Comparative Reasoning: Making an Audio Language Model Better at Comparing Emotions
Pith reviewed 2026-06-25 23:17 UTC · model grok-4.3
The pith
Conditioning audio language models on paired speech with reasoning traces improves emotion comparison using only 5% of conventional training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
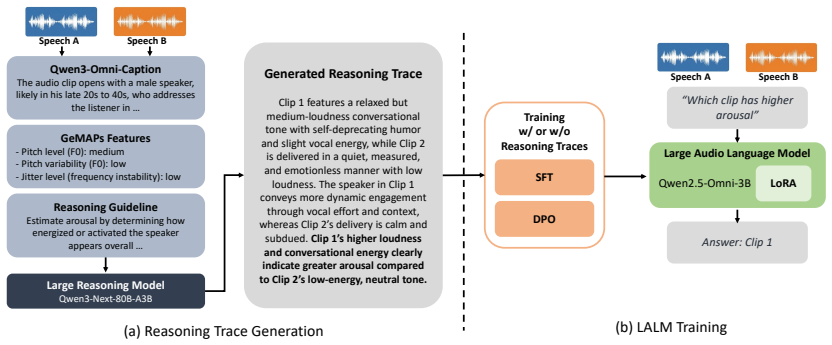
The reasoning-guided ordinal SER framework conditions an LALM on paired speech inputs. The model is trained using reasoning traces generated from both semantic audio descriptions and acoustic evidence derived from GeMAPS features, enabling interpretable comparative decisions. Beyond direct supervision, direct preference optimization encourages stronger separation for emotional differences. Experiments show that the proposed framework improves preference prediction while requiring only 5% of the training data used by conventional ordinal SER systems.
What carries the argument
The reasoning-guided ordinal SER framework that conditions an LALM on paired speech inputs and trains it with reasoning traces from semantic audio descriptions and GeMAPS features.
If this is right
- The model produces interpretable comparative decisions on emotional dimensions.
- Direct preference optimization yields stronger separation between utterances differing in arousal, valence, or dominance.
- Preference prediction improves relative to conventional ordinal SER systems.
- Effective training occurs with only 5% of the data volume required by standard approaches.
Where Pith is reading between the lines
- The same conditioning approach may support comparative judgments on the non-emotional dimensions the paper lists, such as environmental or prosodic properties.
- Hybrid use of external acoustic features like GeMAPS alongside language-model reasoning could generalize to other audio tasks that benefit from limited-data regimes.
- The resulting interpretability of traces may allow users to inspect and correct specific failure modes in pairwise emotion comparisons.
Load-bearing premise
The reasoning traces generated from both semantic audio descriptions and acoustic evidence derived from GeMAPS features are accurate and sufficiently informative to enable the LALM to make reliable comparative decisions on emotional dimensions.
What would settle it
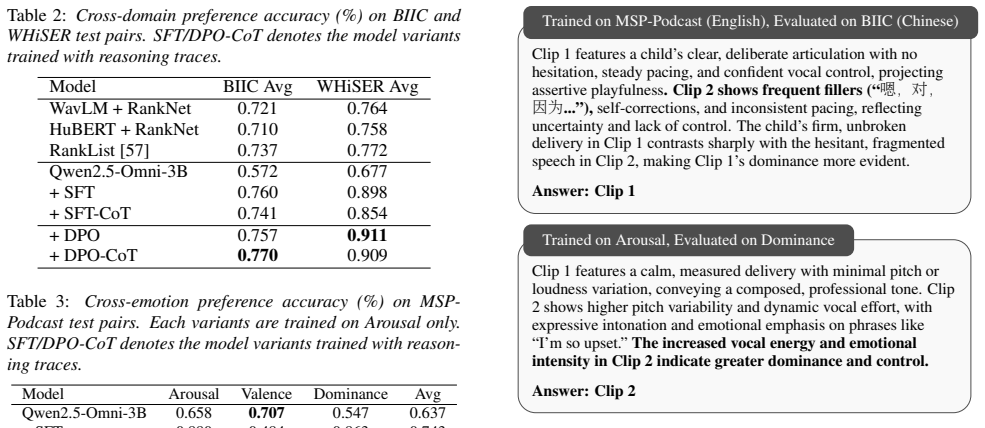
An experiment that replaces the generated reasoning traces with random or erroneous text and measures whether preference prediction accuracy falls back to or below the level of conventional ordinal SER baselines trained on the full dataset.
Figures
read the original abstract
Large audio-language models (LALMs) can reason about audio, yet it remains unclear whether they can perform comparative judgments between two speech signals along emotional, environmental, linguistic, prosodic, and interpersonal dimensions. We study this question in the context of speech emotion recognition (SER), where the model determines which utterance exhibits higher arousal, valence, or dominance. We introduce a reasoning-guided ordinal SER framework that conditions an LALM on paired speech inputs. The model is trained using reasoning traces generated from both semantic audio descriptions and acoustic evidence derived from GeMAPS features, enabling interpretable comparative decisions. Beyond direct supervision, we also employ direct preference optimization to encourage stronger separation for emotional differences. Experiments show that the proposed framework improves preference prediction while requiring only 5% of the training data used by conventional ordinal SER systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a reasoning-guided ordinal speech emotion recognition (SER) framework for large audio-language models (LALMs). The model is conditioned on paired speech inputs and trained on reasoning traces generated from semantic audio descriptions combined with acoustic evidence from GeMAPS features; direct preference optimization is additionally applied to encourage separation along emotional dimensions. The central empirical claim is that this yields improved preference prediction while using only 5% of the training data required by conventional ordinal SER systems.
Significance. If the reported data-efficiency gains hold after proper validation of the reasoning traces, the work would provide evidence that LALMs can acquire comparative emotional reasoning in a more sample-efficient and interpretable manner than standard supervised ordinal models, with potential implications for reducing annotation costs in affective computing.
major comments (3)
- [Abstract] Abstract and Experiments section: the claim that only 5% of conventional training data is required is presented without any description of the baseline ordinal SER systems, the exact data volumes used, statistical significance tests, error bars, or controls for post-hoc subset selection; this information is load-bearing for the data-efficiency conclusion.
- [Methods] Methods section (reasoning-trace generation): no quantitative validation of trace accuracy is reported (e.g., human agreement rates, consistency with ground-truth ordinal labels, or an ablation that removes trace content while retaining the same supervision volume); without such checks the performance gains cannot be confidently attributed to emergent comparative reasoning rather than high-quality synthetic supervision.
- [Experiments] Experiments section: the abstract states that traces are generated from both semantic descriptions and GeMAPS features, yet no ablation isolating the contribution of the acoustic (GeMAPS) component versus semantic-only traces is described; this is required to substantiate the role of acoustic evidence in the comparative decisions.
minor comments (2)
- [Abstract] The abstract lists environmental, linguistic, prosodic, and interpersonal dimensions as targets of comparison, yet the reported experiments focus exclusively on arousal, valence, and dominance; the scope of the empirical evaluation should be clarified.
- [Methods] Notation for the preference-optimization objective and the precise form of the reasoning traces should be introduced with equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that directly strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the claim that only 5% of conventional training data is required is presented without any description of the baseline ordinal SER systems, the exact data volumes used, statistical significance tests, error bars, or controls for post-hoc subset selection; this information is load-bearing for the data-efficiency conclusion.
Authors: We agree the data-efficiency claim requires fuller documentation. In the revised manuscript we will expand both the Abstract and Experiments section to describe the baseline ordinal SER systems, report the precise training data volumes (full conventional dataset size and the 5% subset actually used), include error bars across multiple runs, present statistical significance tests, and detail the subset selection procedure with controls against post-hoc bias. revision: yes
-
Referee: [Methods] Methods section (reasoning-trace generation): no quantitative validation of trace accuracy is reported (e.g., human agreement rates, consistency with ground-truth ordinal labels, or an ablation that removes trace content while retaining the same supervision volume); without such checks the performance gains cannot be confidently attributed to emergent comparative reasoning rather than high-quality synthetic supervision.
Authors: We acknowledge the absence of quantitative validation in the current version. We will add to the Methods section: human agreement rates on a sampled set of traces, consistency metrics against ground-truth ordinal labels, and an ablation that removes trace content while preserving equivalent supervision volume. These additions will allow readers to assess whether gains stem from comparative reasoning. revision: yes
-
Referee: [Experiments] Experiments section: the abstract states that traces are generated from both semantic descriptions and GeMAPS features, yet no ablation isolating the contribution of the acoustic (GeMAPS) component versus semantic-only traces is described; this is required to substantiate the role of acoustic evidence in the comparative decisions.
Authors: We agree an ablation isolating the GeMAPS component is necessary. We will add this experiment to the Experiments section, directly comparing semantic-only traces against traces that combine semantic descriptions with GeMAPS acoustic features, thereby quantifying the incremental contribution of the acoustic evidence. revision: yes
Circularity Check
No significant circularity; empirical claims rest on training procedure and experiments
full rationale
The paper presents a training framework for an LALM that conditions on paired audio inputs and reasoning traces derived from semantic descriptions plus GeMAPS acoustic features, followed by direct preference optimization. The reported improvement in preference prediction at 5% data volume is framed as an experimental outcome of this procedure. No equations, derivations, or self-referential definitions appear that would reduce any prediction to a fitted input or self-citation chain by construction. Any concerns about trace fidelity constitute a validation or correctness issue rather than circularity in a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GeMAPS features supply reliable acoustic evidence for generating useful reasoning traces about emotional dimensions
Reference graph
Works this paper leans on
-
[1]
Comparative Reasoning: Making an Audio Language Model Better at Comparing Emotions
Introduction Recent progress inlarge audio-language models(LALMs) has substantially advanced audio understanding across a wide range of domains, including speech, environmental sounds, music, and complex acoustic scenes [1–5]. Recent studies have fur- ther enhanced these models with reasoning capabilities through chain-of-thought(CoT) supervision [6, 7] a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Related Work Preference learning has been explored in SER well before the emergence of audio-language models. Early studies showed that humans are more consistent when comparing emotional in- tensities than when assigning absolute ratings, motivating ordi- nal supervision for emotion perception [24, 25, 31, 32]. Build- ing on this observation, learning-to...
-
[3]
The goal of the system is to determine the relative emotional attribute level between two speech sam- ples
Methodology Figure 1 presents an overview of the proposed reasoning-guided ordinal SER framework. The goal of the system is to determine the relative emotional attribute level between two speech sam- ples. Given two utterances, the model predicts which sample exhibits higher arousal, valence, or dominance. Instead of es- timating absolute attribute scores...
-
[4]
Experiments 4.1. Datasets and Label Preparation We conduct experiments primarily on the MSP-Podcast v2.0 corpus [48], which contains approximately 409 hours of speech annotated for the emotional attributes (arousal, valence, and dominance), primary and secondary categorical emotions. The dataset is partitioned into training, development, and test sets wit...
-
[5]
Conclusions We studied whether LALMs can compare emotional content across speech rather than only predict emotions independently. By formulating ordinal speech emotion recognition as a pair- wise decision task, we show that LALMs require task-specific adaptation but can perform reliable cross-audio comparison af- ter SFT and DPO, achieving strong data eff...
-
[6]
The research design, ex- periments, analysis, and conclusions were entirely developed by the authors, who are fully responsible for the content of this manuscript
Generative AI Use Disclosure Generative AI tools were used only to assist with minor lan- guage editing and stylistic polishing. The research design, ex- periments, analysis, and conclusions were entirely developed by the authors, who are fully responsible for the content of this manuscript
-
[8]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
T. Changli, Y . Wenyi, S. Guangzhi, C. Xianzhao, T. Tian, L. Wei, L. Lu, M. Zejun, and Z. Chao, “SALMONN: Towards generic hearing abilities for large language models,”arXiv:2310.13289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of the Associ- ation for Computational Linguistics: EMNLP 2023, 2023, pp. 15 757–15 773
2023
-
[10]
Emotion-llama: Multimodal emo- tion recognition and reasoning with instruction tuning,
Z. Cheng, Z.-Q. Cheng, J.-Y . He, K. Wang, Y . Lin, Z. Lian, X. Peng, and A. Hauptmann, “Emotion-llama: Multimodal emo- tion recognition and reasoning with instruction tuning,”Advances in Neural Information Processing Systems, vol. 37, pp. 110 805– 110 853, 2024
2024
-
[11]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S. gil Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” 2025. [Online]. Available: https://arxiv.org/abs/2507.08128
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information pro- cessing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[13]
Audio- reasoner: Improving reasoning capability in large audio language models,
X. Zhifei, M. Lin, Z. Liu, P. Wu, S. Yan, and C. Miao, “Audio- reasoner: Improving reasoning capability in large audio language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 23 840– 23 862
2025
-
[14]
Train- ing language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Train- ing language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[15]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural informa- tion processing systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the lim- its of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Omni-r1: Do you really need audio to fine- tune your audio llm?
A. Rouditchenko, S. Bhati, E. Araujo, S. Thomas, H. Kuehne, R. Feris, and J. Glass, “Omni-r1: Do you really need audio to fine- tune your audio llm?” inIEEE Automatic Speech Recognition and Understanding Workshop, 2025
2025
-
[18]
Audio-thinker: Guiding audio language model when and how to think via reinforcement learning,
S. Wu, C. Li, W. Wang, H. Zhang, H. Wang, M. Yu, and D. Yu, “Audio-thinker: Guiding audio language model when and how to think via reinforcement learning,”arXiv preprint arXiv:2508.08039, 2025
-
[19]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio Technical Report,” 2024. [Online]. Available: https://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
ADIFF: Explaining audio difference using natural language,
S. Deshmukh, S. Han, R. Singh, and B. Raj, “ADIFF: Explaining audio difference using natural language,” inThe Thirteenth Inter- national Conference on Learning Representations, 2025
2025
-
[21]
arXiv preprint arXiv:2508.13992 , year=
S. Kumar, ˇS. Sedl ´aˇcek, V . Lokegaonkar, F. L ´opez, W. Yu, N. Anand, H. Ryu, L. Chen, M. Pli ˇcka, M. Hlav ´aˇceket al., “Mmau-pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence,”arXiv preprint arXiv:2508.13992, 2025
-
[22]
J. Kim, H. Yun, S. H. Woo, C.-H. H. Yang, and G. Kim, “Wow-bench: Evaluating fine-grained acoustic perception in audio-language models via marine mammal vocalizations,”arXiv preprint arXiv:2508.20976, 2025
-
[23]
Beyond single-audio: Advancing multi-audio processing in audio large language models,
Y . Chen, X. Yue, X. Gao, C. Zhang, L. F. D’Haro, R. T. Tan, and H. Li, “Beyond single-audio: Advancing multi-audio processing in audio large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 10 917– 10 930
2024
-
[24]
Not all features are equal: Selection of robust features for speech emo- tion recognition in noisy environments,
S.-G. Leem, D. Fulford, J.-P. Onnela, D. Gard, and C. Busso, “Not all features are equal: Selection of robust features for speech emo- tion recognition in noisy environments,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), Singapore, May 2022, pp. 6447–6451
2022
-
[25]
Selective acoustic feature enhancement for speech emo- tion recognition with noisy speech,
——, “Selective acoustic feature enhancement for speech emo- tion recognition with noisy speech,”IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 32, pp. 917–929, 2024
2024
-
[26]
Formulating emotion perception as a probabilistic model with application to categorical emotion clas- sification,
R. Lotfian and C. Busso, “Formulating emotion perception as a probabilistic model with application to categorical emotion clas- sification,” inInternational Conference on Affective Computing and Intelligent Interaction (ACII 2017), San Antonio, TX, USA, October 2017, pp. 415–420
2017
-
[27]
Adaptation level, personality theory, and psychopathology
S. Goldstone and J. L. Goldfarb, “Adaptation level, personality theory, and psychopathology.”Psychological Bulletin, vol. 61, no. 3, p. 176, 1964
1964
-
[28]
Combining ranking and clas- sification to improve emotion recognition in spontaneous speech,
H. Cao, R. Verma, and A. Nenkova, “Combining ranking and clas- sification to improve emotion recognition in spontaneous speech,” inInterspeech 2012, Portland, OR, USA, September 2012, pp. 358–361
2012
-
[29]
Turbo decoders for audio-visual continuous speech recognition,
A. Abdelaziz, “Turbo decoders for audio-visual continuous speech recognition,” inInterspeech 2017, Stockholm, Sweden, August 2017, pp. 3667–3671
2017
-
[30]
The ordinal nature of emotions,
G. Yannakakis, R. Cowie, and C. Busso, “The ordinal nature of emotions,” inInternational Conference on Affective Computing and Intelligent Interaction (ACII 2017), San Antonio, TX, USA, October 2017, pp. 248–255
2017
-
[31]
The ordinal nature of emotions: An emerging approach,
——, “The ordinal nature of emotions: An emerging approach,” IEEE Transactions on Affective Computing, vol. 12, no. 1, pp. 16– 35, January-March 2021
2021
-
[32]
Ranking emotional attributes with deep neural networks,
S. Parthasarathy, R. Lotfian, and C. Busso, “Ranking emotional attributes with deep neural networks,” inIEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP 2017), New Orleans, LA, USA, March 2017, pp. 4995–4999
2017
-
[33]
Audio-visual emotion recognition with pref- erence learning based on intended and multi-modal perceived la- bels,
Y . Lei and H. Cao, “Audio-visual emotion recognition with pref- erence learning based on intended and multi-modal perceived la- bels,”IEEE transactions on affective computing, vol. 14, no. 4, pp. 2954–2969, 2023
2023
-
[34]
Unsupervised domain adaptation for preference learning based speech emotion recog- nition,
A. R. Naini, M. A. Kohler, and C. Busso, “Unsupervised domain adaptation for preference learning based speech emotion recog- nition,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[35]
Generalization of self-supervised learning-based rep- resentations for cross-domain speech emotion recognition,
A. Reddy Naini, M. Kohler, E. Richerson, D. Robinson, and C. Busso, “Generalization of self-supervised learning-based rep- resentations for cross-domain speech emotion recognition,” in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2024), Seoul, Republic of Korea, April 2024, pp. 12 031–12 035
2024
-
[36]
The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,
F. Eyben, K. Scherer, B. Schuller, J. Sundberg, E. Andr ´e, C. Busso, L. Devillers, J. Epps, P. Laukka, S. Narayanan, and K. Truong, “The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,”IEEE Transactions on Affective Computing, vol. 7, no. 2, pp. 190–202, April-June 2016
2016
-
[37]
Preference-learning with qualita- tive agreement for sentence level emotional annotations,
S. Parthasarathy and C. Busso, “Preference-learning with qualita- tive agreement for sentence level emotional annotations,” inInter- speech 2018, Hyderabad, India, September 2018, pp. 252–256
2018
-
[38]
Grounding truth via ordi- nal annotation,
G. N. Yannakakis and H. P. Martinez, “Grounding truth via ordi- nal annotation,” inInternational Conference on Affective Com- puting and Intelligent Interaction (ACII 2015), Xi’an, China, September 2015, pp. 574–580
2015
-
[39]
Retrieving categorical emotions using a probabilistic framework to define preference learning samples,
R. Lotfian and C. Busso, “Retrieving categorical emotions using a probabilistic framework to define preference learning samples,” inInterspeech 2016, San Francisco, CA, USA, September 2016, pp. 490–494
2016
-
[40]
Speaker-sensitive emo- tion recognition via ranking: Studies on acted and spontaneous speech,
H. Cao, R. Verma, and A. Nenkova, “Speaker-sensitive emo- tion recognition via ranking: Studies on acted and spontaneous speech,”Computer Speech & Language, vol. 29, no. 1, pp. 186– 202, January 2015
2015
-
[41]
Don’t classify rat- ings of affect; rank them!
H. Martinez, G. Yannakakis, and J. Hallam, “Don’t classify rat- ings of affect; rank them!”IEEE Transactions on Affective Com- puting, vol. 5, no. 2, pp. 314–326, July-September 2014
2014
-
[42]
Using agreement on direction of change to build rank-based emotion classifiers,
S. Parthasarathy, R. Cowie, and C. Busso, “Using agreement on direction of change to build rank-based emotion classifiers,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 24, no. 11, pp. 2108–2121, November 2016
2016
-
[43]
Combining relative and absolute learning formulations to pre- dict emotional attributes from speech,
A. Reddy Naini, S. Subramanium, S.-G. Leem, and C. Busso, “Combining relative and absolute learning formulations to pre- dict emotional attributes from speech,” inIEEE Automatic Speech Recognition and Understanding Workshop (ASRU 2023), Taipei, Taiwan, December 2023, pp. 1–8
2023
-
[44]
Multi-dimensional ordinal em- bedding for attribute modeling in speech emotion recognition,
A. Reddy Naini and C. Busso, “Multi-dimensional ordinal em- bedding for attribute modeling in speech emotion recognition,” in International Conference on Affective Computing and Intelligent Interaction (ACII 2025), Canberra, Australia, October 2025
2025
-
[45]
Preference learning labels by anchoring on consecutive annotations,
A. Reddy Naini, A. Salman, and C. Busso, “Preference learning labels by anchoring on consecutive annotations,” inInterspeech 2023, Dublin, Ireland, August 2023, pp. 1898–1902
2023
-
[46]
Ordinal learn- ing for emotion recognition in customer service calls,
W. Han, T. Jiang, Y . Li, B. Schuller, and H. Ruan, “Ordinal learn- ing for emotion recognition in customer service calls,” inIEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP 2020), Barcelona, Spain, May 2020, pp. 6494– 6498
2020
-
[47]
Reasoning beyond majority vote: An explain- able speechlm framework for speech emotion recognition,
B.-H. Su, H.-Y . Shih, J. Tian, J. Shi, C.-C. Lee, C. Busso, and S. Watanabe, “Reasoning beyond majority vote: An explain- able speechlm framework for speech emotion recognition,”arXiv preprint arXiv:2509.24187, 2025
-
[48]
RE-LLM: Refin- ing empathetic speech-llm responses by integrating emotion nu- ance,
J.-H. Chen, B.-H. Su, Y .-T. Wu, and C.-C. Lee, “RE-LLM: Refin- ing empathetic speech-llm responses by integrating emotion nu- ance,”arXiv preprint arXiv:2602.10716, 2026
-
[49]
ADEPT: RL-aligned agentic decoding of emotion via evidence probing tools–from consensus learning to ambiguity-driven emo- tion reasoning,
E. Sun, B. Su, A. Reddy Naini, S. Watanabe, and C. Busso, “ADEPT: RL-aligned agentic decoding of emotion via evidence probing tools–from consensus learning to ambiguity-driven emo- tion reasoning,” inInternational Conference on Machine Learn- ing (ICML 2026), Seoul, Republic of Korea, July 2026
2026
-
[50]
Emotionthinker: Prosody-aware reinforcement learning for explainable speech emotion reasoning,
D. Wang, S. Liu, T. Zhang, Y . Chen, J. Li, and H. Meng, “Emotionthinker: Prosody-aware reinforcement learning for explainable speech emotion reasoning,”arXiv preprint arXiv:2601.15668, 2026
-
[51]
Emoprefer: Can large lan- guage models understand human emotion preferences?
Z. Lian, L. Sun, L. Chen, H. Chen, Z. Cheng, F. Zhang, Z. Jia, Z. Ma, F. Ma, X. Peng, and J. Tao, “Emoprefer: Can large lan- guage models understand human emotion preferences?”arXiv preprint arXiv:2507.04278, 2025
-
[52]
Iterative reasoning preference optimization,
R. Y . Pang, W. Yuan, H. He, K. Cho, S. Sukhbaatar, and J. Weston, “Iterative reasoning preference optimization,”Advances in Neural Information Processing Systems, vol. 37, pp. 116 617–116 637, 2024
2024
-
[53]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu, Y . Lv, Y . Wang, D. Guo, H. Wang, L. Ma, P. Zhang, X. Zhang, H. Hao, Z. Guo, B. Yang, B. Zhang, Z. Ma, X. Wei, S. Bai, K. Chen, X. Liu, P. Wang, M. Yang, D. Liu, X. Ren, B. Zheng, R. Men, F. Zhou, B. Yu, J. Yang, L. Yu, J. Zhou, and J. Lin, “Qwen3-Omni Technical Report,” 2025...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
C. Busso, R. Lotfian, K. Sridhar, A. N. Salman, W.-C. Lin, L. Goncalves, S. Parthasarathy, A. R. Naini, S.-G. Leem, L. Martinez-Lucas, H.-C. Chou, and P. Mote, “The MSP-Podcast Corpus,” 2025. [Online]. Available: https: //arxiv.org/abs/2509.09791
-
[55]
An intelligent infrastructure toward large scale naturalistic affective speech corpora collec- tion,
S. Upadhyay, W.-S. Chien, B.-H. Su, L. Goncalves, Y .-T. Wu, A. Salman, C. Busso, and C.-C. Lee, “An intelligent infrastructure toward large scale naturalistic affective speech corpora collec- tion,” inInternational Conference on Affective Computing and In- telligent Interaction (ACII 2023), Cambridge, MA, USA, Septem- ber 2023, pp. 1–8
2023
-
[56]
WHiSER: White House Tapes speech emo- tion recognition corpus,
A. Reddy Naini, L. Goncalves, M. Kohler, D. Robinson, E. Rich- erson, and C. Busso, “WHiSER: White House Tapes speech emo- tion recognition corpus,” inInterspeech 2024, Kos Island, Greece, September 2024, pp. 1595–1599
2024
-
[57]
White house tapes,
Richard Nixon Presidential Library and Museum, “White house tapes,” https://www.nixonlibrary.gov/white-house-tapes, 2024, accessed: 2026-03-05
2024
-
[58]
Qwen3-next-80b-a3b: Towards ultimate training and inference efficiency,
Qwen Team, “Qwen3-next-80b-a3b: Towards ultimate training and inference efficiency,” https://qwen.ai/blog?id= 4074cca80393150c248e508aa62983f9cb7d27cd, 2025, technical report, Alibaba Qwen. Accessed: 2026-03-05
2025
-
[59]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” 2021. [Online]. Available: https: //arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, October 2022
2022
-
[61]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[62]
Learning to rank using gradient descent,
C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton, and G. Hullender, “Learning to rank using gradient descent,” inInternational conference on Machine learning (ICML 2005), Bonn, Germany, August 2005, pp. 89–96
2005
-
[63]
RankList – a listwise preference learning framework for predicting subjective pref- erences,
A. Reddy Naini, F. Diaz, and C. Busso, “RankList – a listwise preference learning framework for predicting subjective pref- erences,” inAAAI Conference on Artificial Intelligence (AAAI 2026), Singapore, January 2026
2026
-
[64]
Dawn of the trans- former era in speech emotion recognition: Closing the valence gap,
J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. Schuller, “Dawn of the trans- former era in speech emotion recognition: Closing the valence gap,”IEEE Transactions on Pattern Analysis and Machine Intel- ligence, vol. 45, no. 9, pp. 10 745–10 759, September 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.