Remember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
Pith reviewed 2026-05-22 06:40 UTC · model grok-4.3
The pith
Persistent 3D reconstruction and RGB sequence modeling enable effective curiosity-driven exploration in 3D environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
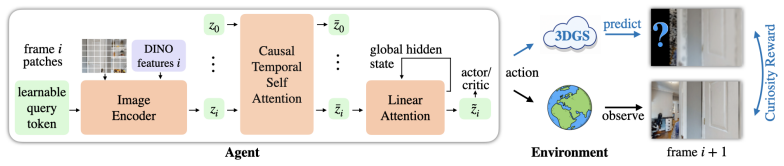
The authors claim that curiosity requires both spatial persistence through a continuously updated world model and episodic context through trajectory history. They implement the persistent model via online 3D reconstruction and the episodic context via a sequence model over raw RGB frames. This lets the agent explore effectively during training and navigate at deployment using only RGB observations.
What carries the argument
Online 3D reconstruction as persistent world model together with sequence model over RGB observations for episodic context in the policy.
If this is right
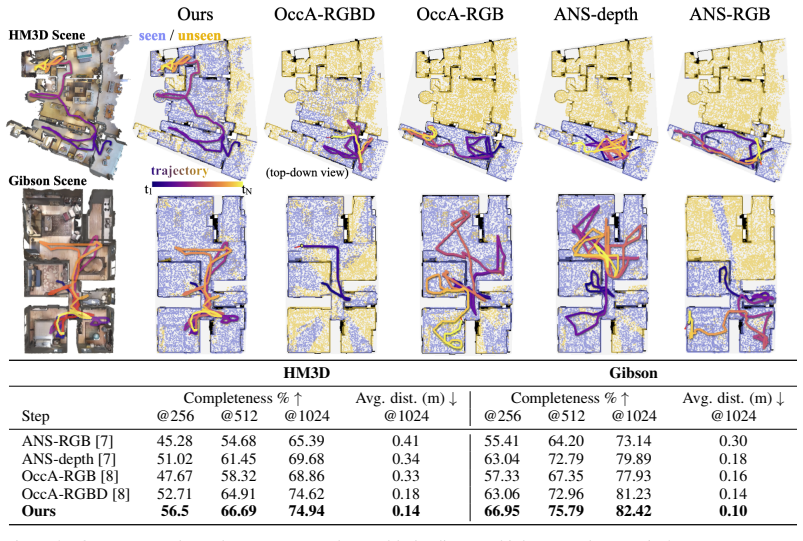
- The curiosity-trained agent outperforms RL active mapping baselines on HM3D.
- It generalizes zero-shot to Gibson and procedurally generated worlds.
- It adapts efficiently to tasks like apple picking and image-goal navigation.
- Adaptation outperforms training those tasks from scratch.
Where Pith is reading between the lines
- This combination of persistence and memory may address similar looping issues in other long-horizon RL problems.
- The method suggests that explicit mapping can complement learned policies in navigation without sacrificing end-to-end RGB control at test time.
- Extensions could test the approach with noisy real-world sensor data instead of perfect simulation.
Load-bearing premise
The online 3D reconstruction remains accurate enough over long trajectories in cluttered scenes and the RGB sequence model alone provides sufficient memory to avoid state revisits.
What would settle it
If long-horizon trials in cluttered indoor environments show frequent revisits to the same locations or incomplete coverage despite the 3D model and sequence policy, the necessity of these components for effective curiosity would be called into question.
Figures




read the original abstract
Exploration is a prerequisite for learning useful behaviors in sparse-reward, long-horizon tasks, particularly within 3D environments. Curiosity-driven reinforcement learning addresses this via intrinsic rewards derived from the mismatch between the agent's predictive model of the world and reality. However, translating this intrinsic motivation to complex, photorealistic environments remains difficult, as agents can become trapped in local loops and receive fresh rewards for revisiting forgotten states. In this work, we demonstrate that this failure stems from a lack of spatial persistence and episodic context. We show that effective curiosity requires a model of the world that is persistent and continuously updated, paired with an agent that maintains an episodic trajectory history to navigate toward novel regions. We achieve this using an online 3D reconstruction as a persistent model of the world, while the agent policy is parameterized as a sequence model over RGB observations to maintain episodic context. This design enables effective exploration during training while allowing the agent to navigate using solely RGB frames at deployment. Trained purely via curiosity on HM3D, our agent outperforms RL-based active mapping baselines and generalizes zero-shot to Gibson and AI-generated worlds. Our end-to-end policy enables efficient adaptation to downstream tasks, such as apple picking and image-goal navigation, outperforming from-scratch baselines. Please see video results at https://recuriosity.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a curiosity-driven exploration approach for photorealistic 3D environments. It claims that effective intrinsic motivation requires a persistent world model implemented via online 3D reconstruction paired with episodic context supplied by a sequence model over raw RGB observations. The policy is trained end-to-end using only curiosity rewards on HM3D, after which it is reported to outperform RL-based active mapping baselines, to generalize zero-shot to Gibson and procedurally generated worlds, and to enable efficient fine-tuning on downstream tasks such as apple picking and image-goal navigation.
Significance. If the empirical results hold, the work would be a meaningful contribution to embodied exploration and intrinsic motivation. By supplying an explicit spatial substrate for the curiosity signal and a lightweight episodic memory via sequence modeling, the method directly targets the local-loop failure mode that has limited prior curiosity agents in cluttered indoor scenes. The fact that the final policy operates from RGB alone at deployment time is practically attractive. The combination of reconstruction-based persistence with standard sequence modeling is a clean architectural choice that could be adopted more broadly.
major comments (2)
- [§4] §4 (Experimental results): The abstract and main claims assert outperformance over RL-based active mapping baselines together with zero-shot transfer, yet the text provides neither the numerical metrics, baseline implementation details, nor ablation tables needed to evaluate those claims. Without these data the strength of evidence for the central thesis cannot be assessed.
- [Reconstruction and reward section] Reconstruction and reward section: The method relies on the online 3D reconstruction remaining sufficiently accurate and complete to generate a reliable curiosity signal across hundreds to thousands of steps in cluttered HM3D scenes. No quantitative reconstruction-quality metrics (coverage, drift, or map-vs-ground-truth overlap) are reported, leaving the load-bearing premise that the persistent map correctly labels novel versus visited regions unverified.
minor comments (2)
- [Figure 1] The architecture diagram would benefit from explicit arrows showing how the reconstruction output is used only for the intrinsic reward and not as input to the policy at deployment time.
- [§3.2] A short paragraph clarifying the exact form of the episodic context (length of RGB history, attention mechanism, etc.) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential contribution to embodied exploration and for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the empirical support.
read point-by-point responses
-
Referee: [§4] §4 (Experimental results): The abstract and main claims assert outperformance over RL-based active mapping baselines together with zero-shot transfer, yet the text provides neither the numerical metrics, baseline implementation details, nor ablation tables needed to evaluate those claims. Without these data the strength of evidence for the central thesis cannot be assessed.
Authors: We agree that the current presentation of results in Section 4 lacks sufficient detail for independent evaluation. In the revised manuscript we will add tables reporting all numerical metrics (success rates, coverage, and efficiency) for the main comparisons, explicit implementation details for the RL-based active mapping baselines (including hyperparameters and training protocols), and additional ablation tables isolating the contributions of persistent reconstruction and episodic sequence modeling. These changes will directly support the claims of outperformance and zero-shot transfer to Gibson and synthetic environments. revision: yes
-
Referee: [Reconstruction and reward section] Reconstruction and reward section: The method relies on the online 3D reconstruction remaining sufficiently accurate and complete to generate a reliable curiosity signal across hundreds to thousands of steps in cluttered HM3D scenes. No quantitative reconstruction-quality metrics (coverage, drift, or map-vs-ground-truth overlap) are reported, leaving the load-bearing premise that the persistent map correctly labels novel versus visited regions unverified.
Authors: We acknowledge that direct quantitative validation of reconstruction quality is important for confirming the reliability of the curiosity signal. We will add metrics on reconstruction coverage, drift over long trajectories, and overlap with ground-truth maps (where simulator access permits) to the revised manuscript. While the end-to-end exploration performance on HM3D provides indirect support for the map's utility, these explicit measurements will better substantiate the premise that the persistent 3D model correctly distinguishes novel from visited regions. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents an empirical approach to curiosity-driven exploration using an online 3D reconstruction as a persistent world model and a sequence model over RGB frames for episodic context. Performance claims (outperformance on HM3D, zero-shot transfer to Gibson) are validated through training and evaluation on external benchmarks rather than any closed mathematical derivation. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the central results to inputs by construction. The method relies on established reconstruction and RL components with results measured against independent baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Online 3D reconstruction from RGB can serve as a sufficiently accurate and continuously updated persistent model of the environment.
- domain assumption A sequence model over RGB observations is adequate to maintain episodic trajectory history for navigation decisions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
curiosity reward... discrepancy between novel view renders and ground truth observation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948. 2
work page 1948
-
[2]
Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J. Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In ICRA, 2017. 2
work page 2017
-
[3]
DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames. InICLR, 2020. 2
work page 2020
-
[4]
A possibility for implementing curiosity and boredom in model-building neural controllers
Jürgen Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. InFrom Animals to Animats: Proceedings of the First International Confer- ence on Simulation of Adaptive Behavior. MIT Press/Bradford Books, 1991. 2, 14
work page 1991
-
[5]
Curiosity-driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InICML, 2017. 2, 7, 9, 14
work page 2017
-
[6]
Advancing Open-source World Models
Robbyant Team. Advancing open-source world models.arXiv preprint arXiv:2601.20540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Learning to explore using active neural slam
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhut- dinov. Learning to explore using active neural slam. InICLR, 2020. 2, 6, 9, 14
work page 2020
-
[8]
Ramakrishnan, Ziad Al-Halah, and Kristen Grauman
Santhosh K. Ramakrishnan, Ziad Al-Halah, and Kristen Grauman. Occupancy anticipation for efficient exploration and navigation. InECCV, 2020. 6, 14
work page 2020
-
[9]
Gleam: Learning generalizable exploration policy for active mapping in complex 3d indoor scenes
Xiao Chen, Tai Wang, Quanyi Li, Tao Huang, Jiangmiao Pang, and Tianfan Xue. Gleam: Learning generalizable exploration policy for active mapping in complex 3d indoor scenes. In ICCV, 2025. 2, 6, 9, 14
work page 2025
-
[10]
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. First return, then explore. InNature, 2021. 2, 9
work page 2021
-
[11]
Learning exploration policies for navigation
Tao Chen, Saurabh Gupta, and Abhinav Gupta. Learning exploration policies for navigation. In ICLR, 2019. 2, 9, 14
work page 2019
-
[12]
Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexan- der Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. InNeurIPS, 2021. 2, 6, 7, 8
work page 2021
-
[13]
Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: real-world perception for embodied agents. InCVPR, 2018. 2, 6
work page 2018
-
[14]
World Labs. Generating worlds. https://www.worldlabs.ai/blog/generating-worlds andhttps://www.worldlabs.ai/blog/spark-2.0, 2024. Accessed: 2025. 2, 8
work page 2024
-
[15]
3d gaussian splatting as markov chain monte carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Weiwei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splatting as markov chain monte carlo. InNeurIPS, 2024. 4, 6, 15 10
work page 2024
-
[16]
Vincent Sitzmann, Semon Rezchikov, William T. Freeman, Joshua B. Tenenbaum, and Fredo Durand. Light field networks: Neural scene representations with single-evaluation rendering. InNeurIPS, 2021. 4
work page 2021
-
[17]
Dinov2: Learning robust visual features without supervision
Maxime Oquab and Timothée Darcet et al. Dinov2: Learning robust visual features without supervision. InTMLR, 2023. 4
work page 2023
-
[18]
Learning to (learn at test time): Rnns with expressive hidden states
Yu Sun and Xinhao Li et al. Learning to (learn at test time): Rnns with expressive hidden states. InICML, 2025. 5
work page 2025
-
[19]
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Junyi Zhang, Charles Herrmann, Junhwa Hur, Chen Sun, Ming-Hsuan Yang, Forrester Cole, Trevor Darrell, and Deqing Sun. Loger: Long-context geometric reconstruction with hybrid memory.arXiv preprint arXiv:2603.03269, 2026. 5, 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 5, 15
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Sapg: Split and aggregate policy gradients
Jayesh Singla, Ananye Agarwal, and Deepak Pathak. Sapg: Split and aggregate policy gradients. InICML, 2024. 5
work page 2024
-
[22]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR,
-
[23]
Habitat 3.0: A co-habitat for humans, avatars and robots,
Xavi Puig and Eric Undersander et al. Habitat 3.0: A co-habitat for humans, avatars and robots,
-
[24]
What does really matter in image goal navigation? In3DV, 2026
Gianluca Monaci, Philippe Weinzaepfel, and Christian Wolf. What does really matter in image goal navigation? In3DV, 2026. 6
work page 2026
-
[25]
Zike Yan, Haoxiang Yang, and Hongbin Zha. Active neural mapping. InICCV, 2023. 7, 9, 14
work page 2023
-
[26]
Learning to Navigate in Complex Environments
Piotr Mirowski, Razvan Pascanu, Fabio Viola, Hubert Soyer, Andrew J Ballard, Andrea Banino, Misha Denil, Ross Goroshin, Laurent Sifre, Koray Kavukcuoglu, et al. Learning to navigate in complex environments.arXiv preprint arXiv:1611.03673, 2016. 8
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
Exploration by random network distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation. InICLR, 2019. 9, 14
work page 2019
-
[28]
Self-supervised exploration via disagree- ment
Deepak Pathak, Dhiraj Gandhi, and Abhinav Gupta. Self-supervised exploration via disagree- ment. InICML, 2019. 9, 14
work page 2019
-
[29]
Episodic curiosity through reachability
Nikolay Savinov, Anton Raichuk, Raphaël Marinier, Damien Vincent, Marc Pollefeys, Timothy Lillicrap, and Sylvain Gelly. Episodic curiosity through reachability. InICLR, 2019. 9, 14
work page 2019
-
[30]
Never give up: Learning directed exploration strategies
Adrià Puigdomènech Badia and Pablo Sprechmann et al. Never give up: Learning directed exploration strategies. InICLR, 2020. 14
work page 2020
-
[31]
Exploration via elliptical episodic bonuses
Mikael Henaff, Roberta Raileanu, Minqi Jiang, and Tim Rocktäschel. Exploration via elliptical episodic bonuses. InNeurIPS, 2022. 14
work page 2022
-
[32]
Go beyond imagination: maximizing episodic reachability with world models
Yao Fu, Run Peng, and Honglak Lee. Go beyond imagination: maximizing episodic reachability with world models. InICML, 2023. 9, 14
work page 2023
-
[33]
Improving intrinsic exploration by creating stationary objectives
Roger Creus Castanyer, Joshua Romoff, and Glen Berseth. Improving intrinsic exploration by creating stationary objectives. InICLR, 2024. 9, 14
work page 2024
-
[34]
Wen Jiang, Boshu Lei, and Kostas Daniilidis. Fisherrf: Active view selection and uncertainty quantification for radiance fields using fisher information. InECCV, 2024. 9, 14
work page 2024
-
[35]
MAGICIAN: Efficient Long- Term Planning with Imagined Gaussians for Active Mapping
Shiyao Li, Antoine Guédon, Shizhe Chen, and Vincent Lepetit. MAGICIAN: Efficient Long- Term Planning with Imagined Gaussians for Active Mapping. InCVPR, 2026. 14
work page 2026
-
[36]
Multimodal llm guided explo- ration and active mapping using fisher information
Wen Jiang, Boshu Lei, Katrina Ashton, and Kostas Daniilidis. Multimodal llm guided explo- ration and active mapping using fisher information. InICCV, 2025. 9, 14 11
work page 2025
-
[37]
Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature Space
Yuhang He, Irving Fang, Yiming Li, Rushi Bhavesh Shah, and Chen Feng. Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature Space. InRSS,
-
[38]
Philip J. Ball and Jakob Bauer et al. Genie 3: A new frontier for world models, 2025. URL https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ . 9, 15
work page 2025
-
[39]
World Action Models are Zero-shot Policies
Seonghyeon Ye and Yunhao Ge et al. Dreamzero: World action models are zero-shot policies. arXiv preprint arXiv:2602.15922, 2026. 9, 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Ziqi Ma, Mengzhan Liufu, and Georgia Gkioxari. Out of sight, out of mind? evaluating state evolution in video world models.arXiv preprint arXiv:2603.13215, 2026. 9, 15
-
[41]
3d gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. InSIGGRAPH, 2023. 9, 15
work page 2023
-
[42]
Splatam: Splat, track & map 3d gaussians for dense rgb-d slam
Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon Luiten. Splatam: Splat, track & map 3d gaussians for dense rgb-d slam. InCVPR, 2024. 9, 15
work page 2024
-
[43]
State entropy maximization with random encoders for efficient exploration
Younggyo Seo, Lili Chen, Jinwoo Shin, Honglak Lee, Pieter Abbeel, and Kimin Lee. State entropy maximization with random encoders for efficient exploration. InICML, 2021. 14
work page 2021
-
[44]
Maxin- forl: Boosting exploration in reinforcement learning through information gain maximization
Bhavya Sukhija, Stelian Coros, Andreas Krause, Pieter Abbeel, and Carmelo Sferrazza. Maxin- forl: Boosting exploration in reinforcement learning through information gain maximization. In ICLR, 2025
work page 2025
-
[45]
Tenenbaum, Tim Rocktäschel, and Edward Grefenstette
Andres Campero, Roberta Raileanu, Heinrich Küttler, Joshua B. Tenenbaum, Tim Rocktäschel, and Edward Grefenstette. Learning with amigo: Adversarially motivated intrinsic goals. In ICLR, 2021. 14
work page 2021
-
[46]
Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A. Efros. Large-scale study of curiosity-driven learning. InICLR, 2019. 14
work page 2019
-
[47]
Ride: Rewarding impact-driven exploration for procedurally-generated environments
Roberta Raileanu and Tim Rocktäschel. Ride: Rewarding impact-driven exploration for procedurally-generated environments. InICLR, 2020. 14
work page 2020
-
[48]
Focus on impact: Indoor exploration with intrinsic motivation
Roberto Bigazzi, Federico Landi, Silvia Cascianelli, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. Focus on impact: Indoor exploration with intrinsic motivation. InRA-L, 2022. 14
work page 2022
-
[49]
Bayes’ Rays: Uncertainty quantification in neural radiance fields
Lily Goli, Cody Reading, Silvia Sellán, Alec Jacobson, and Andrea Tagliasacchi. Bayes’ Rays: Uncertainty quantification in neural radiance fields. InCVPR, 2024. 14
work page 2024
-
[50]
Uncertainty-driven planner for exploration and navigation
Georgios Georgakis, Bernadette Bucher, Anton Arapin, Karl Schmeckpeper, Nikolai Matni, and Kostas Daniilidis. Uncertainty-driven planner for exploration and navigation. InICRA, 2022
work page 2022
-
[51]
Macarons: Mapping and coverage anticipation with rgb online self-supervision
Antoine Guédon, Tom Monnier, Pascal Monasse, and Vincent Lepetit. Macarons: Mapping and coverage anticipation with rgb online self-supervision. InCVPR, 2023
work page 2023
-
[52]
Nextbest- path: Efficient 3d mapping of unseen environments
Shiyao Li, Antoine Guedon, Clémentin Boittiaux, Shizhe Chen, and Vincent Lepetit. Nextbest- path: Efficient 3d mapping of unseen environments. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,ICLR, 2025
work page 2025
-
[53]
Activesplat: High-fidelity scene reconstruction through active gaussian splatting
Yuetao Li, Zijia Kuang, Ting Li, Qun Hao, Zike Yan, Guyue Zhou, and Shaohui Zhang. Activesplat: High-fidelity scene reconstruction through active gaussian splatting. InRA-L, 2025
work page 2025
-
[54]
Activegamer: Active gaussian mapping through efficient rendering
Liyan Chen, Huangying Zhan, Kevin Chen, Xiangyu Xu, Qingan Yan, Changjiang Cai, and Yi Xu. Activegamer: Active gaussian mapping through efficient rendering. InCVPR, 2025
work page 2025
-
[55]
Rt-guide: Real-time gaussian splatting for information-driven exploration
Yuezhan Tao, Dexter Ong, Varun Murali, Igor Spasojevic, Pratik Chaudhari, and Vijay Kumar. Rt-guide: Real-time gaussian splatting for information-driven exploration. InRA-L, 2025. 12
work page 2025
-
[56]
Mapex: Indoor structure exploration with probabilistic information gain from global map predictions
Cherie Ho, Seungchan Kim, Brady Moon, Aditya Parandekar, Narek Harutyunyan, Chen Wang, Katia Sycara, Graeme Best, and Sebastian Scherer. Mapex: Indoor structure exploration with probabilistic information gain from global map predictions. InICRA, 2025
work page 2025
-
[57]
Pipe planner: Pathwise information gain with map predictions for indoor robot exploration
Seungjae Baek, Brady Moon, Seungchan Kim, Muqing Cao, Cherie Ho, Sebastian Scherer, and Jeong Hwan Jeon. Pipe planner: Pathwise information gain with map predictions for indoor robot exploration. InIROS, 2025. 14
work page 2025
-
[58]
Sen Wang, Bangwei Liu, Zhenkun Gao, Lizhuang Ma, Xuhong Wang, Yuan Xie, and Xin Tan. Explore with long-term memory: A benchmark and multimodal llm-based reinforcement learning framework for embodied exploration. InCVPR, 2026. 14
work page 2026
-
[59]
Where to look next: Learning viewpoint recommendations for informative trajectory planning
Max Lodel, Bruno Brito, Alvaro Serra-Gómez, Laura Ferranti, Robert Babuška, and Javier Alonso-Mora. Where to look next: Learning viewpoint recommendations for informative trajectory planning. InICRA, 2022. 14
work page 2022
-
[60]
Gennbv: Generalizable next-best-view policy for active 3d reconstruction
Xiao Chen, Quanyi Li, Tai Wang, Tianfan Xue, and Jiangmiao Pang. Gennbv: Generalizable next-best-view policy for active 3d reconstruction. InCVPR, 2024. 14
work page 2024
-
[61]
On-the-fly reconstruction for large-scale novel view synthesis from unposed images
Andreas Meuleman, Ishaan Shah, Alexandre Lanvin, Bernhard Kerbl, and George Drettakis. On-the-fly reconstruction for large-scale novel view synthesis from unposed images. InTOG,
-
[62]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024. 15
work page 2024
-
[63]
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InCVPR, 2025. 15
work page 2025
-
[64]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025. 15
work page 2025
-
[65]
Lyra 2.0: Explorable Generative 3D Worlds
Tianchang Shen and Sherwin Bahmani et al. Lyra 2.0: Explorable generative 3d worlds.arXiv preprint arXiv:2604.13036, 2026. 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Learning 3d persistent embodied world models
Siyuan Zhou, Yilun Du, Yuncong Yang, Lei Han, Peihao Chen, Dit-Yan Yeung, and Chuang Gan. Learning 3d persistent embodied world models. InNeurIPS, 2025
work page 2025
-
[67]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025. 15
-
[68]
High- dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InICLR, 2016. 15 13 A Video Results Please refer to our website,recuriosity.github.io, for video results of our agent exploring diverse 3D environments and performing downstream tasks. B Related Work...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.