PrologMCP: A Standardized Prolog Tool Interface for LLM Agents
Pith reviewed 2026-06-27 04:23 UTC · model grok-4.3
The pith
Delegating inference to Prolog via a standardized MCP tool lets LLM agents match or exceed reasoning models on deductive tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PrologMCP provides a task-agnostic, compact tool interface to a stateful Prolog server with structured error reporting and per-session isolation, turning autoformalization followed by symbolic execution into a reliable primitive that achieves near-perfect accuracy on deductive benchmarks where natural-language reasoning in LLMs drops.
What carries the argument
The Model Context Protocol tool interface to a stateful Prolog interpreter that supports the translate-run-inspect-repair cycle for inference delegation.
If this is right
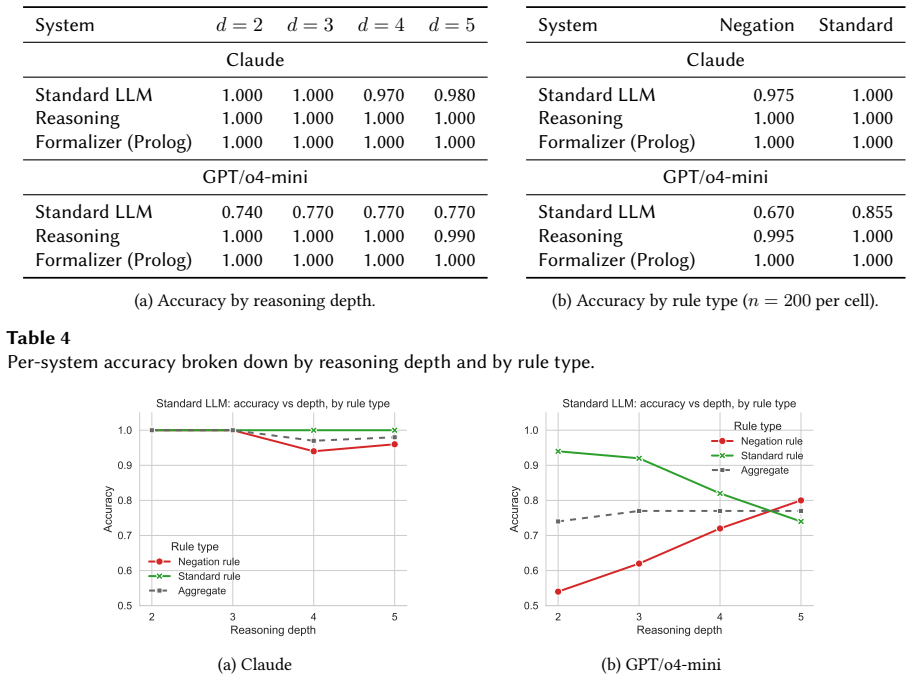
- Agents reach 1.00 accuracy on general deductive tasks versus 0.762 for standard models like GPT-4.1.
- Accuracy on challenging deductive subsets stays near 1.00 while reasoning LLMs fall to 0.94-0.95.
- The same interface works across tasks without bespoke integrations.
- Inference becomes directly inspectable and repairable through Prolog interaction.
Where Pith is reading between the lines
- Similar standardized interfaces could be created for other solvers such as SAT or first-order theorem provers.
- The separation of translation and execution may reduce error accumulation on problems requiring many inference steps.
- The method could be tested on planning or verification tasks outside the current benchmarks.
Load-bearing premise
The formalizer agent can translate natural-language problems into correct Prolog programs that preserve original meaning without introducing errors.
What would settle it
A test where the formalizer produces Prolog programs that return wrong answers on problems the pure LLM models solve correctly, driving overall accuracy below the LLM baselines.
Figures

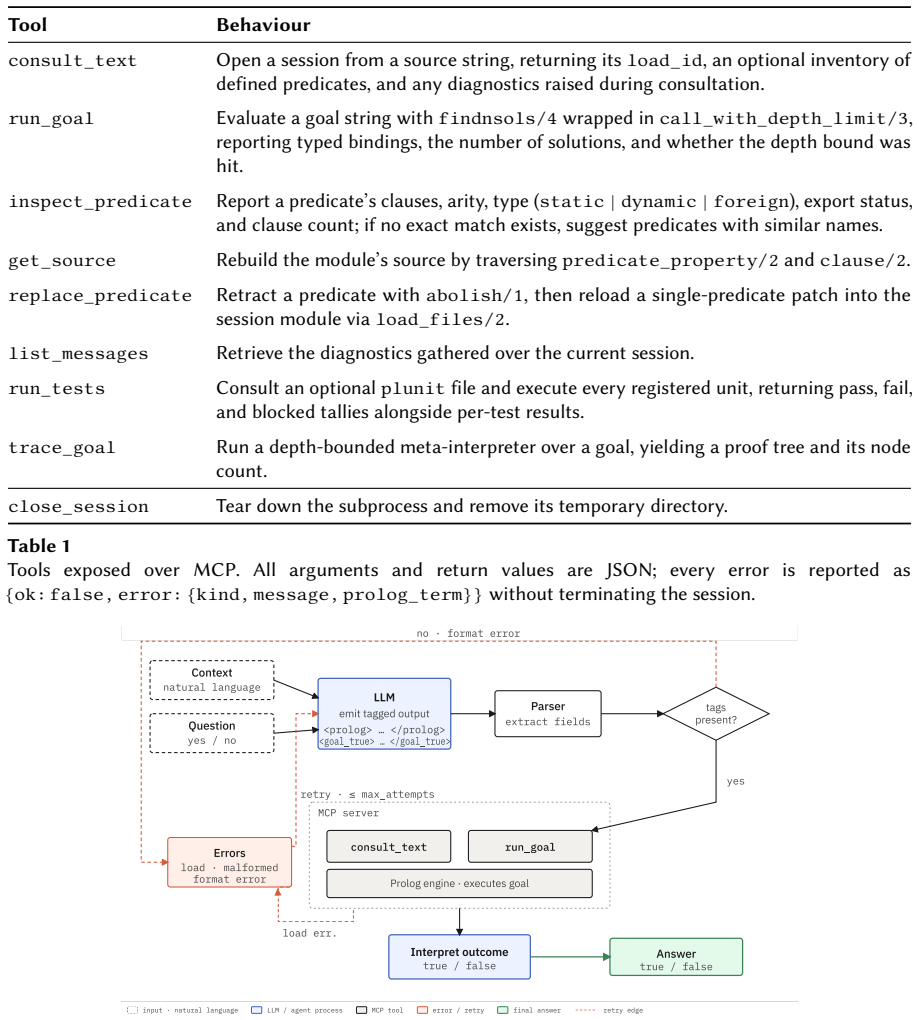
read the original abstract
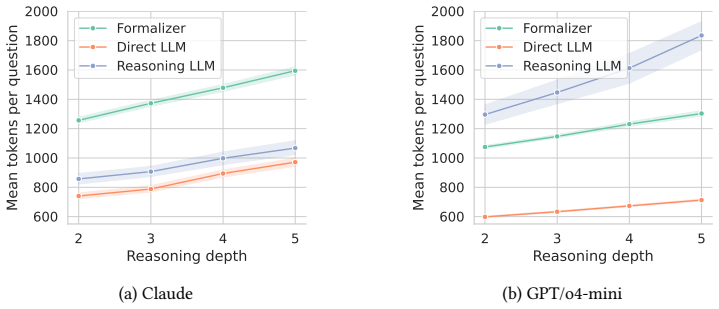
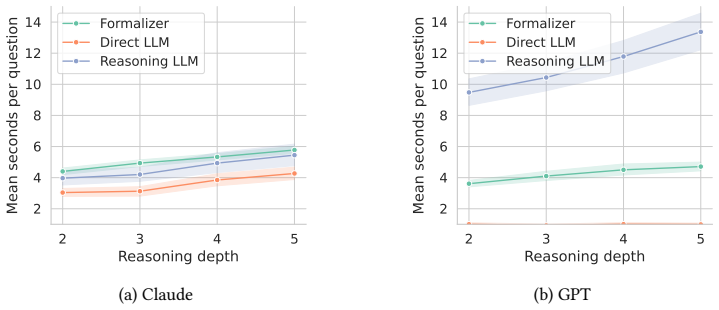
Frontier reasoning-tuned language models still fail on deductive tasks at depth, and the cost of improved performance through extended internal reasoning scales poorly. Symbolic delegation offers a complementary route: a language model translates the problem, while a solver performs the inference. However, current autoformalization pipelines for logic programming are typically bespoke integrations tied to particular tasks or agents. We introduce PrologMCP, a task-agnostic, open-source server that exposes Prolog as a stateful tool through the Model Context Protocol (MCP). Its compact tool interface, structured error reporting, and per-session isolation make the translate-run-inspect-repair loop a reusable primitive for MCP-capable agents. We evaluate a formalizer agent enhanced with PrologMCP against standard and reasoning LLMs (Claude Sonnet 4.6, GPT-4.1, and o4-mini) on two subsets of PARARULE-Plus: a general-purpose sample and a more challenging one targeting a specific failure mode of natural-language reasoning. On the general sample, the formalizer matches or exceeds reasoning LLMs (accuracy 1.00 vs.\ 1.00 / 0.998), with the largest gains over standard models (0.762 for GPT-4.1). On the challenging subset, the formalizer remains near-perfect (1.00 / 0.99) while reasoning LLMs drop to 0.95 / 0.94. These results suggest that delegating inference to Prolog via MCP is a robust and inspectable alternative to extended natural-language reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrologMCP, a task-agnostic open-source server that exposes Prolog as a stateful tool via the Model Context Protocol (MCP), enabling LLM agents to perform a translate-run-inspect-repair loop for delegating deductive inference. It evaluates a formalizer agent using this interface against standard and reasoning LLMs (Claude Sonnet 4.6, GPT-4.1, o4-mini) on general and challenging subsets of PARARULE-Plus, reporting accuracies of 1.00 (general) and 1.00/0.99 (challenging) for the formalizer versus lower or comparable figures for the LLMs, and claims that Prolog delegation via MCP offers a robust, inspectable alternative to extended natural-language reasoning.
Significance. If the central empirical claim holds, the work supplies a reusable, standardized primitive for symbolic delegation that addresses scalability issues in pure neural reasoning on deductive tasks; the open-source release and MCP compatibility are concrete strengths for reproducibility and integration. The reported accuracy differentials on the challenging subset provide a falsifiable, externally benchmarked comparison that strengthens the case for hybrid approaches.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation description: the reported accuracies (1.00 on general sample; 1.00/0.99 on challenging subset) are presented as evidence for successful Prolog delegation, yet no independent verification of formalizer correctness is supplied—no error rate on translation, no sample of generated Prolog programs, and no comparison against gold-standard formalizations. This directly affects attribution of the performance edge to the solver rather than the LLM's own reasoning during formalization or repair.
- [Evaluation] Evaluation description: the paper provides no details on data exclusion criteria, exact prompt engineering for the formalizer, or statistical significance testing of the accuracy differences, leaving open whether the near-perfect scores on the challenging subset (targeting a specific NL reasoning failure mode) could be inflated by benchmark-specific artifacts or unmeasured translation errors.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical note on the size of the evaluated subsets to allow immediate assessment of result robustness.
- [Abstract] Minor notation inconsistency: the abstract lists three LLMs but reports only two accuracy figures for the reasoning models on the challenging subset; clarify whether the third model was omitted or grouped.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and abstract sections. We address each major comment below, indicating where revisions will be made to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation description: the reported accuracies (1.00 on general sample; 1.00/0.99 on challenging subset) are presented as evidence for successful Prolog delegation, yet no independent verification of formalizer correctness is supplied—no error rate on translation, no sample of generated Prolog programs, and no comparison against gold-standard formalizations. This directly affects attribution of the performance edge to the solver rather than the LLM's own reasoning during formalization or repair.
Authors: We acknowledge the absence of explicit translation error rates or gold-standard comparisons in the current manuscript. The evaluation is designed to measure end-to-end accuracy on PARARULE-Plus to demonstrate the practical utility of the MCP interface for delegation. The largest gains appear on the challenging subset where pure LLM reasoning degrades, which is consistent with the solver contributing to the result rather than the formalizer alone. To strengthen the paper, we will add representative examples of generated Prolog programs and a brief discussion of the translate-run-inspect-repair loop. However, PARARULE-Plus provides only natural-language problems and answers, not gold Prolog formalizations, so direct comparison is not feasible without creating new annotations. revision: partial
-
Referee: [Evaluation] Evaluation description: the paper provides no details on data exclusion criteria, exact prompt engineering for the formalizer, or statistical significance testing of the accuracy differences, leaving open whether the near-perfect scores on the challenging subset (targeting a specific NL reasoning failure mode) could be inflated by benchmark-specific artifacts or unmeasured translation errors.
Authors: We will expand the evaluation section to include the data sampling and exclusion criteria used for both subsets, as well as the exact prompts provided to the formalizer agent. On statistical significance, the reported figures are already near ceiling; we can add a note explaining why formal tests were not applied or include them if the editor prefers. The challenging subset targets a documented natural-language reasoning failure mode from prior work on PARARULE-Plus, and results are presented separately for general and challenging cases to allow readers to assess potential artifacts. revision: yes
- Direct comparison of formalizations against gold-standard Prolog programs, as no such annotations exist in the PARARULE-Plus benchmark.
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential steps
full rationale
The paper introduces a tool interface (PrologMCP) and reports direct accuracy comparisons on PARARULE-Plus subsets against external LLMs. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described evaluation. The central claim rests on benchmark results rather than any reduction of outputs to the method's own definitions or prior self-citations. The formalizer's translation quality is an unverified assumption, but that is a correctness concern, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Model Context Protocol provides a stable, stateful mechanism for exposing external tools to LLM agents.
Reference graph
Works this paper leans on
-
[1]
McCarthy, Programs with Common Sense, Technical Report, USA, 1960
J. McCarthy, Programs with Common Sense, Technical Report, USA, 1960
1960
-
[2]
Kowalski, Predicate logic as a programming language, in: IFIP Congress, 1974, pp
R. Kowalski, Predicate logic as a programming language, in: IFIP Congress, 1974, pp. 569–574
1974
-
[3]
Newell, H
A. Newell, H. A. Simon, Computer science as empirical inquiry: Symbols and search, Communica- tions of the ACM 19 (1976) 113–126
1976
-
[4]
B. Y. Lin, R. Le Bras, K. Richardson, A. Sabharwal, R. Poovendran, P. Clark, Y. Choi, Zebralogic: On the scaling limits of llms for logical reasoning, in: International Conference on Machine Learning, PMLR, 2025, pp. 37889–37905
2025
-
[5]
Kazemi, B
M. Kazemi, B. Fatemi, H. Bansal, J. Palowitch, C. Anastasiou, S. V. Mehta, L. K. Jain, V. Aglietti, D. Jindal, Y. P. Chen, et al., Big-bench extra hard, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26473–26501
2025
-
[6]
Dziri, X
N. Dziri, X. Lu, M. Sclar, X. L. Li, L. Jiang, B. Y. Lin, S. Welleck, P. West, C. Bhagavatula, R. Le Bras, et al., Faith and fate: Limits of transformers on compositionality, Advances in neural information processing systems 36 (2023) 70293–70332
2023
-
[7]
S. I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, M. Farajtabar, GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview. net/forum?id=AjXkRZIvjB
2025
-
[8]
Shojaee, I
P. Shojaee, I. Mirzadeh, M. Horton, S. Bengio, M. Farajtabar, et al., The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, Advances in Neural Information Processing Systems 38 (2026) 108018–108059
2026
-
[9]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, T. Scialom, Toolformer: Language models can teach themselves to use tools, Advances in neural information processing systems 36 (2023) 68539–68551
2023
-
[10]
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, G. Neubig, Pal: Program-aided language models, in: International conference on machine learning, PMLR, 2023, pp. 10764–10799
2023
-
[11]
Y. Wu, A. Q. Jiang, W. Li, M. Rabe, C. Staats, M. Jamnik, C. Szegedy, Autoformal- ization with Large Language Models, Advances in Neural Information Processing Sys- tems 35 (2022) 32353–32368. URL: https://proceedings.neurips.cc/paper_files/paper/2022/hash/ d0c6bc641a56bebee9d985b937307367-Abstract-Conference.html
2022
-
[12]
Towards a Common Framework for Autoformalization , booktitle =
A. Mensfelt, D. Tena Cucala, S. Franco, A. Koutsoukou-Argyraki, V. Trencsenyi, K. Stathis, Towards a common framework for autoformalization, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 2026, pp. 40971–40980. doi:10.1609/aaai.v40i48.42132
-
[13]
N. Borazjanizadeh, S. T. Piantadosi, Reliable reasoning beyond natural language, arXiv preprint arXiv:2407.11373 (2024)
arXiv 2024
-
[14]
A. Mensfelt, K. Stathis, V. Tencsenyi, Generative agents for multi-agent autoformalization of interaction scenarios, in: Proceedings of the 28th European Conference on Artificial Intelligence (ECAI 2025), volume 413 ofFrontiers in Artificial Intelligence and Applications, IOS Press, 2025, pp. 3759–3766. doi:10.3233/FAIA251256
-
[15]
X. Yang, B. Chen, Y.-C. Tam, Arithmetic reasoning with llm: Prolog generation & permutation, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), 2024, pp. 699–710
2024
-
[16]
X. Tan, Y. Deng, X. Qiu, W. Xu, C. Qu, W. Chu, Y. Xu, Y. Qi, Thought-like-pro: Enhancing reasoning of large language models through self-driven prolog-based chain-of-thought, arXiv preprint arXiv:2407.14562 (2024)
arXiv 2024
-
[17]
N. Mellgren, P. Schneider-Kamp, L. G. Poech, Training language models to use prolog as a tool, arXiv preprint arXiv:2512.07407 (2025)
Pith/arXiv arXiv 2025
-
[18]
P. Zunjare, M. Hsiao, Neuroprolog: Multi-task fine-tuning for neurosymbolic mathematical reasoning via the cocktail effect, arXiv preprint arXiv:2603.02504 (2026)
arXiv 2026
-
[19]
F. He, Z. Chen, X. Liang, T. Ma, Y. Qiu, S. Wu, J. Yan, Protoreasoning: Prototypes as the foundation for generalizable reasoning in llms, arXiv preprint arXiv:2506.15211 (2025)
arXiv 2025
-
[20]
GitHub repository
adamrybinski, Prolog-MCP Server, https://github.com/adamrybinski/prolog-mcp, 2025. GitHub repository. Accessed 2026-06-19
2025
-
[21]
GitHub repository
umuro, prolog-mcp, https://github.com/umuro/prolog-mcp, 2025. GitHub repository. Accessed 2026-06-19
2025
-
[22]
GitHub repos- itory and PyPI package
rikarazome, prolog-reasoner, https://github.com/rikarazome/prolog-reasoner, 2026. GitHub repos- itory and PyPI package. Accessed 2026-06-19
2026
-
[23]
GitHub repository
vpursuit, MCP Ecosystem, https://github.com/vpursuit/model-context-lab, 2025. GitHub repository. Accessed 2026-06-19
2025
-
[24]
Q. Bao, A. Y. Peng, T. Hartill, N. Tan, Z. Deng, M. Witbrock, J. Liu, Multi-step deductive reasoning over natural language: An empirical study on out-of-distribution generalisation, arXiv preprint arXiv:2207.14000 (2022)
arXiv 2022
-
[25]
Körner, M
P. Körner, M. Leuschel, J. Barbosa, V. Santos Costa, V. Dahl, M. V. Hermenegildo, J. F. Morales, J. Wielemaker, D. Diaz, S. Abreu, G. Ciatto, Fifty years of prolog and beyond, Theory and Practice of Logic Programming (2022)
2022
-
[26]
Wielemaker, T
J. Wielemaker, T. Schrijvers, M. Triska, T. Lager, Swi-prolog, Theory and Practice of Logic Programming 12 (2012) 67–96
2012
-
[27]
R. A. Kowalski, D. Kuehner, Linear resolution with selection function, Artificial Intelligence 2 (1971) 227–260
1971
-
[28]
K. L. Clark, Negation as failure, in: H. Gallaire, J. Minker (Eds.), Logic and Data Bases, Springer, 1978, pp. 293–322
1978
-
[29]
Anthropic, Introducing the Model Context Protocol, https://www.anthropic.com/news/ model-context-protocol, 2024
2024
-
[30]
X. Hou, Y. Zhao, S. Wang, H. Wang, Model Context Protocol (MCP): Landscape, security threats, and future research directions, ACM Transactions on Software Engineering and Methodology (2026)
2026
-
[31]
S. Szeider, Bridging language models and symbolic solvers via the model context protocol, in: 28th International Conference on Theory and Applications of Satisfiability Testing (SAT 2025), Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2025, pp. 30–1
2025
-
[32]
Clark, O
P. Clark, O. Tafjord, K. Richardson, Transformers as soft reasoners over language, in: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-PRICAI 2020), International Joint Conferences on Artificial Intelligence Organization, California, 2020
2020
-
[33]
Abiteboul, R
S. Abiteboul, R. Hull, V. Vianu, Foundations of databases, volume 8, Addison-Wesley Reading, 1995
1995
-
[34]
type": "object
K. R. Apt, H. A. Blair, A. Walker, Towards a theory of declarative knowledge, in: J. Minker (Ed.), Foundations of Deductive Databases and Logic Programming, Morgan Kaufmann, 1988, pp. 89–148. A. PARARULE-Plus Example instance: non-negation, people Instance ID:NonNegationRule-D2-11112 Context.Charlie is strong. Charlie is high. Charlie is huge. Bob is thin...
1988
-
[35]
Valid SWI-Prolog source code that captures every fact and rule
-
[36]
if someone is not high then they are dull
A single query goal: - goal_true -- SUCCEEDS when the answer is TRUE If goal_true fails, the answer is FALSE (closed-world assumption: anything not provable from the given facts and rules is false). SWI-Prolog conventions: - All atom names are lowercase and use underscores for spaces: ‘anne‘, ‘is_kind‘, ‘likes_fish‘ - Facts: ‘kind(anne).‘ ‘likes(bob, alic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.