CoMo3R-SLAM: Collaborative Monocular Dense SLAM with Learned 3D Reconstruction Priors for Outdoor Multi-Agent Systems
Pith reviewed 2026-06-29 06:52 UTC · model grok-4.3
The pith
Learned 3D reconstruction priors allow monocular RGB cameras to produce globally consistent metric maps for multiple outdoor robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoMo3R-SLAM demonstrates that learned feed-forward 3D reconstruction priors can provide the robust geometric information required for cross-agent verification, closed-form Sim(3) gauge synchronization, and GPU-accelerated global bundle adjustment, enabling the production of globally consistent metric maps from monocular RGB inputs in outdoor multi-agent systems without depth sensors or parametric intrinsics.
What carries the argument
Learned feed-forward 3D reconstruction priors that guide the front-end tracking and enable dense pointmap matching for cross-agent constraints.
If this is right
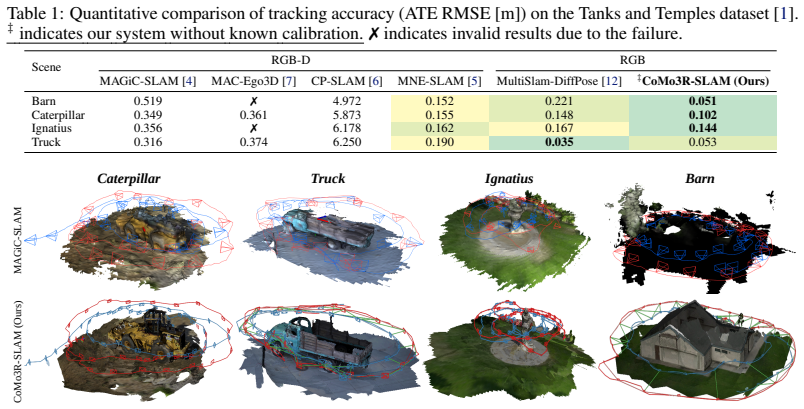
- The system achieves the best absolute trajectory error on three of four Tanks and Temples scenes.
- It matches or exceeds state-of-the-art RGB-D methods on Waymo sequences.
- The system operates online at 8 FPS using only monocular RGB.
- Robust cross-agent constraints are generated without relying on traditional feature matching.
Where Pith is reading between the lines
- Such systems could reduce hardware requirements and costs for multi-robot deployments in large outdoor areas.
- Extensions might include handling dynamic environments or integrating with semantic understanding.
- The approach suggests learned priors can substitute for depth in other SLAM variants.
Load-bearing premise
Learned feed-forward 3D reconstruction priors supply reliable geometric information sufficient for cross-agent verification and scale recovery in outdoor scenes with low overlap and repetitive structures.
What would settle it
Demonstrating a set of outdoor scenes where the learned priors produce inaccurate geometry that leads to failed cross-agent data association or inconsistent scale in the final map.
Figures




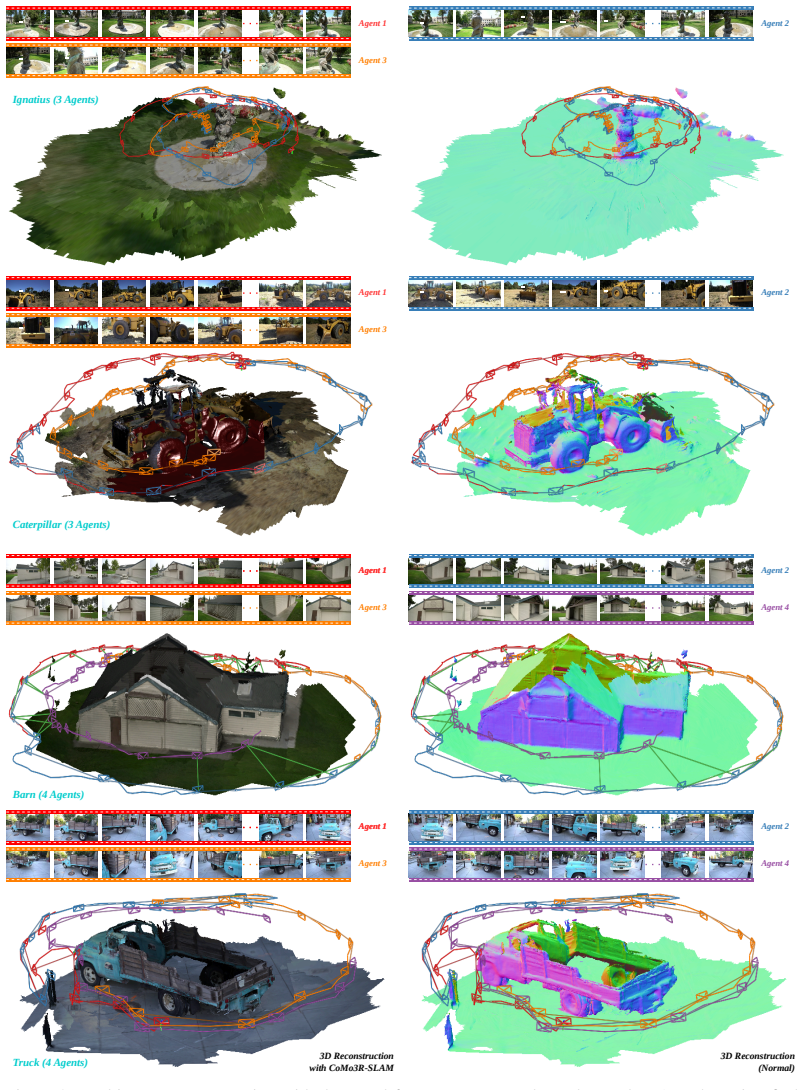
read the original abstract
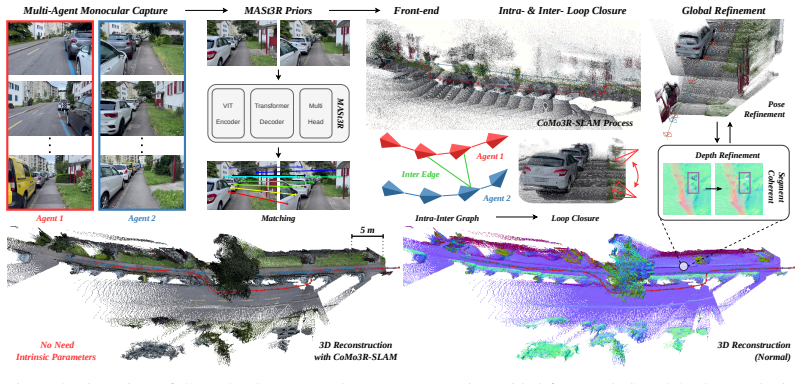
Collaborative dense SLAM is essential for multi-robot teams to achieve scalable and consistent 3D perception across large-scale outdoor environments. Existing systems typically depend on depth sensors, incurring significant payload, power, and calibration costs. Monocular RGB cameras are a lightweight alternative, but collaborative monocular dense SLAM remains difficult due to scale ambiguity, unreliable inter-agent data association, especially in outdoor scenes where low overlap and repetitive structures make traditional feature matching unreliable, motivating robust geometric information. We propose CoMo3R-SLAM, the first collaborative monocular dense RGB SLAM system that leverages robust learned feed-forward 3D reconstruction priors for outdoor multi-agent mapping. Each agent runs a prior-guided front-end for real-time tracking and local dense fusion, while a coordinator performs dense pointmap matching for cross-agent verification, closed-form Sim(3) gauge synchronization, and GPU-accelerated global bundle adjustment with segment-level depth optimization. Requiring neither depth sensors nor parametric intrinsics, our system produces robust cross-agent constraints and globally consistent metric maps from monocular RGB alone. On Tanks and Temples and Waymo sequences, CoMo3R-SLAM achieves the best ATE on three of four Tanks and Temples scenes and competitive Waymo accuracy, matching or exceeding state-of-the-art RGB-D methods while running online at 8 FPS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CoMo3R-SLAM, a collaborative monocular dense RGB SLAM system for outdoor multi-agent mapping. Each agent runs a prior-guided front-end for real-time tracking and local dense fusion; a coordinator performs dense pointmap matching for cross-agent verification, closed-form Sim(3) gauge synchronization, and GPU-accelerated global bundle adjustment with segment-level depth optimization. The system requires neither depth sensors nor known intrinsics and claims to produce robust cross-agent constraints and globally consistent metric maps from monocular RGB alone. On Tanks and Temples and Waymo sequences it reports the best ATE on three of four Tanks and Temples scenes, competitive Waymo accuracy, and online operation at 8 FPS.
Significance. If the central claims hold after validation, the work would be significant for multi-robot perception: it demonstrates that learned feed-forward 3D priors can enable metric-scale collaborative dense mapping with only monocular cameras in large-scale outdoor scenes, addressing payload and calibration costs of depth sensors. The online 8 FPS performance and explicit handling of low-overlap repetitive-structure regimes are practical strengths.
major comments (3)
- [Abstract] Abstract: the claim of best ATE on three of four Tanks and Temples scenes is presented without error bars, standard deviations across runs, or ablation details, making it impossible to assess whether the reported gains over baselines are statistically meaningful or robust.
- [Abstract] Abstract: no derivation, equations, or algorithmic description is supplied for the closed-form Sim(3) synchronization step, which is load-bearing for the metric consistency claim across agents.
- [Abstract] Abstract / Methods: the central claim that learned feed-forward 3D reconstruction priors supply reliable geometry for cross-agent verification and scale recovery in low-overlap outdoor scenes is not supported by any independent quantification (e.g., pointmap error versus LiDAR ground truth under the exact conditions where traditional matching fails); any systematic bias in the priors would directly undermine the Sim(3) constraints and global BA.
minor comments (1)
- [Abstract] Abstract: the statement 'matching or exceeding state-of-the-art RGB-D methods' would be strengthened by explicit citations to the specific RGB-D baselines being compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions to strengthen the manuscript while maintaining scientific accuracy.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of best ATE on three of four Tanks and Temples scenes is presented without error bars, standard deviations across runs, or ablation details, making it impossible to assess whether the reported gains over baselines are statistically meaningful or robust.
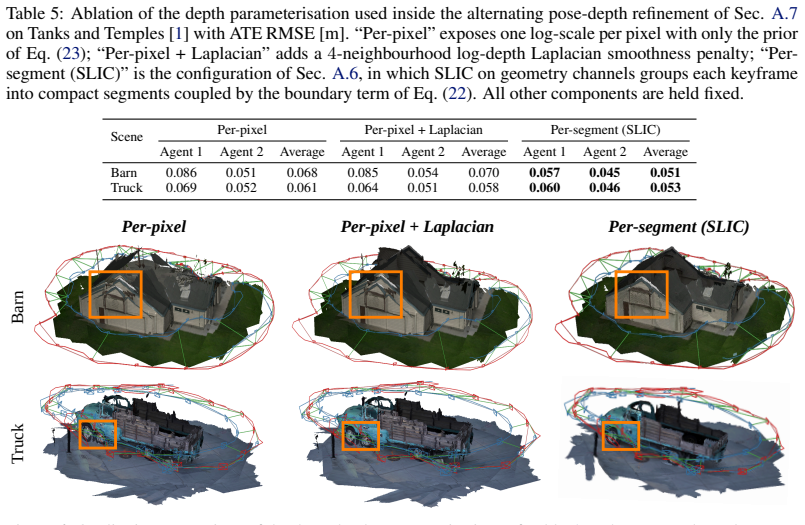
Authors: We agree that error bars and standard deviations would improve assessment of robustness. The reported ATE values are from single runs, consistent with much of the SLAM literature, but we will rerun experiments with varied initializations on the Tanks and Temples sequences, report means and standard deviations, and expand ablation details on the priors' contribution in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: no derivation, equations, or algorithmic description is supplied for the closed-form Sim(3) synchronization step, which is load-bearing for the metric consistency claim across agents.
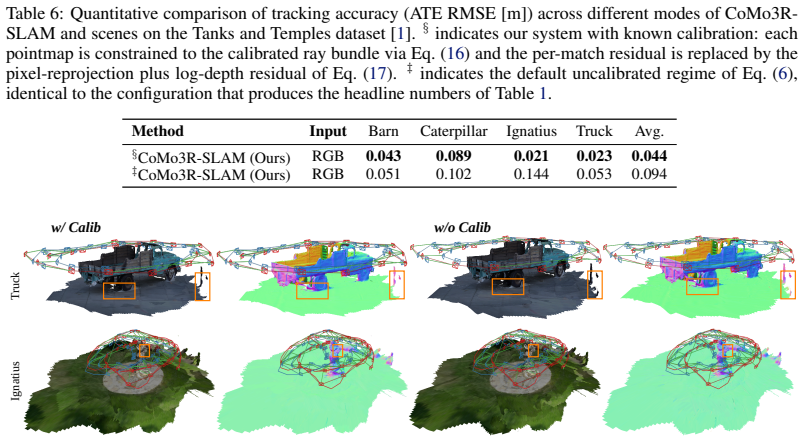
Authors: The closed-form Sim(3) synchronization is derived in Section 3.2 using pointmap correspondences to solve the similarity transformation via a closed-form least-squares formulation. We will add a brief summary of the key equations and a pointer to Section 3.2 directly in the abstract to make the metric consistency claim more self-contained. revision: partial
-
Referee: [Abstract] Abstract / Methods: the central claim that learned feed-forward 3D reconstruction priors supply reliable geometry for cross-agent verification and scale recovery in low-overlap outdoor scenes is not supported by any independent quantification (e.g., pointmap error versus LiDAR ground truth under the exact conditions where traditional matching fails); any systematic bias in the priors would directly undermine the Sim(3) constraints and global BA.
Authors: The end-to-end ATE results on challenging low-overlap scenes provide indirect support for the priors' utility, as the system outperforms baselines that rely on traditional matching. Direct independent pointmap error quantification against LiDAR ground truth in failure regimes of traditional methods is not present in the current experiments. We will add a limitations discussion on potential prior biases and their impact on Sim(3) constraints. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The abstract and system description present an architecture that applies external learned feed-forward 3D reconstruction priors to front-end tracking, dense pointmap matching, Sim(3) synchronization, and global BA. No equations, fitted parameters, or self-citations are shown that would make any claimed output (cross-agent constraints, metric maps, ATE scores) equivalent to the inputs by construction. The performance claims rest on benchmark results (Tanks and Temples, Waymo) that are independent of any internal fitting loop described here, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Knapitsch, J
A. Knapitsch, J. Park, Q.-Y . Zhou, and V . Koltun. Tanks and temples: Benchmarking large- scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
2017
-
[2]
P. Schmuck, T. Ziegler, M. Karrer, J. Perraudin, and M. Chli. Covins: Visual-inertial slam for centralized collaboration.arXiv preprint arXiv:2108.05756, 2021
-
[3]
Y . Tian, Y . Chang, F. H. Arias, C. Nieto-Granda, J. P. How, and L. Carlone. Kimera-multi: Robust, distributed, dense metric-semantic slam for multi-robot systems.IEEE transactions on robotics, 38(4), 2022
2022
-
[4]
Yugay, T
V . Yugay, T. Gevers, and M. R. Oswald. Magic-slam: Multi-agent gaussian globally consistent slam. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6741–6750, 2025
2025
-
[5]
T. Deng, G. Shen, C. Xun, S. Yuan, T. Jin, H. Shen, Y . Wang, J. Wang, H. Wang, D. Wang, et al. Mne-slam: Multi-agent neural slam for mobile robots. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1485–1494, 2025
2025
-
[6]
J. Hu, M. Mao, H. Bao, G. Zhang, and Z. Cui. Cp-slam: Collaborative neural point-based slam system.Advances in Neural Information Processing Systems, 36:39429–39442, 2023
2023
-
[7]
X. Xu, F. Xue, S. Zhao, Y . Pan, S. Scherer, and X. Huang. Mac-ego3d: Multi-agent gaussian consensus for real-time collaborative ego-motion and photorealistic 3d reconstruction. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 854–863, 2025
2025
-
[8]
L. Chen, Y . Su, J. Wang, P. Han, Z. Xia, S. Bu, K. Li, B. Hu, S. Meng, and G. Wang. Coma- slam: Collaborative multi-agent gaussian slam with geometric consistency. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2922–2929, 2026
2026
- [9]
-
[10]
Thomas, A
A. Thomas, A. Sonawalla, A. Rose, and J. P. How. Grand-slam: Local optimization for globally consistent large-scale multi-agent gaussian slam.IEEE Robotics and Automation Letters, 2025
2025
-
[11]
Schmuck and M
P. Schmuck and M. Chli. Ccm-slam: Robust and efficient centralized collaborative monocular simultaneous localization and mapping for robotic teams.Journal of Field Robotics, 36(4): 763–781, 2019
2019
-
[12]
Lipson and J
L. Lipson and J. Deng. Multi-session slam with differentiable wide-baseline pose optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19626–19635, 2024
2024
-
[13]
Y . Zhou and H. Wu. Multi-agent monocular dense slam with 3d reconstruction priors.arXiv preprint arXiv:2511.19031, 2025
-
[14]
Y . Li, P. Ye, and Q. Jia. Mang-slam: Multi-agent neural submap and gaussian representation for dense mapping.IEEE Robotics and Automation Letters, 11(2):2242–2249, 2025
2025
-
[15]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[16]
Leroy, Y
V . Leroy, Y . Cabon, and J. Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024. 10
2024
-
[17]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual ge- ometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[18]
Murai, E
R. Murai, E. Dexheimer, and A. J. Davison. Mast3r-slam: Real-time dense slam with 3d recon- struction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025
2025
-
[19]
Maggio, H
D. Maggio, H. Lim, and L. Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.Advances in Neural Information Processing Systems, 38:129839–129867, 2026
2026
-
[20]
Lajoie, B
P.-Y . Lajoie, B. Ramtoula, Y . Chang, L. Carlone, and G. Beltrame. Door-slam: Distributed, online, and outlier resilient slam for robotic teams.IEEE Robotics and Automation Letters, 5 (2):1656–1663, 2020
2020
-
[21]
Lajoie and G
P.-Y . Lajoie and G. Beltrame. Swarm-slam: Sparse decentralized collaborative simultaneous localization and mapping framework for multi-robot systems.IEEE Robotics and Automation Letters, 9(1):475–482, 2023
2023
- [22]
-
[23]
J. Yu, T. Chen, and M. Schwager. Hammer: heterogeneous, multi-robot semantic gaussian splatting.IEEE Robotics and Automation Letters, 2025
2025
-
[24]
Z. Cao, Q. Shao, S. Zhai, J. Zhang, A. Nguyen, and B. Huang. Mags-slam: Monocular multi- agent gaussian splatting slam for geometrically and photometrically consistent reconstruction. arXiv preprint arXiv:2605.10760, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse. Monoslam: Real-time single cam- era slam.IEEE transactions on pattern analysis and machine intelligence, 29(6):1052–1067, 2007
2007
-
[26]
Campos, R
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard ´os. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
2021
-
[27]
Engel, T
J. Engel, T. Sch ¨ops, and D. Cremers. Lsd-slam: Large-scale direct monocular slam. InEuro- pean conference on computer vision, pages 834–849. Springer, 2014
2014
-
[28]
Engel, V
J. Engel, V . Koltun, and D. Cremers. Direct sparse odometry.IEEE transactions on pattern analysis and machine intelligence, 40(3):611–625, 2017
2017
-
[29]
R. A. Newcombe, S. J. Lovegrove, and A. J. Davison. Dtam: Dense tracking and mapping in real-time. In2011 international conference on computer vision, pages 2320–2327. IEEE, 2011
2011
-
[30]
Teed and J
Z. Teed and J. Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Advances in neural information processing systems, 34:16558–16569, 2021
2021
-
[31]
Lipson, Z
L. Lipson, Z. Teed, and J. Deng. Deep patch visual slam. InEuropean Conference on Computer Vision, pages 424–440. Springer, 2024
2024
-
[32]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[33]
Sucar, S
E. Sucar, S. Liu, J. Ortiz, and A. J. Davison. imap: Implicit mapping and positioning in real- time. InProceedings of the IEEE/CVF international conference on computer vision, pages 6229–6238, 2021. 11
2021
-
[34]
Z. Zhu, S. Peng, V . Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, and M. Pollefeys. Nice- slam: Neural implicit scalable encoding for slam. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12786–12796, 2022
2022
-
[35]
Z. Zhu, S. Peng, V . Larsson, Z. Cui, M. R. Oswald, A. Geiger, and M. Pollefeys. Nicer-slam: Neural implicit scene encoding for rgb slam. In2024 International Conference on 3D Vision (3DV), pages 42–52. IEEE, 2024
2024
-
[36]
M. M. Johari, C. Carta, and F. Fleuret. Eslam: Efficient dense slam system based on hybrid rep- resentation of signed distance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17408–17419, 2023
2023
-
[37]
Sandstr ¨om, Y
E. Sandstr ¨om, Y . Li, L. Van Gool, and M. R. Oswald. Point-slam: Dense neural point cloud- based slam. InProceedings of the IEEE/CVF international conference on computer vision, pages 18433–18444, 2023
2023
-
[38]
L. Liso, E. Sandstr ¨om, V . Yugay, L. Van Gool, and M. R. Oswald. Loopy-slam: Dense neural slam with loop closures. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20363–20373, 2024
2024
-
[39]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[40]
Keetha, J
N. Keetha, J. Karhade, K. M. Jatavallabhula, G. Yang, S. Scherer, D. Ramanan, and J. Luiten. Splatam: Splat track & map 3d gaussians for dense rgb-d slam. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21357–21366, 2024
2024
-
[41]
Sandstr ¨om, G
E. Sandstr ¨om, G. Zhang, K. Tateno, M. Oechsle, M. Niemeyer, Y . Zhang, M. Patel, L. Van Gool, M. Oswald, and F. Tombari. Splat-slam: Globally optimized rgb-only slam with 3d gaussians. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1680–1691, 2025
2025
-
[42]
Zhang, Q
W. Zhang, Q. Cheng, D. Skuddis, N. Zeller, D. Cremers, and N. Haala. Hi-slam2: Geometry- aware gaussian slam for fast monocular scene reconstruction.IEEE Transactions on Robotics, 41:6478–6493, 2025
2025
-
[43]
M. Li, S. Liu, H. Zhou, G. Zhu, N. Cheng, T. Deng, and H. Wang. Sgs-slam: Semantic gaussian splatting for neural dense slam. InEuropean Conference on Computer Vision, pages 163–179. Springer, 2024
2024
-
[44]
Gaussian-slam: Photo-realistic dense slam with gaussian splatting,
V . Yugay, Y . Li, T. Gevers, and M. R. Oswald. Gaussian-slam: Photo-realistic dense slam with gaussian splatting.arXiv preprint arXiv:2312.10070, 2023
-
[45]
Matsuki, R
H. Matsuki, R. Murai, P. H. Kelly, and A. J. Davison. Gaussian splatting slam. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18039–18048, 2024
2024
-
[46]
Z. Peng, T. Shao, Y . Liu, J. Zhou, Y . Yang, J. Wang, and K. Zhou. Rtg-slam: Real-time 3d reconstruction at scale using gaussian splatting. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
- [47]
-
[48]
B. P. Duisterhof, L. Zust, P. Weinzaepfel, V . Leroy, Y . Cabon, and J. Revaud. Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In2025 International Conference on 3D Vision (3DV), pages 1–10. IEEE, 2025. 12
2025
-
[49]
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[50]
Y . Liu, S. Dong, S. Wang, Y . Yin, Y . Yang, Q. Fan, and B. Chen. Slam3r: Real-time dense scene reconstruction from monocular rgb videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16651–16662, 2025
2025
-
[51]
Wang and L
H. Wang and L. Agapito. 3d reconstruction with spatial memory. In2025 International Con- ference on 3D Vision (3DV), pages 78–89. IEEE, 2025
2025
-
[52]
Teed and J
Z. Teed and J. Deng. Tangent space backpropagation for 3d transformation groups. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10338– 10347, 2021
2021
-
[53]
Tolias, T
G. Tolias, T. Jenicek, and O. Chum. Learning and aggregating deep local descriptors for instance-level recognition. InEuropean Conference on Computer Vision, pages 460–477. Springer, 2020
2020
-
[54]
Tolias, Y
G. Tolias, Y . Avrithis, and H. J´egou. To aggregate or not to aggregate: Selective match kernels for image search. InProceedings of the IEEE international conference on computer vision, pages 1401–1408, 2013
2013
-
[55]
S. Umeyama. Least-squares estimation of transformation parameters between two point pat- terns.IEEE Transactions on pattern analysis and machine intelligence, 13(4):376–380, 1991
1991
-
[56]
Achanta, A
R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. S¨usstrunk. Slic superpixels compared to state-of-the-art superpixel methods.IEEE transactions on pattern analysis and machine intelligence, 34(11):2274–2282, 2012
2012
-
[57]
Concha and J
A. Concha and J. Civera. Dpptam: Dense piecewise planar tracking and mapping from a monocular sequence. In2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5686–5693. IEEE, 2015
2015
-
[58]
Mazur, G
K. Mazur, G. Bae, and A. J. Davison. Superprimitive: Scene reconstruction at a primitive level. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4979–4989, 2024
2024
-
[59]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 13 Appendix / Supplemental Materials 3D Reconstruction (Norma...
2020
-
[60]
(5) (depths frozen) for at most100iterations; repeat up to5passes untilmax i∥∆tW Ci ∥2 <5mm
Run global pose LM-IRLS over Eq. (5) (depths frozen) for at most100iterations; repeat up to5passes untilmax i∥∆tW Ci ∥2 <5mm
-
[61]
w/ Loop Closure
Forr= 1, . . . , RwithR= 100: (a) build segments from each keyframe’s current canonical pointmap via Eq. (19); (b) refinesby Eq. (24) (poses frozen,10inner iterations); (c) write the updated ˆXback into the canonical pointmaps; (d) run a short pose pass (Eq. (5),50iterations) so the poses absorb the depth change; (e) broadcast the new global poses to all ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.