Fairness-Aware and Latency-Controllable Scheduling for Chunked-Prefill LLM Serving
Pith reviewed 2026-06-27 15:07 UTC · model grok-4.3
The pith
Aging-based scheduling with latency prediction cuts mean LLM serving latency over 10% versus FCFS
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
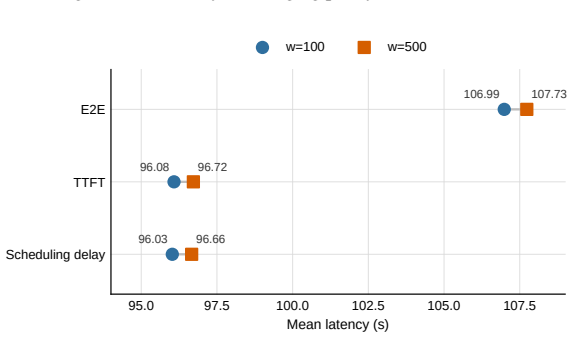
The authors establish that a lightweight aging-based scheduling policy, together with Latency-Prediction-Based Request Scheduling (LPRS) and Active Prefill Control (APC), replaces FCFS and static budgets to enforce fairness and target-time constraints, producing over 10% lower mean end-to-end latency, reduced P99 tail latency, and suppressed prefill fragmentation on NVIDIA GPUs and Ascend accelerators with real-world workloads.
What carries the argument
Aging-based scheduling policy that dynamically sets priorities from accumulated waiting time and remaining prefill work, augmented by LPRS for target-time constraints and APC for active regulation of prefill concurrency.
If this is right
- The aging policy reduces mean end-to-end latency by over 10% compared to FCFS.
- LPRS and APC together reduce P99 tail latency.
- The policies suppress prefill fragmentation.
- Structural prefill control and temporal latency constraints are complementary.
Where Pith is reading between the lines
- The aging priority formula could be adapted to non-chunked serving engines if waiting-time and work estimates remain available.
- Releasing the code allows independent checks on whether the latency gains persist under different hardware or traffic mixes.
- The approach highlights a general tension between prefill chunking efficiency and request fairness that other schedulers may need to address.
Load-bearing premise
That the tested real-world workloads on NVIDIA GPUs and Ascend accelerators represent typical production heterogeneous LLM serving traffic and that gains come from the policies rather than other factors.
What would settle it
Running the same policies on a fresh workload set with markedly different request sizes or arrival patterns and finding no reduction in mean or P99 latency would falsify the central performance claim.
Figures

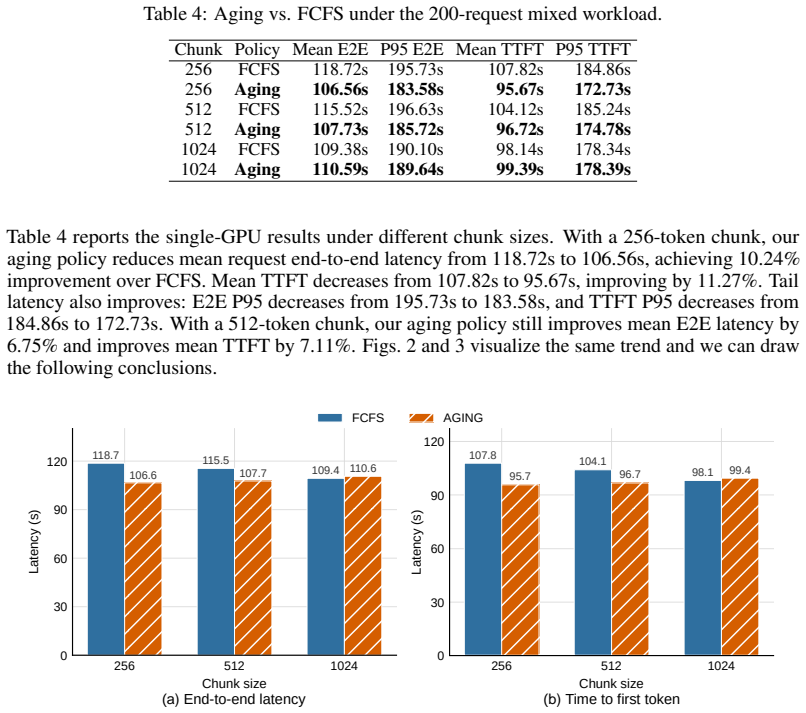
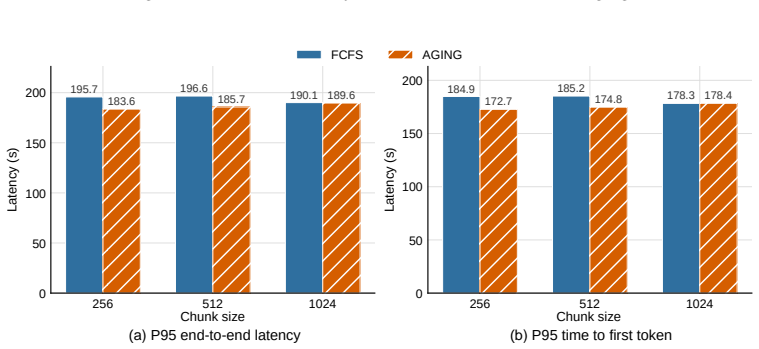
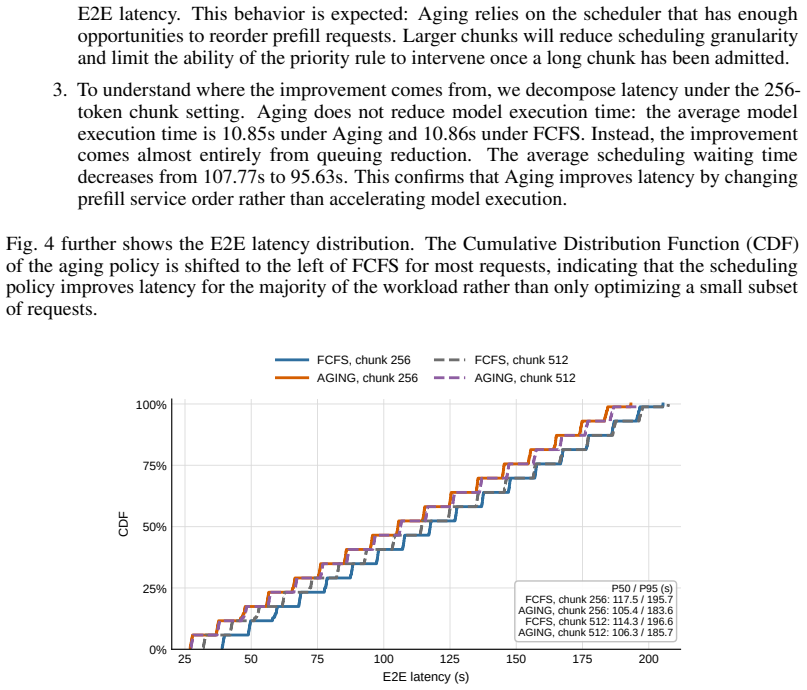
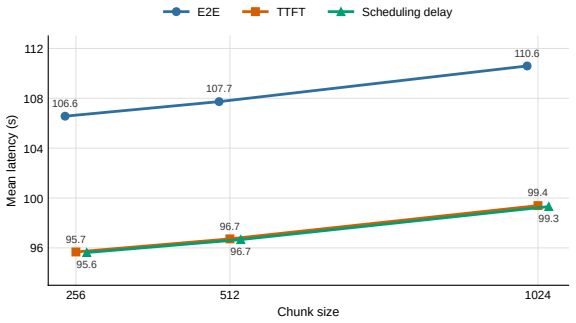
read the original abstract
As large language models (LLMs) are increasingly deployed with highly heterogeneous workloads, chunked-prefill execution has emerged as a mainstream serving architecture. Balancing scheduling fairness and latency stability in such environments is critical; otherwise, severe head-of-line blocking and request starvation will degrade user experience. However, existing systems rely on rigid First-Come, First-Served (FCFS) policies and static token budgets, leading to fairness degradation and unpredictable latency jitter. To address these issues, we propose a fairness-aware and latency-controllable scheduling framework for chunked-prefill LLM engines. Specifically, we design a lightweight aging-based scheduling policy that dynamically calculates priorities using accumulated waiting time and remaining prefill work. Furthermore, we develop Latency-Prediction-Based Request Scheduling (LPRS) and Active Prefill Control (APC) to replace static budgets with target-time constraints and actively regulate prefill concurrency. We evaluated our scheduling framework on NVIDIA GPUs and Ascend accelerators using real-world workloads. Results show the aging policy reduces mean end-to-end latency by over 10\% compared to FCFS. Moreover, LPRS and APC significantly reduce P99 tail latency and suppress prefill fragmentation, confirming that the structural prefill control and the temporal latency constraints are fundamentally complementary. All codes have been released in Github.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fairness-aware and latency-controllable scheduling framework for chunked-prefill LLM serving. It introduces a lightweight aging-based policy that computes priorities from waiting time and remaining prefill work, plus Latency-Prediction-Based Request Scheduling (LPRS) that replaces static token budgets with target-time constraints and Active Prefill Control (APC) that regulates prefill concurrency. Evaluation on NVIDIA GPUs and Ascend accelerators with real-world workloads reports that the aging policy reduces mean end-to-end latency by over 10% versus FCFS, while LPRS+APC reduce P99 tail latency and suppress prefill fragmentation; the authors conclude the structural and temporal mechanisms are complementary. All code is released.
Significance. If the performance deltas are shown to be robust and causally attributable to the proposed policies, the work would provide a practical contribution to production LLM serving by improving fairness and tail latency under heterogeneous chunked-prefill workloads. The open-source release supports reproducibility.
major comments (3)
- [§5 (Evaluation)] §5 (Evaluation): The reported >10% mean E2E latency reduction and P99 improvements lack any description of the number of runs, statistical tests, error bars, or variance across trials, so the quantitative claims cannot be assessed for reliability.
- [§5 (Evaluation)] §5 (Evaluation): No ablation experiments are presented that hold all other factors fixed while toggling only the aging priority, LPRS target-time logic, or APC concurrency control; therefore the conclusion that the mechanisms are 'fundamentally complementary' rests on an unisolated comparison against an unspecified FCFS baseline.
- [§5 (Evaluation)] §5 (Evaluation): The workloads are described only as 'real-world' with no characterization of arrival burstiness, prefill-length distribution, or multi-model heterogeneity, leaving open whether the observed gains generalize or are artifacts of the particular traces and accelerator implementations.
minor comments (2)
- The abstract and §5 should explicitly state the exact FCFS baseline configuration (e.g., token budget, preemption rules) used for comparison.
- Notation for priority calculation in the aging policy (waiting time + remaining prefill work) should be formalized with an equation in §3 or §4.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation section. We address each major comment below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [§5 (Evaluation)] The reported >10% mean E2E latency reduction and P99 improvements lack any description of the number of runs, statistical tests, error bars, or variance across trials, so the quantitative claims cannot be assessed for reliability.
Authors: We agree that details on experimental repeatability and variance are necessary for assessing reliability. The experiments underlying the reported figures were repeated across multiple independent trials, but the manuscript omitted the exact count, error bars, and any statistical tests. In the revised version we will explicitly state the number of runs, include error bars (standard deviation), and report the results of basic statistical comparisons where appropriate. revision: yes
-
Referee: [§5 (Evaluation)] No ablation experiments are presented that hold all other factors fixed while toggling only the aging priority, LPRS target-time logic, or APC concurrency control; therefore the conclusion that the mechanisms are 'fundamentally complementary' rests on an unisolated comparison against an unspecified FCFS baseline.
Authors: We acknowledge that the current evaluation does not isolate the contribution of each mechanism through controlled ablations. The complementarity claim was drawn from the joint improvements observed when all components are enabled versus the FCFS baseline. To address the concern we will add a dedicated ablation study in the revision that toggles the aging policy, LPRS, and APC individually while holding all other factors constant. revision: yes
-
Referee: [§5 (Evaluation)] The workloads are described only as 'real-world' with no characterization of arrival burstiness, prefill-length distribution, or multi-model heterogeneity, leaving open whether the observed gains generalize or are artifacts of the particular traces and accelerator implementations.
Authors: The workloads are drawn from production traces, yet the manuscript provides only a high-level description. We agree that quantitative characterization of arrival patterns, prefill-length distributions, and heterogeneity would improve interpretability. In the revision we will insert a workload characterization subsection that reports the relevant statistics (e.g., inter-arrival time distributions, prefill token histograms, and model mix). revision: yes
Circularity Check
No circularity; purely empirical claims with no derivation chain
full rationale
The paper describes a scheduling framework with aging policy, LPRS, and APC, then reports measured latency reductions from evaluations on NVIDIA GPUs and Ascend accelerators using real-world workloads. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. All headline results (e.g., >10% mean latency reduction, P99 improvements) are presented as direct experimental outcomes rather than reductions to prior definitions or fits. This is a standard systems paper whose central claims rest on external benchmarks, not internal self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x,
Q. Zheng, X. Xia, X. Zou, Y . Dong, S. Wang, Y . Xue, L. Shen, Z. Wang, A. Wang, Y . Li et al., “Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 5673–5684
2023
-
[2]
Evaluating verifiability in generative search engines,
N. Liu, T. Zhang, and P. Liang, “Evaluating verifiability in generative search engines,” in Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 2023, pp. 7001–7025
2023
-
[3]
Retrieval-augmented generation for knowledge- intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge- intensive nlp tasks,” inAnnual Conference on Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[4]
Deepdiver: Adaptive search intensity scaling via open-web reinforcement learning,
W. Shi, H. Tan, C. Kuang, X. Li, X. Ren, C. Zhang, H. Chen, Y . Wang, L. Hou, and L. Shang, “Deepdiver: Adaptive search intensity scaling via open-web reinforcement learning,”arXiv preprint arXiv:2505.24332, 2025
arXiv 2025
-
[5]
Taming throughput-latency tradeoff in llm inference with sarathi-serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. Gulavani, A. Tumanov, and R. Ramjee, “Taming throughput-latency tradeoff in llm inference with sarathi-serve,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 117–134
2024
-
[6]
Llumnix: Dynamic scheduling for large language model serving,
B. Sun, Z. Huang, H. Zhao, W. Xiao, X. Zhang, Y . Li, and W. Lin, “Llumnix: Dynamic scheduling for large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024, pp. 173–191
2024
-
[7]
Fairness in serving large language models,
Y . Sheng, S. Cao, D. Li, B. Zhu, Z. Li, D. Zhuo, J. E. Gonzalez, and I. Stoica, “Fairness in serving large language models,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024, pp. 965–988
2024
-
[8]
Orca: A distributed serving system for Transformer-Based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S.-J. Kim, and B.-G. Chun, “Orca: A distributed serving system for Transformer-Based generative models,” inProceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2022, pp. 521–538
2022
-
[9]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023, pp. 611–626
2023
-
[10]
DistServe: Disaggregat- ing prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregat- ing prefill and decoding for goodput-optimized large language model serving,” inProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024, pp. 193–210
2024
-
[11]
Mooncake: A kvcache-centric disaggregated architecture for llm serving,
R. Qin, Z. Li, W. He, J. Cui, H. Tang, F. Ren, T. Ma, S. Cai, Y . Zhang, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: A kvcache-centric disaggregated architecture for llm serving,” ACM Transactions on Storage, pp. 1–38, 2025
2025
-
[12]
Shad- owkv: Kv cache in shadows for high-throughput long-context llm inference,
H. Sun, L.-W. Chang, W. Bao, S. Zheng, N. Zheng, X. Liu, H. Dong, Y . Chi, and B. Chen, “Shad- owkv: Kv cache in shadows for high-throughput long-context llm inference,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025, pp. 1–19. 18
2025
-
[13]
(2025) vllm-ascend: Huawei ascend npu backend for vllm
vLLM Ascend Project. (2025) vllm-ascend: Huawei ascend npu backend for vllm. [Online]. Available: https://github.com/vllm-project/vllm-ascend
2025
-
[14]
MindIE-LLM: Ascend large language model inference engine,
Ascend, “MindIE-LLM: Ascend large language model inference engine,” https://github.com/ Ascend/MindIE-LLM, 2026, accessed: 2026-05-09
2026
-
[15]
Serving large language models on huawei cloudmatrix384,
P. Zuo, H. Lin, J. Deng, N. Zou, X. Yang, Y . Diao, W. Gao, K. Xu, Z. Chen, S. Luet al., “Serving large language models on huawei cloudmatrix384,”arXiv preprint arXiv:2506.12708, 2025
arXiv 2025
-
[16]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,”Nature, vol. 645, pp. 633–638, 2025
2025
-
[17]
Vidur: A large-scale simulation framework for llm inference,
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. S. Gulavani, R. Ramjee, and A. Tumanov, “Vidur: A large-scale simulation framework for llm inference,”Proceedings of Machine Learning and Systems, vol. 6, pp. 351–366, 2024
2024
-
[18]
A survey on inference optimization techniques for mixture of experts models,
J. Liu, P. Tang, W. Wang, Y . Ren, X. Hou, P. A. Heng, M. Guo, and C. Li, “A survey on inference optimization techniques for mixture of experts models,”ACM Computing Surveys, vol. 58, no. 10, pp. 1–37, 2026
2026
-
[19]
Application of distributed technology in large model training and inference,
W. Zheng, “Application of distributed technology in large model training and inference,”Big Data, vol. 10, no. 5, pp. 1–10, 2024
2024
-
[20]
Loongserve: Efficiently serving long- context large language models with elastic sequence parallelism,
B. Wu, S. Liu, Y . Zhong, P. Sun, X. Liu, and X. Jin, “Loongserve: Efficiently serving long- context large language models with elastic sequence parallelism,” inProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, 2024, pp. 640–654
2024
-
[21]
Splitwise: Efficient generative llm inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, Í. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 118–132
2024
-
[22]
Distributional reinforcement learning with quantile regression,
W. Dabney, M. Rowland, M. Bellemare, and R. Munos, “Distributional reinforcement learning with quantile regression,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018, pp. 2892–2901
2018
-
[23]
Pangu embedded: An efficient dual-system llm reasoner with metacognition,
H. Chen, Y . Wang, K. Han, D. Li, L. Li, Z. Bi, J. Li, H. Wang, F. Mi, M. Zhuet al., “Pangu embedded: An efficient dual-system llm reasoner with metacognition,”arXiv preprint arXiv:2505.22375, 2025
arXiv 2025
-
[24]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in7th International Conference on Learning Representations (ICLR), 2019, pp. 1–18. 19
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.