Generative-Model Predictive Planning for Navigation in Partially Observable Environments
Pith reviewed 2026-06-26 21:11 UTC · model grok-4.3
The pith
BeliefDiffusion combines diffusion models for multimodal beliefs with model predictive control to plan navigation from partial observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
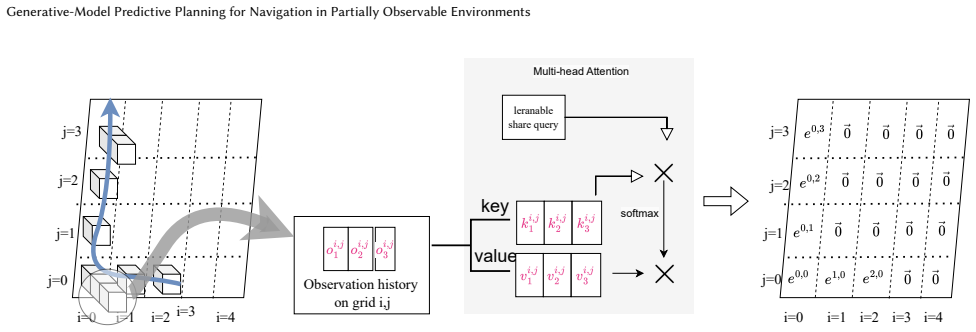
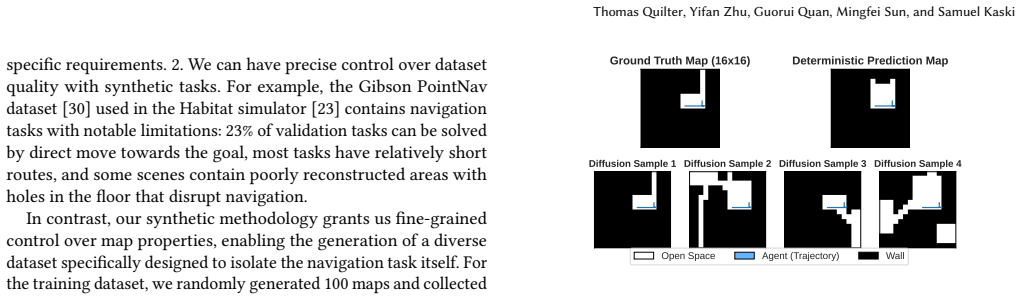
BeliefDiffusion leverages diffusion models to explicitly characterize multimodal belief distributions and utilizes Model Predictive Control (MPC) to simultaneously plan ahead. It consists of two steps: (1) Imagining plausible environment configurations based on observation history and (2) Planning efficient navigation strategies across an aggregated configurations. Through extensive experiments in synthetic map environments, it demonstrates significantly higher navigation success rate and path efficiency than model-free reinforcement learning baselines and other generative approaches.
What carries the argument
The two-step BeliefDiffusion procedure that first uses a diffusion model to sample multiple environment configurations consistent with the observation history and then applies MPC across the aggregated set of configurations.
If this is right
- Navigation success rates rise because actions are chosen to succeed across multiple possible environments rather than a single guessed map.
- Path efficiency improves because the planner avoids routes that would fail under plausible alternative configurations.
- The approach handles perceptual aliasing better than methods that collapse beliefs to a single mode.
- No expert demonstrations are needed because the diffusion model learns the belief distribution directly from observation histories.
Where Pith is reading between the lines
- The same two-step structure could be tested in continuous state spaces such as robot navigation through rooms with movable obstacles.
- If the diffusion sampling step can be made fast enough, the method might extend to online replanning when new observations arrive during execution.
- Similar diffusion-based aggregation could be applied to other planning problems that involve discrete choices under uncertainty, such as task allocation with ambiguous sensor data.
Load-bearing premise
Diffusion models can accurately and efficiently characterize multimodal belief distributions from observation history without requiring substantial data or expert demonstrations.
What would settle it
A controlled test in which the diffusion model is replaced by a unimodal belief estimator and navigation performance drops to the level of the baselines.
Figures


read the original abstract
Navigation in partially observable environments presents a significant challenge for autonomous agents, requiring effective decision-making with limited sensory information in unknown environments. Belief-based methods, particularly those using neural networks to approximate the belief space, often fail to capture the inherent multimodality of belief spaces, especially in high-dimensional cases with perceptual aliasing. While generative models present a compelling alternative, they typically require substantial data or expert demonstrations and lack explicit mechanisms for long-term planning. In this paper, we introduce BeliefDiffusion, a novel framework that combines the benefits of both generation and planning. BeliefDiffusion leverages diffusion models to explicitly characterize multimodal belief distributions and utilizes Model Predictive Control (MPC) to simultaneously plan ahead. It consists of two steps: (1) Imagining plausible environment configurations based on observation history and (2) Planning efficient navigation strategies across an aggregated configurations. Through extensive experiments in synthetic map environments, we demonstrate that BeliefDiffusion significantly outperforms both model-free reinforcement learning baselines and other generative approaches in navigation success rate and path efficiency. Our results validate that explicitly incorporating multimodal belief representations into planning enables more robust navigation in partially observable settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BeliefDiffusion, a framework that uses diffusion models to explicitly characterize multimodal belief distributions from observation histories in partially observable environments and integrates this with Model Predictive Control (MPC) for planning navigation strategies. It consists of imagining plausible environment configurations and planning across aggregated configurations. The paper claims that this approach significantly outperforms model-free reinforcement learning baselines and other generative approaches in navigation success rate and path efficiency based on experiments in synthetic map environments.
Significance. If the experimental results hold and the diffusion component indeed captures multimodal beliefs without substantial data, the explicit incorporation of generative belief modeling into MPC planning could offer a useful direction for robust navigation under perceptual aliasing in POMDPs, addressing limitations of neural belief approximations.
major comments (2)
- [Abstract] Abstract: The abstract reports that BeliefDiffusion 'significantly outperforms' both model-free RL baselines and other generative approaches in synthetic experiments, but provides no details on model architecture, training data, baselines, or statistical significance. This information is load-bearing for the central claim that explicitly incorporating multimodal belief representations enables more robust navigation.
- [Abstract] Abstract: The claim that the framework avoids the data or demonstration requirements of prior generative models is central to the novelty and the attribution of outperformance to the multimodal belief mechanism, yet no mechanism for data-efficient training of the diffusion model on observation histories is described.
Simulated Author's Rebuttal
We thank the referee for the feedback on the abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports that BeliefDiffusion 'significantly outperforms' both model-free RL baselines and other generative approaches in synthetic experiments, but provides no details on model architecture, training data, baselines, or statistical significance. This information is load-bearing for the central claim that explicitly incorporating multimodal belief representations enables more robust navigation.
Authors: We agree the abstract is concise and could better contextualize the performance claims. The full manuscript provides the model architecture in Section 3, training data and procedure in Section 4.1, baselines (model-free RL and generative methods) in Section 4.2, and statistical significance via repeated trials with variance reported in the results. We will revise the abstract to include a brief reference to the synthetic map environments and evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract: The claim that the framework avoids the data or demonstration requirements of prior generative models is central to the novelty and the attribution of outperformance to the multimodal belief mechanism, yet no mechanism for data-efficient training of the diffusion model on observation histories is described.
Authors: The diffusion model is trained on observation histories generated from the agent's own rollouts in the synthetic environments, without expert demonstrations. This is possible because diffusion models can learn multimodal distributions from modest numbers of trajectories collected online. We will revise the abstract to explicitly note this training approach and ensure the methods section highlights the distinction from demonstration-dependent generative baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce BeliefDiffusion as a novel framework that combines diffusion models for explicit multimodal belief characterization with MPC planning, validated through experiments in synthetic environments. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce the central claim to its inputs by construction. The contrast with prior generative models is stated as motivation rather than a load-bearing self-referential premise, and the outperformance is attributed to empirical results rather than any self-definitional or ansatz-smuggled mechanism. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
2021
-
[2]
Hugh Durrant-Whyte and Tim Bailey. 2006. Simultaneous localization and mapping: part I.IEEE robotics & automation magazine13, 2 (2006), 99–110
2006
-
[3]
Himanshu Gupta. 2024. Efficient Continuous Space BeliefMDP Solutions for Navigation and Active Sensing.. InAAMAS. 2749–2751
2024
-
[4]
David Ha and Jürgen Schmidhuber. 2018. World models.arXiv preprint arXiv:1803.10122(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2019. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [6]
-
[7]
Milos Hauskrecht. 2000. Value-function approximations for partially observable Markov decision processes.Journal of artificial intelligence research13 (2000), 33–94
2000
-
[8]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[9]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Marcus Hoerger, Joshua Song, Hanna Kurniawati, and Alberto Elfes. 2019. Pomdp- based candy server: Lessons learned from a seven day demo. InProceedings of the International Conference on Automated Planning and Scheduling, Vol. 29. 698–706
2019
-
[11]
Mineui Hong, Minjae Kang, and Songhwai Oh. 2023. Diffused task-agnostic milestone planner.Advances in Neural Information Processing Systems36 (2023), 387–405
2023
-
[12]
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. 2022. Plan- ning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. 1998. Plan- ning and acting in partially observable stochastic domains.Artificial intelligence 101, 1-2 (1998), 99–134
1998
-
[14]
Peter Karkus, David Hsu, and Wee Sun Lee. 2017. Qmdp-net: Deep learning for planning under partial observability.Advances in neural information processing systems30 (2017)
2017
-
[15]
Mikko Lauri and Risto Ritala. 2016. Planning for robotic exploration based on forward simulation.Robotics and Autonomous Systems83 (2016), 15–31
2016
-
[16]
Ruben Martinez-Cantin, Nando De Freitas, Eric Brochu, José Castellanos, and Arnaud Doucet. 2009. A Bayesian exploration-exploitation approach for optimal online sensing and planning with a visually guided mobile robot.Autonomous Robots27 (2009), 93–103
2009
-
[17]
Manfred Morari and Jay H Lee. 1999. Model predictive control: past, present and future.Computers & chemical engineering23, 4-5 (1999), 667–682
1999
-
[18]
Teddy Ort, Liam Paull, and Daniela Rus. 2018. Autonomous vehicle navigation in rural environments without detailed prior maps. In2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2040–2047
2018
-
[19]
Santhosh Kumar Ramakrishnan, Devendra Singh Chaplot, Ziad Al-Halah, Jiten- dra Malik, and Kristen Grauman. 2022. Poni: Potential functions for objectgoal navigation with interaction-free learning. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. 18890–18900
2022
-
[20]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[21]
Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.061251, 2 (2022), 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Nassir Navab, Joachim Horneg- ger, William M. Wells, and Alejandro F. Frangi (Eds.). Springer International Publishing, Cham, 234–241
2015
-
[23]
Stephane Ross, Brahim Chaib-draa, and Joelle Pineau. 2008. Bayesian reinforce- ment learning in continuous POMDPs with application to robot navigation. In 2008 IEEE International Conference on Robotics and Automation. IEEE, 2845–2851
2008
-
[24]
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. 2019. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision. 9339–9347
2019
-
[25]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[26]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Max Schwenzer, Muzaffer Ay, Thomas Bergs, and Dirk Abel. 2021. Review on model predictive control: An engineering perspective.The International Journal of Advanced Manufacturing Technology117, 5 (2021), 1327–1349
2021
-
[28]
James A Sethian. 1999. Fast marching methods.SIAM review41, 2 (1999), 199–235
1999
-
[29]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [30]
- [31]
-
[32]
Fei Xia, Amir R Zamir, Zhiyang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. 2018. Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE conference on computer vision and pattern recognition. 9068–9079
2018
-
[33]
Xinyao Yu, Sixian Zhang, Xinhang Song, Xiaorong Qin, and Shuqiang Jiang. 2024. Trajectory Diffusion for ObjectGoal Navigation.Advances in Neural Information Processing Systems37 (2024), 110388–110411
2024
-
[34]
Sixian Zhang, Xinyao Yu, Xinhang Song, Xiaohan Wang, and Shuqiang Jiang
-
[35]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Imagine Before Go: Self-Supervised Generative Map for Object Goal Navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16414–16425
- [36]
- [37]
-
[38]
Jiayu Zou, Kun Tian, Zheng Zhu, Yun Ye, and Xingang Wang. 2024. Diffbev: Conditional diffusion model for bird’s eye view perception. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 7846–7854
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.