Text2DSL: LLM-Based Code Generation for Domain-Specific Languages
Pith reviewed 2026-06-26 10:36 UTC · model grok-4.3
The pith
Providing formal DSL specifications in prompts enables LLMs to generate valid code from natural language at 98.6-99.4 percent syntactic accuracy
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
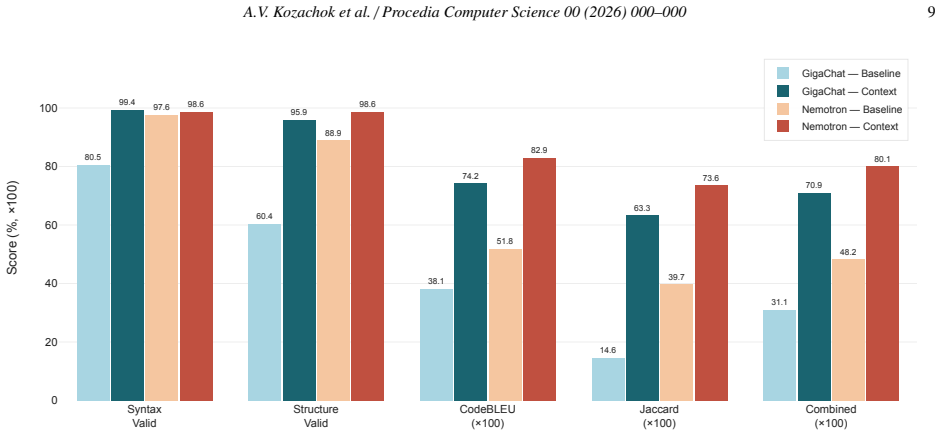
For the Text2DSL problem class, injecting a formal target-language specification into the prompt context is a robust enabling factor for high-quality generation without model fine-tuning. This is shown by the consistent and substantial lifts in syntactic validity to 98.6-99.4 percent, structural validity, and CodeBLEU scores when the context is supplied to two models of different active-parameter counts and provenance.
What carries the argument
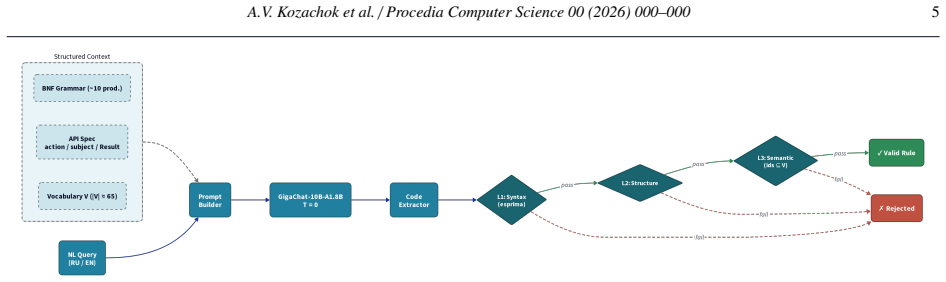
Structured prompt context consisting of the target DSL's BNF grammar, API specification, and permitted identifier vocabulary, which guides the model toward syntactically and structurally valid output.
If this is right
- High syntactic validity in DSL code generation becomes achievable through prompt context alone rather than model retraining.
- Structural validity and code similarity metrics improve by double-digit percentages when formal language specifications are supplied.
- The same context-injection method yields comparable gains on models that differ in scale and training origin.
- Text2DSL tasks can be addressed at high quality without task-specific fine-tuning of the base language model.
Where Pith is reading between the lines
- The same context-injection technique may transfer to DSLs used in other policy or configuration domains beyond operating-system security.
- Tooling that automatically assembles the required grammar and vocabulary context could lower the barrier for non-experts to produce correct rules.
- Developers might test whether the gains persist when the natural-language input is noisier or less aligned with the training distribution of the benchmark.
Load-bearing premise
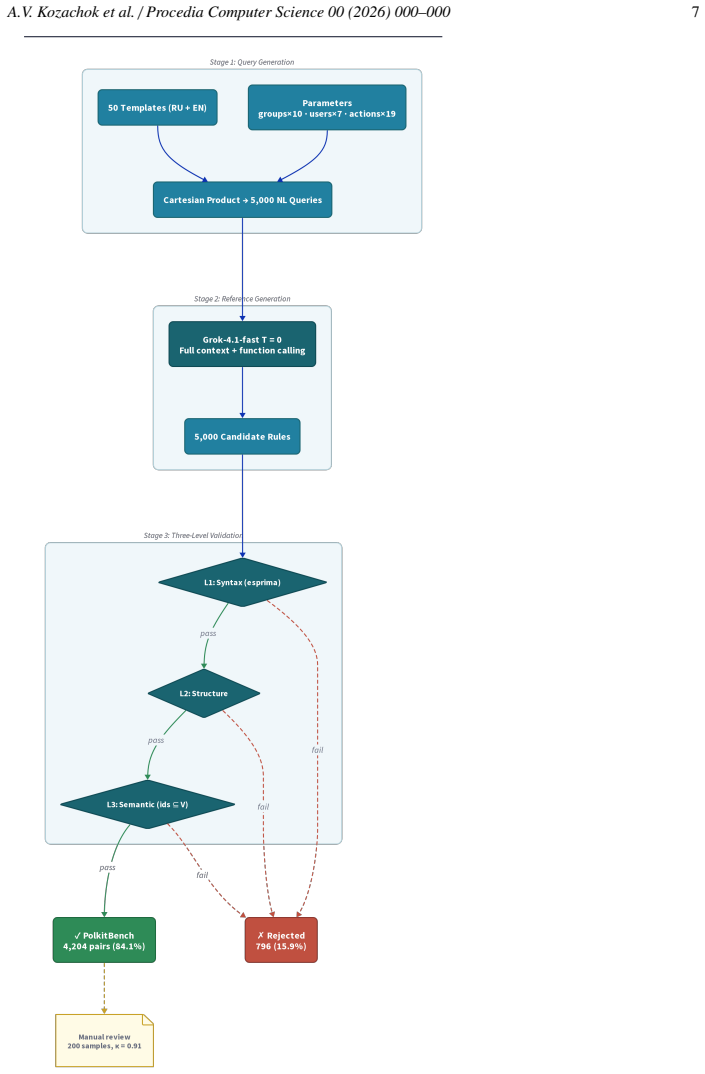
The PolkitBench dataset of 4,204 pairs, each validated through a three-level AST-based pipeline, is representative of real-world natural language descriptions for Polkit rules.
What would settle it
Repeating the prompt experiments on a different domain-specific language or on a set of uncurated real-user queries and finding that the addition of formal context produces no meaningful gains in syntactic validity or CodeBLEU score.
Figures

read the original abstract
Domain-specific languages (DSLs) are widely used for managing operating system security policies, yet manually authoring rules in such languages demands high expertise and is error-prone. This paper formalises the task of automatic DSL code generation from natural language descriptions - Text2DSL - as a distinct problem class, separate from Text-to-SQL and general-purpose code generation. We introduce the PolkitBench dataset comprising 4,204 verified natural-language-to-Polkit-rule pairs, each validated through a three-level AST-based pipeline. Controlled prompt experiments on two MoE models of different scale and provenance - GigaChat-10B-A1.8B (1.8B active parameters) and Nemotron-3-Nano-30B-A3B (3B active) - demonstrate the critical role of structured context (BNF grammar, API specification, permitted identifier vocabulary) for LLM-based DSL code generation. Across both models, supplying context raises syntactic validity to 98.6-99.4%, structural validity by +9.7 to +35.5 pp, and the CodeBLEU score by +60% to +95%. The consistency of the effect across models of different scale and provenance indicates that, for the Text2DSL class of problems, injecting a formal target-language specification into the prompt context is a robust enabling factor for high-quality generation without model fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to formalize Text2DSL as a distinct problem class separate from Text-to-SQL, introduces the PolkitBench dataset of 4,204 verified NL-to-Polkit-rule pairs validated by a three-level AST pipeline, and reports controlled prompt experiments on two MoE models (GigaChat-10B-A1.8B and Nemotron-3-Nano-30B-A3B) showing that adding formal context (BNF grammar, API specification, permitted identifier vocabulary) raises syntactic validity to 98.6-99.4%, structural validity by +9.7 to +35.5 pp, and CodeBLEU by +60% to +95%, concluding that context injection is a robust enabler for high-quality Text2DSL generation without fine-tuning.
Significance. If the results hold, the work supplies concrete empirical evidence that structured formal specifications in prompts can produce large, consistent gains in generation quality for a security-policy DSL without model fine-tuning, with the cross-model consistency (different scales and provenance) as a notable strength. The introduction of a new benchmark dataset with automated validation is also a positive contribution for the code-generation subfield.
major comments (2)
- [Abstract] Abstract: the claim that the results indicate context injection is a 'robust enabling factor for the Text2DSL class of problems' is not supported by the reported evidence, which derives exclusively from the single Polkit DSL and PolkitBench dataset; no second DSL with different syntactic characteristics (e.g., deeper nesting or richer type system) is evaluated to establish class-level applicability.
- [Dataset section] Dataset section: the three-level AST-based validation pipeline for the 4,204 pairs is described at high level only, with no details on natural-language sourcing, selection criteria, or potential biases, which is load-bearing for assessing whether the dataset supports the reported validity and similarity metrics.
minor comments (2)
- [Methods] Add explicit definitions and an example for the distinction between syntactic validity and structural validity in the methods section.
- [Results tables] Tables reporting the validity and CodeBLEU results should include per-condition sample sizes and any variance measures to aid interpretation of the percentage-point gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing where revisions are warranted to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the results indicate context injection is a 'robust enabling factor for the Text2DSL class of problems' is not supported by the reported evidence, which derives exclusively from the single Polkit DSL and PolkitBench dataset; no second DSL with different syntactic characteristics (e.g., deeper nesting or richer type system) is evaluated to establish class-level applicability.
Authors: We agree that the empirical results are derived from a single DSL (Polkit) and therefore do not constitute direct evidence for the entire Text2DSL class. The cross-model consistency strengthens the finding for Polkit but cannot alone establish class-wide applicability. We will revise the abstract (and related claims in the introduction and conclusion) to state that the results demonstrate context injection as a robust enabling factor for high-quality generation on the Polkit DSL without fine-tuning, while noting that evaluation on additional DSLs with differing syntactic properties would be required to support broader class-level conclusions. revision: yes
-
Referee: [Dataset section] Dataset section: the three-level AST-based validation pipeline for the 4,204 pairs is described at high level only, with no details on natural-language sourcing, selection criteria, or potential biases, which is load-bearing for assessing whether the dataset supports the reported validity and similarity metrics.
Authors: We acknowledge that the current description of the dataset construction and validation pipeline is high-level. In the revised manuscript we will expand the Dataset section to provide concrete details on natural-language sourcing (including sources such as policy documentation and expert-generated examples), explicit selection criteria used to arrive at the final 4,204 pairs, and an explicit discussion of potential biases (e.g., coverage of common versus rare policy patterns and any filtering steps that could affect metric validity). revision: yes
Circularity Check
No circularity; empirical measurements only
full rationale
The paper introduces PolkitBench and reports direct experimental measurements of syntactic validity, structural validity, and CodeBLEU under controlled prompt conditions on two LLMs. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The Text2DSL formalization is definitional framing for the empirical task, not a self-referential reduction. Single-DSL scope is a generalizability concern, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-level AST-based pipeline correctly validates the natural-language-to-Polkit-rule pairs for use in measuring generation quality.
Reference graph
Works this paper leans on
-
[1]
M. Chen, J. Tworek, H. Jun et al., Evaluating Large Language Models Trained on Code, preprint, arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[2]
Z. Feng, D. Guo, D. Tang et al., CodeBERT: A Pre-Trained Model for Programming and Natural Languages, in: Findings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 1536–1547
2020
-
[3]
R. Li, L.B. Allal, Y . Zi et al., StarCoder: May the Source Be with You!, Transactions on Machine Learning Research, 2023
2023
-
[4]
T. Yu, R. Zhang, K. Yang et al., Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text- to-SQL Task, in: Proceedings of EMNLP 2018, 2018, pp. 3911–3921
2018
-
[5]
Pourreza, D
M. Pourreza, D. Rafiei, DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction, in: Advances in Neural Information Processing Systems 36, 2023
2023
-
[6]
Papineni, S
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, BLEU: A Method for Automatic Evaluation of Machine Translation, in: Proceedings of the 40th Annual Meeting of the ACL, 2002, pp. 311–318
2002
-
[7]
Scholak, N
T. Scholak, N. Schucher, D. Bahdanau, PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models, in: Proceedings of EMNLP 2021, 2021, pp. 9895–9901
2021
-
[8]
Poesia, O
G. Poesia, O. Polozov, V . Le et al., Synchromesh: Reliable Code Generation from Pre-trained Language Models, in: Proceedings of ICLR 2022, 2022
2022
-
[9]
URL:https://www.freedesktop.org/software/polkit/docs/latest/
freedesktop.org, polkit Reference Manual, 2024. URL:https://www.freedesktop.org/software/polkit/docs/latest/
2024
-
[10]
Smalley, C
S. Smalley, C. Vance, W. Salamon, Implementing SELinux as a Linux Security Module, NAI Labs Report #01-043, 2001
2001
-
[11]
URL:https://www.openpolicyagent.org/docs/latest/
Open Policy Agent, OPA Documentation, 2024. URL:https://www.openpolicyagent.org/docs/latest/
2024
-
[12]
URL:https://developer.hashicorp.com/terraform/language
HashiCorp, Terraform Language Documentation, 2024. URL:https://developer.hashicorp.com/terraform/language
2024
-
[13]
Rahman, C
A. Rahman, C. Parnin, L. Williams, The Seven Sins: Security Smells in Infrastructure as Code Scripts, in: Proceedings of ICSE 2019, 2019, pp. 164–175
2019
-
[14]
J. Austin, A. Odena, M. Nye et al., Program Synthesis with Large Language Models, preprint, arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[15]
V . Zhong, C. Xiong, R. Socher, Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning, preprint, arXiv:1709.00103, 2017
Pith/arXiv arXiv 2017
-
[16]
B. Rozi `ere, J. Gehring, F. Gloeckle et al., Code Llama: Open Foundation Models for Code, preprint, arXiv:2308.12950, 2023
Pith/arXiv arXiv 2023
-
[17]
D. Guo, Q. Zhu, D. Yang et al., DeepSeek-Coder: When the Large Language Model Meets Programming, preprint, arXiv:2401.14196, 2024
Pith/arXiv arXiv 2024
-
[18]
D. Guo, S. Ren, S. Lu et al., GraphCodeBERT: Pre-training Code Representations with Data Flow, in: Proceedings of ICLR 2021, 2021
2021
-
[19]
H. Li, J. Zhang, C. Li et al., RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL, in: Proceedings of AAAI 2023, 2023, pp. 13067–13075
2023
-
[20]
N. Jain, S. Vaidyanath, A. Iyer et al., Jigsaw: Large Language Models Meet Program Synthesis, in: Proceedings of ICSE 2022, 2022, pp. 1219– 1231
2022
-
[21]
Narayan, I
A. Narayan, I. Patil, S. Pen et al., Can LLMs Generate Correct Bash Scripts?, in: Proceedings of the 1st Workshop on NL-to-Code, 2022
2022
- [22]
-
[23]
S. Geng, J. Josifoski, D. Perez et al., Grammar-Constrained Decoding for Structured NLP Tasks, preprint, arXiv:2305.13971, 2024
arXiv 2024
-
[24]
S. Ren, D. Guo, S. Lu et al., CodeBLEU: A Method for Automatic Evaluation of Code Synthesis, preprint, arXiv:2009.10297, 2020
Pith/arXiv arXiv 2009
-
[25]
URL:https://huggingface.co/ai-sage/GigaChat3-10B-A1.8B
SberDevices, GigaChat3-10B-A1.8B, 2025. URL:https://huggingface.co/ai-sage/GigaChat3-10B-A1.8B
2025
-
[26]
URL:https://huggingface.co/nvidia/Nemotron-3-Nano-30B-A3B
NVIDIA, Nemotron-3-Nano-30B-A3B, 2025. URL:https://huggingface.co/nvidia/Nemotron-3-Nano-30B-A3B
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.