CRAFT: Cost-aware Refinement And Front-aware Tuning of Prompts
Pith reviewed 2026-06-28 06:36 UTC · model grok-4.3
The pith
CRAFT searches the full Pareto front of prompt accuracy and token cost instead of fixing a weighted trade-off before search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
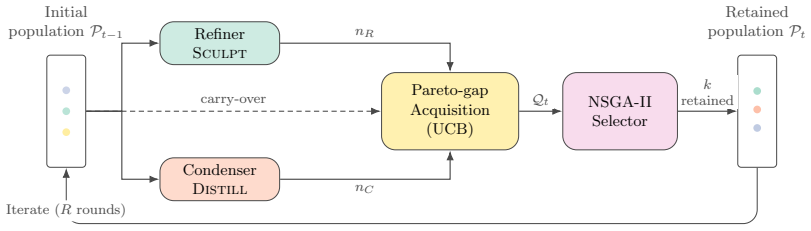
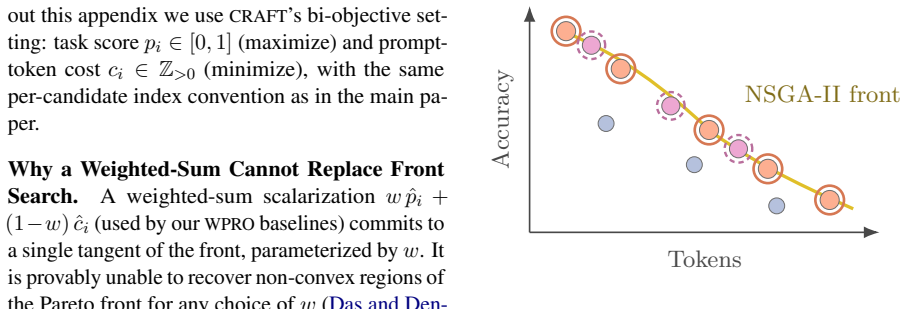
CRAFT treats validation calls to the target LLM as the scarce resource and allocates them to candidates near the optimistic candidate front; complementary accuracy-oriented and cost-oriented generators propose edits each round, Pareto-gap acquisition spends the per-round validation budget, and NSGA-II retention preserves a spread-out population. The resulting fronts reach both high-accuracy and low-cost regions on six benchmarks, whereas accuracy-only, cost-only, and weighted-sum baselines concentrate in narrower regions, turning the accuracy-cost trade-off into a post-search choice rather than a pre-search weight.
What carries the argument
Pareto-gap acquisition that directs scarce validation budget toward candidates near the optimistic candidate front, supported by complementary accuracy-oriented and cost-oriented prompt-edit generators and NSGA-II population retention.
If this is right
- The accuracy-cost trade-off can be chosen after the search finishes rather than before it starts.
- Accuracy-only, cost-only, and weighted-sum baselines each recover only narrow segments of the front.
- The validation budget is spent on candidates near the current optimistic front instead of being spread uniformly or committed to a single weight.
- NSGA-II retention maintains population diversity across the front throughout the search.
Where Pith is reading between the lines
- Production systems could inspect the retained front and pick shorter prompts when a modest accuracy drop is acceptable for the deployment budget.
- The same generator-plus-acquisition pattern could be applied to other multi-objective prompt problems such as balancing accuracy against latency or against safety metrics.
- The method makes it feasible to compare prompt fronts across different target models without re-committing to a fixed weight for each model.
Load-bearing premise
The two complementary generators will reliably propose edits that lie close enough to the true optimistic front for Pareto-gap acquisition to cover the relevant regions without large gaps.
What would settle it
On any of the six benchmarks, run CRAFT and a fixed-weight baseline with identical validation-call budgets and check whether the baseline ever produces a prompt whose accuracy-cost pair lies outside the final CRAFT front.
Figures













read the original abstract
Prompts tuned for accuracy often grow long, raising inference cost on every model call. The best accuracy-cost trade-off depends on the task and the budget, so prompt optimization is a search over the Pareto front of accuracy and prompt-token cost rather than for one prompt. The usual shortcut, collapsing the objectives into a weighted sum, fixes the trade-off weight before search and often recovers only a narrow region of the front, a failure we call scalarization collapse. We present CRAFT (Cost-aware Refinement And Front-aware Tuning), a Pareto-front prompt optimizer that treats target-LLM validation calls as the scarce resource and allocates them to candidates near the optimistic candidate front. Each round, complementary accuracy-oriented and cost-oriented generators propose edits, Pareto-gap acquisition spends the per-round validation budget, and NSGA-II retention keeps a spread-out population. Across six classification and reasoning benchmarks, CRAFT's retained fronts reach both high-accuracy and low-cost regions, while accuracy-only, cost-only, and weighted-sum baselines each concentrate in narrower regions. The accuracy-cost trade-off becomes a post-search choice, not a pre-search weight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CRAFT, a multi-objective prompt optimizer that searches the Pareto front of accuracy versus prompt-token cost. It employs complementary accuracy-oriented and cost-oriented generators to propose edits, Pareto-gap acquisition to allocate scarce target-LLM validation calls, and NSGA-II to retain a spread-out population. The central empirical claim is that, across six classification and reasoning benchmarks, the retained fronts cover both high-accuracy and low-cost regions while accuracy-only, cost-only, and weighted-sum baselines each collapse to narrower sub-fronts, thereby converting the accuracy-cost trade-off into a post-search selection rather than a pre-search scalarization weight.
Significance. If the empirical coverage claims hold and the generator assumption is validated, the work would offer a practical advance for prompt engineering in cost-sensitive settings by avoiding scalarization collapse and enabling budget-dependent prompt selection after optimization. No machine-checked proofs, reproducible code artifacts, or parameter-free derivations are described.
major comments (2)
- [Method (generators and acquisition)] The strongest claim—that CRAFT fronts reach both high-accuracy and low-cost regions while baselines concentrate narrowly—rests on the unverified assumption that the accuracy-oriented and cost-oriented generators reliably produce edits near the optimistic candidate front so that Pareto-gap acquisition can allocate the validation budget without large gaps. No empirical check on generator coverage, edit quality, or frequency with which proposed candidates lie on or near the true front is supplied.
- [Abstract and Experiments] Abstract and Experiments: the assertion of superior front coverage on six benchmarks is stated without quantitative metrics (e.g., hypervolume, coverage ratios), statistical tests, or a description of how the accuracy-only, cost-only, and weighted-sum baselines were implemented and tuned, so the data-to-claim link cannot be evaluated.
minor comments (1)
- [Method] Notation for the optimistic candidate front and Pareto-gap acquisition should be defined with explicit equations or pseudocode in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to incorporate additional empirical checks and quantitative metrics.
read point-by-point responses
-
Referee: [Method (generators and acquisition)] The strongest claim—that CRAFT fronts reach both high-accuracy and low-cost regions while baselines concentrate narrowly—rests on the unverified assumption that the accuracy-oriented and cost-oriented generators reliably produce edits near the optimistic candidate front so that Pareto-gap acquisition can allocate the validation budget without large gaps. No empirical check on generator coverage, edit quality, or frequency with which proposed candidates lie on or near the true front is supplied.
Authors: We agree that the manuscript does not contain a direct empirical verification of generator coverage or the frequency with which proposed candidates lie near the true front. The design rationale for the complementary generators is presented in Section 3, and the broader fronts observed in the experiments provide indirect support for their utility. To address the concern, the revision will include a new analysis quantifying the proportion of generated candidates that improve or lie close to the current Pareto front across rounds. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: the assertion of superior front coverage on six benchmarks is stated without quantitative metrics (e.g., hypervolume, coverage ratios), statistical tests, or a description of how the accuracy-only, cost-only, and weighted-sum baselines were implemented and tuned, so the data-to-claim link cannot be evaluated.
Authors: The current version relies on visual comparison of retained fronts in the figures. We will add hypervolume values, coverage ratios, and appropriate statistical tests in the revised Experiments section. We will also expand the baseline descriptions to detail the exact implementation and tuning procedure for the accuracy-only, cost-only, and weighted-sum variants. revision: yes
Circularity Check
No circularity; algorithmic procedure with independent empirical claims
full rationale
The paper presents CRAFT as an algorithmic procedure (accuracy/cost generators + Pareto-gap acquisition + NSGA-II retention) evaluated on six benchmarks. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claim concerns empirical coverage of the accuracy-cost front and is not a derivation that collapses to a definition or fit. This matches the default expectation of no significant circularity for a non-mathematical algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2005.14165 , year=
Language Models are Few-Shot Learners , author=. arXiv preprint arXiv:2005.14165 , year=
Pith/arXiv arXiv 2005
-
[2]
The Power of Scale for Parameter-Efficient Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month=nov, year=. doi:10.18653/v1/2021.emnlp-main.243 , pages=
-
[3]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month=aug, year=. doi:10.18653/v1/2021.acl-long.353 , pages=
-
[4]
2024 , publisher=
Liu, Xiao and Zheng, Yanan and Du, Zhengxiao and Ding, Ming and Qian, Yujie and Yang, Zhilin and Tang, Jie , journal=. 2024 , publisher=
2024
-
[5]
Qin, Guanghui and Eisner, Jason , editor=. Learning How to Ask: Querying. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month=jun, year=. doi:10.18653/v1/2021.naacl-main.410 , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Making Pre-trained Language Models Better Few-shot Learners , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month=aug, year=. doi:10.18653/v1/2021.acl-long.295 , pages=
-
[8]
arXiv preprint arXiv:2211.11890 , year=
Tempera: Test-time prompting via reinforcement learning , author=. arXiv preprint arXiv:2211.11890 , year=
-
[9]
The Twelfth International Conference on Learning Representations , year=
Large Language Models as Optimizers , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
arXiv preprint arXiv:2203.07281 , year=
Grips: Gradient-free, edit-based instruction search for prompting large language models , author=. arXiv preprint arXiv:2203.07281 , year=
-
[11]
Automatic Engineering of Long Prompts
Hsieh, Cho-Jui and Si, Si and Yu, Felix and Dhillon, Inderjit. Automatic Engineering of Long Prompts. Findings of the Association for Computational Linguistics ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.634
-
[12]
arXiv preprint arXiv:2211.01910 , year=
Large language models are human-level prompt engineers , author=. arXiv preprint arXiv:2211.01910 , year=
-
[13]
arXiv preprint arXiv:2307.07415 , year=
Autohint: Automatic prompt optimization with hint generation , author=. arXiv preprint arXiv:2307.07415 , year=
-
[14]
Findings of the Association for Computational Linguistics: ACL 2024 , month=aug, year=
Prompt Engineering a Prompt Engineer , author=. Findings of the Association for Computational Linguistics: ACL 2024 , month=aug, year=. doi:10.18653/v1/2024.findings-acl.21 , pages=
-
[15]
Pryzant, Reid and Iter, Dan and Li, Jerry and Lee, Yin and Zhu, Chenguang and Zeng, Michael. Automatic Prompt Optimization with ``Gradient Descent'' and Beam Search. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.494
-
[16]
Black-Box Prompt Optimization: Aligning Large Language Models without Model Training , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month=aug, year=. doi:10.18653/v1/2024.acl-long.176 , pages=
-
[17]
arXiv preprint arXiv:2210.17041 , year=
GPS: Genetic prompt search for efficient few-shot learning , author=. arXiv preprint arXiv:2210.17041 , year=
-
[18]
2024 IEEE Congress on Evolutionary Computation (CEC) , pages=
Large language models as evolutionary optimizers , author=. 2024 IEEE Congress on Evolutionary Computation (CEC) , pages=. 2024 , organization=
2024
-
[19]
The Twelfth International Conference on Learning Representations , year=
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
Proceedings of the 41st International Conference on Machine Learning , pages =
Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[21]
Optimizing generative
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Lu, Pan and Huang, Zhi and Guestrin, Carlos and Zou, James , journal=. Optimizing generative. 2025 , publisher=
2025
-
[22]
Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , booktitle=
Omar Khattab and Arnav Singhvi and Paridhi Maheshwari and Zhiyuan Zhang and Keshav Santhanam and Sri Vardhamanan A and Saiful Haq and Ashutosh Sharma and Thomas T. Joshi and Hanna Moazam and Heather Miller and Matei Zaharia and Christopher Potts , booktitle=. 2024 , url=
2024
-
[23]
Schnabel, Tobias and Neville, Jennifer. Symbolic Prompt Program Search: A Structure-Aware Approach to Efficient Compile-Time Prompt Optimization. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.37
-
[24]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[25]
Publications Manual , year = "1983", publisher =
1983
-
[26]
arXiv preprint arXiv:2005.04118 , year=
Beyond accuracy: Behavioral testing of NLP models with CheckList , author=. arXiv preprint arXiv:2005.04118 , year=
arXiv 2005
-
[27]
arXiv preprint arXiv:2302.09664 , year=
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
-
[28]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[29]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[30]
Dan Gusfield , title =. 1997
1997
-
[31]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[32]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[33]
, title =
Turing, Alan M. , title =. Mind , volume =
-
[34]
Nature , volume =
Learning Representations by Back-Propagating Errors , author =. Nature , volume =
-
[35]
Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
Planning as Satisfiability , author =. Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
-
[36]
Artificial Intelligence , volume =
Collaborative Plans for Complex Group Action , author =. Artificial Intelligence , volume =
-
[37]
The Entropy Formula for the
Grisha Perelman , howpublished =. The Entropy Formula for the
-
[38]
Causality , author =
-
[39]
Tnternational Conference on Machine Learning , pages=
Dropout as a Bayesian approximation: Representing model uncertainty in deep learning , author=. Tnternational Conference on Machine Learning , pages=
-
[40]
Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
” Diversity and Uncertainty in Moderation” are the Key to Data Selection for Multilingual Few-shot Transfer , author=. Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
2022
-
[41]
Advances in neural information processing systems , pages=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , pages=
-
[42]
Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, volume 2: Short Papers , pages=
Active learning for post-editing based incrementally retrained MT , author=. Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, volume 2: Short Papers , pages=
-
[43]
Transactions of the Association for Computational Linguistics , volume=
Multilingual denoising pre-training for neural machine translation , author=. Transactions of the Association for Computational Linguistics , volume=. 2020 , publisher=
2020
-
[44]
arXiv preprint arXiv:2010.11934 , year=
mT5: A massively multilingual pre-trained text-to-text transformer , author=. arXiv preprint arXiv:2010.11934 , year=
arXiv 2010
-
[45]
arXiv preprint arXiv:2012.15674 , year=
ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora , author=. arXiv preprint arXiv:2012.15674 , year=
arXiv 2012
-
[46]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Reinforced training data selection for domain adaptation , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[47]
Proceedings of the 45th annual meeting of the association of computational linguistics , pages=
Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification , author=. Proceedings of the 45th annual meeting of the association of computational linguistics , pages=
-
[48]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages=
Data point selection for cross-language adaptation of dependency parsers , author=. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages=
-
[49]
and McDonald, Ryan and Petrov, Slav and Pyysalo, Sampo and Silveira, Natalia and Tsarfaty, Reut and Zeman, Daniel
Nivre, Joakim and de Marneffe, Marie-Catherine and Ginter, Filip and Goldberg, Yoav and Haji c , Jan and Manning, Christopher D. and McDonald, Ryan and Petrov, Slav and Pyysalo, Sampo and Silveira, Natalia and Tsarfaty, Reut and Zeman, Daniel. U niversal D ependencies v1: A Multilingual Treebank Collection. Proceedings of the Tenth International Conferenc...
2016
-
[50]
Massively Multilingual Transfer for NER
Rahimi, Afshin and Li, Yuan and Cohn, Trevor. Massively Multilingual Transfer for NER. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1015
-
[51]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
From Zero to Hero: On the Limitations of Zero-Shot Language Transfer with Multilingual Transformers , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[52]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[53]
How Multilingual is Multilingual BERT ?
Pires, Telmo and Schlinger, Eva and Garrette, Dan. How Multilingual is Multilingual BERT ?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1493
-
[54]
HuggingFace's Transformers: State-of-the-art Natural Language Processing , journal =
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R. HuggingFace's Transformers: State-of-the-art Natural Language Processing , journal =. 2019 , url =
2019
-
[55]
SRILM - an extensible language modeling toolkit
Stolcke, Andreas , biburl =. SRILM - an extensible language modeling toolkit. , url =. INTERSPEECH , editor =
-
[56]
and Lewis, William
Moore, Robert C. and Lewis, William. Intelligent Selection of Language Model Training Data. Proceedings of the ACL 2010 Conference Short Papers. 2010
2010
-
[57]
Domain Adaptation via Pseudo In-Domain Data Selection
Axelrod, Amittai and He, Xiaodong and Gao, Jianfeng. Domain Adaptation via Pseudo In-Domain Data Selection. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. 2011
2011
-
[58]
Cross-lingual Language Model Pretraining , url =
Conneau, Alexis and Lample, Guillaume , booktitle =. Cross-lingual Language Model Pretraining , url =
-
[59]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Unsupervised Cross-lingual Representation Learning at Scale , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[60]
International Conference on Learning Representations , year=
Cross-Lingual Ability of Multilingual BERT: An Empirical Study , author=. International Conference on Learning Representations , year=
-
[61]
On the Cross-lingual Transferability of Monolingual Representations
Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani. On the Cross-lingual Transferability of Monolingual Representations. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.421
-
[62]
Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT
Wu, Shijie and Dredze, Mark. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1077
-
[63]
Zero-Shot Cross-Lingual Transfer with Meta Learning
Nooralahzadeh, Farhad and Bekoulis, Giannis and Bjerva, Johannes and Augenstein, Isabelle. Zero-Shot Cross-Lingual Transfer with Meta Learning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.368
-
[64]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages=
-
[65]
and Nowozin, Sebastian and Dillon, Joshua and Lakshminarayanan, Balaji and Snoek, Jasper , booktitle =
Ovadia, Yaniv and Fertig, Emily and Ren, Jie and Nado, Zachary and Sculley, D. and Nowozin, Sebastian and Dillon, Joshua and Lakshminarayanan, Balaji and Snoek, Jasper , booktitle =. Can you trust your model s uncertainty? Evaluating predictive uncertainty under dataset shift , url =
-
[66]
2012 , publisher=
Bayesian learning for neural networks , author=. 2012 , publisher=
2012
-
[67]
Entropy-based Training Data Selection for Domain Adaptation
Song, Yan and Klassen, Prescott and Xia, Fei and Kit, Chunyu. Entropy-based Training Data Selection for Domain Adaptation. Proceedings of COLING 2012: Posters. 2012
2012
-
[68]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Quantifying uncertainties in natural language processing tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[69]
2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops , pages=
Entropy-based active learning for object recognition , author=. 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops , pages=. 2008 , organization=
2008
-
[70]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[71]
Sabou, Marta and Bontcheva, Kalina and Scharl, Arno , title =. Proceedings of the 12th International Conference on Knowledge Management and Knowledge Technologies , articleno =. 2012 , isbn =. doi:10.1145/2362456.2362479 , abstract =
-
[72]
Complex Linguistic Annotation -- No Easy Way Out! A Case from B angla and H indi POS Labeling Tasks
Dandapat, Sandipan and Biswas, Priyanka and Choudhury, Monojit and Bali, Kalika. Complex Linguistic Annotation -- No Easy Way Out! A Case from B angla and H indi POS Labeling Tasks. Proceedings of the Third Linguistic Annotation Workshop ( LAW III ). 2009
2009
-
[73]
2016 , publisher=
Collaborative Annotation for Reliable Natural Language Processing: Technical and Sociological Aspects , author=. 2016 , publisher=
2016
-
[74]
Glenn W. Brier. VERIFICATION OF FORECASTS EXPRESSED IN TERMS OF PROBABILITY. Monthly Weather Review. 1950. doi:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2
-
[75]
Quarterly Journal of the Royal Meteorological Society , volume =
Bröcker, Jochen , title =. Quarterly Journal of the Royal Meteorological Society , volume =. doi:https://doi.org/10.1002/qj.456 , url =. https://rmets.onlinelibrary.wiley.com/doi/pdf/10.1002/qj.456 , abstract =
-
[76]
International Conference on Artificial Intelligence and Statistics , pages=
On Data Efficiency of Meta-learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[77]
arXiv preprint arXiv:2001.08735 , year=
Cross-domain few-shot classification via learned feature-wise transformation , author=. arXiv preprint arXiv:2001.08735 , year=
arXiv 2001
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning loss for active learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
International Conference on Machine Learning , pages=
Deep bayesian active learning with image data , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[80]
arXiv preprint arXiv:1708.00489 , year=
Active learning for convolutional neural networks: A core-set approach , author=. arXiv preprint arXiv:1708.00489 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.