Geometry-Consistent Endoscopic Representations for Image-Guided Navigation via Structured Foundation Model Adaptation
Pith reviewed 2026-06-27 03:09 UTC · model grok-4.3
The pith
Hierarchy-aware low-rank adapters plus synthetic geometric supervision produce geometry-consistent features for monocular endoscopic navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
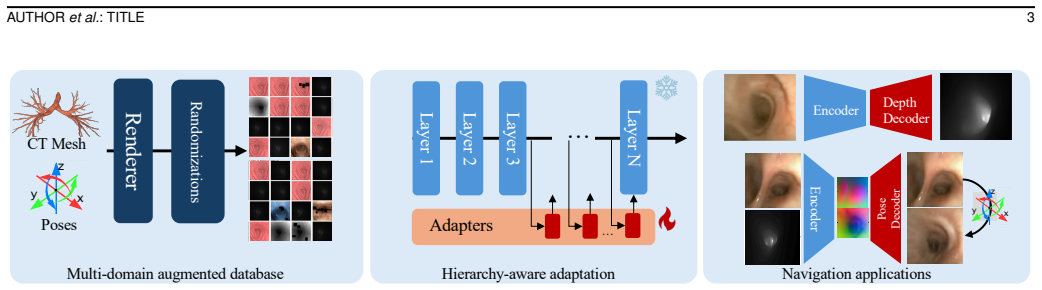
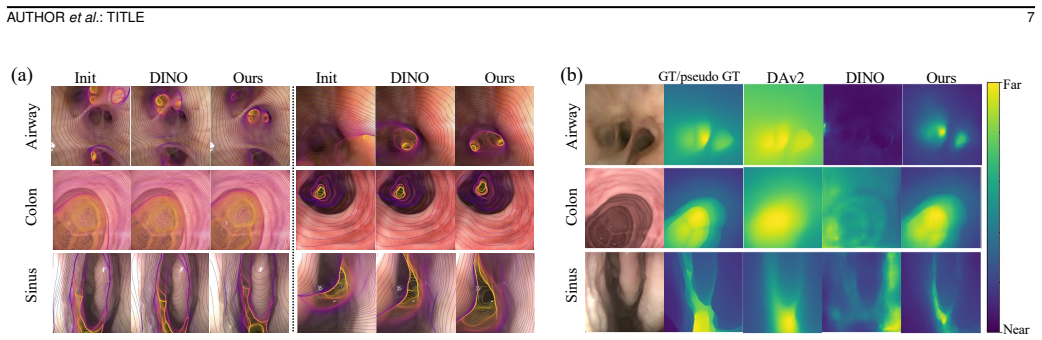
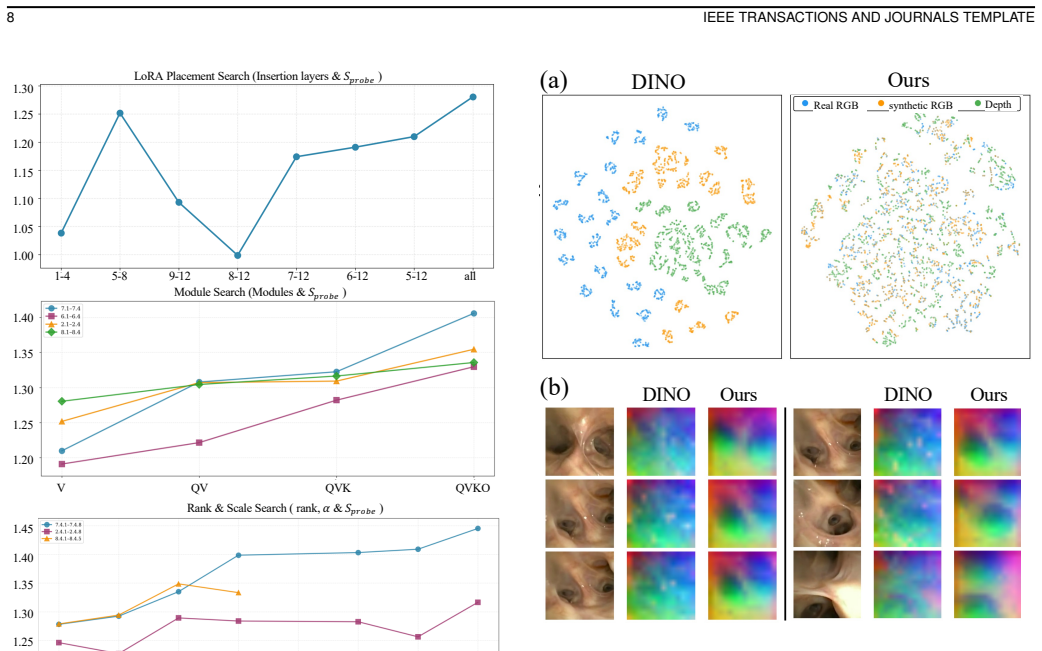
Hierarchy-Aware Geometry-Semantic Adaptation is a structured alternative to standard LoRA that inserts low-rank adapters selectively across the transformer hierarchy and couples them with layer-wise training objectives to encourage geometric correspondence in intermediate features and semantic consistency in deeper features; when trained with a synthetic data pipeline that provides accurate geometric supervision, this produces geometry-consistent and domain-robust image representations that improve performance on pose estimation and monocular depth estimation while enabling favorable synthetic-to-real transfer on clinical bronchoscopy.
What carries the argument
Hierarchy-Aware Geometry-Semantic Adaptation, which inserts low-rank adapters selectively across the transformer hierarchy and couples them with layer-wise objectives for geometry in intermediate layers and semantics in deeper layers.
If this is right
- Improved accuracy on pose estimation and monocular depth estimation tasks.
- Favorable synthetic-to-real transfer on clinical bronchoscopy data.
- The representations serve as a useful initialization for limited-supervision adaptation to sinus endoscopy and colonoscopy.
- Performance scales favorably with larger model size and more training data.
Where Pith is reading between the lines
- The same hierarchy-aware structure might stabilize feature correspondence under non-rigid tissue deformation even without explicit deformation modeling.
- The approach could reduce reliance on large quantities of real annotated endoscopic data by leveraging synthetic geometry as the primary signal.
- Extending the layer-wise objectives to additional tasks such as surface reconstruction might further tighten geometry consistency without changing the adapter placement.
Load-bearing premise
The synthetic data pipeline supplies accurate geometric supervision whose distribution is close enough to real endoscopic images for the hierarchy-aware adapters to produce transferable geometry-consistent features.
What would settle it
A direct comparison on clinical bronchoscopy videos showing that the adapted model yields no measurable gain in pose estimation accuracy or depth consistency over a standard LoRA baseline or an unadapted foundation model would falsify the central claim.
Figures

read the original abstract
Accurate vision-based navigation in monocular endoscopy is difficult due to limited depth cues, weak tissue texture, non-rigid deformation, and substantial appearance variation across domains, all of which complicate pose estimation, depth prediction, and image-to-anatomy alignment. Although recent vision foundation models have shown promise, their learned representations often remain insufficiently geometry-consistent, hindering stable feature correspondence and limiting their reliability for downstream navigation tasks. We propose a unified framework for learning geometry-consistent and domain-robust image representations for monocular endoscopy. The framework combines a synthetic data pipeline that provides accurate geometric supervision with Hierarchy-Aware Geometry-Semantic Adaptation, a structured alternative to standard LoRA that inserts low-rank adapters selectively across the transformer hierarchy and couples them with layer-wise training objectives to encourage geometric correspondence in intermediate features and semantic consistency in deeper features. Experiments on public and proprietary datasets show improved geometric and semantic representation quality, leading to better performance on downstream navigation tasks including pose estimation and monocular depth estimation. The learned representations show favorable synthetic-to-real transfer on clinical bronchoscopy and provide a useful initialization for adaptation to sinus endoscopy and colonoscopy under limited supervision. The framework also shows favorable scaling with model size and training data. These results support hierarchy-aware, geometry-guided adaptation as a practical approach for endoscopic representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified framework for learning geometry-consistent and domain-robust representations for monocular endoscopy. It combines a synthetic data pipeline supplying geometric supervision with Hierarchy-Aware Geometry-Semantic Adaptation, a structured alternative to standard LoRA that inserts low-rank adapters selectively across the transformer hierarchy and couples them to layer-wise objectives targeting geometric correspondence in intermediate features and semantic consistency in deeper layers. Experiments on public and proprietary datasets are claimed to demonstrate improved geometric and semantic representation quality, better performance on pose estimation and monocular depth estimation, favorable synthetic-to-real transfer on clinical bronchoscopy, and utility as initialization for sinus endoscopy and colonoscopy under limited supervision, with favorable scaling in model size and data volume.
Significance. If the empirical claims hold with rigorous quantitative support, the work could offer a practical route for adapting large vision foundation models to endoscopic navigation, where domain shifts, weak texture, and non-rigid deformation are persistent obstacles. The hierarchy-aware, geometry-guided adaptation strategy and the emphasis on synthetic-to-real transfer under limited supervision address real clinical needs and may generalize beyond bronchoscopy.
major comments (2)
- [Abstract] Abstract: the abstract asserts that experiments show 'improved geometric and semantic representation quality' and 'better performance on downstream navigation tasks' yet supplies no quantitative metrics, error bars, ablation details, or statistical tests. Without these, the magnitude and reliability of the claimed gains cannot be assessed.
- [Abstract] Abstract (framework description): the central claim that the synthetic data pipeline supplies geometric supervision whose distribution is sufficiently close to real endoscopic images for the hierarchy-aware adapters to produce transferable features rests on an unverified distributional assumption; the manuscript must demonstrate this closeness (e.g., via feature-space distances or failure-case analysis) for the synthetic-to-real transfer results to be convincing.
minor comments (2)
- [Abstract] Abstract: the term 'Hierarchy-Aware Geometry-Semantic Adaptation' is introduced without a concise definition or pointer to the precise architectural modification relative to standard LoRA.
- [Abstract] Abstract: the statement that the framework 'shows favorable scaling with model size and training data' lacks any indication of the scaling regime or the metrics used to establish favorability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts that experiments show 'improved geometric and semantic representation quality' and 'better performance on downstream navigation tasks' yet supplies no quantitative metrics, error bars, ablation details, or statistical tests. Without these, the magnitude and reliability of the claimed gains cannot be assessed.
Authors: We agree that the abstract would benefit from including key quantitative indicators to substantiate the claims. In the revised manuscript we will incorporate concise references to the main results (e.g., relative reductions in pose estimation error and depth metrics on the reported datasets, together with pointers to the corresponding tables and ablation studies). This change will be made while respecting the abstract length constraint. revision: yes
-
Referee: [Abstract] Abstract (framework description): the central claim that the synthetic data pipeline supplies geometric supervision whose distribution is sufficiently close to real endoscopic images for the hierarchy-aware adapters to produce transferable features rests on an unverified distributional assumption; the manuscript must demonstrate this closeness (e.g., via feature-space distances or failure-case analysis) for the synthetic-to-real transfer results to be convincing.
Authors: The full paper already contains quantitative transfer results on clinical bronchoscopy data and qualitative feature visualizations supporting the utility of the synthetic supervision. To directly address the distributional-closeness concern we will add a targeted analysis (feature-space distance metrics or explicit failure-case discussion) in the revised manuscript, either in the experiments section or as supplementary material referenced from the abstract if space allows. revision: yes
Circularity Check
No significant circularity; empirical pipeline with external supervision
full rationale
The paper describes an empirical framework that combines a synthetic data pipeline (providing geometric supervision) with hierarchy-aware adapters inserted into a foundation model. Reported gains on pose estimation, depth estimation, and synthetic-to-real transfer are measured on public/proprietary datasets and clinical bronchoscopy sequences. No equations, uniqueness theorems, or load-bearing derivations are present in the provided text that reduce any claimed result to a fitted parameter or self-citation by construction. The central claims remain falsifiable via the external benchmarks and transfer experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
Pith/arXiv arXiv 2018
-
[2]
Dream to control: Learn- ing behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learn- ing behaviors by latent imagination,”arXiv preprint arXiv:1912.01603, 2019
Pith/arXiv arXiv 1912
-
[3]
Optical techniques for 3d surface reconstruction in computer-assisted laparo- scopic surgery,
L. Maier-Hein, P. Mountney, A. Bartoli, H. Elhawary, D. Elson, A. Groch, A. Kolb, M. Rodrigues, J. Sorger, S. Speidelet al., “Optical techniques for 3d surface reconstruction in computer-assisted laparo- scopic surgery,”Medical image analysis, vol. 17, no. 8, pp. 974–996, 2013
2013
-
[4]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[5]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[6]
Surgical- sam: Efficient class promptable surgical instrument segmentation,
W. Yue, J. Zhang, K. Hu, Y . Xia, J. Luo, and Z. Wang, “Surgical- sam: Efficient class promptable surgical instrument segmentation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 6890–6898
2024
-
[7]
Medical sam 2: Segment medical images as video via segment anything model 2,
J. Zhu, A. Hamdi, Y . Qi, Y . Jin, and J. Wu, “Medical sam 2: Segment medical images as video via segment anything model 2,”arXiv preprint arXiv:2408.00874, 2024
arXiv 2024
-
[8]
Endovit: pretraining vision transformers on a large collection of endoscopic images,
D. Bati ´c, F. Holm, E. ¨Ozsoy, T. Czempiel, and N. Navab, “Endovit: pretraining vision transformers on a large collection of endoscopic images,”International Journal of Computer Assisted Radiology and Surgery, vol. 19, no. 6, pp. 1085–1091, 2024
2024
-
[9]
Endodino: A foundation model for gi endoscopy,
P. Dermyer, A. Kalra, and M. Schwartz, “Endodino: A foundation model for gi endoscopy,”arXiv preprint arXiv:2501.05488, 2025
arXiv 2025
-
[10]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[11]
K. Phuntsho, Abdullah, K. Lee, I. Lee, and E. Ahn, “Adaptation of foundation models for medical image analysis: Strategies, challenges, and future directions,” 2025. [Online]. Available: https://arxiv.org/abs/ 2511.01284
arXiv 2025
-
[12]
Fastsam3d: An efficient segment anything model for 3d volumetric medical images,
Y . Shen, J. Li, X. Shao, B. Inigo Romillo, A. Jindal, D. Dreizin, and M. Unberath, “Fastsam3d: An efficient segment anything model for 3d volumetric medical images,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 542–552
2024
-
[13]
Gsam+ cutie: text- promptable tool mask annotation for endoscopic video,
R. D. Soberanis-Mukul, J. Cheng, J. E. Mangulabnan, S. S. Vedula, M. Ishii, G. Hager, R. H. Taylor, and M. Unberath, “Gsam+ cutie: text- promptable tool mask annotation for endoscopic video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 2388–2394
2024
-
[14]
Fluorosam: A language-promptable foundation model for flexible x-ray image segmentation,
B. D. Killeen, L. J. Wang, B. I ˜n´ıgo, H. Zhang, M. Armand, R. H. Taylor, G. Osgood, and M. Unberath, “Fluorosam: A language-promptable foundation model for flexible x-ray image segmentation,” inInterna- tional Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2025, pp. 248–258
2025
-
[15]
St-adapter: Parameter- efficient image-to-video transfer learning,
J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li, “St-adapter: Parameter- efficient image-to-video transfer learning,”Advances in Neural Infor- mation Processing Systems, vol. 35, pp. 26 462–26 477, 2022
2022
-
[16]
Foundation model for endoscopy video analysis via large-scale self-supervised pre-train,
Z. Wang, C. Liu, S. Zhang, and Q. Dou, “Foundation model for endoscopy video analysis via large-scale self-supervised pre-train,” in International conference on medical image computing and computer- assisted intervention. Springer, 2023, pp. 101–111
2023
-
[17]
Endomamba: an efficient foundation model for endoscopic videos via hierarchical pre-training,
Q. Tian, H. Liao, X. Huang, B. Yang, D. Lei, S. Ourselin, and H. Liu, “Endomamba: an efficient foundation model for endoscopic videos via hierarchical pre-training,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2025, pp. 224–234
2025
-
[18]
H. Li, D. Lu, J. d’Almeida, D. Isik, E. K. Aghdam, N. DiSanto, A. Acar, S. Sharma, J. Y . Wu, R. J. Webster IIIet al., “Monocular absolute depth estimation from endoscopy via domain-invariant feature learning and latent consistency,”arXiv preprint arXiv:2511.02247, 2025
arXiv 2025
-
[19]
Enhancing gastroenterology with multimodal learning: the role of large language model chatbots in digestive endoscopy,
Y . Qin, J. Chang, L. Li, and M. Wu, “Enhancing gastroenterology with multimodal learning: the role of large language model chatbots in digestive endoscopy,”Frontiers in Medicine, vol. 12, p. 1583514, 2025
2025
-
[20]
A fully differentiable framework for 2d/3d registration and the projective spatial transformers,
C. Gao, A. Feng, X. Liu, R. H. Taylor, M. Armand, and M. Unberath, “A fully differentiable framework for 2d/3d registration and the projective spatial transformers,”IEEE transactions on medical imaging, vol. 43, no. 1, pp. 275–285, 2023
2023
-
[21]
Synthetic data accelerates the development of gen- eralizable learning-based algorithms for x-ray image analysis,
C. Gao, B. D. Killeen, Y . Hu, R. B. Grupp, R. H. Taylor, M. Armand, and M. Unberath, “Synthetic data accelerates the development of gen- eralizable learning-based algorithms for x-ray image analysis,”Nature Machine Intelligence, vol. 5, no. 3, pp. 294–308, 2023
2023
-
[22]
Surgical-dino: adapter learning of foundation models for depth estimation in endoscopic surgery,
B. Cui, M. Islam, L. Bai, and H. Ren, “Surgical-dino: adapter learning of foundation models for depth estimation in endoscopic surgery,” International Journal of Computer Assisted Radiology and Surgery, vol. 19, no. 6, pp. 1013–1020, 2024
2024
-
[23]
What is the best 3d scene representation for robotics? from geometric to foundation models,
T. Deng, Y . Pan, S. Yuan, D. Li, C. Wang, M. Li, L. Chen, L. Xie, D. Wang, J. Wanget al., “What is the best 3d scene representation for robotics? from geometric to foundation models,”arXiv preprint arXiv:2512.03422, 2025
arXiv 2025
-
[24]
H. Shu, R. D. Soberanis-Mukul, J. Xu, H. Ding, M. Ringel, M. Shen, S. I. Sayed, H. Rafii-Tari, and M. Unberath, “Bronchopt: Vision- based pose optimization with fine-tuned foundation models for accurate bronchoscopy navigation,”arXiv preprint arXiv:2511.09443, 2025
arXiv 2025
-
[25]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[26]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[27]
Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
Pith/arXiv arXiv 2023
-
[28]
Contrastive learning for unpaired image-to-image translation,
T. Park, A. A. Efros, R. Zhang, and J.-Y . Zhu, “Contrastive learning for unpaired image-to-image translation,” inEuropean conference on computer vision. Springer, 2020, pp. 319–345
2020
-
[29]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[30]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[31]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232
2017
-
[32]
Leveraging near-field lighting for monocular depth estimation from endoscopy videos,
A. Paruchuri, S. Ehrenstein, S. Wang, I. Fried, S. M. Pizer, M. Nietham- mer, and R. Sengupta, “Leveraging near-field lighting for monocular depth estimation from endoscopy videos,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 473–491
2024
-
[33]
Colonoscopy 3d video dataset with paired depth from 2d-3d registration,
T. L. Bobrow, M. Golhar, R. Vijayan, V . S. Akshintala, J. R. Garcia, and N. J. Durr, “Colonoscopy 3d video dataset with paired depth from 2d-3d registration,”Medical image analysis, vol. 90, p. 102956, 2023
2023
-
[34]
Depth map prediction from a single image using a multi-scale deep network,
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[35]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
2021
-
[36]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Sys- tems, vol. 37, pp. 21 875–21 911, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.