From Prompt to Process: a Process Taxonomy and Comparative Assessment of Frameworks Supporting AI Software Development Agents
Pith reviewed 2026-06-28 05:14 UTC · model grok-4.3
The pith
AI software development frameworks shift from isolated prompts to structured processes using artifacts and reviews, but none covers all six key dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a six-dimension process taxonomy—specification, context, roles, execution, validation and portability—with a scoring rubric that turns it into a replicable instrument. We apply it to six frameworks: GitHub Spec Kit, OpenSpec, BMAD Method, Get Shit Done, Spec Kitty and Reversa, plus an out-of-sample case Spec-Flow. Among frameworks that adopt some process there is convergence: the isolated prompt loses centrality, and persistent artifacts, work contracts, traceability and human review become mechanisms that reduce ambiguity and coordinate agents. No framework strongly covers all six dimensions, exposing a structural trade-off between process depth and portability across agents.
What carries the argument
Six-dimension process taxonomy with scoring rubric: specification, context, roles, execution, validation and portability.
If this is right
- Isolated prompts lose centrality as persistent artifacts and human review coordinate agents.
- Work contracts and traceability become central mechanisms for reducing ambiguity.
- A structural trade-off exists between process depth and portability across agents.
- Recurring risks include drift between specification and code plus excessive trust in generated artifacts.
- Empirical evaluation should focus on intermediate-quality metrics, context governance, installation security and reproducibility.
Where Pith is reading between the lines
- The taxonomy could guide design of hybrid frameworks that modularize dimensions to ease the depth-portability trade-off.
- Platform dependence and fragility of community extensions suggest value in studying standardized interfaces between frameworks.
- Risks around generated artifacts point to potential value of automated drift-detection tools as a testable extension.
Load-bearing premise
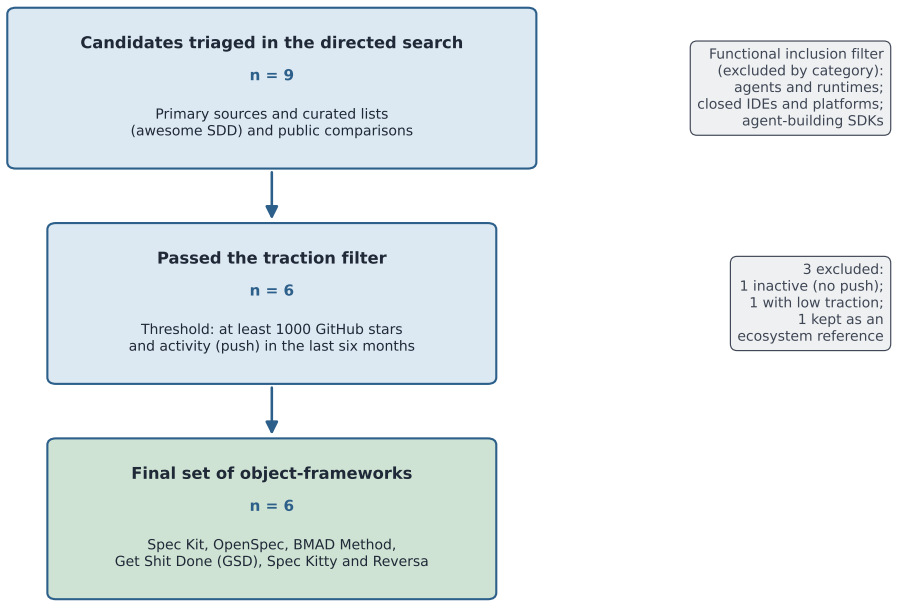
The directed search of primary sources using a functional inclusion criterion and traction measurement produced a representative sample of frameworks that accurately reflects the current landscape without significant omission or bias.
What would settle it
Identification of a widely adopted framework that scores strongly on all six dimensions while maintaining high portability across agents would challenge the claimed trade-off.
Figures
read the original abstract
AI tools for programming are no longer just autocomplete or chat assistants: they organize themselves as development frameworks, with process, roles, artifacts and verification. Recent surveys map agents and LLMs for software engineering, but a study centered on the operational frameworks that turn these capabilities into process is missing. We ran a directed search of primary sources, with a functional inclusion criterion and traction measurement, and selected six frameworks: GitHub Spec Kit, OpenSpec, BMAD Method, Get Shit Done (GSD), Spec Kitty and Reversa. Each attacks AI development through a different path: spec-driven development in full and lightweight variants, agent-driven agile planning, context engineering over the agent, worktree isolation and review, and recovery of operational specifications from legacy systems. Our central contribution is a six-dimension process taxonomy: specification, context, roles, execution, validation and portability, with a scoring rubric that turns it into a replicable instrument. We apply it to the six frameworks and an out-of-sample case, Spec-Flow. Two results stand out. Among frameworks that already adopt some process there is convergence: the isolated prompt loses centrality, and persistent artifacts, work contracts, traceability and human review become mechanisms that reduce ambiguity and coordinate agents. And no framework strongly covers all six dimensions, exposing a structural trade-off between process depth and portability across agents. We also found recurring risks: drift between specification and code, excessive trust in generated artifacts, fragility of community extensions, platform dependence and a lack of benchmarks for the complete process. We close with a research agenda for empirical evaluation, focused on intermediate-quality metrics, context governance, installation security and reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a six-dimension process taxonomy (specification, context, roles, execution, validation, portability) with an associated scoring rubric for evaluating AI software development frameworks. It applies this instrument via a directed search to six frameworks (GitHub Spec Kit, OpenSpec, BMAD Method, GSD, Spec Kitty, Reversa) plus an out-of-sample case (Spec-Flow), concluding that frameworks converge on persistent artifacts, work contracts, traceability and human review while exhibiting a structural trade-off between process depth and portability; it also catalogs recurring risks and outlines a research agenda.
Significance. If the taxonomy and rubric prove replicable and the sample representative, the work supplies a needed structured lens for comparing operational AI development processes rather than isolated agents or LLMs, with explicit credit for defining a scoring rubric that converts the taxonomy into a replicable instrument and for including an out-of-sample validation case.
major comments (3)
- [Abstract (methods paragraph)] Abstract (methods paragraph): the directed search is characterized only as using 'a functional inclusion criterion and traction measurement' with no search strings, databases, candidate pool size, or explicit exclusion rules supplied. This under-specification is load-bearing for the representativeness claim that underpins both the convergence observation and the 'no framework strongly covers all six dimensions' conclusion.
- [Results] Results (application of taxonomy): the manuscript supplies no raw per-framework dimension scores, inter-rater reliability statistics, or explicit validation steps for the scoring rubric. Without these, the mapping from rubric to the reported convergence and depth-portability trade-off cannot be independently verified.
- [Framework selection and scoring] § on framework selection and scoring: the choice of the six primary frameworks plus Spec-Flow is presented without evidence that the functional inclusion criterion systematically avoids favoring specification-heavy approaches or omitting frameworks that might achieve broader dimension coverage, directly affecting the generality of the structural trade-off claim.
minor comments (2)
- [Taxonomy definition] The six dimensions are introduced at a high level; explicit operational definitions or example scoring anchors for each would improve replicability of the instrument.
- [Risks and research agenda] Risks section lists platform dependence and lack of benchmarks but does not connect them quantitatively back to the dimension scores.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each of the major comments point by point below, indicating the revisions we will make to improve the manuscript's transparency and replicability.
read point-by-point responses
-
Referee: [Abstract (methods paragraph)] Abstract (methods paragraph): the directed search is characterized only as using 'a functional inclusion criterion and traction measurement' with no search strings, databases, candidate pool size, or explicit exclusion rules supplied. This under-specification is load-bearing for the representativeness claim that underpins both the convergence observation and the 'no framework strongly covers all six dimensions' conclusion.
Authors: We agree that the abstract's description of the search method is concise and could benefit from additional detail to support replicability. In the revised manuscript, we will expand the Methods section to explicitly list the search strings employed (e.g., terms related to 'AI software development frameworks', 'spec-driven AI agents'), the primary sources and databases consulted (GitHub repositories, arXiv preprints, developer forums), the size of the initial candidate pool, and the full set of exclusion rules applied. This will provide a clearer basis for the representativeness of the selected frameworks. revision: yes
-
Referee: [Results] Results (application of taxonomy): the manuscript supplies no raw per-framework dimension scores, inter-rater reliability statistics, or explicit validation steps for the scoring rubric. Without these, the mapping from rubric to the reported convergence and depth-portability trade-off cannot be independently verified.
Authors: This is a valid observation regarding transparency. We will add a supplementary table presenting the raw scores for each framework across the six dimensions. Since the scoring was conducted by the author team using the defined rubric, we will explicitly state that it was a single-rater process and discuss this as a limitation, while noting plans for future multi-rater studies. Additionally, we will elaborate on the validation steps, including how the out-of-sample Spec-Flow case was used to test the taxonomy's applicability. revision: partial
-
Referee: [Framework selection and scoring] § on framework selection and scoring: the choice of the six primary frameworks plus Spec-Flow is presented without evidence that the functional inclusion criterion systematically avoids favoring specification-heavy approaches or omitting frameworks that might achieve broader dimension coverage, directly affecting the generality of the structural trade-off claim.
Authors: We selected frameworks based on their explicit definition of end-to-end processes for AI-assisted software development and measurable traction indicators such as community adoption and documentation quality. The sample includes a range of approaches beyond pure specification (e.g., GSD's agent-driven agile planning and Spec Kitty's context engineering). To strengthen this, we will revise the relevant section to provide more detailed justification of the inclusion criteria, list examples of excluded frameworks with reasons, and discuss potential selection biases. The inclusion of the out-of-sample Spec-Flow case already serves to partially address generalizability concerns. revision: yes
Circularity Check
No circularity: qualitative taxonomy and scoring are self-contained
full rationale
The paper introduces a novel six-dimension taxonomy (specification, context, roles, execution, validation, portability) with an explicit scoring rubric, then applies it to six frameworks selected by directed search plus one out-of-sample case. No equations, fitted parameters, or derivations exist. The convergence claim and depth-vs-portability trade-off are direct empirical observations from the rubric scores, not reductions to prior self-referential quantities or self-citations. The methods description of the search is high-level but does not create definitional or load-bearing circularity in the assessment results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dimensions specification, context, roles, execution, validation and portability comprehensively and usefully describe AI software development processes.
Reference graph
Works this paper leans on
-
[1]
6 Best Spec-Driven Development Tools for AI Coding in 2026.https: //www.augmentcode.com/tools/best-spec-driven-development-tools, 2026
Augment Code. 6 Best Spec-Driven Development Tools for AI Coding in 2026.https: //www.augmentcode.com/tools/best-spec-driven-development-tools, 2026. Accessed 2026-05-26
2026
-
[2]
Spec-Driven Development (SDD): The Definitive 2026 Guide.https://thebcms
BCMS. Spec-Driven Development (SDD): The Definitive 2026 Guide.https://thebcms. com/blog/spec-driven-development, 2026. Accessed 2026-05-26
2026
-
[3]
Happy Bhati. Agentic AI in the Software Development Lifecycle: Architecture, Empirical Evidence, and the Reshaping of Software Engineering, 2026. doi: 10.48550/arXiv.2604.26275
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.26275 2026
-
[4]
BMAD Method Documentation
BMad Code. BMAD Method Documentation. https://docs.bmad-method.org/, 2026. Accessed 2026-05-26
2026
-
[5]
BMAD-METHOD: Breakthrough Method for Agile AI Driven Development
BMad Code Org. BMAD-METHOD: Breakthrough Method for Agile AI Driven Development. https://github.com/bmad-code-org/BMAD-METHOD, 2026. Accessed 2026-05-26
2026
-
[6]
Elliot J. Chikofsky and James H. Cross. Reverse Engineering and Design Recovery: A Taxonomy.IEEE Software, 7(1):13–17, 1990. doi: 10.1109/52.43044
-
[7]
Spec-Driven Development Framework Patterns
David Daniel. Spec-Driven Development Framework Patterns. https://daviddaniel. tech/research/papers/sdd-frameworks/, 2026. Accessed 2026-05-26. 15
2026
-
[8]
Fission-AI/OpenSpec: A Lightweight Specification Framework for Human-AI Alignment Before Coding
Fission AI. Fission-AI/OpenSpec: A Lightweight Specification Framework for Human-AI Alignment Before Coding. https://github.com/Fission-AI/OpenSpec, 2026. Accessed 2026-05-28
2026
-
[9]
Vahid Garousi, Michael Felderer, and Mika V. Mäntylä. Guidelines for including grey literature and conducting multivocal literature reviews in software engineering.Information and Software Technology, 106:101–121, 2019
2019
-
[10]
github/spec-kit: Toolkit to Help You Get Started with Spec-Driven Development
GitHub. github/spec-kit: Toolkit to Help You Get Started with Spec-Driven Development. https://github.com/github/spec-kit, 2026. Accessed 2026-05-26
2026
-
[11]
Spec Kit: A Specification-Driven Development Toolkit.https://github.github
GitHub. Spec Kit: A Specification-Driven Development Toolkit.https://github.github. io/spec-kit/, 2026. Accessed 2026-05-26
2026
-
[12]
Get Shit Done (GSD): A Lightweight Meta-Prompting, Context Engineering and Spec-Driven Development System for Claude Code.https://github.com/gsd-build/ get-shit-done, 2026
GSD Build. Get Shit Done (GSD): A Lightweight Meta-Prompting, Context Engineering and Spec-Driven Development System for Claude Code.https://github.com/gsd-build/ get-shit-done, 2026. Accessed 2026-05-28. Project relocated tohttps://github.com/ open-gsd/gsd-core
2026
-
[13]
ACM Transactions on Software Engineering and Methodology , volume=
Junda He, Christoph Treude, and David Lo. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–35, 2025. doi: 10.1145/3712003
-
[14]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology, 33(8):1–79, 2024. doi: 10.1145/3695988
-
[15]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, 2024. doi: 10.48550/arXiv.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2024
-
[16]
Haolin Jin et al. From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future, 2024. doi: 10.48550/arXiv.2408.02479
-
[17]
Pearl Brereton, David Budgen, Mark Turner, John Bailey, and Stephen Linkman
Barbara Kitchenham, O. Pearl Brereton, David Budgen, Mark Turner, John Bailey, and Stephen Linkman. Systematic literature reviews in software engineering: A systematic literature review.Information and Software Technology, 51(1):7–15, 2009
2009
-
[18]
Large Language Model-Based Agents for Software Engineering: A Survey,
Junwei Liu et al. Large Language Model-Based Agents for Software Engineering: A Survey,
-
[19]
doi: 10.48550/arXiv.2409.02977
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.02977
-
[20]
Sanderson Oliveira de Macedo and Ronaldo Martins da Costa. Reversa: A Reverse Documen- tationEngineeringFrameworkforConvertingLegacySoftwareintoOperationalSpecifications for AI Agents, 2026. doi: 10.48550/arXiv.2605.18684
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.18684 2026
-
[21]
Spec-Flow: Spec-Driven Development workflow for Claude Code
marcusgoll. Spec-Flow: Spec-Driven Development workflow for Claude Code. https: //github.com/marcusgoll/Spec-Flow, 2026. Accessed 2026-05-29
2026
-
[22]
OpenSpec: A Lightweight Spec-Driven Framework.https://openspec.dev/,
OpenSpec. OpenSpec: A Lightweight Spec-Driven Framework.https://openspec.dev/,
-
[23]
OpenSpec vs Spec Kit vs BMAD vs Kiro: Complete Comparison Guide
OpenSpec. OpenSpec vs Spec Kit vs BMAD vs Kiro: Complete Comparison Guide. https://openspec.pro/comparison/, 2026. Accessed 2026-05-26
2026
-
[24]
Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants, 2026
Deepak Babu Piskala. Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants, 2026. doi: 10.48550/arXiv.2602.00180. 16
-
[25]
Spec Kitty: Spec-Driven Development for AI Coding Agents.https://github
Priivacy AI. Spec Kitty: Spec-Driven Development for AI Coding Agents.https://github. com/Priivacy-ai/spec-kitty, 2026. Accessed 2026-05-28
2026
-
[26]
ChatDev: Communicative Agents for Software Development
Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative Agents for Software Development, 2024. doi: 10.48550/arXiv.2307.07924
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.07924 2024
-
[27]
Satadru Sengupta, Tamunokorite Briggs, and Ivan Myshakivskyi. Meta-Engineering Har- nesses for AI-Native Software Production: A Contract-Driven Adversarial Verification Architecture with Early Deployment Report, 2026. doi: 10.48550/arXiv.2605.25665
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.25665 2026
-
[28]
Spec Kit Agents: Context-Grounded Agentic Workflows
Pardis Taghavi and Santosh Bhavani. Spec Kit Agents: Context-Grounded Agentic Work- flows, 2026. doi: 10.48550/arXiv.2604.05278
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05278 2026
-
[29]
Fangchao Tian, Tianlu Wang, Peng Liang, Chong Wang, Arif Ali Khan, and Muhammad Ali Babar. The Impact of Traceability on Software Maintenance and Evolution: A Mapping Study.Journal of Software: Evolution and Process, 33(10), 2021. doi: 10.1002/smr.2374
-
[30]
Agents in Software Engineering: Survey, Landscape, and Vision, 2024
Yanlin Wang et al. Agents in Software Engineering: Survey, Landscape, and Vision, 2024. doi: 10.48550/arXiv.2409.09030
-
[31]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, 2024. doi: 10.48550/arXiv.2405.15793. 17
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.15793 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.