GoodServe: Towards High-Goodput Serving of Agentic LLM Inferences over Heterogeneous Resources
Pith reviewed 2026-05-19 19:27 UTC · model grok-4.3
The pith
GoodServe routes agentic LLM requests across heterogeneous GPUs with predict-and-rectify decisions to raise goodput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
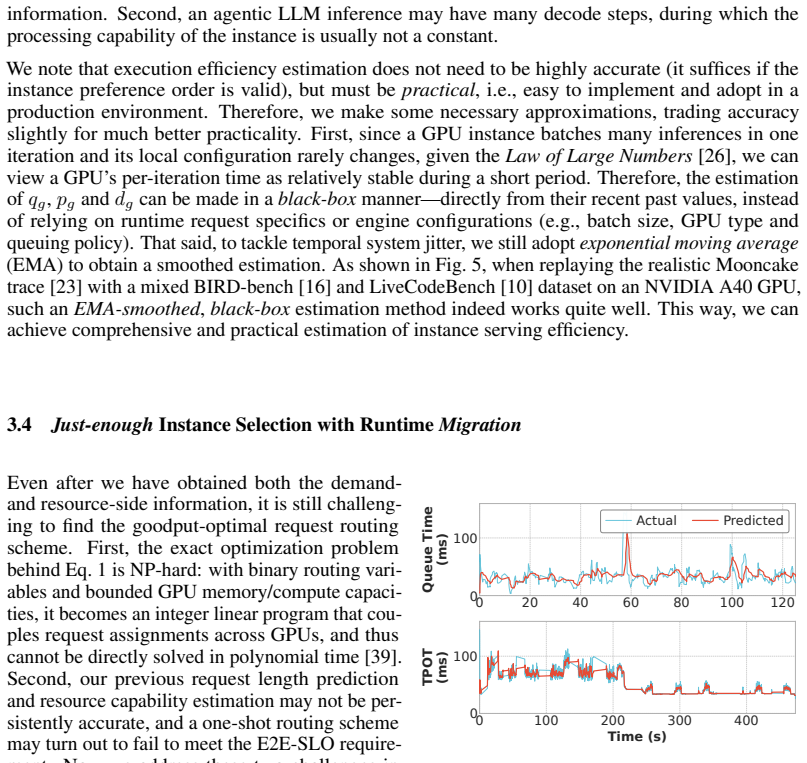
GoodServe performs inference routing in a predict-and-rectify manner. It estimates request output lengths and GPU serving status accurately, selects routes with a just-enough instance selection heuristic, and periodically monitors active requests to trigger migrations when SLO-violation risks emerge. Evaluations show this raises goodput by up to 27.4 percent over existing methods.
What carries the argument
Predict-and-rectify routing that combines output-length estimates, GPU status checks, a just-enough instance selection heuristic, and runtime request migrations.
If this is right
- A larger share of agentic requests finish before their end-to-end latency deadlines on mixed hardware.
- Operators obtain higher effective throughput from the same heterogeneous GPU pool without buying extra capacity.
- Periodic monitoring and migration reduce the impact of sudden changes in request behavior or resource load.
- Routing quality depends directly on the accuracy of the length and status estimates used at decision time.
Where Pith is reading between the lines
- The same estimation-plus-heuristic pattern might apply to non-agentic LLM workloads if output-length prediction stays reliable.
- Combining the approach with dynamic GPU allocation could reduce idle time in cloud clusters serving mixed inference jobs.
- The migration mechanism could be tested under bursty arrival patterns to see how often it activates in practice.
Load-bearing premise
Estimates of request output lengths and current GPU serving status can be obtained accurately and in a practical way.
What would settle it
Measure goodput when length predictions are replaced with random or constant values and check whether the reported gains over baselines remain.
Figures







read the original abstract
Large Language Models (LLMs) play a critical role in emerging agentic applications, where the timely completion of each entire inference is critical. Meanwhile, agentic LLM inferences are increasingly served on heterogeneous GPUs in operator's resource pools. Therefore, it is crucial to route incoming inference requests to appropriate GPUs so that their end-to-end latency requirements are satisfied whenever possible, thereby achieving high goodput. In this paper, we propose GoodServe, a goodput-optimized serving system for agentic inferences over heterogeneous resources. GoodServe performs inference routing in a predict-and-rectify manner. It estimates the request output lengths as well as the GPU serving status in an accurate and also practical manner. Based on information from both the demand and resource sides, it then makes high-quality routing decisions using a just-enough instance selection heuristic. It also periodically monitors SLO-violation risks of active requests and triggers runtime request migrations to address unexpected dynamics. Our evaluations show that GoodServe improves goodput by up to 27.4% over existing routing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GoodServe, a serving system for agentic LLM inferences over heterogeneous GPUs. It routes requests via a predict-and-rectify approach that estimates output lengths and GPU status, applies a just-enough instance selection heuristic, and uses periodic monitoring plus runtime migrations to mitigate SLO violations. The central empirical claim is an improvement in goodput of up to 27.4% relative to existing routing methods.
Significance. If the reported goodput gains are shown to be robust to realistic prediction error, the work would address a practical need in serving variable, multi-turn agentic workloads on mixed hardware while respecting end-to-end latency targets. The predict-and-rectify plus migration design offers a concrete heuristic that could be adopted in production serving stacks.
major comments (2)
- [Evaluation] Evaluation section: the headline 27.4% goodput improvement is presented without any reported accuracy metrics (MAPE, quantile error, etc.) for the output-length predictor on the agentic traces used. Because the just-enough selection heuristic and migration trigger both depend directly on these estimates, the absence of a sensitivity sweep (e.g., injecting 30-40% error) leaves open whether the measured delta survives realistic non-stationary, heavy-tailed output distributions.
- [§3] §3 (Design): the claim that output lengths and GPU serving status can be estimated 'in an accurate and also practical manner' is load-bearing for the routing decisions, yet the manuscript supplies neither the concrete prediction model nor its training/validation procedure on multi-turn agentic traces. Without this, it is impossible to judge whether the heuristic remains stable when tool calls or conditional branching alter length distributions mid-execution.
minor comments (2)
- The abstract would benefit from a one-sentence summary of the workloads, number of GPUs, and baseline systems used to obtain the 27.4% figure.
- [§4] Notation for 'goodput' and 'SLO-violation risk' should be defined at first use and kept consistent with any equations in §4.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify areas where additional details and analyses would strengthen the presentation of GoodServe's predict-and-rectify routing approach. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the headline 27.4% goodput improvement is presented without any reported accuracy metrics (MAPE, quantile error, etc.) for the output-length predictor on the agentic traces used. Because the just-enough selection heuristic and migration trigger both depend directly on these estimates, the absence of a sensitivity sweep (e.g., injecting 30-40% error) leaves open whether the measured delta survives realistic non-stationary, heavy-tailed output distributions.
Authors: We agree that explicit accuracy metrics for the output-length predictor and a sensitivity analysis to prediction errors are important for validating the robustness of the reported goodput gains. In the revised manuscript, we will add these to the Evaluation section: MAPE, quantile errors, and related metrics computed on the agentic traces. We will also include a sensitivity sweep that injects controlled prediction errors (20-50%) to simulate realistic non-stationary and heavy-tailed conditions, showing that the 27.4% improvement holds under such perturbations. revision: yes
-
Referee: [§3] §3 (Design): the claim that output lengths and GPU serving status can be estimated 'in an accurate and also practical manner' is load-bearing for the routing decisions, yet the manuscript supplies neither the concrete prediction model nor its training/validation procedure on multi-turn agentic traces. Without this, it is impossible to judge whether the heuristic remains stable when tool calls or conditional branching alter length distributions mid-execution.
Authors: We acknowledge that while §3 describes the estimation of output lengths and GPU status at a conceptual level, it does not provide the concrete prediction model or its training/validation details. In the revision, we will expand §3 to specify the prediction model (including its type and features), the training and validation procedures on multi-turn agentic traces, and how the model accounts for dynamics such as tool calls or conditional branching. This will allow assessment of the heuristic's stability. revision: yes
Circularity Check
No circularity: empirical system evaluation with independent performance claims
full rationale
The paper describes a practical serving system (GoodServe) that estimates output lengths and GPU status, applies a just-enough instance selection heuristic, and performs runtime migrations. The headline result (up to 27.4% goodput improvement) is reported as an outcome of evaluations over existing routing methods. No equations, self-citations, or definitions are provided that reduce this empirical delta to a fitted parameter, self-referential prediction, or ansatz imported from prior author work. The estimation step is presented as a precondition rather than a derived result that tautologically produces the gain. This is a standard systems paper whose central claim rests on external benchmarking rather than internal reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GoodServe performs inference routing in a predict-and-rectify manner. It estimates the request output lengths as well as the GPU serving status in an accurate and also practical manner... just-enough instance selection heuristic.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we design a Mixture-of-Experts-style prediction model, which ensembles multiple simple-yet-professional MLPs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Efficient and scalable agentic ai with heteroge- neous systems.arXiv preprint arXiv:2507.19635, 2025
Zain Asgar, Michelle Nguyen, and Sachin Katti. Efficient and scalable agentic ai with heteroge- neous systems.arXiv preprint arXiv:2507.19635, 2025
-
[2]
Ai-powered chat agent: Revolutionizing online shopping
Tina Babu, Rajesh Sharma, et al. Ai-powered chat agent: Revolutionizing online shopping. In2024 2nd International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), pages 1–5. IEEE, 2024
work page 2024
-
[3]
Agrim Bari, Parikshit Hegde, and Gustavo de Veciana. Optimal scheduling algorithms for llm inference: Theory and practice.Proceedings of the ACM on Measurement and Analysis of Computing Systems, 9(3):1–43, 2025
work page 2025
-
[4]
LiteLLM: Python sdk and proxy server for unified llm api access
BerriAI. LiteLLM: Python sdk and proxy server for unified llm api access. https://github. com/BerriAI/litellm, 2026. GitHub repository. Accessed: 2026-04-14
work page 2026
-
[5]
Will Chow. Slice: Slo-driven scheduling for llm inference on edge computing devices.arXiv preprint arXiv:2510.18544, 2025
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Past-future scheduler for llm serving under sla guarantees
Ruihao Gong, Shihao Bai, Siyu Wu, Yunqian Fan, Zaijun Wang, Xiuhong Li, Hailong Yang, and Xianglong Liu. Past-future scheduler for llm serving under sla guarantees. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 798–813, 2025
work page 2025
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, and Ion Stoica. M \’elange: Cost efficient large language model serving by exploiting gpu heterogeneity.arXiv preprint arXiv:2404.14527, 2024
-
[10]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Serving models, fast and slow: optimizing heterogeneous llm inferencing workloads at scale
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St Amant, Chetan Bansal, Victor Rühle, Anoop Kulkarni, et al. Sageserve: Opti- mizing llm serving on cloud data centers with forecast aware auto-scaling.arXiv preprint arXiv:2502.14617, 2025
-
[12]
Demystifying cost-efficiency in llm serving over heterogeneous gpus
Youhe Jiang, Fangcheng Fu, Xiaozhe Yao, Guoliang He, Xupeng Miao, Ana Klimovic, Bin Cui, Binhang Yuan, and Eiko Yoneki. Demystifying cost-efficiency in llm serving over heterogeneous gpus.arXiv preprint arXiv:2502.00722, 2025
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Yunho Jin, Chun-Feng Wu, David Brooks, and Gu-Yeon Wei. S3: Increasing gpu utilization during generative inference for higher throughput.Advances in Neural Information Processing Systems, 36:18015–18027, 2023
work page 2023
-
[15]
KAIROS: Stateful, Context-Aware Power-Efficient Agentic Inference Serving
Hyungjun Kim et al. Kairos: Power-aware serving of agentic ai workloads.arXiv preprint arXiv:2604.16682, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023
work page 2023
-
[17]
{AlpaServe}: Statistical multiplexing with model parallelism for deep learning serving
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. {AlpaServe}: Statistical multiplexing with model parallelism for deep learning serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), pages 663–679, 2023
work page 2023
-
[18]
SEW: Self-Evolving Agentic Workflows for Automated Code Generation
Siwei Liu, Jinyuan Fang, Han Zhou, Yingxu Wang, and Zaiqiao Meng. Sew: Self-evolving agentic workflows for automated code generation.arXiv preprint arXiv:2505.18646, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
llm-d Project. Workload variant autoscaler. https://llm-d.ai/docs/architecture/ Components/workload-variant-autoscaler, 2026. Accessed: 2026-05-05
work page 2026
-
[20]
Helix: Serving large language models over heterogeneous gpus and network via max-flow
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Serving large language models over heterogeneous gpus and network via max-flow. In Proceedings of the 30th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 1, pages 586–602, 2025
work page 2025
-
[21]
Hexgen-flow: Optimizing llm inference request scheduling for agentic text-to-sql
You Peng, Youhe Jiang, Wenqi Jiang, Chen Wang, and Binhang Yuan. Hexgen-flow: Optimizing llm inference request scheduling for agentic text-to-sql.arXiv preprint arXiv:2505.05286, 2025
-
[22]
Xuan-Quang Phan, Tan-Ha Mai, Thai-Duy Dinh, Minh-Thuan Nguyen, and Lam-Son Lê. Askdb: An llm agent for natural language interaction with relational databases.arXiv preprint arXiv:2511.16131, 2025
-
[23]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 155–170, 2025
work page 2025
-
[24]
Ray Project. Ray serve documentation. https://docs.ray.io/en/latest/serve/index. html, 2026. Accessed: 2026-01-25
work page 2026
-
[25]
Ray serve llm routing policies
Ray Project. Ray serve llm routing policies. https://docs.ray.io/en/latest/serve/ llm/architecture/routing-policies.html, 2026. Accessed: 2026-01-25
work page 2026
-
[26]
Pál Révész.The laws of large numbers, volume 4. Academic Press, 2014
work page 2014
-
[27]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
A statistical interpretation of term specificity and its application in retrieval
Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21, 1972
work page 1972
-
[29]
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. Preble: Efficient distributed prompt scheduling for llm serving.arXiv preprint arXiv:2407.00023, 2024
-
[30]
Llumnix: Dynamic scheduling for large language model serving
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24), pages 173–191, 2024
work page 2024
-
[31]
The AIBrix Team, Jiaxin Shan, Varun Gupta, Le Xu, Haiyang Shi, Jingyuan Zhang, Ning Wang, Linhui Xu, Rong Kang, Tongping Liu, et al. Aibrix: Towards scalable, cost-effective large language model inference infrastructure.arXiv preprint arXiv:2504.03648, 2025. 11
-
[32]
vLLM Project. vllm: A high-throughput and memory-efficient inference and serving engine for llms.https://github.com/vllm-project/vllm, 2026. Accessed: 2026-01-25
work page 2026
-
[33]
STAR: Decode-Phase Rescheduling for LLM Inference
Zhibin Wang, Zetao Hong, Xue Li, Zibo Wang, Shipeng Li, Qingkai Meng, Qing Wang, Chengying Huan, Rong Gu, Sheng Zhong, et al. Adaptive rescheduling in prefill-decode disaggregated llm inference.arXiv preprint arXiv:2510.13668, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference
Haoran Wu, Can Xiao, Jiayi Nie, Xuan Guo, Binglei Lou, Jeffrey TH Wong, Zhiwen Mo, Cheng Zhang, Przemyslaw Forys, Chengyang Ai, et al. Combating the memory walls: Optimization pathways for long-context agentic llm inference.arXiv preprint arXiv:2509.09505, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yibo Yan, Shen Wang, Jiahao Huo, Philip S Yu, Xuming Hu, and Qingsong Wen. Mathagent: Leveraging a mixture-of-math-agent framework for real-world multimodal mathematical error detection. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 69–82, 2025
work page 2025
-
[36]
Qwen2.5 technical report, 2025
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page 2025
-
[37]
Jiahuan Yu, Mingtao Hu, Zichao Lin, and Minjia Zhang. Superinfer: Slo-aware rotary schedul- ing and memory management for llm inference on superchips.arXiv preprint arXiv:2601.20309, 2026
work page internal anchor Pith review arXiv 2026
-
[38]
Shibo Yu, Mohammad Goudarzi, and Adel Nadjaran Toosi. Efficient routing of inference requests across llm instances in cloud-edge computing.arXiv preprint arXiv:2507.15553, 2025
-
[39]
Tempo: Application-aware llm serving with mixed slo requirements.arXiv preprint arXiv:2504.20068,
Wei Zhang, Zhiyu Wu, Yi Mu, Rui Ning, Banruo Liu, Nikhil Sarda, Myungjin Lee, and Fan Lai. Jitserve: Slo-aware llm serving with imprecise request information.arXiv preprint arXiv:2504.20068, 2025
-
[40]
Jitserve: Slo-aware llm serving with imprecise request information
Wei Zhang, Zhiyu Wu, Yi Mu, Rui Ning, Banruo Liu, Nikhil Sarda, Myungjin Lee, and Fan Lai. Jitserve: Slo-aware llm serving with imprecise request information. 2025. 12 A Appendix A.1 Notations used inGoodServe Notation Description rRequest index gGPU index RSet of requests GSet of available GPU backends Dr End-to-end latency deadline (SLO) of requestr Lin...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.