Quality Adaptive Angular Margin Learning for Respiratory Sound Classification
Pith reviewed 2026-06-27 08:16 UTC · model grok-4.3
The pith
Quality-adaptive angular margins improve feature generalization for respiratory sound classification on both in-distribution and out-of-distribution data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
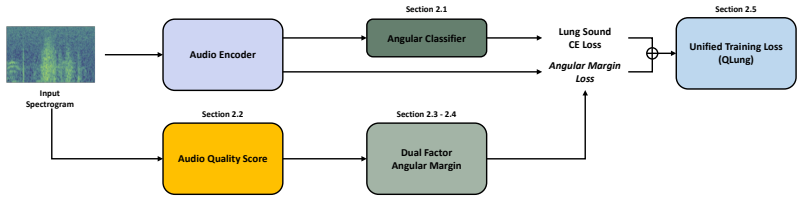
QLung introduces a no-reference audio quality margin derived from spectral entropy and root-mean-square energy that adaptively scales angular margins, combined with a log-scaled margin for training stability and an angular classifier that normalizes features and class weights, thereby improving intra-class compactness and inter-class separability for respiratory sound classification.
What carries the argument
The no-reference audio quality margin from spectral entropy and root-mean-square energy, which adaptively scales angular margins based on recording quality.
If this is right
- In-distribution accuracy on ICBHI rises 2.46 percent above the cross-entropy baseline.
- Out-of-distribution accuracy on SPRSound exceeds all prior state-of-the-art methods.
- Log-scaled margins stabilize training when classes are severely imbalanced.
- Angular normalization keeps margin penalties uniform across the unit hypersphere.
- Feature representations become more compact within each respiratory-sound class and more separable between classes.
Where Pith is reading between the lines
- The same quality-derived scaling could be tested on other imbalanced audio tasks such as environmental sound or medical speech classification.
- If the quality metric correlates with clinical recording conditions, the method may reduce the performance gap between controlled and real-world deployment.
- Replacing the entropy-energy margin with alternative no-reference measures would provide a direct test of whether the particular choice of quality signal is essential.
Load-bearing premise
The no-reference margin computed from spectral entropy and root-mean-square energy accurately measures recording quality and can safely scale angular margins without adding bias or training instability.
What would settle it
Retraining the same backbone with a fixed (non-quality-adaptive) angular margin and observing that out-of-distribution accuracy on SPRSound drops below the reported state-of-the-art level would falsify the value of the adaptive scaling.
Figures



read the original abstract
We present a quality-adaptive angular-margin learning framework that improves feature generalization by enforcing intra-class compactness and inter-class separability. Our framework, titled QLung, introduces a no-reference audio quality margin derived from spectral entropy and root-mean-square energy, which adaptively scales angular margins based on recording quality. To this end, we propose a log-scaled angular margin that stabilizes training under severe class imbalance. We also use an angular classifier that normalizes features and class weights, ensuring margin penalties are applied consistently on the unit hypersphere. Our approach improves in-distribution performance on the ICBHI dataset by 2.46\% over the cross-entropy baseline, and most significantly, achieves the strongest out-of-distribution performance on the SPRSound dataset compared to prior state-of-the-art methods. Code is available at https://github.com/RSC-Toolkit/QLung.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents QLung, a quality-adaptive angular margin learning framework for respiratory sound classification. It introduces a no-reference audio quality margin based on spectral entropy and root-mean-square energy to adaptively scale angular margins, a log-scaled angular margin to handle class imbalance, and an angular classifier that normalizes features and weights. The approach is claimed to improve in-distribution performance on the ICBHI dataset by 2.46% over cross-entropy baseline and achieve the strongest out-of-distribution performance on the SPRSound dataset compared to prior methods. Code is made available.
Significance. If the results hold, this work could be significant for improving generalization in medical audio classification tasks where data quality varies. The provision of code at the GitHub link is a strength that enhances reproducibility and allows for verification of the claims.
major comments (2)
- [Abstract] Abstract: The abstract reports a 2.46% performance improvement and superior OOD results but supplies no experimental details, ablation studies, statistical significance tests, or error bars. This makes it impossible to assess the validity of the central claims regarding the quality-adaptive margin's contribution.
- [Abstract] Abstract: There is no information on whether the margin scaling parameters (derived from spectral entropy and RMS energy) are independently derived or fitted to the same data used for evaluation, which could introduce circularity and bias in the reported gains.
minor comments (1)
- [Abstract] Abstract: The title and abstract use 'QLung' but do not expand the acronym or provide a clear definition of the framework components.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports a 2.46% performance improvement and superior OOD results but supplies no experimental details, ablation studies, statistical significance tests, or error bars. This makes it impossible to assess the validity of the central claims regarding the quality-adaptive margin's contribution.
Authors: We agree the abstract is concise by design and omits experimental details. The full manuscript details the ICBHI and SPRSound protocols, ablation studies on margin components, and results with standard deviations across runs in Sections 4 and 5. To address the concern, we will revise the abstract to briefly note the evaluation protocol and cross-validation setup while keeping it within length limits. revision: yes
-
Referee: [Abstract] Abstract: There is no information on whether the margin scaling parameters (derived from spectral entropy and RMS energy) are independently derived or fitted to the same data used for evaluation, which could introduce circularity and bias in the reported gains.
Authors: The scaling parameters are computed per-sample in a strictly no-reference manner from the raw audio waveform (spectral entropy and RMS energy) with no fitting, optimization, or use of labels or evaluation data. This is stated in the method description as a fixed signal-quality heuristic. We will add explicit wording in the revised abstract and Section 3 to confirm independence from training/evaluation splits and eliminate any ambiguity. revision: yes
Circularity Check
No circularity detected from provided text
full rationale
The abstract and reader's summary describe a quality-adaptive margin derived from spectral entropy and RMS energy, plus a log-scaled angular margin and angular classifier, but supply no equations, derivation chain, or self-citations. No load-bearing step reduces by construction to its inputs, and performance claims are presented as empirical outcomes rather than forced by definition or fit. The derivation is therefore self-contained against the given material.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spectral entropy and root-mean-square energy provide a reliable no-reference proxy for audio recording quality suitable for margin adaptation.
Reference graph
Works this paper leans on
-
[1]
Introduction Respiratory sound classification (RSC) has attracted growing interest due to its potential to support the diagnosis of respira- tory diseases. Recent progress has been driven by advances in model architectures ranging from CNNs to Transformers, which have enabled the learning of increasingly discriminative repre- sentations from respiratory r...
Pith/arXiv arXiv 2026
-
[2]
Angular Classifier Angular margin losses are designed to encourage features to cluster on the unit hypersphere in the directions of their class weight vectors [17, 21]
Methodology 2.1. Angular Classifier Angular margin losses are designed to encourage features to cluster on the unit hypersphere in the directions of their class weight vectors [17, 21]. However, in a standard linear classifier, the target logit also depends on feature and weight norms, which can dilute purely angular clustering under angular margin regu- ...
-
[3]
Experimental Setup ICBHI Dataset.We evaluated our method on the ICBHI 2017 respiratory sound dataset [19], a widely used benchmark for RSC
Experiments 3.1. Experimental Setup ICBHI Dataset.We evaluated our method on the ICBHI 2017 respiratory sound dataset [19], a widely used benchmark for RSC. The dataset comprises approximately 5.5 hours of record- ings, segmented into 6,898 respiratory cycles. Following the official protocol, the data are split into training (60%) and test (40%) subsets a...
2017
-
[4]
Conclusion In this paper, we introduced QLung to address the challenges of low-quality recordings and class imbalance in RSC by propos- ing DFAM with an angular classifier to adapt angular mar- gins. Extensive experiments validated that QLung improved AST fine-tuning by an absolute 2.46% on the ICBHI dataset and achieved best OOD performance on the SPRSou...
-
[5]
RS-2025-16066662)
Acknowledgement This research was supported by the Regional Innovation System & Education(RISE) program through the Jeonbuk RISE Center, funded by the Ministry of Education(MOE) and the Jeonbuk State, Republic of Korea(2026-RISE-13-WKU), and by the Na- tional Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (grant no. RS-2025-16066662)
2026
-
[6]
The authors have verified all technical content and maintain full account- ability for the work
Generative AI Use Disclosure Generative AI (ChatGPT) was used solely for grammar correc- tion and linguistic polishing of this manuscript. The authors have verified all technical content and maintain full account- ability for the work
-
[7]
Lungrn+ nl: An improved adventitious lung sound classification using non-local block resnet neural network with mixup data augmentation
Y . Ma, X. Xu, and Y . Li, “Lungrn+ nl: An improved adventitious lung sound classification using non-local block resnet neural network with mixup data augmentation.” inInterspeech, 2020, pp. 2902–2906
2020
-
[8]
Adventitious respiratory classification using attentive residual neural networks,
Z. Yang, S. Liu, M. Song, E. Parada-Cabaleiro, and B. W. Schuller, “Adventitious respiratory classification using attentive residual neural networks,” inProc. Interspeech 2020, 2020, pp. 2912–2916
2020
-
[9]
Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification,
S. Bae, J.-W. Kim, W.-Y . Cho, H. Baek, S. Son, B. Lee, C. Ha, K. Tae, S. Kim, and S.-Y . Yun, “Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification,” inProc. Interspeech 2023, 2023, pp. 5436–5440
2023
-
[10]
Bts: Bridging text and sound modalities for metadata-aided respi- ratory sound classification,
J. W. Kim, M. Toikkanen, Y . Choi, S. E. Moon, and H. Y . Jung, “Bts: Bridging text and sound modalities for metadata-aided respi- ratory sound classification,” inProceedings of the Annual Confer- ence of the International Speech Communication Association, INTER- SPEECH, 2024, pp. 1690–1694
2024
-
[11]
Improving Respiratory Sound Classi- fication with Architecture-Agnostic Knowledge Distillation from En- sembles,
M. Toikkanen and J.-W. Kim, “Improving Respiratory Sound Classi- fication with Architecture-Agnostic Knowledge Distillation from En- sembles,” inInterspeech 2025, 2025, pp. 1023–1027
2025
-
[12]
Pretraining respiratory sound represen- tations using metadata and contrastive learning,
I. Moummad and N. Farrugia, “Pretraining respiratory sound represen- tations using metadata and contrastive learning,” in2023 IEEE Work- shop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2023, pp. 1–5
2023
-
[13]
Stethoscope- guided supervised contrastive learning for cross-domain adaptation on respiratory sound classification,
J.-W. Kim, S. Bae, W.-Y . Cho, B. Lee, and H.-Y . Jung, “Stethoscope- guided supervised contrastive learning for cross-domain adaptation on respiratory sound classification,” inICASSP 2024-2024 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 1431–1435
2024
-
[14]
Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,
J.-W. Kim, M. Toikkanen, A. Jalali, M. Kim, H.-J. Han, H. Kim, W. Shin, H.-Y . Jung, and K. Kim, “Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,”IEEE Journal of Biomedical and Health Informatics, vol. 29, no. 8, pp. 5381–5393, 2025
2025
-
[15]
Tri-mtl: A triple multitask learning approach for respiratory disease diagnosis,
J.-W. Kim, S. Lee, M. Toikkanen, D. Hwang, and K. Kim, “Tri-mtl: A triple multitask learning approach for respiratory disease diagnosis,” arXiv preprint arXiv:2505.06271, 2025
arXiv 2025
-
[16]
Empow- ering multimodal respiratory sound classification with counterfactual adversarial debiasing for out-of-distribution robustness,
H. Koo, M. Toikkanen, Y . T. Kim, S. Y . Kim, and J.-W. Kim, “Empow- ering multimodal respiratory sound classification with counterfactual adversarial debiasing for out-of-distribution robustness,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 14 967–14 971
2026
-
[17]
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” inProc. Interspeech 2019, 2019, pp. 2613–2617
2019
-
[18]
Adver- sarial fine-tuning using generated respiratory sound to address class imbalance,
J.-W. Kim, C. Yoon, M. Toikkanen, S. Bae, and H.-Y . Jung, “Adver- sarial fine-tuning using generated respiratory sound to address class imbalance,”arXiv preprint arXiv:2311.06480, 2023
arXiv 2023
-
[19]
Repaug- ment: Input-agnostic representation-level augmentation for respiratory sound classification,
J.-W. Kim, M. Toikkanen, S. Bae, M. Kim, and H.-Y . Jung, “Repaug- ment: Input-agnostic representation-level augmentation for respiratory sound classification,” in2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2024, pp. 1–6
2024
-
[20]
Lungmix: A mixup- based strategy for generalization in respiratory sound classification,
S. Ge, W. Zhang, S. Xie, B. Yan, and Z. Wang, “Lungmix: A mixup- based strategy for generalization in respiratory sound classification,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[21]
H. Koo, Y . T. Kim, M. Toikkanen, and J.-W. Kim, “Mitigating stethoscope-induced shortcuts in respiratory sound classification un- der federated domain generalization with causality-inspired interven- tions,”arXiv preprint arXiv:2605.29862, 2026
Pith/arXiv arXiv 2026
-
[22]
Sphereface: Deep hypersphere embedding for face recognition,
W. Liu, Y . Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 212–220
2017
-
[23]
Arcface: Additive an- gular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive an- gular margin loss for deep face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4690–4699
2019
-
[24]
Large margin softmax loss for speaker ver- ification,
Y . Liu, L. He, and J. Liu, “Large margin softmax loss for speaker ver- ification,” inInterspeech 2019, 2019, pp. 2873–2877
2019
-
[25]
A respiratory sound database for the development of automated classification,
B. Rocha, D. Filos, L. Mendes, I. V ogiatzis, E. Perantoni, E. Kaimakamis, P. Natsiavas, A. Oliveira, C. J ´acome, A. Marques et al., “A respiratory sound database for the development of automated classification,” inInternational conference on biomedical and health informatics. Springer, 2017, pp. 33–37
2017
-
[26]
Sprsound: Open-source sjtu paedi- atric respiratory sound database,
Q. Zhang, J. Zhang, J. Yuan, H. Huang, Y . Zhang, B. Zhang, G. Lv, S. Lin, N. Wang, X. Liuet al., “Sprsound: Open-source sjtu paedi- atric respiratory sound database,”IEEE Transactions on Biomedical Circuits and Systems, vol. 16, no. 5, pp. 867–881, 2022
2022
-
[27]
Curricularface: adaptive curriculum learning loss for deep face recog- nition,
Y . Huang, Y . Wang, Y . Tai, X. Liu, P. Shen, S. Li, J. Li, and F. Huang, “Curricularface: adaptive curriculum learning loss for deep face recog- nition,” inproceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2020, pp. 5901–5910
2020
-
[28]
Ima- genet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Ima- genet: A large-scale hierarchical image database,” in2009 IEEE con- ference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[29]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” inProc. IEEE ICASSP 2017, New Orleans, LA, 2017
2017
-
[30]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dub- nov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[31]
Prototype learning for inter- pretable respiratory sound analysis,
Z. Ren, T. T. Nguyen, and W. Nejdl, “Prototype learning for inter- pretable respiratory sound analysis,” inICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9087–9091
2022
-
[32]
A domain transfer based data augmentation method for automated respiratory classification,
Z. Wang and Z. Wang, “A domain transfer based data augmentation method for automated respiratory classification,” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9017–9021
2022
-
[33]
LungAdapter: Efficient Adapt- ing Audio Spectrogram Transformer for Lung Sound Classification,
L. Xiao, L. Fang, Y . Yang, and W. Tu, “LungAdapter: Efficient Adapt- ing Audio Spectrogram Transformer for Lung Sound Classification,” inInterspeech 2024, 2024, pp. 4738–4742
2024
-
[34]
AST: Audio Spectrogram Trans- former,
Y . Gong, Y .-A. Chung, and J. Glass, “AST: Audio Spectrogram Trans- former,” inProc. Interspeech 2021, 2021, pp. 571–575
2021
-
[35]
Adam: A method for stochastic optimiza- tion,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[36]
Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,
J.-W. Kim, M. Toikkanen, A. Jalali, M. Kim, H.-J. Han, H. Kim, W. Shin, H.-Y . Jung, and K. Kim, “Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.