Biological Reasoning-Informed Regression for Interpretable Regulatory DNA Activity Prediction
Pith reviewed 2026-06-27 18:59 UTC · model grok-4.3
The pith
R3LM teaches language models to reason over structured biological data before regressing regulatory DNA activity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By structuring DNA regulatory information into a biologically grounded format and building CRE-ReasonBench to link sequences, activity scores, and mechanistic reasoning traces, two-stage training first teaches language models to reason over the structured knowledge and then to perform regression, yielding state-of-the-art enhancer activity prediction across three cell types while generating interpretable explanations that outperform both raw-sequence language models and specialized DNA models.
What carries the argument
The R3LM framework, which uses a biologically grounded data format for regulatory sequences together with reasoning traces from the CRE-ReasonBench dataset and applies two-stage training to enable reasoning-informed regression in language models.
If this is right
- Enhancer activity prediction reaches higher accuracy across three cell types than either raw-sequence language models or existing specialized DNA models.
- Predictions are accompanied by mechanistic reasoning traces that make the outputs interpretable.
- The trained model can function as an interpretable reward model for assisting in cis-regulatory element design.
- Language models can be adapted to biological regression tasks through added reasoning supervision rather than raw sequence input alone.
Where Pith is reading between the lines
- The same combination of structured biological formatting and reasoning traces could be applied to other sequence-to-function tasks such as promoter strength or variant effect prediction.
- If the performance gain comes mainly from the reasoning stage, general language models might reduce reliance on task-specific DNA architectures when similar datasets exist.
- Explanations generated by the model could be checked against experimental assays to iteratively improve the quality of the reasoning traces in future datasets.
Load-bearing premise
The assumption that supplying a structured biological format plus mechanistic reasoning traces will let language models reach higher regression accuracy and produce accurate explanations after two-stage training.
What would settle it
After two-stage training on CRE-ReasonBench, the resulting model fails to exceed baseline performance on enhancer activity prediction in the three tested cell types or produces mechanistic explanations that do not align with known regulatory biology on held-out sequences.
Figures

read the original abstract
DNA cis-regulatory elements (CREs) such as enhancers control gene expression levels. Accurately predicting regulatory activity from DNA sequences is valuable but challenging, as it requires understanding complex biological regulatory processes. Existing methods typically regress activity scores from sequences in a black-box manner, limiting both interpretability and regression performance. Meanwhile, large language models (LLMs) benefit from explicit reasoning processes, yet directly applying LLMs to raw DNA sequences performs poorly. In this paper, we bridge this gap by introducing R3LM, a framework that teaches LLMs reasoning-informed regression on regulatory DNA through structured biological knowledge. Specifically, we design a biologically grounded data format that structures DNA's regulatory information for improved LLM understanding, and construct CRE-ReasonBench, the first dataset that associates DNA sequences and activity scores with mechanistic reasoning traces. Through two-stage training that first teaches LLMs reasoning over structured biological information then performs regression, R3LM achieves state-of-the-art performance on enhancer prediction across three cell types, outperforming both LLMs with raw sequence input and specialized DNA models while providing interpretable mechanistic explanations. We expect R3LM as an interpretable reward model that can effectively assist biologists in CRE design. Code is available at https://github.com/DuanYi516/R3LM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces R3LM, a framework that teaches LLMs reasoning-informed regression for predicting regulatory DNA (enhancer) activity. It uses a biologically grounded structured data format for DNA sequences and constructs CRE-ReasonBench, a dataset pairing sequences and activity scores with mechanistic reasoning traces. A two-stage training process first teaches reasoning over the structured information then performs regression; the abstract claims this yields state-of-the-art performance across three cell types, outperforming both raw-sequence LLMs and specialized DNA models while supplying interpretable mechanistic explanations usable as a reward model for CRE design.
Significance. If the central performance and interpretability claims hold with rigorous evidence, the work would be a meaningful contribution to regulatory genomics by moving beyond black-box sequence regression toward biologically grounded LLM reasoning, while also releasing a new reasoning-annotated benchmark dataset.
major comments (1)
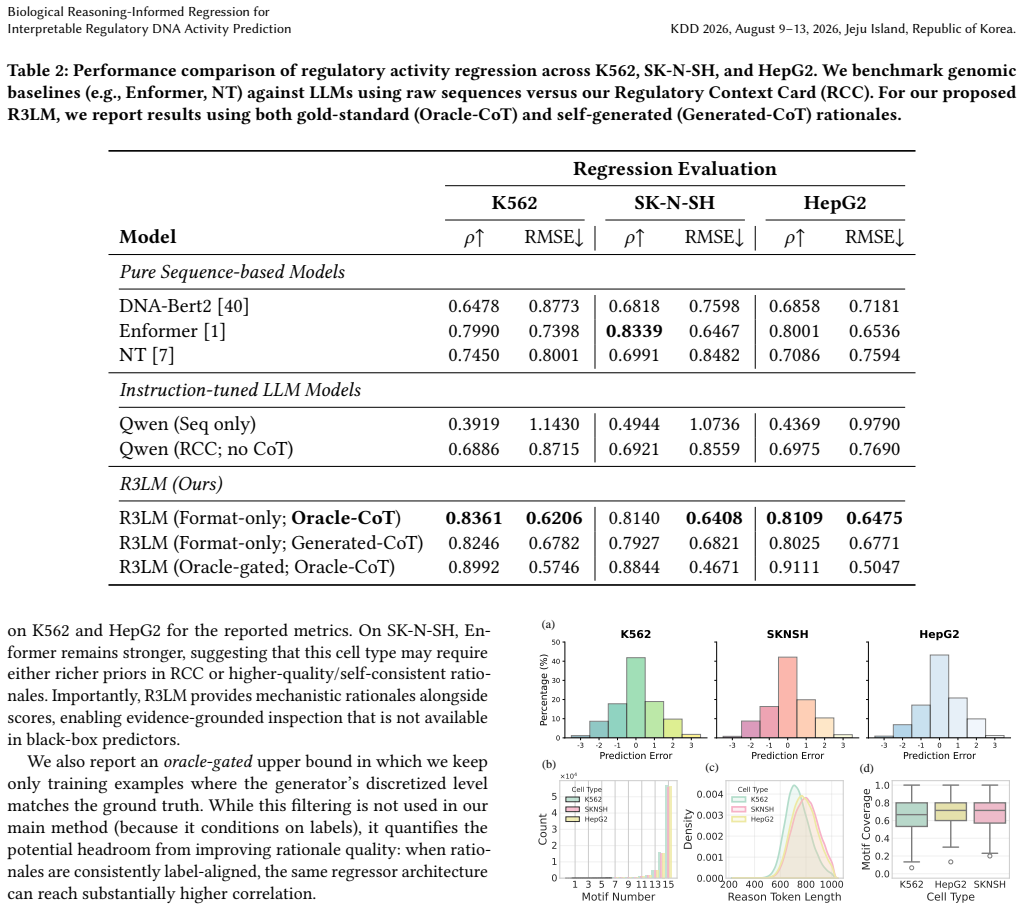
- [Abstract] Abstract: the claim that R3LM 'achieves state-of-the-art performance on enhancer prediction across three cell types, outperforming both LLMs with raw sequence input and specialized DNA models' is load-bearing for the paper's central contribution, yet the abstract supplies no quantitative metrics, baselines, statistical tests, or experimental details to support it.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below and agree that the abstract requires strengthening with quantitative details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that R3LM 'achieves state-of-the-art performance on enhancer prediction across three cell types, outperforming both LLMs with raw sequence input and specialized DNA models' is load-bearing for the paper's central contribution, yet the abstract supplies no quantitative metrics, baselines, statistical tests, or experimental details to support it.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the performance claims. In the revised manuscript we will update the abstract to report the key Pearson correlation values achieved by R3LM on the three cell types, the specific baselines (both raw-sequence LLMs and specialized DNA models) against which it was compared, and a brief statement of the evaluation protocol and statistical significance. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical ML framework: construction of CRE-ReasonBench dataset with reasoning traces, a biologically structured data format, and two-stage LLM training for regression. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. Central claims rest on experimental SOTA results rather than any reduction to inputs by construction. This is a standard non-circular empirical training setup.
Axiom & Free-Parameter Ledger
free parameters (1)
- two-stage training hyperparameters
axioms (1)
- domain assumption Explicit reasoning processes improve LLM performance on complex tasks
Reference graph
Works this paper leans on
-
[1]
Žiga Avsec, Vikram Agarwal, Daniel Visentin, Joseph R Ledsam, Agnieszka Grabska-Barwinska, Kyle R Taylor, Yannis Assael, John Jumper, Pushmeet Kohli, and David R Kelley. 2021. Effective gene expression prediction from sequence by integrating long-range interactions.Nature methods18, 10 (2021), 1196–1203
2021
-
[2]
Žiga Avsec, Natasha Latysheva, Jun Cheng, Guido Novati, Kyle R Taylor, Tom Ward, Clare Bycroft, Lauren Nicolaisen, Eirini Arvaniti, Joshua Pan, et al. 2026. Advancing regulatory variant effect prediction with AlphaGenome.Nature649, 8099 (2026), 1206–1218
2026
-
[3]
Ying Ba, Tianyu Zhang, Yalong Bai, Wenyi Mo, Tao Liang, Bing Su, and Ji- Rong Wen. 2025. Enhancing Reward Models for High-quality Image Generation: Beyond Text-Image Alignment. arXiv:2507.19002 [cs.CV] https://arxiv.org/abs/ 2507.19002
arXiv 2025
-
[4]
Timothy L Bailey, James Johnson, Charles E Grant, and William S Noble. 2015. The MEME suite.Nucleic acids research43, W1 (2015), W39–W49
2015
-
[5]
Xingyu Chen, Shihao Ma, Runsheng Lin, Jiecong Lin, and Bo Wang. 2025. Ctrl- DNA: Controllable Cell-Type-Specific Regulatory DNA Design via Constrained RL. arXiv:2505.20578 [cs.LG] https://arxiv.org/abs/2505.20578
arXiv 2025
-
[6]
Cheng-Han Chiang, Hung yi Lee, and Michal Lukasik. 2025. TRACT: Regression- Aware Fine-tuning Meets Chain-of-Thought Reasoning for LLM-as-a-Judge. arXiv:2503.04381 [cs.CL] https://arxiv.org/abs/2503.04381
arXiv 2025
-
[7]
Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Car- ranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P. de Almeida, Hassan Sirelkhatim, Guillaume Richard, Marcin Skwark, Karim Beguir, Marie Lopez, and Thomas Pierrot. 2025. Nucleotide Trans- former: building and evaluating robust foundation m...
-
[8]
Bernardo P. de Almeida, Guillaume Richard, Hugo Dalla-Torre, Christopher Blum, Lorenz Hexemer, Priyanka Pandey, Stefan Laurent, Chandana Rajesh, Marie Lopez, Alexandre Laterre, Maren Lang, Uğur Şahin, Karim Beguir, and Thomas Pierrot. 2025. A multimodal conversational agent for DNA, RNA and protein tasks.Nature Machine Intelligence7, 6 (01 Jun 2025), 928–...
-
[9]
Bernardo P de Almeida, Christoph Schaub, Michaela Pagani, Stefano Secchia, Eileen EM Furlong, and Alexander Stark. 2024. Targeted design of synthetic enhancers for selected tissues in the Drosophila embryo.Nature626, 7997 (2024), 207–211
2024
-
[10]
Carl G de Boer, Eeshit Dhaval Vaishnav, Ronen Sadeh, Esteban Luis Abeyta, Nir Friedman, and Aviv Regev. 2020. Deciphering eukaryotic gene-regulatory logic with 100 million random promoters.Nature biotechnology38, 1 (2020), 56–65
2020
-
[11]
Seppe De Winter, Vasileios Konstantakos, and Stein Aerts. 2025. Modelling and design of transcriptional enhancers.Nature Reviews Bioengineering3 (2025), 374–389
2025
-
[12]
Kseniia Dudnyk, Donghong Cai, Chenlai Shi, Jian Xu, and Jian Zhou. 2024. Sequence basis of transcription initiation in the human genome.Science384, 6694 (2024), eadj0116
2024
-
[13]
Adibvafa Fallahpour, Andrew Magnuson, Purav Gupta, Shihao Ma, Jack Naimer, Arnav Shah, Haonan Duan, Omar Ibrahim, Hani Goodarzi, Chris J. Maddison, and Bo Wang. 2025. BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model. arXiv:2505.23579 [cs.LG] https://arxiv.org/abs/2505.23579
arXiv 2025
-
[14]
Tianshun Gao and Jiang Qian. 2020. EnhancerAtlas 2.0: an updated resource with enhancer annotation in 586 tissue/cell types across nine species.Nucleic acids research48, D1 (2020), D58–D64
2020
-
[15]
Ilias Georgakopoulos-Soares, Chengyu Deng, Vikram Agarwal, Candace SY Chan, Jingjing Zhao, Fumitaka Inoue, and Nadav Ahituv. 2023. Transcription factor binding site orientation and order are major drivers of gene regulatory activity. Nature communications14, 1 (2023), 2333
2023
-
[16]
Laura H Goetz and Nicholas J Schork. 2018. Personalized medicine: motivation, challenges, and progress.Fertility and sterility109, 6 (2018), 952–963
2018
-
[17]
Sager J Gosai, Rodrigo I Castro, Natalia Fuentes, John C Butts, Kousuke Mouri, Michael Alasoadura, Susan Kales, Thanh Thanh L Nguyen, Ramil R Noche, Arya S Rao, et al. 2024. Machine-guided design of cell-type-targeting cis-regulatory elements.Nature634, 8036 (2024), 1211–1220
2024
-
[18]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[19]
Jiaxin Guo, Zewen Chi, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. 2025. Reward Reasoning Model. arXiv:2505.14674 [cs.CL] https: //arxiv.org/abs/2505.14674
arXiv 2025
-
[20]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2023. Large Language Models are Zero-Shot Reasoners. arXiv:2205.11916 [cs.CL] https://arxiv.org/abs/2205.11916
Pith/arXiv arXiv 2023
-
[21]
Avantika Lal, David Garfield, Tommaso Biancalani, and Gokcen Eraslan. 2024. De- signing realistic regulatory DNA with autoregressive language models.Genome Research34, 9 (2024), 1411–1420
2024
-
[22]
Zehui Li, Vallijah Subasri, Yifei Shen, Dongsheng Li, Wentao Gu, Guy-Bart Stan, Yiren Zhao, and Caihua Shan. 2026. Omni-DNA: a Genomic model supporting sequence understanding, long-context, and textual annotation.Advances in Neural Information Processing Systems38 (2026), 133044–133072
2026
-
[23]
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. 2024. Conflict- Averse Gradient Descent for Multi-task Learning. arXiv:2110.14048 [cs.LG] https://arxiv.org/abs/2110.14048
arXiv 2024
-
[24]
Aaron J Lorenz, Shiaoman Chao, Franco G Asoro, Elliot L Heffner, Takeshi Hayashi, Hiroyoshi Iwata, Kevin P Smith, Mark E Sorrells, and Jean-Luc Jannink
-
[25]
Genomic selection in plant breeding: knowledge and prospects.Advances in agronomy110 (2011), 77–123
2011
-
[26]
Damla Ovek Baydar, Ieva Rauluseviciute, Dina R Aronsen, Romain Blanc-Mathieu, Ine Bonthuis, Herman de Beukelaer, Katalin Ferenc, Alice Jegou, Vipin Ku- mar, Roza Berhanu Lemma, Jérémy Lucas, Mathis Pochon, Chang M Yun, Vivekanandan Ramalingam, Salil Sanjay Deshpande, Aman Patel, Georgi K Marinov, Austin T Wang, Alejandro Aguirre, Jaime A Castro-Mondragon,...
-
[27]
Tomas Pachano, Víctor Sánchez-Gaya, Thais Ealo, Maria Mariner-Faulí, Tore Bleckwehl, {Helena G.} Asenjo, Patricia Respuela, Sara Cruz-Molina, María {Muñoz-San Martín}, Endika Haro, {Wilfred F.J.} {van IJcken}, David Landeira, and Alvaro Rada-Iglesias. 2021. Orphan CpG islands amplify poised enhancer regulatory activity and determine target gene responsive...
-
[28]
Aniketh Janardhan Reddy, Xinyang Geng, Michael Herschl, Sathvik Kolli, Aviral Kumar, Patrick Hsu, Sergey Levine, and Nilah Ioannidis. 2024. Designing cell- type-specific promoter sequences using conservative model-based optimization. Advances in Neural Information Processing Systems37 (2024), 93033–93059
2024
-
[29]
Aniketh Janardhan Reddy, Michael H Herschl, Xinyang Geng, Sathvik Kolli, Amy X Lu, Aviral Kumar, Patrick D Hsu, Sergey Levine, and Nilah M Ioannidis
-
[30]
Strategies for effectively modelling promoter-driven gene expression using transfer learning. 2023–02 pages. doi:10.1101/2023.02.24.529941
-
[31]
Eilon Sharon, Yael Kalma, Ayala Sharp, Tali Raveh-Sadka, Michal Levo, Danny Zeevi, Leeat Keren, Zohar Yakhini, Adina Weinberger, and Eran Segal. 2012. Infer- ring gene regulatory logic from high-throughput measurements of thousands of systematically designed promoters.Nature biotechnology30, 6 (2012), 521–530
2012
-
[32]
Ibrahim I Taskiran, Katina I Spanier, Hannah Dickmänken, Niklas Kempynck, Alexandra Pančíková, Eren Can Ekşi, Gert Hulselmans, Joy N Ismail, Koen Theu- nis, Roel Vandepoel, et al. 2024. Cell-type-directed design of synthetic enhancers. Nature626, 7997 (2024), 212–220
2024
-
[33]
Eeshit Dhaval Vaishnav, Carl G de Boer, Jennifer Molinet, Moran Yassour, Lin Fan, Xian Adiconis, Dawn A Thompson, Joshua Z Levin, Francisco A Cubillos, and Aviv Regev. 2022. The evolution, evolvability and engineering of gene regulatory DNA.Nature603, 7901 (2022), 455–463
2022
-
[34]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171 [cs.CL] https://arxiv.org/abs/2203.11171
Pith/arXiv arXiv 2023
-
[35]
Yajie Wang, Pu Xue, Mingfeng Cao, Tianhao Yu, Stephan T Lane, and Huimin Zhao. 2021. Directed evolution: methodologies and applications.Chemical reviews 121, 20 (2021), 12384–12444
2021
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL] https: //arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[37]
Anouck Wijgaerts, Christine Wittevrongel, Chantal Thys, Timothy Devos, Kathe- lijne Peerlinck, Marloes R Tijssen, Chris Van Geet, and Kathleen Freson. 2017. The transcription factor GATA1 regulates NBEAL2 expression through a long- distance enhancer.Haematologica102, 4 (2017), 695
2017
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[39]
Zhao Yang, Bing Su, Chuan Cao, and Ji-Rong Wen. 2025. Regulatory DNA Sequence Design with Reinforcement Learning. InInternational Conference on Learning Representations, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 73499–73524. https://proceedings.iclr.cc/paper_files/paper/2025/file/ b65b7e0d910fbb9f05b2c1d241e7ade1-Paper-Conference.pdf
2025
-
[40]
Zhao Yang, Jiwei Zhu, and Bing Su. 2025. SPACE: Your Genomic Profile Predictor is a Powerful DNA Foundation Model. InForty-second International Conference on Machine Learning
2025
-
[41]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo
-
[42]
doi: 10.18653/v1/2024.acl-demos.38
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Yixin Cao, Yang Feng, and Deyi Xiong (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 400–410. doi:10.18653/v1/2024.acl-demos.38
-
[43]
Zhihan Zhou, Yanrong Ji, Weijian Li, Pratik Dutta, Ramana Davuluri, and Han Liu
-
[44]
DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome. arXiv:2306.15006 [q-bio.GN] https://arxiv.org/abs/2306.15006 A Training Details Data split.All training/validation/test samples follow the official regLM split. Stage-I supervised fine-tuning.For each cell type, we curate 1,000 instruction-following training instances generated ...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.