieval in driving video data and the value of the newly released annotations.
Circularity Check
No significant circularity
full rationale
The paper presents STRIVE-D as an empirical framework relying on concrete mechanisms (calibration via observed event frequencies in weakly labeled videos, data-driven rule adaptation, and late fusion with VL/keyword signals) to address rule brittleness. No equations, derivations, or first-principles claims are provided that reduce any reported accuracy improvement or prediction to fitted parameters or self-referential quantities by construction. No self-citations are used to import uniqueness theorems or ansatzes, and the 84% relative improvement is framed as an observed outcome across external benchmarks rather than a derived guarantee. The derivation chain is therefore self-contained against independent data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BDD100K: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. BDD100K: A diverse driving dataset for heterogeneous multitask learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[2]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[3]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
2020
-
[4]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features....
Pith/arXiv arXiv 2025
-
[5]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Chen Keqin, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026
Pith/arXiv arXiv 2026
-
[6]
Towards neuro-symbolic video understanding
Minkyu Choi, Harsh Goel, Mohammad Omama, Yunhao Yang, Sahil Shah, and Sandeep Chinchali. Towards neuro-symbolic video understanding. InEuropean Conference on Computer Vision, pages 220–236. Springer, 2024
2024
-
[7]
Neus-qa: Grounding long-form video understanding in temporal logic and neuro-symbolic reasoning
Sahil Shah, SP Sharan, Harsh Goel, Minkyu Choi, Mustafa Munir, Manvik Pasula, Radu Marculescu, and Sandeep Chinchali. Neus-qa: Grounding long-form video understanding in temporal logic and neuro-symbolic reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[8]
ViperGPT: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. ViperGPT: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[9]
Neural-symbolic videoqa: Learning compositional spatio-temporal reasoning for real-world video question answering, 2024
Lili Liang, Guanglu Sun, Jin Qiu, and Lizhong Zhang. Neural-symbolic videoqa: Learning compositional spatio-temporal reasoning for real-world video question answering, 2024
2024
-
[10]
Learning to rank for information retrieval.Foundations and Trends in Information Retrieval, 3(3):225–331, 2009
Tie-Yan Liu. Learning to rank for information retrieval.Foundations and Trends in Information Retrieval, 3(3):225–331, 2009
2009
-
[11]
Distant supervision for relation extraction without labeled data
Mike Mintz, Steven Bills, Rion Snow, and Daniel Jurafsky. Distant supervision for relation extraction without labeled data. InProceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 1003–1011, 2009
2009
-
[12]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[13]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625:468–475, 2024. 10
2024
-
[14]
DrivingDojo dataset: Advancing interactive and knowledge-enriched driving world model
Yuqi Wang, Ke Cheng, Jiawei He, Qitai Wang, Hengchen Dai, Yuntao Chen, Fei Xia, and Zhaoxiang Zhang. DrivingDojo dataset: Advancing interactive and knowledge-enriched driving world model. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024
2024
-
[15]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[16]
Hitea: Hierarchi- cal temporal alignment for training-free long-video temporal grounding
Xinyi Xu, Hongsong Wang, Guo-Sen Xie, Caifeng Shan, and Fang Zhao. Hitea: Hierarchi- cal temporal alignment for training-free long-video temporal grounding. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval.Neurocomputing, 508:293–304, 2022
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval.Neurocomputing, 508:293–304, 2022
2022
-
[18]
X-CLIP: End-to- end multi-grained contrastive learning for video-text retrieval
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-CLIP: End-to- end multi-grained contrastive learning for video-text retrieval. InProceedings of the 30th ACM International Conference on Multimedia (ACM MM), 2022
2022
-
[19]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[20]
VideoChat: Chat-centric video understanding.Science China Information Sciences, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Yali Wang, Limin Wang, and Yu Qiao. VideoChat: Chat-centric video understanding.Science China Information Sciences, 2025
2025
-
[21]
VideoRAG: Retrieval- augmented generation over video corpus
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. VideoRAG: Retrieval- augmented generation over video corpus. InFindings of the Association for Computational Linguistics (ACL Findings), 2025
2025
-
[22]
The probabilistic relevance framework: Bm25 and beyond.Found
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond.Found. Trends Inf. Retr., 3(4):333–389, April 2009
2009
-
[23]
SPLADE: Sparse lexical and expansion model for first stage ranking
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. SPLADE: Sparse lexical and expansion model for first stage ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pages 2288–2292, 2021
2021
-
[24]
VideoComp: Advancing fine-grained compositional and temporal alignment in video-text models
Dahun Kim, AJ Piergiovanni, Ganesh Mallya, and Anelia Angelova. VideoComp: Advancing fine-grained compositional and temporal alignment in video-text models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 29060–29070, 2025
2025
-
[25]
Ventura, A
L. Ventura, A. Yang, C. Schmid, and G. Varol. Tf-covr: Temporally fine-grained composed video retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[26]
Reasoning text-to-video retrieval via digital twin video representations and large language models, 2025
Yiqing Shen, Chenxiao Fan, Chenjia Li, and Mathias Unberath. Reasoning text-to-video retrieval via digital twin video representations and large language models, 2025
2025
-
[27]
ifinder: Structured zero- shot vision-based llm grounding for dash-cam video reasoning
Manyi Yao, Bingbing Zhuang, Sparsh Garg, and Abhishek Aich. ifinder: Structured zero- shot vision-based llm grounding for dash-cam video reasoning. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[28]
From road to code: Neuro-symbolic program synthesis for autonomous driving scene translation and analysis
Johnathan Leung, Guansen Tong, Parasara Sridhar Duggirala, and Praneeth Chakravarthula. From road to code: Neuro-symbolic program synthesis for autonomous driving scene translation and analysis. In George Pappas, Pradeep Ravikumar, and Sanjit A. Seshia, editors,Proceedings of the International Conference on Neuro-symbolic Systems, volume 288 ofProceedings...
2025
-
[29]
A V A: Towards agentic video analytics with vision language models
Yuxuan Yan, Shiqi Jiang, Ting Cao, Yifan Yang, Qianqian Yang, Yuanchao Shu, Yuqing Yang, and Lili Qiu. A V A: Towards agentic video analytics with vision language models. InUSENIX Symposium on Networked Systems Design and Implementation (NSDI), 2026
2026
-
[30]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[31]
DiLu: A knowledge-driven approach to autonomous driving with large language models
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. DiLu: A knowledge-driven approach to autonomous driving with large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[32]
Monitoring temporal properties of continuous signals
Oded Maler and Dejan Nickovic. Monitoring temporal properties of continuous signals. In Formal Techniques, Modelling and Analysis of Timed and Fault-Tolerant Systems (FORMAT- S/FTRTFT), volume 3253 ofLecture Notes in Computer Science, pages 152–166. Springer, 2004
2004
-
[33]
Robust satisfaction of temporal logic over real-valued signals
Alexandre Donzé and Oded Maler. Robust satisfaction of temporal logic over real-valued signals. InFormal Modeling and Analysis of Timed Systems (FORMATS), volume 6246 of Lecture Notes in Computer Science, pages 92–106. Springer, 2010
2010
-
[34]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V . Cormack, Charles L A Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’09, page 758–759, New York, NY , USA, 2009. Association for Computing Machinery
2009
-
[35]
Moura, Shizhan Zhu, and Orly Zvitia
Daniel C. Moura, Shizhan Zhu, and Orly Zvitia. Nexar dashcam collision prediction dataset and challenge. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2025
2025
-
[36]
Gpt-4o system card, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card, 2024
2024
-
[37]
Uncertainty-based traffic accident anticipation with spatio- temporal relational learning
Wentao Bao, Qi Yu, and Yu Kong. Uncertainty-based traffic accident anticipation with spatio- temporal relational learning. InACM Multimedia Conference, May 2020
2020
-
[38]
Abductive ego-view accident video understanding for safe driving perception
Jianwu Fang, Lei-lei Li, Junfei Zhou, Junbin Xiao, Hongkai Yu, Chen Lv, Jianru Xue, and Tat-Seng Chua. Abductive ego-view accident video understanding for safe driving perception. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22030–22040, June 2024
2024
-
[39]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[40]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[41]
GeoCalib: Single-image calibration with geometric optimization
Alexander Veicht, Paul-Edouard Sarlin, Philipp Lindenberger, and Marc Pollefeys. GeoCalib: Single-image calibration with geometric optimization. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[42]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24185–24198, 2024
2024
-
[43]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras.Advances in Neural Information Processing Systems (NeurIPS), 34:16558– 16569, 2021
Zachary Teed and Jia Deng. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras.Advances in Neural Information Processing Systems (NeurIPS), 34:16558– 16569, 2021. 12
2021
-
[44]
Scaling open-vocabulary object detection
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[45]
ByteTrack: Multi-object tracking by associating every detection box
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. ByteTrack: Multi-object tracking by associating every detection box. InProceedings of the European Conference on Computer Vision (ECCV), 2022
2022
-
[46]
OMR: Occlusion-aware memory-based refinement for video lane detection
Dongkwon Jin and Chang-Su Kim. OMR: Occlusion-aware memory-based refinement for video lane detection. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[47]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3D v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
2024
-
[48]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, et al. Segment anything.arXiv preprint arXiv:2304.02643, 2023
Pith/arXiv arXiv 2023
-
[49]
car skids in snow
Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Tracking objects as points. InEuropean Conference on Computer Vision (ECCV), 2020. 13 A Experimental Setup A.1 Perception Pipeline We adopt the perception pipeline of iFinder [27] with a single substitution: the video captioner used at library-construction time is replaced by Qwen2.5-VL-7B [40]. The pip...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.