It's Much Easier for Neural Networks to learn Game of Life Dynamics with the Right Activation Function: Polynomial Kolmogorov-Arnold Networks
Pith reviewed 2026-06-26 08:47 UTC · model grok-4.3
The pith
A second-degree polynomial activation lets minimal neural networks learn Conway's Game of Life rules reliably, with or without updating weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
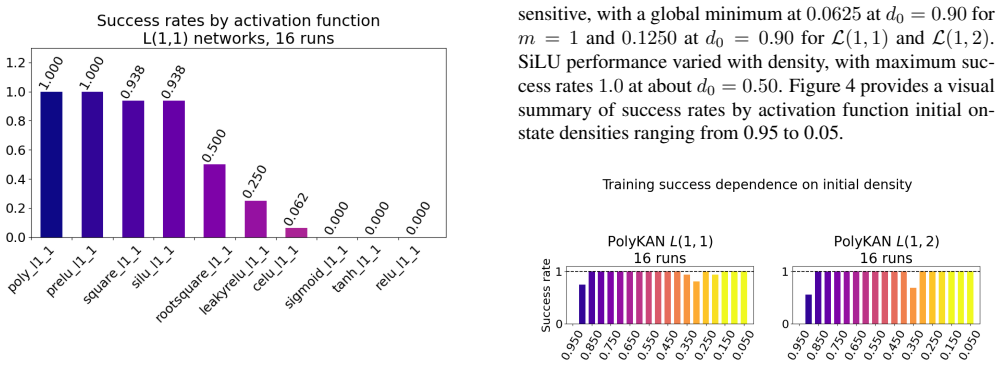
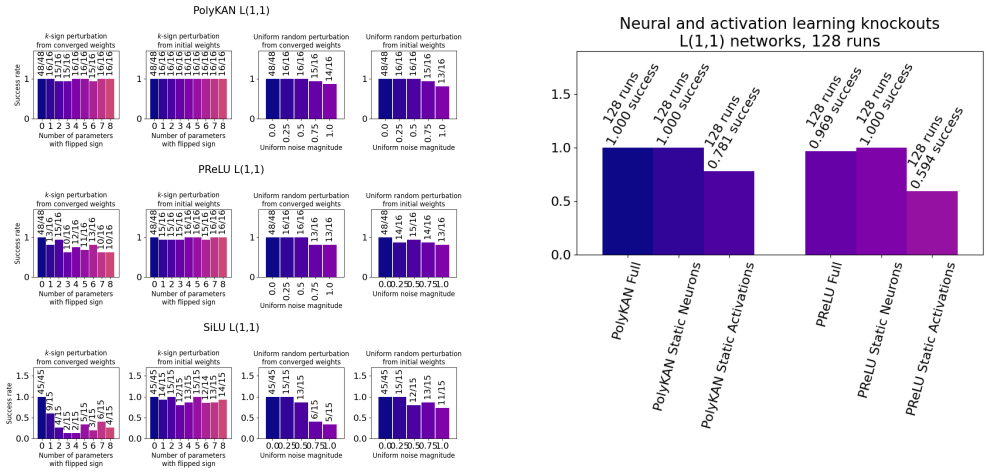
Networks equipped with a second-degree polynomial activation function learn the update rules of Conway's Game of Life consistently, including in the fixed-weight case where only the activation parameters are optimized; the same task remains markedly harder for ReLU networks of comparable size.
What carries the argument
A second-degree polynomial activation function that supplies the quadratic terms present in the Game of Life birth and survival conditions.
If this is right
- Minimal networks become sufficient for representing discrete dynamical systems whose update rules are low-degree polynomials.
- Activation-function design can substitute for weight learning in tasks whose governing equations have known polynomial structure.
- Cellular automata supply compact, verifiable benchmarks for testing whether new activations improve learning of physics-like rules.
- The gap between minimal representable networks and reliably learnable networks narrows when inductive bias aligns with rule algebra.
Where Pith is reading between the lines
- The same polynomial bias may help networks learn other discrete or continuous systems whose local rules are quadratic, such as certain lattice gases or simplified fluid models.
- Fixed-weight polynomial networks could serve as interpretable modules inside larger hybrid models where only a few parameters need to be learned.
- Systematic comparison of polynomial degree against rule complexity offers a route to activation selection that does not rely on scale.
Load-bearing premise
Observed performance gaps are caused mainly by how well the activation matches the algebraic structure of the Life rules rather than by differences in training procedure, initialization scale, or other unstated architectural details.
What would settle it
Train otherwise identical networks on the same Life grids but replace the polynomial activation with a different non-linear function whose Taylor expansion lacks the required quadratic terms; if those networks still reach high accuracy at the same small sizes, the activation-matching explanation does not hold.
Figures



read the original abstract
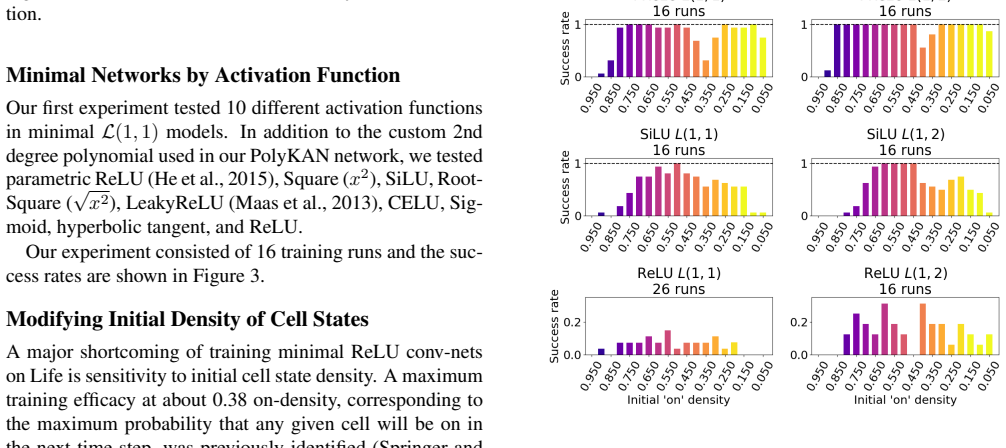
Previous work has found a gap between the scale of neural networks that reliably learn Conway's Game of Life, and minimal networks capable of representing the classic cellular automaton with hard-coded parameter values. Viewing neural network learning as a search process suggests a dependence on networks large enough to contain sub-networks with lucky initializations (sometimes known as 'winning tickets') that actually learn the task. In this work, we reorient our perspective from discovering Life rules as a search problem back to a learning problem, and reason that with fitting inductive biases, the problem should be much more amenable to minimal networks. We find that network variants with several alternative activation functions meaningfully outperform the default choice of Rectified Linear Units, and in particular, that a 2nd degree polynomial activation function consistently learns Life dynamics with or without the benefit of learning neural weights. Our results provide an informative demonstration of the benefits of matching learning to the task at hand and challenge the easy default choice of scale for all problems. In particular, we advocate for the use of cellular automata as simple test domains for developing strategies that can benefit machine learning for science, physics-based deep learning, and interpretable machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a 2nd-degree polynomial activation function enables minimal neural networks (including variants of Kolmogorov-Arnold Networks) to learn Conway's Game of Life dynamics far more readily than ReLU, with consistent success even when weights are not learned; this is presented as evidence that matching the activation's inductive bias to the underlying boolean polynomial structure of the CA rules reduces the need for large networks or lucky initializations.
Significance. If the empirical results hold under controlled conditions, the work would usefully illustrate how task-specific activations can make discrete dynamical systems like cellular automata tractable for small networks, supporting broader arguments for interpretable and physics-aligned ML. The use of Game of Life as a test domain is a clear strength for reproducibility and falsifiability.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent outperformance' and that the 2nd-degree polynomial 'consistently learns Life dynamics with or without the benefit of learning neural weights' is stated without any quantitative metrics, baselines, statistical details, or controls, preventing verification that the central claim is supported by the data.
- [Abstract] Experimental comparison (throughout): the central claim that performance differences arise from the activation matching Game of Life structure requires that all variants (ReLU vs. polynomial, fixed vs. learned weights) are identical in architecture, parameter count, optimizer, learning-rate schedule, initialization distribution, and training steps. The abstract refers to 'network variants with several alternative activation functions' without confirming these controls, so observed gaps could be driven by unstated differences in training dynamics instead.
minor comments (1)
- [Abstract] The title emphasizes Kolmogorov-Arnold Networks while the abstract describes 'network variants'; clarify whether the reported results use KAN-style learnable univariate functions or standard MLPs with fixed polynomial activations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater quantitative detail and explicit confirmation of experimental controls will strengthen the presentation and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' and that the 2nd-degree polynomial 'consistently learns Life dynamics with or without the benefit of learning neural weights' is stated without any quantitative metrics, baselines, statistical details, or controls, preventing verification that the central claim is supported by the data.
Authors: The abstract is a concise summary; the quantitative metrics, baselines, success rates over multiple runs, and statistical details supporting the claims appear in the experimental results (Sections 3 and 4). To address the concern, we will revise the abstract to include key quantitative findings and references to the controls. revision: yes
-
Referee: [Abstract] Experimental comparison (throughout): the central claim that performance differences arise from the activation matching Game of Life structure requires that all variants (ReLU vs. polynomial, fixed vs. learned weights) are identical in architecture, parameter count, optimizer, learning-rate schedule, initialization distribution, and training steps. The abstract refers to 'network variants with several alternative activation functions' without confirming these controls, so observed gaps could be driven by unstated differences in training dynamics instead.
Authors: All activation variants were evaluated under identical conditions: the same network architectures, parameter counts, optimizers, learning-rate schedules, initialization distributions, and training steps, differing solely in the activation function. This is stated in the Methods section. We will add an explicit sentence to the abstract confirming these controls. revision: yes
Circularity Check
No circularity: empirical activation comparisons with no derivations or self-referential reductions
full rationale
The paper reports experimental results on activation functions for learning Game of Life dynamics. No equations, first-principles derivations, or predictions are claimed that could reduce to fitted inputs or self-citations by construction. All load-bearing claims rest on direct performance measurements across variants rather than any mathematical chain that loops back to its own assumptions. This matches the default expectation of non-circular empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- polynomial degree =
2
axioms (1)
- domain assumption Neural network learning difficulty for Game of Life stems from mismatch between activation shape and task structure
Reference graph
Works this paper leans on
-
[1]
Rectifier nonlinearities improve neural network acoustic models , author=. Proc. icml , volume=. 2013 , organization=
2013
-
[2]
Journal de Math
Optimal approximation rate of ReLU networks in terms of width and depth , author=. Journal de Math. 2022 , publisher=
2022
-
[3]
Neural Networks , year=
Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks , author=. Neural Networks , year=
-
[4]
2015 IEEE International Conference on Computer Vision (ICCV) , year=
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , author=. 2015 IEEE International Conference on Computer Vision (ICCV) , year=
2015
-
[5]
Neural Networks , year=
A feedforward neural network with function shape autotuning , author=. Neural Networks , year=
-
[6]
Artificial Life , year=
Life Worth Mentioning: Complexity in Life-Like Cellular Automata , author=. Artificial Life , year=
-
[7]
Physica D: Nonlinear Phenomena , volume=
Universality and complexity in cellular automata , author=. Physica D: Nonlinear Phenomena , volume=. 1984 , publisher=
1984
-
[8]
2021 IEEE Conference on Games (CoG) , year=
Carle's Game: An Open-Ended Challenge in Exploratory Machine Creativity , author=. 2021 IEEE Conference on Games (CoG) , year=
2021
-
[9]
Scientific American , year = 1970, volume =
Martin Gardner , title =. Scientific American , year = 1970, volume =
1970
-
[10]
Berlekamp, E. R. and Conway, J. H and Guy, R. K. , title =
-
[11]
MIT Press series in scientific computation , year=
Cellular automata machines - a new environment for modeling , author=. MIT Press series in scientific computation , year=
-
[12]
Axioms , year=
A Model for the Universe that Begins to Resemble a Quantum Computer , author=. Axioms , year=
-
[13]
Calculating space (
Zuse, Konrad , journal=. Calculating space (. 1970 , publisher=
1970
-
[14]
Neural Networks , year=
Approximation capabilities of multilayer feedforward networks , author=. Neural Networks , year=
-
[15]
PhD thesis: Modeles connexionnistes de l'apprentissage (connectionist learning models) , author=
-
[16]
Neural Information Processing Systems , year=
How Neural Nets Work , author=. Neural Information Processing Systems , year=
-
[17]
Mathematics of Control, Signals and Systems , year=
Approximation by superpositions of a sigmoidal function , author=. Mathematics of Control, Signals and Systems , year=
-
[18]
Twelve Papers on Algebra and Real Functions , isbn=
On the representation of continuous functions of several variables by superpositions of continuous functions of a smaller number of variables , author=. Twelve Papers on Algebra and Real Functions , isbn=. 1961 , publisher=
1961
-
[19]
2025 26th International Conference on Computational Problems of Electrical Engineering (CPEE) , year=
Convolutional Kolmogorov Arnold Networks as an accurate alternative to Convolutional Neural Networks for rule discovery in Game of Life , author=. 2025 26th International Conference on Computational Problems of Electrical Engineering (CPEE) , year=
2025
-
[20]
IEEE Trans
Polynomial Theory of Complex Systems , author=. IEEE Trans. Syst. Man Cybern. , year=
-
[21]
1967 , publisher=
Cybernetics and forecasting techniques , author=. 1967 , publisher=
1967
-
[22]
It's hard for neural networks to learn the
Springer, Jacob M and Kenyon, Garrett T , booktitle=. It's hard for neural networks to learn the. 2021 , organization=
2021
-
[23]
Advances in Neural Information Processing Systems , volume=
Learning graph cellular automata , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in neural information processing systems , volume=
On the expressive power of deep polynomial neural networks , author=. Advances in neural information processing systems , volume=
-
[25]
Algebraic Statistics , volume=
Activation degree thresholds and expressiveness of polynomial neural networks , author=. Algebraic Statistics , volume=. 2025 , publisher=
2025
-
[26]
Uncertainty in Artificial Intelligence , pages=
On the inductive bias of neural networks for learning read-once dnfs , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
2022
-
[27]
Baader, Maximilian and M. Expressivity of. arXiv preprint arXiv:2311.04015 , year=
-
[28]
international conference on machine learning , pages=
On the expressive power of deep neural networks , author=. international conference on machine learning , pages=. 2017 , organization=
2017
-
[29]
Physical Review E , volume=
Cellular automata as convolutional neural networks , author=. Physical Review E , volume=. 2019 , publisher=
2019
-
[30]
Nature Machine Intelligence , pages=
Single-unit activations confer inductive biases for emergent circuit solutions to cognitive tasks , author=. Nature Machine Intelligence , pages=. 2025 , publisher=
2025
-
[31]
Proceedings of the Royal Society A , volume=
Inductive biases for deep learning of higher-level cognition , author=. Proceedings of the Royal Society A , volume=. 2022 , publisher=
2022
-
[32]
Deep Learning using Rectified Linear Units (ReLU)
Deep learning using rectified linear units (relu) , author=. arXiv preprint arXiv:1803.08375 , pages=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
KAN: Kolmogorov-Arnold Networks
Liu, Ziming and Wang, Yixuan and Vaidya, Sachin and Ruehle, Fabian and Halverson, James and Solja. arXiv preprint arXiv:2404.19756 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Kolmogorov
Polson, Sarah and Sokolov, Vadim , journal=. Kolmogorov. 2025 , publisher=
2025
-
[35]
Neural networks , volume=
Multilayer feedforward networks are universal approximators , author=. Neural networks , volume=. 1989 , publisher=
1989
-
[36]
PolyKAN: Efficient Fused
Yu, Mingkun and Zhong, Heming and Huang, Dan and Lu, Yutong and Jiang, Jiazhi , journal=. PolyKAN: Efficient Fused
-
[37]
Computer Science Review , year=
A practitioner’s guide to Kolmogorov–Arnold networks , author=. Computer Science Review , year=
-
[38]
2026 , publisher=
Ren, Pengfei and Pan, Tony Yuxiang and Yang, Guangyu and Guo, Yanchen and Wei, Weibo and Pan, Zhenkuan , journal=. 2026 , publisher=
2026
-
[39]
KAN-SR: A Kolmogorov-Arnold Network Guided Symbolic Regression Framework
B. arXiv preprint arXiv:2509.10089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Symbolic Regression Based on
Huang, Yiming and Li, Bin and Wu, Zhaohui and Liu, Wenchao , journal=. Symbolic Regression Based on. 2025 , publisher=
2025
-
[41]
Opening the black-box: symbolic regression with
Panczyk, Nataly R and Erdem, Omer F and Radaideh, Majdi I , journal=. Opening the black-box: symbolic regression with
-
[42]
arXiv preprint arXiv:2411.03884 , year=
Polynomial composition activations: Unleashing the dynamics of large language models , author=. arXiv preprint arXiv:2411.03884 , year=
-
[43]
Artificial Life , volume=
Automating the search for artificial life with foundation models , author=. Artificial Life , volume=. 2025 , publisher=
2025
-
[44]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
The lottery ticket hypothesis: Finding sparse, trainable neural networks , author=. arXiv preprint arXiv:1803.03635 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Neural networks , volume=
The Kolmogorov--Arnold representation theorem revisited , author=. Neural networks , volume=. 2021 , publisher=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.