V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
Pith reviewed 2026-06-25 21:21 UTC · model grok-4.3
The pith
V-Zero enables answer-label-free on-policy distillation for fine-grained visual reasoning via contrastive evidence gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
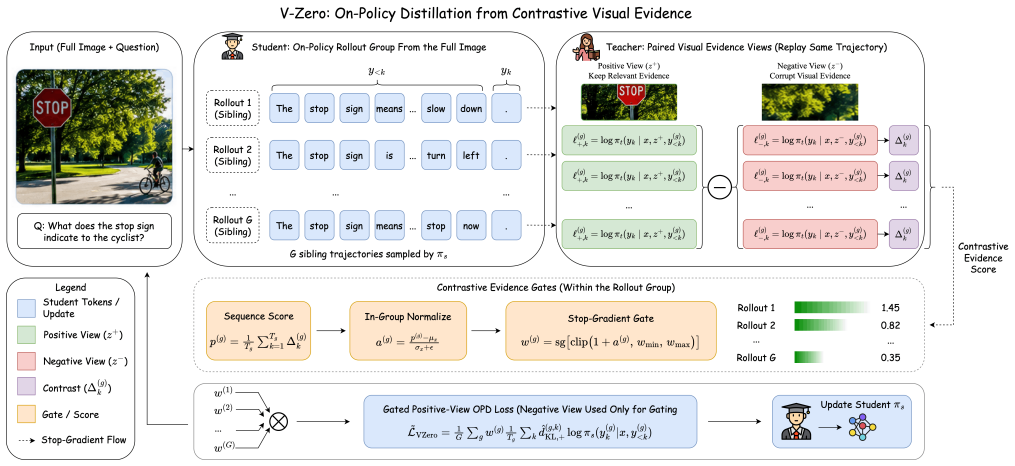
V-Zero revisits on-policy distillation as negative-free stop-gradient alignment and shows that its ceiling stems from the absence of trajectory-level discrimination. The framework therefore pairs a question-relevant regional crop with a negative visual view during training to evaluate student-sampled trajectories and gate the application of dense token-level distillation, achieving effective learning with no textual answer supervision.
What carries the argument
Contrastive evidence gating, which evaluates and selectively applies distillation to student trajectories by contrasting a question-relevant crop against a negative visual view.
If this is right
- Consistently improves fine-grained visual reasoning across multiple benchmarks
- Preserves strong generalization on held-out tasks
- Achieves more than 5 times faster training than prior supervised fine-tuning methods
- Achieves more than 10 times faster training than reinforcement learning baselines
Where Pith is reading between the lines
- The gating mechanism could be tested on non-visual modalities if analogous positive-negative pairs can be constructed from other sensory data.
- Removing answer labels may lower the barrier to scaling visual reasoning datasets collected from uncurated sources.
- The speed advantage might allow iterative self-improvement loops that alternate between sampling and gated distillation within a single training run.
Load-bearing premise
Pairing a question-relevant regional crop with a negative visual view during training can reliably evaluate and gate student trajectories to supply effective trajectory-level discrimination without external answer labels.
What would settle it
A controlled experiment on the same benchmarks where trajectories selected by the contrastive gating produce no accuracy gain over ungated on-policy distillation.
Figures



read the original abstract
Fine-grained visual reasoning requires multimodal large language models (MLLMs) to identify task-relevant visual evidence and ground their reasoning in local image regions. Existing agentic methods typically rely on reinforcement learning with verifiable rewards or supervised fine-tuning on large-scale annotated reasoning traces, leading to costly exploration, hand-designed verification rules, or heavy dependence on textual supervision. A natural way to avoid such external answer labels is to learn from trajectories sampled by the student itself, which points to On-Policy Distillation (OPD). To understand what OPD can and cannot provide for visual reasoning, we revisit it as negative-free stop-gradient alignment. This perspective shows that, although OPD provides effective token-level correction, its ceiling is constrained by the absence of trajectory-level discrimination. Motivated by these observations, we propose V-Zero, an answer-label-free framework for visual reasoning with contrastive evidence gating. V-Zero uses no annotated textual answer labels; instead, during training it pairs a question-relevant regional crop with a negative visual view to evaluate student-sampled trajectories and gate dense token-level distillation. Experiments on multiple visual reasoning benchmarks show that V-Zero consistently improves fine-grained visual reasoning while preserving strong generalization. Notably, V-Zero is more than 5$\times$ faster than previous supervised fine-tuning methods and more than 10$\times$ faster than reinforcement learning baselines. Code and dataset will be released at https://github.com/eVI-group-SCU/V-Zero
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes V-Zero, an answer-label-free on-policy distillation framework for fine-grained visual reasoning in multimodal large language models. It revisits on-policy distillation as negative-free stop-gradient alignment to identify its limitations at the trajectory level, then introduces contrastive evidence gating that pairs a question-relevant regional crop with a negative visual view to evaluate and gate student-sampled trajectories for distillation. The paper claims that this approach improves fine-grained visual reasoning on multiple benchmarks, maintains strong generalization, and achieves substantial speedups (over 5× compared to supervised fine-tuning and over 10× compared to reinforcement learning baselines), with code and dataset to be released.
Significance. If the contrastive evidence gating mechanism reliably provides trajectory-level discrimination without requiring answer labels or verification rules, the result would be significant for developing efficient, label-efficient training methods for visual reasoning agents. The planned release of code and dataset strengthens the potential impact by enabling reproducibility and further research. However, the absence of quantitative results in the abstract limits the immediate assessment of the claimed gains.
major comments (2)
- [Abstract] Abstract: The claims of consistent improvements in fine-grained visual reasoning, strong generalization, and speedups of more than 5× over SFT and 10× over RL are presented without any numerical results, baseline details, ablation studies, or error analysis. This makes it impossible to evaluate the central empirical claims against the data.
- [Method] Method description of contrastive evidence gating: The load-bearing assumption that pairing a question-relevant regional crop with a negative visual view can reliably evaluate and gate trajectories for effective discrimination is not supported by any external verification or shown correlation with reasoning quality. If crop selection implicitly relies on answer knowledge, the label-free claim and trajectory-level advantage over OPD would not hold.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of consistent improvements in fine-grained visual reasoning, strong generalization, and speedups of more than 5× over SFT and 10× over RL are presented without any numerical results, baseline details, ablation studies, or error analysis. This makes it impossible to evaluate the central empirical claims against the data.
Authors: We agree that the abstract would benefit from including key quantitative results to allow immediate evaluation of the claims. In the revised manuscript we will update the abstract to report specific metrics, such as accuracy gains on the evaluated benchmarks and the measured speedup factors (approximately 5.3× versus SFT and 11.2× versus RL baselines), while retaining conciseness. Baseline names and a brief reference to the main experimental tables will also be added. revision: yes
-
Referee: [Method] Method description of contrastive evidence gating: The load-bearing assumption that pairing a question-relevant regional crop with a negative visual view can reliably evaluate and gate trajectories for effective discrimination is not supported by any external verification or shown correlation with reasoning quality. If crop selection implicitly relies on answer knowledge, the label-free claim and trajectory-level advantage over OPD would not hold.
Authors: The question-relevant crop is obtained via a frozen pre-trained visual grounding model that receives only the question text and the original image; no answer labels or reasoning traces are used. The negative view is produced by random cropping of non-salient regions. Our main results already demonstrate that V-Zero outperforms the OPD baseline, providing indirect evidence that the contrastive score supplies useful trajectory-level discrimination. To directly address the concern we will add (i) a detailed description of the crop-selection pipeline confirming it is label-free and (ii) a new analysis correlating the contrastive gating scores with human judgments of reasoning quality on a held-out set of trajectories. These additions will be made without introducing answer supervision. revision: partial
Circularity Check
No circularity; empirical framework with no self-referential reductions or fitted predictions.
full rationale
The paper describes V-Zero as an empirical answer-label-free method using contrastive evidence gating via question-relevant crops and negative views to gate student trajectories. No equations, derivations, or first-principles claims are presented that reduce performance gains to inputs by construction. The method is positioned as overcoming OPD limitations through design choices, but these are not shown to be tautological or dependent on self-citation chains. The central assumption about discrimination effectiveness is an empirical hypothesis, not a definitional loop. This matches the default expectation of no significant circularity for empirical papers without mathematical reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption On-policy distillation supplies effective token-level correction but requires additional trajectory-level discrimination for visual reasoning.
Reference graph
Works this paper leans on
-
[1]
BabyVision: Visual Reasoning Beyond Language , url =. 2026 , bdsk-url-1 =. arXiv , author =:2601.06521 , primaryclass =
arXiv 2026
-
[2]
CountQA: How Well Do MLLMs Count in the Wild? , url =. 2025 , bdsk-url-1 =. arXiv , author =:2508.06585 , primaryclass =
arXiv 2025
-
[3]
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness , url =. 2025 , bdsk-url-1 =. arXiv , author =:2504.10514 , primaryclass =
arXiv 2025
-
[4]
CVBench: Benchmarking Cross-Video Synergies for Complex Multimodal Reasoning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2508.19542 , primaryclass =
arXiv 2026
-
[5]
arXiv preprint , title =
Wenbin Wang and Liang Ding and Minyan Zeng and Xiabin Zhou and Li Shen and Yong Luo and Dacheng Tao , date-added =. arXiv preprint , title =. 2024 , bdsk-url-1 =
2024
-
[6]
Are We on the Right Way for Evaluating Large Vision-Language Models? , url =. 2024 , bdsk-url-1 =. arXiv , author =:2403.20330 , primaryclass =
Pith/arXiv arXiv 2024
-
[7]
MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans? , url =. 2025 , bdsk-url-1 =. arXiv , author =:2408.13257 , primaryclass =
Pith/arXiv arXiv 2025
-
[8]
Revisiting on-policy distillation: Empirical failure modes and simple fixes , year =
Fu, Yuqian and Huang, Haohuan and Jiang, Kaiwen and Liu, Jiacai and Jiang, Zhuo and Zhu, Yuanheng and Zhao, Dongbin , journal =. Revisiting on-policy distillation: Empirical failure modes and simple fixes , year =
-
[9]
On-policy distillation.Thinking Machines Lab: Connectionism, 2025
Kevin Lu and Thinking Machines Lab , date-added =. On-Policy Distillation , year =. doi:10.64434/tml.20251026 , journal =
-
[10]
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , url =. 2024 , bdsk-url-1 =. arXiv , author =:2306.13649 , primaryclass =
arXiv 2024
-
[11]
Self-Distillation Enables Continual Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2601.19897 , primaryclass =
Pith/arXiv arXiv 2026
-
[12]
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones? , url =. 2025 , bdsk-url-1 =. arXiv , author =:2502.19557 , primaryclass =
arXiv 2025
-
[13]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , url =. 2026 , bdsk-url-1 =. arXiv , author =:2604.13016 , primaryclass =
Pith/arXiv arXiv 2026
-
[14]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens , url =. 2025 , bdsk-url-1 =. arXiv , author =:2506.17218 , primaryclass =
Pith/arXiv arXiv 2025
-
[15]
Latent Chain-of-Thought for Visual Reasoning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2510.23925 , primaryclass =
arXiv 2025
-
[16]
Latent Visual Reasoning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2509.24251 , primaryclass =
Pith/arXiv arXiv 2025
-
[17]
Perception-Aware Policy Optimization for Multimodal Reasoning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2507.06448 , primaryclass =
Pith/arXiv arXiv 2026
-
[18]
Visually-Guided Policy Optimization for Multimodal Reasoning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2604.09349 , primaryclass =
Pith/arXiv arXiv 2026
-
[19]
Bootstrap your own latent-a new approach to self-supervised learning , volume =
Grill, Jean-Bastien and Strub, Florian and Altch. Bootstrap your own latent-a new approach to self-supervised learning , volume =. Advances in neural information processing systems , pages =
-
[20]
Exploring simple siamese representation learning , year =
Chen, Xinlei and He, Kaiming , booktitle =. Exploring simple siamese representation learning , year =
-
[21]
Qwen3-vl technical report , year =
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and Cheng, Zesen and Deng, Lianghao and Ding, Wei and Gao, Chang and Ge, Chunjiang and others , journal =. Qwen3-vl technical report , year =
-
[22]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , year =
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and others , journal =. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , year =
-
[23]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , year =
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , booktitle =. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , year =
-
[24]
V?: Guided visual search as a core mechanism in multimodal llms , year =
Wu, Penghao and Xie, Saining , booktitle =. V?: Guided visual search as a core mechanism in multimodal llms , year =
-
[25]
Mm-vet: Evaluating large multimodal models for integrated capabilities , year =
Yu, Weihao and Yang, Zhengyuan and Li, Linjie and Wang, Jianfeng and Lin, Kevin and Liu, Zicheng and Wang, Xinchao and Wang, Lijuan , journal =. Mm-vet: Evaluating large multimodal models for integrated capabilities , year =
-
[26]
Mmbench: Is your multi-modal model an all-around player? , year =
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and others , booktitle =. Mmbench: Is your multi-modal model an all-around player? , year =
-
[27]
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , year =
Chu, Tianzhe and Zhai, Yuexiang and Yang, Jihan and Tong, Shengbang and Xie, Saining and Schuurmans, Dale and Le, Quoc V and Levine, Sergey and Ma, Yi , journal =. Sft memorizes, rl generalizes: A comparative study of foundation model post-training , year =
-
[28]
thinking with images
Zheng, Ziwei and Yang, Michael and Hong, Jack and Zhao, Chenxiao and Xu, Guohai and Yang, Le and Shen, Chao and Yu, Xing , journal =. Deepeyes: Incentivizing" thinking with images" via reinforcement learning , year =
-
[29]
On information and sufficiency , volume =
Kullback, Solomon and Leibler, Richard A , journal =. On information and sufficiency , volume =
-
[30]
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images , url =. 2026 , bdsk-url-1 =. arXiv , author =:2512.17306 , primaryclass =
arXiv 2026
-
[31]
Don't Blink: Evidence Collapse during Multimodal Reasoning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2604.04207 , primaryclass =
Pith/arXiv arXiv 2026
-
[32]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers , url =. 2025 , bdsk-url-1 =. arXiv , author =:2506.23918 , primaryclass =
Pith/arXiv arXiv 2025
-
[33]
Self-Distilled RLVR , url =. 2026 , bdsk-url-1 =. arXiv , author =:2604.03128 , primaryclass =
Pith/arXiv arXiv 2026
-
[34]
Reinforced Attention Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2602.04884 , primaryclass =
arXiv 2026
-
[35]
arXiv preprint arXiv:2601.20802 , title =
H. arXiv preprint arXiv:2601.20802 , title =. 2026 , bdsk-url-1 =
Pith/arXiv arXiv 2026
-
[36]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , url =. 2026 , bdsk-url-1 =. arXiv , author =:2601.18734 , primaryclass =
Pith/arXiv arXiv 2026
-
[37]
Experiential Reinforcement Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2602.13949 , primaryclass =
arXiv 2026
-
[38]
DeepEyesV2: Toward Agentic Multimodal Model , url =. 2026 , bdsk-url-1 =. arXiv , author =:2511.05271 , primaryclass =
Pith/arXiv arXiv 2026
-
[39]
Revisiting the Necessity of Lengthy Chain-of-Thought in Vision-centric Reasoning Generalization , url =. 2025 , bdsk-url-1 =. arXiv , author =:2511.22586 , primaryclass =
arXiv 2025
-
[40]
Seeing but Not Believing: Probing the Disconnect Between Visual Attention and Answer Correctness in VLMs , url =. 2025 , bdsk-url-1 =. arXiv , author =:2510.17771 , primaryclass =
arXiv 2025
-
[41]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.15966 , primaryclass =
Pith/arXiv arXiv 2025
-
[42]
Reflect to Inform: Boosting Multimodal Reasoning via Information-Gain-Driven Verification , url =. 2026 , bdsk-url-1 =. arXiv , author =:2603.26348 , primaryclass =
arXiv 2026
-
[43]
Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception , url =. 2026 , bdsk-url-1 =. arXiv , author =:2602.11858 , primaryclass =
arXiv 2026
-
[44]
Reliable Thinking with Images , url =. 2026 , bdsk-url-1 =. arXiv , author =:2602.12916 , primaryclass =
arXiv 2026
-
[45]
Thyme: Think Beyond Images , url =. 2025 , bdsk-url-1 =. arXiv , author =:2508.11630 , primaryclass =
Pith/arXiv arXiv 2025
-
[46]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent , url =. 2025 , bdsk-url-1 =. arXiv , author =:2508.05748 , primaryclass =
Pith/arXiv arXiv 2025
-
[47]
Multimodal Chain-of-Thought Reasoning in Language Models , url =. 2024 , bdsk-url-1 =. arXiv , author =:2302.00923 , primaryclass =
Pith/arXiv arXiv 2024
-
[48]
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , url =. 2024 , bdsk-url-1 =. arXiv , author =:2406.09403 , primaryclass =
arXiv 2024
-
[49]
Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.22334 , primaryclass =
arXiv 2025
-
[50]
Ground-R1: Incentivizing Grounded Visual Reasoning via Reinforcement Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2505.20272 , primaryclass =
arXiv 2026
-
[51]
Grounded Chain-of-Thought for Multimodal Large Language Models , url =. 2025 , bdsk-url-1 =. arXiv , author =:2503.12799 , primaryclass =
arXiv 2025
-
[52]
Visual-RFT: Visual Reinforcement Fine-Tuning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2503.01785 , primaryclass =
Pith/arXiv arXiv 2025
-
[53]
GRIT: Teaching MLLMs to Think with Images , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.15879 , primaryclass =
Pith/arXiv arXiv 2025
-
[54]
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs , url =. 2025 , bdsk-url-1 =. arXiv , author =:2502.17422 , primaryclass =
arXiv 2025
-
[55]
Visual Planning: Let's Think Only with Images , url =. 2026 , bdsk-url-1 =. arXiv , author =:2505.11409 , primaryclass =
arXiv 2026
-
[56]
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing , url =. 2025 , bdsk-url-1 =. arXiv , author =:2506.09965 , primaryclass =
Pith/arXiv arXiv 2025
-
[57]
Grounded Reinforcement Learning for Visual Reasoning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.23678 , primaryclass =
Pith/arXiv arXiv 2025
-
[58]
Thinking with Generated Images , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.22525 , primaryclass =
arXiv 2025
-
[59]
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search , url =. 2025 , bdsk-url-1 =. arXiv , author =:2504.09130 , primaryclass =
arXiv 2025
-
[60]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.08617 , primaryclass =
Pith/arXiv arXiv 2025
-
[61]
Look-Back: Implicit Visual Re-focusing in MLLM Reasoning , url =. 2025 , bdsk-url-1 =. arXiv , author =:2507.03019 , primaryclass =
arXiv 2025
-
[62]
DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding , url =. 2025 , bdsk-url-1 =. arXiv , author =:2504.14920 , primaryclass =
arXiv 2025
-
[63]
Perception in Reflection , url =. 2025 , bdsk-url-1 =. arXiv , author =:2504.07165 , primaryclass =
arXiv 2025
-
[64]
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding , url =. 2025 , bdsk-url-1 =. arXiv , author =:2501.05452 , primaryclass =
arXiv 2025
-
[65]
Visual Agents as Fast and Slow Thinkers , url =. 2025 , bdsk-url-1 =. arXiv , author =:2408.08862 , primaryclass =
arXiv 2025
-
[66]
Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning , url =. 2024 , bdsk-url-1 =. arXiv , author =:2403.16999 , primaryclass =
arXiv 2024
-
[67]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2505.14362 , primaryclass =
Pith/arXiv arXiv 2026
-
[68]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , url =. 2024 , bdsk-url-1 =. arXiv , author =:2402.03300 , primaryclass =
Pith/arXiv arXiv 2024
-
[69]
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation , url =. 2026 , bdsk-url-1 =. arXiv , author =:2602.02994 , primaryclass =
Pith/arXiv arXiv 2026
-
[70]
Qwen3 Technical Report , url =. 2025 , bdsk-url-1 =. arXiv , author =:2505.09388 , primaryclass =
Pith/arXiv arXiv 2025
-
[71]
Qwen2.5-VL Technical Report , year =
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
-
[72]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , year =
Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang , journal =. Qwen2-VL: Enhancing Vision-Language Model's P...
-
[73]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , year =
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal =. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , year =
-
[74]
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , booktitle =. HybridFlow: A Flexible and Efficient RLHF Framework , url =. 2025 , bdsk-url-1 =. doi:10.1145/3689031.3696075 , month = Mar, pages =
-
[75]
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning , url =. 2026 , bdsk-url-1 =. arXiv , author =:2512.24330 , primaryclass =
arXiv 2026
-
[76]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search , url =. 2025 , bdsk-url-1 =. arXiv , author =:2509.07969 , primaryclass =
Pith/arXiv arXiv 2025
-
[77]
Skywork-R1V4: Toward Agentic Multimodal Intelligence through Interleaved Thinking with Images and DeepResearch , url =. 2025 , bdsk-url-1 =. arXiv , author =:2512.02395 , primaryclass =
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.