CombEval: A Framework for Evaluating Combinatorial Counting in Large Language Models
Pith reviewed 2026-06-26 17:25 UTC · model grok-4.3
The pith
A dynamic benchmark shows large language models remain brittle on combinatorial counting tasks involving ordered objects, indistinguishable elements, and nested dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
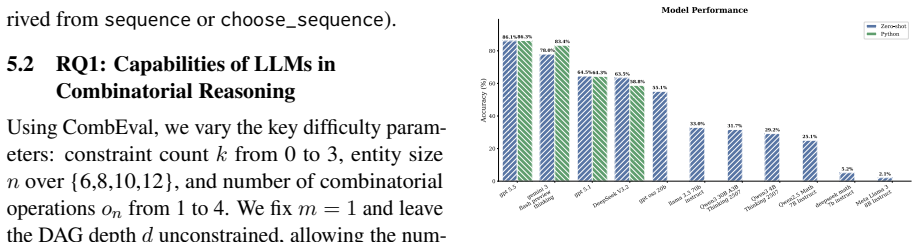
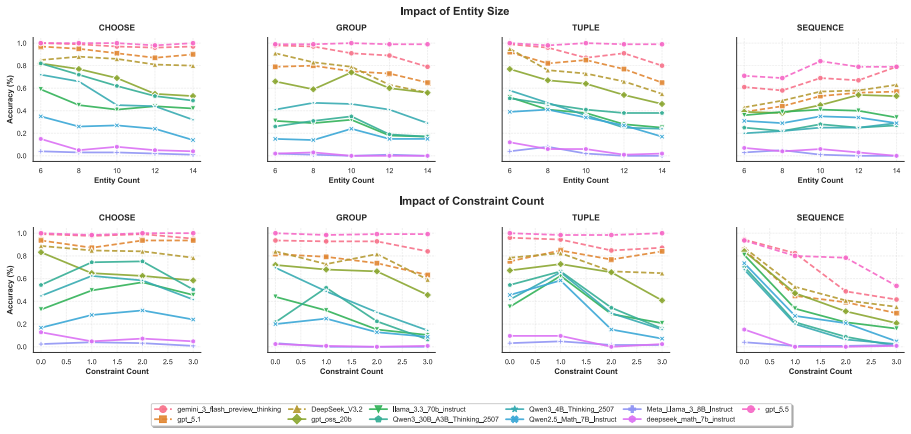
CombEval represents each problem as a typed Cofola specification over entities, combinatorial objects, object dependencies, and constraints, enabling controlled generation of natural-language counting problems with exact solver-verified answers. Unlike static collections, it supports systematic variation of object type, entity scale, constraint count, and reasoning depth. Evaluation of 11 LLMs finds that models remain brittle on ordered objects, indistinguishable elements, relatively positional constraints, and nested object dependencies, with error analysis identifying failures in constraint interpretation and counting principles.
What carries the argument
Typed Cofola specification, which encodes entities, combinatorial objects, dependencies, and constraints to drive dynamic problem generation and solver verification.
If this is right
- Models show greater difficulty with ordered objects than with unordered ones even when code execution is allowed.
- Increasing constraint count or reasoning depth produces measurable drops in accuracy tied to specific structures.
- Failures cluster around misreading relative positions and mishandling dependencies between objects.
- The same generation process can be reused to test whether improvements in one dimension transfer to others.
Where Pith is reading between the lines
- The identified failure modes suggest that current training distributions under-represent problems requiring explicit tracking of order and nesting.
- Dynamic specification frameworks like this could be adapted to generate training examples targeted at the observed error types.
- Similar controlled generation may expose parallel brittleness in other compositional reasoning tasks such as planning under constraints.
Load-bearing premise
The typed Cofola specifications produce natural-language problems whose difficulty and failure modes are driven by the intended combinatorial structure rather than by surface phrasing or solver artifacts.
What would settle it
If the same 11 LLMs achieved uniformly high accuracy across all variations of ordering, distinguishability, relative positions, and nesting depth under the CombEval generation process, the brittleness claim would be falsified.
Figures








read the original abstract
We present CombEval, a dynamic benchmark for evaluating combinatorial counting in large language models. CombEval represents each problem as a typed Cofola specification over entities, combinatorial objects, object dependencies, and constraints, enabling controlled generation of natural-language counting problems with exact solver-verified answers. Unlike static collections, CombEval supports systematic variation of object type, entity scale, constraint count, and reasoning depth. We evaluate 11 LLMs under direct and code-augmented settings and find that models remain brittle on ordered objects, indistinguishable elements, relatively positional constraints, and nested object dependencies. Error analysis further identifies failures in constraint interpretation and counting principles. CombEval provides a diagnostic testbed for studying when and why LLMs fail at combinatorial reasoning. The code and generated benchmark suites are publicly available at \url{https://github.com/YuxuZhou-CN/combination-problem-generation}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CombEval, a dynamic benchmark that uses typed Cofola specifications over entities, objects, dependencies, and constraints to generate natural-language combinatorial counting problems with solver-verified answers. It supports controlled variation of object type, scale, constraints, and depth; evaluates 11 LLMs in direct and code-augmented settings; reports brittleness on ordered objects, indistinguishable elements, relative positional constraints, and nested dependencies; and identifies failures in constraint interpretation and counting principles. Code and benchmark suites are released publicly.
Significance. If the central assumption holds, CombEval supplies a reproducible, extensible diagnostic testbed for combinatorial reasoning failures in LLMs, with systematic variation and public code release as concrete strengths. The empirical focus on specific structural features (ordered objects, nested dependencies) could help isolate reasoning gaps beyond static benchmarks.
major comments (2)
- [Abstract / problem representation] Abstract and § on problem representation: the claim that typed Cofola specifications produce NL problems whose difficulty and error modes are driven by combinatorial structure (rather than phrasing or solver artifacts) is load-bearing for all brittleness conclusions, yet the provided description gives no explicit fidelity checks, alternative-interpretation controls, or post-generation validation that the NL rendering preserves the intended semantics without introducing surface ambiguities.
- [Evaluation protocol] Evaluation protocol (abstract): without the full methods section it is impossible to assess whether post-hoc problem filtering, prompt variations, or solver edge cases affect the reported brittleness on ordered objects and nested dependencies; the soundness of attributing errors to combinatorial features therefore remains unverified.
minor comments (1)
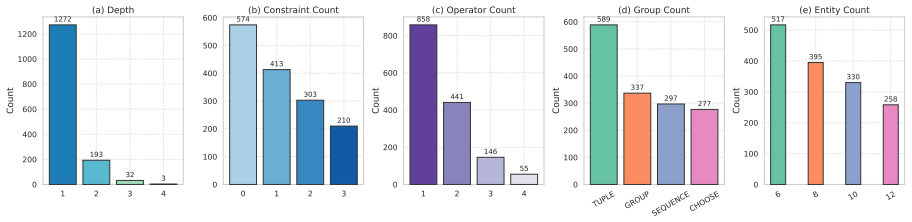
- [Abstract] The abstract states that CombEval 'supports systematic variation of object type, entity scale, constraint count, and reasoning depth' but does not quantify the ranges or distributions used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on CombEval. The comments highlight important aspects of validation that we will address in the revision to strengthen the claims about combinatorial structure driving the observed brittleness.
read point-by-point responses
-
Referee: [Abstract / problem representation] Abstract and § on problem representation: the claim that typed Cofola specifications produce NL problems whose difficulty and error modes are driven by combinatorial structure (rather than phrasing or solver artifacts) is load-bearing for all brittleness conclusions, yet the provided description gives no explicit fidelity checks, alternative-interpretation controls, or post-generation validation that the NL rendering preserves the intended semantics without introducing surface ambiguities.
Authors: The Cofola specification is a typed formal language that directly encodes the combinatorial structure, and the NL rendering is generated via deterministic templates that map each element of the spec to unambiguous natural language phrases. To make this explicit, we will add a dedicated subsection in the problem representation section describing the rendering process, including examples of how constraints are verbalized, and report on a fidelity study where we sampled 100 generated problems and verified that independent annotators could reconstruct the original spec from the NL with high accuracy. This addresses the concern without altering the core results. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol (abstract): without the full methods section it is impossible to assess whether post-hoc problem filtering, prompt variations, or solver edge cases affect the reported brittleness on ordered objects and nested dependencies; the soundness of attributing errors to combinatorial features therefore remains unverified.
Authors: The methods section details that problems are generated on-the-fly from specs, with answers verified by an exact solver (Z3 or similar for counting), and no post-hoc filtering is applied beyond ensuring the solver returns a unique answer. Prompt variations were tested in preliminary experiments but the main results use a fixed prompt template. We will expand the evaluation protocol subsection to include these details, a description of how solver edge cases (e.g., large numbers) are handled by using symbolic counting where possible, and confirm that the brittleness patterns hold across variations. This will allow readers to verify the attribution to combinatorial features. revision: yes
Circularity Check
No circularity: empirical benchmark with direct model evaluations
full rationale
The paper introduces CombEval as a dynamic benchmark using typed Cofola specifications to generate natural-language counting problems with solver-verified answers. Central results consist of direct LLM performance measurements and error analysis on these instances. No mathematical derivations, parameter fitting, predictions of derived quantities, uniqueness theorems, or ansatzes are present. The load-bearing assumption (that NL rendering isolates combinatorial structure) is an empirical validity claim, not a reduction of outputs to inputs by construction. No self-citation chains or renamings of known results appear in the provided text. This is a standard non-circular empirical evaluation setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Solver-verified answers are treated as ground truth for the generated problems.
Reference graph
Works this paper leans on
-
[1]
Essence: A constraint language for specify- ing combinatorial problems.Constraints, 13(3):268– 306. Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Gra- ham Neubig. 2023a. Pal: Program-aided language models. InInternational Conference on Machine Learning, pages 10764–10799. PMLR. Yunfan Gao, Yun Xiong, Xinyu Gao, ...
Pith/arXiv arXiv 2022
-
[2]
arXiv preprint arXiv:2410.05229
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229. Andreas Opedal, Haruki Shirakami, Bernhard Schölkopf, Abulhair Saparov, and Mrinmaya Sachan
-
[3]
Mathgap: Out-of-distribution evaluation on problems with arbitrarily complex proofs.arXiv preprint arXiv:2410.13502. OpenAI. 2025. gpt-oss-120b & gpt-oss-20b model card. Preprint, arXiv:2508.10925. Igor Pak. 2019. COMPLEXITY PROBLEMS IN ENU- MERATIVE COMBINATORICS. InProceedings of the International Congress of Mathematicians (ICM 2018), Rio de Janeiro, B...
arXiv 2025
-
[4]
arXiv preprint arXiv:2501.09686
Towards large reasoning models: A survey of reinforced reasoning with large language models. arXiv preprint arXiv:2501.09686. Yu Xuejun, Jianyuan Zhong, Zijin Feng, Pengyi Zhai, Roozbeh Yousefzadeh, Wei Chong Ng, Haoxiong Liu, Ziyi Shou, Jing Xiong, Yudong Zhou, and 1 others. 2025. Mathesis: Towards formal theorem proving from natural languages.arXiv prep...
Pith/arXiv arXiv 2025
-
[5]
InForty-second International Con- ference on Machine Learning Position Paper Track
Position: Formal mathematical reasoning—a new frontier in ai. InForty-second International Con- ference on Machine Learning Position Paper Track. Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, and 1 others. 2023. A survey of large language models.arXiv preprint arXiv:2303.1...
Pith/arXiv arXiv 2023
-
[6]
Minif2f: a cross-system benchmark for for- mal olympiad-level mathematics.arXiv preprint arXiv:2109.00110. Xin Zhou, Martin Weyssow, Ratnadira Widyasari, Ting Zhang, Junda He, Yunbo Lyu, Jianming Chang, Beiqi Zhang, Dan Huang, and David Lo. 2025. Lessleak- bench: A first investigation of data leakage in llms across 83 software engineering benchmarks.arXiv...
Pith/arXiv arXiv 2025
-
[7]
Show all intermediate steps, including the use of standard combinatorial notation and formulas
First, reason step-by-step to solve the problem. Show all intermediate steps, including the use of standard combinatorial notation and formulas
-
[8]
Compute the exact numerical value; do not leave expressions unevaluated
-
[9]
After completing the reasoning, report the final answer as a single number enclosed in\boxed{}
-
[10]
Question: {question} Figure 5: The prompt template used during evaluation
Do not include any text after the boxed answer. Question: {question} Figure 5: The prompt template used during evaluation. The placeholder {question} is instantiated with a spe- cific problem instance at inference time. sitions, and relative or group-level constraints. C Experimental Details C.1 Capabilities of LLMs in Combinatorial Reasoning dataset dist...
-
[11]
Do not include any natural language explanations, introduction, text, or mathematical derivation
You must ONLY output executable Python code. Do not include any natural language explanations, introduction, text, or mathematical derivation
-
[12]
The code must be self-contained and calculate the exact numerical answer to the problem
-
[13]
Counting and Probability
Print or return the final result within the code. Do not add any text or formatting (like \boxed{}) outside the code block. Question: {question} Figure 6: The prompt template used during code- augmented evaluation (Python setting). The placeholder {question} is instantiated with a specific problem in- stance at inference time. to ensure ground-truth answe...
2021
-
[14]
Keep the mathematical core exactly the same (same numbers, same conditions)
-
[15]
You can change the setting (e.g., from balls in boxes to students in classrooms) if it fits the logic, or just improve the narrative of the current setting
-
[16]
together
Ensure the question is clear and unambiguous. Output Format:Just provide the rewritten problem text. Do not include explanations or the Cofola code. Rewritten Problem: Figure 9: The prompt used to generate rewritten variations of combinatorial problems. Placeholders in blue are replaced with reference examples, the Cofola logic representation, and the ori...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.