The Past Is Prologue: A Plug-in Controller for Selective Updates in Sequentially Evolving LLM Memory
Pith reviewed 2026-07-01 05:57 UTC · model grok-4.3
The pith
Janus is a plug-in controller that decides whether to accept or reject each LLM memory update by flagging suspicious trajectory deviations and testing on a compact hybrid set of coverage, boundary, and fresh tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Janus is a method-agnostic plug-in that decides whether to accept a candidate memory update or retain the previous memory. It identifies suspicious deviations in the update trajectory with the Memory Momentum Trigger and compares the two memories on a compact hybrid evaluation set of coverage, boundary, and fresh tasks instead of replaying the full history, producing consistent accuracy gains of 2.7 to 4.6 points over the base updaters.
What carries the argument
The Memory Momentum Trigger that detects suspicious deviations in the memory-update trajectory, paired with comparison of old and new memories on a compact hybrid evaluation set of coverage, boundary, and fresh tasks.
If this is right
- Existing memory updaters can be wrapped and improved without modifying their internal update rules.
- Updates that aid the current task but harm future performance are rejected before they overwrite useful knowledge.
- Full history replay is avoided while still guarding against over-specific rules or recent-example bias.
- The same controller works across different backbone LLMs and different base memory updaters.
Where Pith is reading between the lines
- The selective-accept mechanism could extend to other sequential knowledge stores that agents maintain over long interactions.
- Dynamic adjustment of the hybrid evaluation set size or composition might further reduce false rejections on novel task types.
- The momentum trigger could be combined with uncertainty estimates from the base updater to refine rejection thresholds.
Load-bearing premise
That performance on the compact hybrid evaluation set reliably predicts whether an update will improve behavior on unseen future tasks without replaying the full history.
What would settle it
On a new long sequence or dataset, always accepting updates produces higher accuracy on held-out tasks than the Janus-controlled updates.
Figures



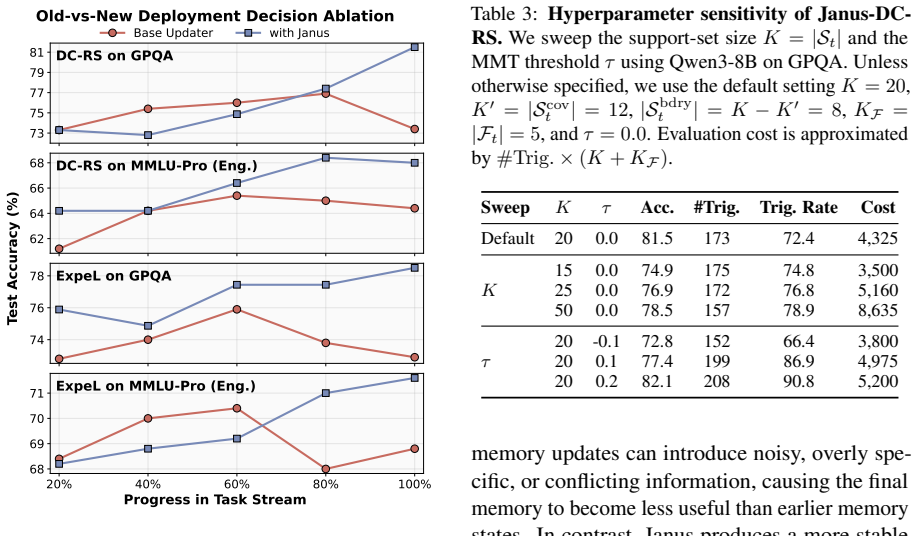
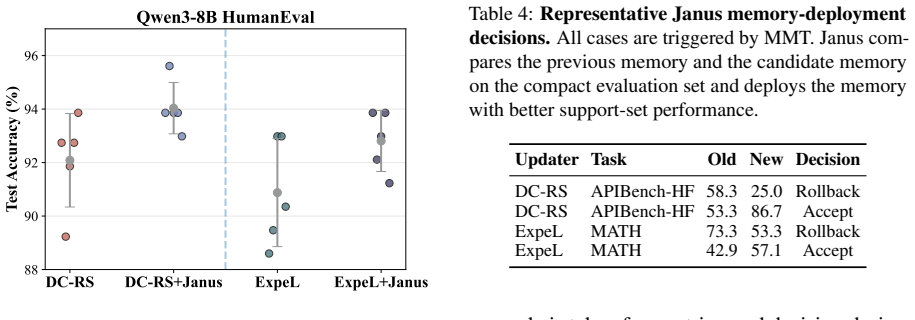
read the original abstract
Sequentially evolving LLM memory enables agents to reuse past experience, but existing systems usually deploy each locally generated memory update without checking whether it improves future behavior. As a result, updates that help the current task may overwrite useful knowledge, introduce over-specific rules, or bias the final memory toward recent examples. We propose Janus, a plug-in memory controller that decides whether to accept a candidate memory update or retain the previous memory. To make this decision efficient, Janus uses a Memory Momentum Trigger to identify suspicious deviations in the memory-update trajectory, and compares old and new memories on a compact hybrid evaluation set of coverage, boundary, and fresh tasks instead of replaying the full history. Janus is method-agnostic and wraps existing updaters without changing their update rules. Across six datasets, two backbone LLMs, and two memory updaters, Janus improves average accuracy by +2.7 to +4.6 points over the corresponding base updaters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Janus, a plug-in memory controller for sequentially evolving LLM memory. Janus decides whether to accept candidate memory updates or retain previous memory by using a Memory Momentum Trigger to identify suspicious deviations and comparing memories on a compact hybrid evaluation set of coverage, boundary, and fresh tasks. The approach is method-agnostic and is evaluated across six datasets, two backbone LLMs, and two memory updaters, claiming average accuracy improvements of +2.7 to +4.6 points over base updaters.
Significance. If the reported gains are shown to result from genuine improvements in generalization rather than circular evaluation, Janus could offer an efficient way to manage memory updates in LLM-based agents, reducing the risk of overwriting useful knowledge or introducing biases from recent examples. The plug-in nature allows integration with existing updaters without modification, which is a practical strength.
major comments (2)
- The abstract claims empirical gains of +2.7 to +4.6 points but provides no information on experimental protocol, statistical tests, baseline details, or ablation studies, making it impossible to evaluate the soundness of the central performance claim.
- The hybrid evaluation set is used both for the Memory Momentum Trigger's decisions and for measuring the accuracy improvements. This setup risks circular evaluation, where the controller may simply retain updates that perform well on the decision metric without ensuring better performance on truly unseen future tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the experimental details and evaluation design while indicating planned revisions.
read point-by-point responses
-
Referee: The abstract claims empirical gains of +2.7 to +4.6 points but provides no information on experimental protocol, statistical tests, baseline details, or ablation studies, making it impossible to evaluate the soundness of the central performance claim.
Authors: We agree the abstract is concise and omits key details. The full manuscript (Sections 4.1–4.3 and 5) specifies the six datasets, two backbone LLMs, two memory updaters, the protocol of multiple independent runs with reported means and standard deviations, and the ablation studies in Section 5.2. We will revise the abstract to include a short statement on the multi-dataset, multi-model evaluation to better support the performance claims. revision: yes
-
Referee: The hybrid evaluation set is used both for the Memory Momentum Trigger's decisions and for measuring the accuracy improvements. This setup risks circular evaluation, where the controller may simply retain updates that perform well on the decision metric without ensuring better performance on truly unseen future tasks.
Authors: The hybrid evaluation set (coverage, boundary, and fresh tasks) is used only inside the Memory Momentum Trigger for the accept/reject decision. Reported accuracy gains are measured on separate held-out test sets that are disjoint from the hybrid set; these test sets are never seen by the trigger. We will add an explicit statement in Section 3.2 and the experimental setup to make this separation unambiguous. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper contains no equations, derivations, or first-principles claims that could reduce to their inputs by construction. The central result is an empirical accuracy improvement (+2.7 to +4.6 points) measured on six datasets after applying the Janus controller; this is presented as an experimental outcome rather than a quantity defined from fitted parameters or the hybrid evaluation set itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The hybrid set is used for update decisions, but the reported gains are not shown to be statistically forced by that same metric, leaving the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance on the compact hybrid evaluation set of coverage, boundary, and fresh tasks reliably indicates whether a memory update improves future behavior.
invented entities (1)
-
Memory Momentum Trigger
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dynamic cheatsheet: Test-time learning with adaptive memory , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[8]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory , author=. arXiv preprint arXiv:2511.20857 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Memp: Exploring Agent Procedural Memory
Memp: Exploring agent procedural memory , author=. arXiv preprint arXiv:2508.06433 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Available at SSRN 6626878 , year=
A Systematic Survey of Self-Evolving Agents: From Model-Centric to Environment-Driven Co-Evolution , author=. Available at SSRN 6626878 , year=
-
[14]
arXiv preprint arXiv:2508.16153 , year=
Memento: Fine-tuning llm agents without fine-tuning llms , author=. arXiv preprint arXiv:2508.16153 , year=
-
[15]
arXiv preprint arXiv:2509.04439 , year=
Arcmemo: Abstract reasoning composition with lifelong llm memory , author=. arXiv preprint arXiv:2509.04439 , year=
-
[16]
Reinforcement Learning for Self-Improving Agent with Skill Library
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Skillweaver: Web agents can self-improve by discovering and honing skills , author=. arXiv preprint arXiv:2504.07079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Gepa: Reflective prompt evolution can outperform reinforcement learning , author=. arXiv preprint arXiv:2507.19457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in neural information processing systems , volume=
Gradient episodic memory for continual learning , author=. Advances in neural information processing systems , volume=
-
[20]
International Conference on Learning Representations 2022 , year=
Pretrained Language Model in Continual Learning: A Comparative Study , author=. International Conference on Learning Representations 2022 , year=
2022
-
[21]
International Conference on Machine Learning , pages=
Agent Workflow Memory , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[22]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in Neural Information Processing Systems , volume=
G-memory: Tracing hierarchical memory for multi-agent systems , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2507.23361
Swe-exp: Experience-driven software issue resolution , author=. arXiv preprint arXiv:2507.23361 , year=
-
[26]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
How Far Can LLMs Improve from Experience? Measuring Test-Time Learning Ability in LLMs with Human Comparison , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[27]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[28]
A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems , author=. arXiv preprint arXiv:2508.07407 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[30]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning , author=. arXiv preprint arXiv:2508.19828 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Nature , volume=
Optimizing generative ai by backpropagating language model feedback , author=. Nature , volume=. 2025 , publisher=
2025
-
[33]
International Conference on Learning Representations , year=
Tent: Fully Test-Time Adaptation by Entropy Minimization , author=. International Conference on Learning Representations , year=
-
[34]
Advances in neural information processing systems , volume=
Memo: Test time robustness via adaptation and augmentation , author=. Advances in neural information processing systems , volume=
-
[35]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[36]
International Conference on Learning Representations , volume=
Critic: Large language models can self-correct with tool-interactive critiquing , author=. International Conference on Learning Representations , volume=
-
[37]
International conference on learning representations , volume=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. International conference on learning representations , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.