Recognition: unknown
KAIROS: Stateful, Context-Aware Power-Efficient Agentic Inference Serving
Pith reviewed 2026-05-10 06:55 UTC · model grok-4.3
The pith
KAIROS tracks evolving agent context to jointly scale GPU frequency, concurrency, and cross-instance placement, delivering 27% average power savings while meeting performance targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KAIROS treats agent context as a first-class signal to manage GPU frequency, per-instance concurrency, and multi-instance placement. It tracks requests at agent granularity, adapts local controls to context growth and agent progress, and routes agents across instances to improve power efficiency while preserving memory stability and performance targets.
What carries the argument
Agent-granularity context tracking that adapts frequency scaling, concurrency caps, and cross-instance routing to context growth and task progress.
If this is right
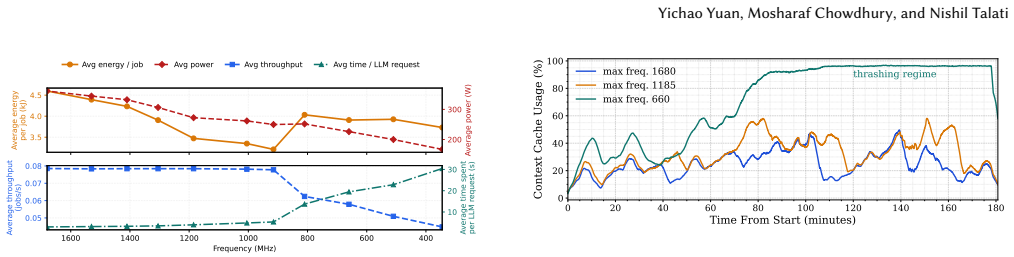
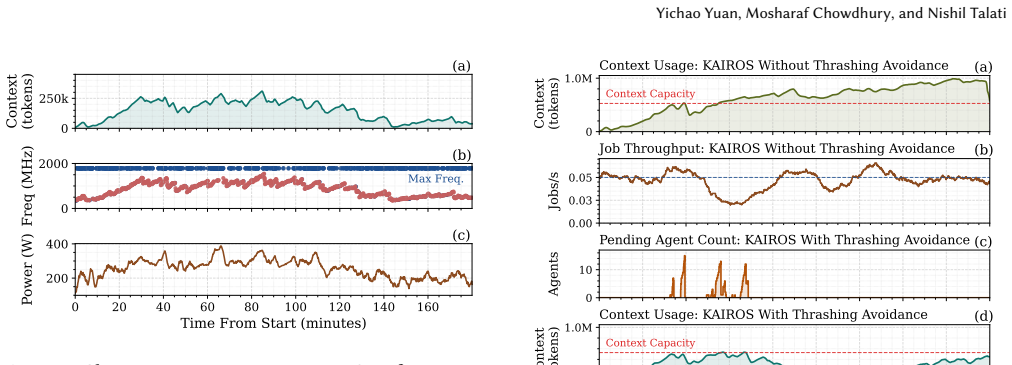
- Power management for agentic serving must treat memory pressure from growing context as a first-order constraint rather than assuming frequency scaling always helps.
- Local frequency and concurrency decisions should be conditioned on agent progress signals to avoid thrashing regimes.
- Cross-instance routing guided by per-agent memory headroom can simultaneously stabilize memory usage and lower total power.
- Average power reductions of 27 percent (up to 39.8 percent) are attainable while still meeting performance targets on representative software and data-engineering agent workloads.
Where Pith is reading between the lines
- Similar context-aware control could apply to other stateful multi-turn AI systems such as long-running simulations or interactive coding environments.
- Hardware designs that expose finer-grained context metadata might reduce the software overhead of the tracking layer KAIROS relies on.
- The approach opens a path to co-optimizing power with other resources such as network bandwidth in distributed agent deployments.
Load-bearing premise
That agent context can be tracked and acted upon as a reliable control signal without overhead that erases the power savings or violates performance targets.
What would settle it
A workload measurement in which the added latency or energy cost of context tracking and routing decisions exceeds the reported power reduction or pushes response times past the stated targets.
Figures










read the original abstract
Power has become a central bottleneck for AI inference. This problem is becoming more urgent as agentic AI emerges as a major workload class, yet prior power-management techniques focus almost entirely on single-turn LLM serving. Our analysis shows that agentic serving behaves fundamentally differently: each request carries long-lived context that evolves across tool-interleaved turns, and lowering GPU frequency can push the system into a thrashing regime where memory pressure sharply worsens both performance and power efficiency. These observations show that power optimization for agentic serving requires rethinking. We present KAIROS, a context-aware power optimization system for agentic AI serving. KAIROS uses agent context as a first-class control signal to jointly manage GPU frequency, per-instance concurrency, and multi-instance request placement. This enables KAIROS to save power when memory headroom exists while avoiding thrashing and preserving performance targets. At a high level, KAIROS tracks requests at agent granularity, adapts local control to context growth and agent progress, and routes agents across instances to jointly improve power efficiency and memory stability. Evaluated across diverse software and data engineering agentic tasks, KAIROS achieves an average of 27% (up to 39.8%) power reduction while meeting the performance targets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KAIROS, a context-aware power optimization system for agentic AI inference serving. It observes that agentic workloads differ from single-turn LLM serving because of long-lived evolving context across tool-interleaved turns and the risk that GPU frequency scaling induces thrashing under memory pressure. KAIROS treats agent context (state, progress, memory headroom) as a first-class signal to jointly control GPU frequency, per-instance concurrency, and multi-instance placement, claiming an average 27% (up to 39.8%) power reduction while meeting performance targets on diverse software and data engineering agentic tasks.
Significance. If the evaluation holds, the work is significant because it identifies a fundamental mismatch between existing power-management techniques and the emerging class of stateful, multi-turn agentic workloads. Treating context as an explicit control input for frequency, concurrency, and placement offers a concrete mechanism to avoid thrashing while still harvesting power savings; the reported quantitative gains provide a useful baseline for future systems work in this area.
major comments (2)
- [Evaluation] Evaluation section: the reported 27% average and 39.8% peak power reductions are stated without any description of the experimental methodology, including workload definitions, baseline systems, hardware platform, measurement methodology, or statistical measures such as error bars or number of runs. This absence prevents assessment of whether the data support the central claim.
- [Evaluation] Evaluation section: the power measurements do not isolate the overhead of context tracking, state maintenance, and cross-instance routing from the GPU power savings. Because the central claim requires that these control-plane mechanisms add negligible cost, the lack of a separate overhead breakdown leaves open the possibility that net savings are smaller than reported while performance targets are still met.
minor comments (1)
- [Abstract] The abstract refers to 'diverse software and data engineering agentic tasks' without naming the specific benchmarks or task distributions used; this detail should appear in the evaluation section for reproducibility.
Simulated Author's Rebuttal
Thank you for the careful review and constructive feedback on our manuscript. We appreciate the recognition that treating agent context as a first-class signal for power management in stateful agentic workloads represents a meaningful departure from prior single-turn LLM techniques. We address each major comment below and will revise the manuscript to strengthen the Evaluation section.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 27% average and 39.8% peak power reductions are stated without any description of the experimental methodology, including workload definitions, baseline systems, hardware platform, measurement methodology, or statistical measures such as error bars or number of runs. This absence prevents assessment of whether the data support the central claim.
Authors: We agree that the submitted manuscript's Evaluation section reports the aggregate power savings without sufficient methodological detail. In the revised version we will expand the section with dedicated subsections that explicitly define: the agentic workloads (specific software-engineering and data-engineering tasks with their context lengths and tool-interleaving patterns), the baseline systems (default DVFS, non-context-aware concurrency limits, and round-robin placement), the hardware platform (GPU models, server configuration, and power instrumentation), the measurement methodology (sampling rates, tools used for GPU and system power, and how performance targets are verified), and statistical reporting (number of runs per configuration and error bars or confidence intervals). These additions will allow readers to evaluate whether the reported figures are supported by the experimental design. revision: yes
-
Referee: [Evaluation] Evaluation section: the power measurements do not isolate the overhead of context tracking, state maintenance, and cross-instance routing from the GPU power savings. Because the central claim requires that these control-plane mechanisms add negligible cost, the lack of a separate overhead breakdown leaves open the possibility that net savings are smaller than reported while performance targets are still met.
Authors: We acknowledge that the current manuscript does not provide a separate accounting of the power and latency overhead introduced by context tracking, state maintenance, and cross-instance routing. In the revision we will add an explicit overhead analysis (either as a new subsection or table) that measures and reports the incremental cost of these control-plane components under the same workloads. This will allow us to demonstrate that the overhead remains small relative to the GPU savings, or, if it is non-negligible in certain regimes, to discuss the net savings transparently while still meeting the stated performance targets. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper is a systems contribution describing KAIROS, a context-aware power management system for agentic inference. It starts from empirical observations about agentic workloads differing from single-turn LLM serving, then presents a design that uses agent context (long-lived state, progress, memory headroom) as a control signal for frequency, concurrency, and placement. The 27% average power reduction is reported from direct evaluation across tasks, not from any equations, fitted parameters, or predictions that reduce to the inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or description; the evaluation measurements are independent of the system description itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association
2024
-
[2]
Amey Agrawal, Haoran Qiu, Junda Chen, Íñigo Goiri, Chaojie Zhang, Rayyan Shahid, Ramachandran Ramjee, Alexey Tumanov, and Esha Choukse. 2024. No Request Left Behind: Tackling Heterogene- ity in Long-Context LLM Inference with Medha.arXiv preprint arXiv:2409.17264(2024). doi:10.48550/arXiv.2409.17264
-
[3]
Mauricio Fadel Argerich and Marta Patiño-Martínez. 2024. Measur- ing and Improving the Energy Efficiency of Large Language Models Inference.IEEE Access12 (2024), 80187–80200. doi:10.1109/ACCESS. 2024.3409745
-
[4]
Zain Asgar, Michelle Nguyen, and Sachin Katti. 2025. Efficient and Scalable Agentic AI with Heterogeneous Systems.arXiv preprint arXiv:2507.19635(2025). doi:10.48550/arXiv.2507.19635
-
[5]
DualScale: Energy-Efficient Disaggregated LLM Serving via Phase-Aware Placement and DVFS
Omar Basit, Yunzhao Liu, Z. Jonny Kong, and Y. Charlie Hu. 2026. BiScale: Energy-Efficient Disaggregated LLM Serving via Phase-Aware Placement and DVFS.arXiv preprint arXiv:2602.18755(2026). doi:10. 48550/arXiv.2602.18755
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Belfer Center for Science and International Affairs. 2025. AI Data Cen- ters and the U.S. Electric Grid.https://www.belfercenter.org/research- analysis/ai-data-centers-us-electric-grid. Accessed: 2026-04-14
2025
-
[7]
Gohar Irfan Chaudhry, Esha Choukse, Haoran Qiu, Íñigo Goiri, Ro- drigo Fonseca, Adam Belay, and Ricardo Bianchini. 2025. Murakkab: Resource-Efficient Agentic Workflow Orchestration in Cloud Plat- forms.arXiv preprint arXiv:2508.18298(2025). doi:10.48550/arXiv.2508. 18298
-
[8]
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang
-
[9]
LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference.arXiv preprint arXiv:2510.09665(2025). doi:10.48550/ arXiv.2510.09665
-
[10]
Jimenez, John Yang, Leyton Ho, Tejal Patward- han, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patward- han, Kevin Liu, and Aleksander Madry. 2024. Introducing SWE-bench Verified.https://openai.com/index/introducing-swe-bench-verified/
2024
-
[11]
arXiv preprint arXiv:2505.06371 (2025)
Jae-Won Chung, Jeff J. Ma, Ruofan Wu, Jiachen Liu, Oh Jun Kweon, Yuxuan Xia, Zhiyu Wu, and Mosharaf Chowdhury. 2025. The ML.ENERGY Benchmark: Toward Automated Inference Energy Mea- surement and Optimization. arXiv:2505.06371 [cs.LG]https://arxiv. org/abs/2505.06371
-
[12]
Ma, and Mosharaf Chowdhury
Jae-Won Chung, Ruofan Wu, Jeff J. Ma, and Mosharaf Chowdhury
- [13]
-
[14]
Characterizing serverless platforms with Serverlessbench
Daniel Crankshaw, Gur-Eyal Sela, Corey Zumar, Xiangxi Mo, Joseph E. Gonzalez, Ion Stoica, and Alexey Tumanov. 2020. InferLine: Latency- Aware Provisioning and Scaling for Prediction Serving Pipelines. In Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20). 477–491. doi:10.1145/3419111.3421285
-
[15]
Christina Delimitrou and Christos Kozyrakis. 2014. Quasar: Resource- Efficient and QoS-Aware Cluster Management. InProceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’14). doi:10.1145/2541940. 2541941
-
[16]
Alex Egg, Martin Iglesias Goyanes, Friso Kingma, Andreu Mora, Le- andro von Werra, and Thomas Wolf. 2025. DABstep: Data Agent Benchmark for Multi-step Reasoning.arXiv preprint arXiv:2506.23719 (2025). doi:10.48550/arXiv.2506.23719
-
[17]
Greeff, David Dion, Star Dorminey, Shailesh Joshi, Yang Chen, Mark Russinovich, and Thomas Moscibroda
Ori Hadary, Luke Marshall, Ishai Menache, Abhisek Pan, Esaias E. Greeff, David Dion, Star Dorminey, Shailesh Joshi, Yang Chen, Mark Russinovich, and Thomas Moscibroda. 2020. Protean: VM Alloca- tion Service at Scale. In14th USENIX Symposium on Operating Sys- tems Design and Implementation (OSDI 20).https://www.usenix.org/ conference/osdi20/presentation/hadary
2020
-
[18]
2026.Harbor: A framework for evaluating and optimizing agents and models in container environments.https: //github.com/harbor-framework/harbor
Harbor Framework Team. 2026.Harbor: A framework for evaluating and optimizing agents and models in container environments.https: //github.com/harbor-framework/harbor
2026
-
[19]
Wenhao He, Youhe Jiang, Penghao Zhao, Quanqing Xu, Eiko Yoneki, Bin Cui, and Fangcheng Fu. 2026. Efficient Multi-round LLM Inference over Disaggregated Serving.arXiv preprint arXiv:2602.14516(2026). doi:10.48550/arXiv.2602.14516
-
[20]
Erik Johannes Husom, Arda Goknil, Lwin Khin Shar, and Sagar Sen
-
[21]
doi:10.48550/ arXiv.2407.16893
The Price of Prompting: Profiling Energy Use in Large Language Models Inference.arXiv preprint arXiv:2407.16893(2024). doi:10.48550/ arXiv.2407.16893
-
[22]
2025.Energy and AI
International Energy Agency. 2025.Energy and AI. Technical Report. International Energy Agency.https://www.iea.org/reports/energy- and-ai
2025
-
[23]
2026.Electricity 2026: Grids
International Energy Agency. 2026.Electricity 2026: Grids. Technical Report. International Energy Agency.https://www.iea.org/reports/ electricity-2026/grids
2026
-
[24]
SageServe: Optimizing LLM Serving on Cloud Data Centers with Forecast Aware Auto-Scaling,
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St. Amant, Chetan Bansal, Victor Rühle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan. 2025. Serving Models, Fast and Slow: Optimizing Heterogeneous LLM Inferencing Workloads at Scale.arXiv preprint arXiv:2502.14617(2025). doi:10. 48550/arXiv.2502.14617
-
[25]
Jimenez, John Yang, Alexander Wettig, Kilian Lieret, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Kilian Lieret, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InThe Twelfth International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=VTF8yNQM66
2024
-
[26]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavarout- sos, Sotirios Xydis, and Dimitrios Soudris. 2024. SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving.arXiv preprint arXiv:2408.05235(2024). doi:10.48550/arXiv.2408.05235
-
[27]
Hao Kang, Ziyang Li, Xinyu Yang, Weili Xu, Yinfang Chen, Junxiong Wang, Beidi Chen, Tushar Krishna, Chenfeng Xu, and Simran Arora
- [28]
-
[29]
Jiin Kim, Byeongjun Shin, Jinha Chung, and Minsoo Rhu. 2026. The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective. In2026 IEEE Interna- tional Symposium on High-Performance Computer Architecture (HPCA). 1–16
2026
-
[30]
Kihyun Kim, Jinwoo Kim, Hyunsun Chung, Myung-Hoon Cha, Hong- Yeon Kim, and Youngjae Kim. 2025. Cost-Efficient LLM Serving in the Cloud: VM Selection with KV Cache Offloading.arXiv preprint arXiv:2504.11816(2025). doi:10.48550/arXiv.2504.11816
-
[31]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[32]
Efficient memory management for large language model serving with PagedAttention
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). 611–626. doi:10.1145/3600006. 3613165
-
[33]
Ruiqi Lai, Hongrui Liu, Chengzhi Lu, Zonghao Liu, Siyu Cao, Siyang Shao, Yixin Zhang, Luo Mai, and Dmitrii Ustiugov. 2025. TokenScale: Timely and Accurate Autoscaling for Disaggregated LLM Serving with Token Velocity.arXiv preprint arXiv:2512.03416(2025). doi:10.48550/ arXiv.2512.03416
-
[34]
Hanchen Li, Qiuyang Mang, Runyuan He, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Hangrui Zhou, Alvin Cheung, Joseph Gonzalez, and Ion Stoica. 2025. Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live.arXiv preprint arXiv:2511.02230(2025). doi:10.48550/arXiv.2511.02230
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.02230 2025
-
[35]
Ecoserve: Designing carbon-aware ai inference systems.arXiv preprint arXiv:2502.05043,
Yueying Li, Zhanqiu Hu, Esha Choukse, Rodrigo Fonseca, G. Edward Suh, and Udit Gupta. 2025. EcoServe: Designing Carbon-Aware AI Inference Systems.arXiv preprint arXiv:2502.05043(2025). doi:10. 48550/arXiv.2502.05043
-
[36]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient Serving of LLM- based Applications with Semantic Variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945. https://www.usenix.org/conference/osdi24/presentation/lin-chaofan
2024
-
[37]
Qunyou Liu, Darong Huang, Marina Zapater, and David Atienza
-
[38]
InProceedings of 63rd ACM/IEEE Design Au- tomation Conference [i.e
GreenLLM: SLO-Aware Dynamic Frequency Scaling for Energy- Efficient LLM Serving. InProceedings of 63rd ACM/IEEE Design Au- tomation Conference [i.e. The Chips to Systems Conference] (DAC ’26). ACM.https://infoscience.epfl.ch/handle/20.500.14299/261894
-
[39]
David Lo, Liqun Cheng, Rama Govindaraju, Parthasarathy Ran- ganathan, and Christos Kozyrakis. 2015. Heracles: Improving Resource Efficiency at Scale. InProceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA ’15). doi:10.1145/2749469. 2749475
-
[40]
Alexandra Sasha Luccioni, Yacine Jernite, and Emma Strubell. 2024. Power Hungry Processing: Watts Driving the Cost of AI Deployment?. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). Association for Computing Machinery, 85–99. doi:10.1145/3630106.3658542
-
[41]
arXiv preprint arXiv:2502.13965 , year =
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, and Ion Stoica. 2025. Autellix: An Efficient Serving Engine for LLM Agents as General Programs.arXiv preprint arXiv:2502.13965 (2025). doi:10.48550/arXiv.2502.13965
-
[42]
Paul Joe Maliakel, Shashikant Ilager, and Ivona Brandic. 2025. Charac- terizing LLM Inference Energy-Performance Tradeoffs across Work- loads and GPU Scaling.arXiv preprint arXiv:2501.08219(2025). doi:10.48550/arXiv.2501.08219
-
[43]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Wal- she, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
work page internal anchor Pith review arXiv 2026
-
[44]
MLCommons. 2026. MLPerf Inference: Datacenter.https:// mlcommons.org/benchmarks/inference-datacenter/. Accessed: 2026- 04-09
2026
-
[45]
Rohit Mural, Ryan Rafaty, Vennila Varadarajan, and Yitian Xu. 2026. AI, Data Centers, and the U.S. Electric Grid. Technical Report. Belfer Center for Science and International Affairs, Harvard Kennedy School.https://www.belfercenter.org/sites/default/files/2026-02/ Mural%20et%20al_AI%20Data%20Centers%20Grid_20260206.pdf
2026
-
[46]
Chenxu Niu, Wei Zhang, Jie Li, Yongjian Zhao, Tongyang Wang, Xi Wang, and Yong Chen. 2026. TokenPowerBench: Benchmarking the Power Consumption of LLM Inference. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 32582–32590. doi:10.1609/ aaai.v40i38.40535
2026
-
[47]
Miray Özcan, Philipp Wiesner, Philipp Weiß, and Odej Kao. 2025. Quantifying the Energy Consumption and Carbon Emissions of LLM Inference via Simulations.arXiv preprint arXiv:2507.11417(2025). doi:10.48550/arXiv.2507.11417
-
[48]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). doi:10.1109/ISCA59077.2024.00019
-
[49]
Archit Patke, Dhemath Reddy, Saurabh Jha, Chandra Narayanaswami, Zbigniew Kalbarczyk, and Ravishankar Iyer. 2025. Hierarchical Au- toscaling for Large Language Model Serving with Chiron.arXiv preprint arXiv:2501.08090(2025). doi:10.48550/arXiv.2501.08090
-
[50]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ram- jee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Man- agement for Serving LLMs without PagedAttention. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25). doi:10.1145/3669940.3707256
-
[51]
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Tamer Başar, and Ravishankar K. Iyer. 2024. Power-aware Deep Learning Model Serving with 𝜇-Serve. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 75–93.https://www.usenix.org/conference/atc24/ presentation/qiu
2024
-
[52]
Ritik Raj, Hong Wang, and Tushar Krishna. 2025. A CPU-Centric Perspective on Agentic AI.arXiv preprint arXiv:2511.00739(2025). doi:10.48550/arXiv.2511.00739
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.00739 2025
-
[53]
Yeonju Ro, Haoran Qiu, Íñigo Goiri, Rodrigo Fonseca, Ricardo Bian- chini, Aditya Akella, Zhangyang Wang, Mattan Erez, and Esha Choukse. 2025. Sherlock: Reliable and Efficient Agentic Workflow Execution.arXiv preprint arXiv:2511.00330(2025). doi:10.48550/arXiv. 2511.00330 13 Yichao Yuan, Mosharaf Chowdhury, and Nishil Talati
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[54]
Keshav Santhanam, Deepti Raghavan, Muhammad Shahir Rahman, Thejas Venkatesh, Neha Kunjal, Pratiksha Thaker, Philip Levis, and Matei Zaharia. 2024. ALTO: An Efficient Network Orchestrator for Compound AI Systems. InProceedings of the 4th Workshop on Machine Learning and Systems (EuroMLSys ’24). 117–125. doi:10.1145/3642970. 3655844
-
[55]
Noah Shinn, Federico Cassano, Bailin Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Lan- guage Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1b44b878bb782e6954cd888628510e90-Abstract-Conference.html
2023
-
[56]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. InThe Ninth International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2010.03768
work page internal anchor Pith review arXiv 2021
-
[57]
Gursimran Singh, Timothy Yu, Haley Li, Cheng Chen, Hanieh Sadri, Qintao Zhang, Yu Zhang, Ying Xiong, Yong Zhang, and Zhenan Fan
-
[58]
arXiv:2510.02613 [cs.DC]https://arxiv.org/abs/2510
ElasticMoE: An Efficient Auto Scaling Method for Mixture-of- Experts Models.arXiv preprint arXiv:2510.02613(2025). doi:10.48550/ arXiv.2510.02613
-
[59]
Jeffrey Spaan, Kuan-Hsun Chen, and Ana-Lucia Varbanescu. 2026. Reducing Compute Waste in LLMs through Kernel-Level DVFS.arXiv preprint arXiv:2601.08539(2026). doi:10.48550/arXiv.2601.08539
-
[60]
Jovan Stojkovic, Esha Choukse, Chaojie Zhang, Inigo Goiri, and Josep Torrellas. 2024. Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference.arXiv preprint arXiv:2403.20306 (2024). doi:10.48550/arXiv.2403.20306
-
[61]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Esha Choukse, Haoran Qiu, Rodrigo Fonseca, Josep Torrellas, and Ricardo Bianchini. 2025. TAPAS: Thermal- and Power-Aware Scheduling for LLM Inference in Cloud Platforms. InProceedings of the 30th ACM International Confer- ence on Architectural Support for Programming Languages and Operat- ing Systems (ASPLOS ’2...
-
[62]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. InProceedings of the 2025 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE Computer Society, 1348–1362. doi:10.1109/HPCA61900. 2025.00102
-
[63]
Noppanat Wadlom, Junyi Shen, and Yao Lu. 2026. Efficient LLM Serving for Agentic Workflows: A Data Systems Perspective.arXiv preprint arXiv:2603.16104(2026). doi:10.48550/arXiv.2603.16104
-
[64]
Zibo Wang, Yijia Zhang, Fuchun Wei, Bingqiang Wang, Yanlin Liu, Zhiheng Hu, Jingyi Zhang, Xiaoxin Xu, Jian He, Xiaoliang Wang, Wanchun Dou, Guihai Chen, and Chen Tian. 2025. Using Analyti- cal Performance/Power Model and Fine-Grained DVFS to Enhance AI Accelerator Energy Efficiency. InProceedings of the 30th ACM International Conference on Architectural S...
-
[65]
Patrick Wilhelm, Thorsten Wittkopp, and Odej Kao. 2025. Beyond Test-Time Compute Strategies: Advocating Energy-per-Token in LLM Inference. InProceedings of the 5th Workshop on Machine Learning and Systems (EuroMLSys ’25). Association for Computing Machinery, Rotterdam, Netherlands, 1–8. doi:10.1145/3721146.3721953
-
[66]
Grant Wilkins, Srinivasan Keshav, and Richard Mortier. 2024. Hybrid Heterogeneous Clusters Can Lower the Energy Consumption of LLM Inference Workloads. InProceedings of the 15th ACM International Conference on Future and Sustainable Energy Systems(Singapore, Sin- gapore)(e-Energy ’24). Association for Computing Machinery, New York, NY, USA, 506–513. doi:1...
-
[67]
Grant Wilkins, Srinivasan Keshav, and Richard Mortier. 2024. Offline Energy-Optimal LLM Serving: Workload-Based Energy Models for LLM Inference on Heterogeneous Systems. InProceedings of the 3rd ACM HotCarbon Workshop on Sustainable Computer Systems (HotCar- bon ’24). Association for Computing Machinery, Santa Cruz, CA, USA, 1–7. doi:10.1145/3727200.3727217
-
[68]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. 2024. SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.https://arxiv.org/abs/2405.15793
work page internal anchor Pith review arXiv 2024
-
[69]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan
-
[70]
InAdvances in Neural Information Processing Systems (NeurIPS), Vol
WebShop: Towards Scalable Real-World Web Inter- action with Grounded Language Agents. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 82ad13ec01f9fe44c01cb91814fd7b8c-Abstract-Conference.html
2022
-
[71]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations (ICLR)
2023
-
[72]
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. 2023. Zeus: Under- standing and Optimizing GPU Energy Consumption of DNN Training. InUSENIX NSDI
2023
-
[73]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. ORCA: A Distributed Serving System for Transformer-Based Generative Models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI). USENIX Association, 521–538
2022
- [74]
-
[75]
Wei Zhang, Zhiyu Wu, Yi Mu, Rui Ning, Banruo Liu, Nikhil Sarda, Myungjin Lee, and Fan Lai. 2026. JITServe: SLO-aware LLM Serving with Imprecise Request Information. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26). USENIX Association.https://www.usenix.org/conference/nsdi26/presentation/ zhang-wei
2026
-
[76]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210.https://www.usenix.org/ conference/osdi24/presentation/zhong-yinmin
2024
-
[77]
http://127.0.0.1:24157
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. 2024. Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 62138–62160.https: //proceedings.mlr.press/v235/zhou2...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.