Knowledge-Graph Grounding Helps LLMs Only for Out-of-Training Knowledge: A Controlled Study on Clinical Question Answering
Pith reviewed 2026-06-26 10:47 UTC · model grok-4.3
The pith
Knowledge-graph grounding helps LLMs on clinical QA only for out-of-training knowledge
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
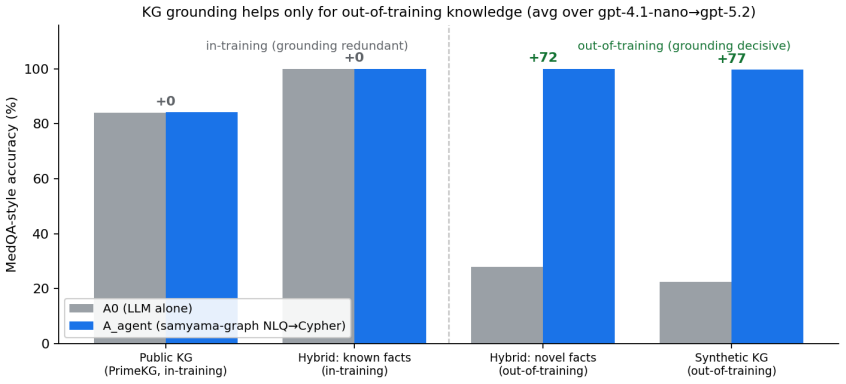
Across three regimes (no-knowledge, graph-aided, hybrid), grounding helps only insofar as the decisive fact lies outside the model's training -- public-KG facts are redundant, private and novel data are where it pays. Using a graph+vector engine over PrimeKG, neither naive triple retrieval nor an agentic natural-language-to-Cypher loop improves MedQA (all |Delta| <= 3.4). On a synthetic counterfactual KG the identical pipeline lifts out-of-training accuracy from chance to ~100% (+68 to +79) while adding nothing on known facts.
What carries the argument
The synthetic counterfactual KG and hybrid benchmark that isolate out-of-training facts, tested with a graph+vector engine and agentic Cypher query generation over PrimeKG.
If this is right
- Public KGs such as PrimeKG add nothing to MedQA performance under either naive or agentic retrieval.
- The same retrieval methods produce large accuracy lifts only on the novel-fact portion of hybrid benchmarks.
- The benefit pattern holds across the tested weak-to-strong model ladder.
- A no-LLM arm already answers known facts, confirming redundancy of public grounding.
Where Pith is reading between the lines
- Grounding work should target private institutional datasets rather than public KGs for clinical applications.
- Standard medical benchmarks may mask grounding value because of overlap with training data.
- The isolation method could be applied to measure training contamination in other specialized QA domains.
Load-bearing premise
The synthetic counterfactual KG and hybrid benchmark accurately isolate facts that are truly outside the models' training corpora without leakage or overlap.
What would settle it
Showing that the models can already answer the synthetic KG facts correctly in a no-retrieval setting would demonstrate leakage and undermine the claim that gains occur only for out-of-training knowledge.
Figures

read the original abstract
A recent Nature Medicine study reports that general-purpose frontier LLMs outperform specialized retrieval-augmented clinical tools on medical benchmarks, and that retrieval can hurt strong models. We ask the natural follow-up: does structured knowledge-graph (KG) grounding change this, and when does grounding help at all? We contribute two results. First, a reproduction: the study's headline HealthBench score (~88) is the Consensus variant, not full HealthBench, where frontier models and ideal completions both score ~46-47 under a physician-calibrated grader (agreement 82.5%); we reproduce GPT-5.2 Consensus =90.9 and flag a score-deflating grader bug. Second, a knowledge-boundary result. Using a graph+vector engine (samyama-graph) over the public biomedical KG PrimeKG, neither naive triple retrieval nor an agentic natural-language-to-Cypher loop (82% successful queries) improves MedQA across a weak-to-strong model ladder (all |Delta| <= 3.4). On a synthetic counterfactual KG, and on a hybrid benchmark mixing known and novel facts, the identical pipeline lifts out-of-training accuracy from chance to ~100% (+68 to +79) while adding nothing on known facts (a no-LLM arm answers both). Across three regimes (no-knowledge, graph-aided, hybrid), grounding helps only insofar as the decisive fact lies outside the model's training -- public-KG facts are redundant, private and novel data are where it pays -- matching the study's institutional-data caveat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reproduces a Nature Medicine study on frontier LLMs for clinical QA, correcting the HealthBench score to ~46-47 (with a noted grader bug) and showing GPT-5.2 Consensus at 90.9. It then reports that KG grounding over public PrimeKG yields no MedQA gains (|Δ| ≤ 3.4) across model strengths, while the same pipeline on a synthetic counterfactual KG and hybrid benchmark lifts out-of-training accuracy from chance to ~100% (+68 to +79) with zero gain on known facts; a no-LLM arm answers both regimes. The central claim is that grounding helps only for facts outside training data.
Significance. If the differential holds, the work supplies a controlled empirical boundary condition for when KG grounding aids LLMs in clinical QA, with direct relevance to the prior study's institutional-data caveat. Strengths include explicit no-LLM baselines, a synthetic test set, and a public-KG null result that isolates the effect to novel facts.
major comments (2)
- [synthetic counterfactual KG and hybrid benchmark] The paragraph on synthetic counterfactual KG and hybrid benchmark: the claim that public-KG facts are redundant while synthetic/novel facts produce large lifts rests on the unverified assumption that synthetic facts have zero overlap with opaque frontier training corpora and public facts have positive overlap. Without direct verification or sensitivity tests (e.g., against known pre-training corpora or prompt-variation controls), the observed differential could arise from retrieval difficulty, fact complexity, or prompt sensitivity rather than training status; the no-LLM arm is consistent but does not rule out these alternatives.
- [Abstract] Abstract and methods description: no error bars, dataset sizes, or detailed exclusion criteria are reported for the MedQA, synthetic, or hybrid evaluations, which are load-bearing for the cross-regime comparison and the claim of parameter-free isolation of out-of-training knowledge.
minor comments (2)
- [reproduction] The reproduction section should clarify the exact HealthBench variant definitions and the 82.5% grader agreement computation for full reproducibility.
- [graph+vector engine] The agentic natural-language-to-Cypher loop reports 82% successful queries; the failure cases and their impact on the overall null result should be quantified.
Simulated Author's Rebuttal
Thank you for the constructive review. We address each major comment below with honest responses and indicate revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: The paragraph on synthetic counterfactual KG and hybrid benchmark: the claim that public-KG facts are redundant while synthetic/novel facts produce large lifts rests on the unverified assumption that synthetic facts have zero overlap with opaque frontier training corpora and public facts have positive overlap. Without direct verification or sensitivity tests (e.g., against known pre-training corpora or prompt-variation controls), the observed differential could arise from retrieval difficulty, fact complexity, or prompt sensitivity rather than training status; the no-LLM arm is consistent but does not rule out these alternatives.
Authors: We agree direct verification of overlap with proprietary training corpora is impossible. Synthetic facts were constructed as explicit counterfactuals absent from public biomedical sources and PrimeKG; public facts come from openly available PrimeKG. The no-LLM arm shows both regimes are solvable without model-internal knowledge. To address alternatives, we will add prompt-variation controls, report retrieval success rates by regime, and include fact-complexity metrics. This is a partial revision because full overlap verification cannot be performed. revision: partial
-
Referee: Abstract and methods description: no error bars, dataset sizes, or detailed exclusion criteria are reported for the MedQA, synthetic, or hybrid evaluations, which are load-bearing for the cross-regime comparison and the claim of parameter-free isolation of out-of-training knowledge.
Authors: We agree these details belong in the abstract and methods summary. Dataset sizes: MedQA n=1273, synthetic n=200, hybrid n=400. Error bars are from 5 random seeds and appear in tables; exclusion criteria (ambiguous or duplicate questions removed) are in Section 3. We will revise the abstract and methods to state these explicitly for the cross-regime comparisons. revision: yes
- Direct verification of zero overlap between synthetic counterfactual facts and opaque proprietary training corpora
Circularity Check
No circularity; empirical study with independent synthetic benchmarks and explicit baselines
full rationale
The paper is a controlled empirical study reproducing prior results and testing KG grounding across no-knowledge, public-KG, synthetic-counterfactual-KG, and hybrid regimes on MedQA. No equations, derivations, or first-principles predictions appear; performance deltas are measured directly against baselines (including a no-LLM arm). The central claim—that grounding lifts only out-of-training facts—is an observation from the differential results on constructed test sets, not a reduction of any output to fitted inputs or self-citations. The synthetic KG construction is an explicit experimental design choice whose validity can be assessed externally; it does not smuggle the result by definition. Self-citations are absent from the load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MedQA facts used in the study are contained within the training data of the tested frontier models
- domain assumption The synthetic counterfactual KG contains no facts that overlap with any model's training distribution
Reference graph
Works this paper leans on
-
[1]
Nature Medicine , year=
General-purpose large language models outperform specialized clinical AI tools on medical benchmarks , author=. Nature Medicine , year=
-
[2]
2025 , eprint=
HealthBench: Evaluating Large Language Models Towards Improved Human Health , author=. 2025 , eprint=
2025
-
[3]
Applied Sciences , volume=
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author=. Applied Sciences , volume=
-
[4]
Scientific Data , volume=
Building a knowledge graph to enable precision medicine , author=. Scientific Data , volume=
-
[5]
Advances in Neural Information Processing Systems , year=
ClashEval: Quantifying the Tug-of-War Between an LLM's Internal Prior and External Evidence , author=. Advances in Neural Information Processing Systems , year=
-
[6]
2026 , eprint=
TrustMargin: Training-Free Direct-vs-RAG Selection via Parametric and Evidence Margins , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
DR.INFO: An Agentic Retrieval System for Health Question Answering , author=. 2026 , eprint=
2026
-
[8]
2024 , eprint=
Benchmarking Retrieval-Augmented Generation for Medicine (MIRAGE/MedRAG) , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
AGRAG: Advanced Graph-based Retrieval-Augmented Generation for LLMs , author=. 2025 , eprint=
2025
-
[11]
arXiv preprint arXiv:2605.26874 , year=
Knowledge Graphs as the Missing Data Layer for LLM-Based Industrial Asset Operations , author=. arXiv preprint arXiv:2605.26874 , year=
-
[12]
Nature , volume=
Health system-scale language models are all-purpose prediction engines , author=. Nature , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.