Learning to target with network interference
Pith reviewed 2026-06-29 10:22 UTC · model grok-4.3
The pith
Knowledge of network interference structure sets the achievable regret in linear bandit targeting, with ignoring it causing inefficiency in large populations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
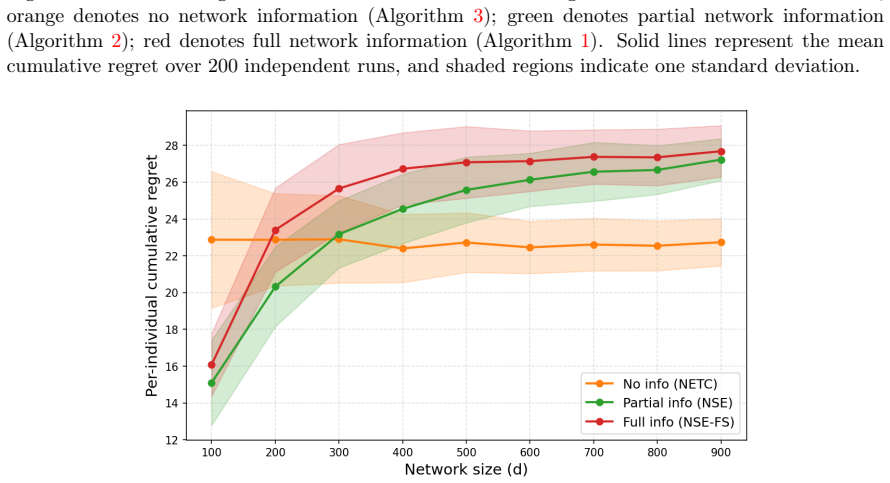
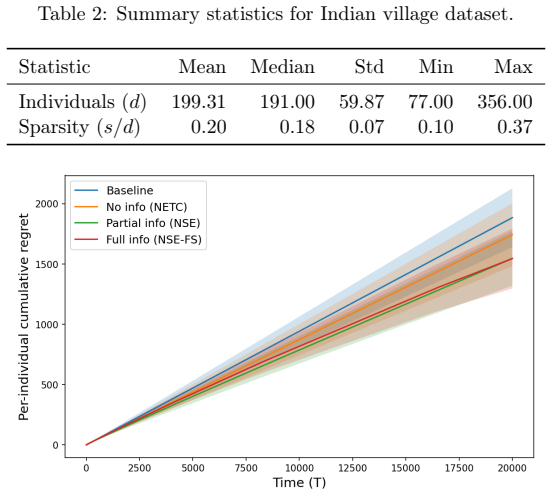
In the linear model with sparse network interference, where each individual's outcome is affected by at most a few others, regret lower bounds characterize the fundamental limits for each level of knowledge about the interference structure. Algorithms are developed that achieve near-optimal regret when the full support is known, when only column support sizes are known, and when no prior knowledge is available, showing how the amount of structural information governs learning efficiency.
What carries the argument
Regret lower bounds and corresponding algorithms that adapt to the available information about the support of the interference matrix in the linear outcome model.
If this is right
- Standard linear bandit methods are provably suboptimal when spillover effects exist but are ignored.
- Full knowledge of the interference support permits the lowest regret among the three regimes.
- Knowledge of column support sizes still improves regret over having no structural information.
- Algorithms exist for each regime that can be deployed in targeting problems with network effects.
Where Pith is reading between the lines
- Collecting even partial network data before targeting could reduce total regret compared to starting with no information.
- The sparsity assumption suggests that methods for estimating the support from initial observations may be worth developing to move between regimes.
- Results could inform sample-efficient design in other domains with spillover, such as market experiments or epidemic control.
Load-bearing premise
The outcomes follow a linear model in which each individual is affected by at most a few others.
What would settle it
An experiment in a large sparse linear network where a standard linear bandit algorithm without structure information matches the regret of the structure-aware algorithms would contradict the lower bound on ignoring the network.
Figures



read the original abstract
This paper studies adaptive targeting under network interference in a bandit setting, where treatments applied to one individual may affect others through spillover effects. We consider a linear model in a sparse regime, where each individual's outcome can be affected by at most a few others. We first establish a regret lower bound showing that ignoring the network structure and reducing the problem to a standard linear bandit inevitably leads to inefficient learning, particularly in large populations. To understand how structural information can be leveraged, we analyze regimes with varying levels of knowledge of the interference structure: (1) full support knowledge, (2) knowledge of the column support sizes, and (3) no prior knowledge. For each regime, we establish regret lower bounds characterizing the fundamental limits of learning, and develop algorithms that achieve near-optimal regret. Together, our results provide a unified view of how knowledge of the interference structure governs the efficiency of online learning under interference, and offer practical adaptive targeting algorithms in each setting. Numerical experiments on synthetic and real-world data demonstrate the practical benefits of our algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies adaptive targeting under network interference in a bandit setting with a linear sparse model where each individual's outcome is affected by at most a few others. It first establishes a regret lower bound showing that ignoring the network structure and reducing to a standard linear bandit leads to inefficient learning in large populations. It then analyzes three regimes of knowledge about the interference structure—(1) full support knowledge, (2) knowledge of column support sizes, and (3) no prior knowledge—providing regret lower bounds characterizing fundamental limits and developing algorithms that achieve near-optimal regret in each regime. Numerical experiments on synthetic and real-world data demonstrate practical benefits.
Significance. If the results hold, the work provides a unified view of how knowledge of interference structure governs efficiency of online learning under network effects, with practical adaptive targeting algorithms for each knowledge regime. Credit is due for the regret lower bounds matched by algorithms across the three regimes and for the empirical validation on real data; these elements strengthen the contribution to the bandit literature with interference.
minor comments (2)
- [Abstract] Abstract: the description of the experiments does not specify the performance metrics, baselines, or statistical controls used to demonstrate benefits; adding one sentence on these would improve clarity without altering the central claims.
- [Introduction] The linear sparse model assumption is stated clearly but its implications for the regret bounds could be illustrated with a brief example in the introduction to aid readers unfamiliar with the sparse regime.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation of minor revision. The summary accurately captures the paper's contributions on regret lower bounds and near-optimal algorithms for linear bandits under sparse network interference in the three knowledge regimes. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper derives regret lower bounds for ignoring network structure and matching algorithms across knowledge regimes using standard linear bandit analysis under a sparse interference model. No quoted steps reduce predictions or bounds to fitted parameters by construction, no self-citation chains support load-bearing claims, and the central results rely on independent proof techniques rather than renaming or ansatz smuggling. This is the expected non-finding for a theoretical regret paper grounded in external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In addition, for any v, r∈R d such thatsupp(v)∩supp(r) =∅and∥v∥ 0 +∥r∥ 0 ≤m, we have |v⊤Ar|= (v+r) ⊤A(v+r)−(v−r) ⊤A(v−r) 4 ≤x+ 1 32 .(21) We now apply the above results withm= 3s. Next, for an arbitrary vectorusatisfying∥u[Sc]∥1 ≤ 3∥u[S]∥1 for someS⊆[d]with|S| ≤s, we decompose its coordinates into blocks of sizeswith the first blockI 1 containing the indi...
-
[2]
By the definition of the blocks, we have for any k≥3that X k≥3 ∥u[Ik]∥2 ≤ X k≥3 1√s ∥u[Ik−1]∥1 ≤ 1√s ∥u[Ic 1]∥1 ≤ 3√s ∥u[I1]∥1 ≤3∥u[I 1]∥2
As for the second term, we have 1 T1 T1X t=1 KX k=3 X j∈Ik ujat,j X j∈I1∪I2 ujat,j ≤ KX k=3 1 T1 T1X t=1 X j∈Ik ujat,j X j∈I1∪I2 ujat,j ≤ x+ 1 32 KX k=3 ∥u[Ik]∥2∥u[I1 ∪I 2]∥2, where the last step uses the result in Equation (21). By the definition of the blocks, we have for any k≥3that X k≥3 ∥u[Ik]∥2 ≤ X k≥3 1√s ∥u[Ik−1]∥1 ≤ 1√s ∥u[Ic 1]∥1 ≤ 3√s ∥u[I1]∥1 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.