VITAL: Visual-Semantic Dual Supervision for Enhanced and Interpretable Latent Reasoning in Medical MLLMs
Pith reviewed 2026-06-29 13:07 UTC · model grok-4.3
The pith
Visual-semantic dual supervision on latent states improves medical multimodal model accuracy and adds post-hoc explanations without inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
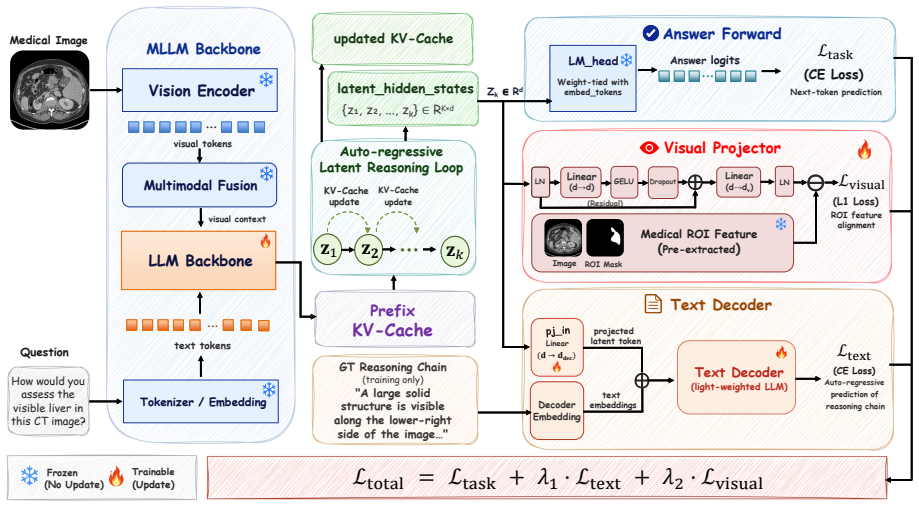
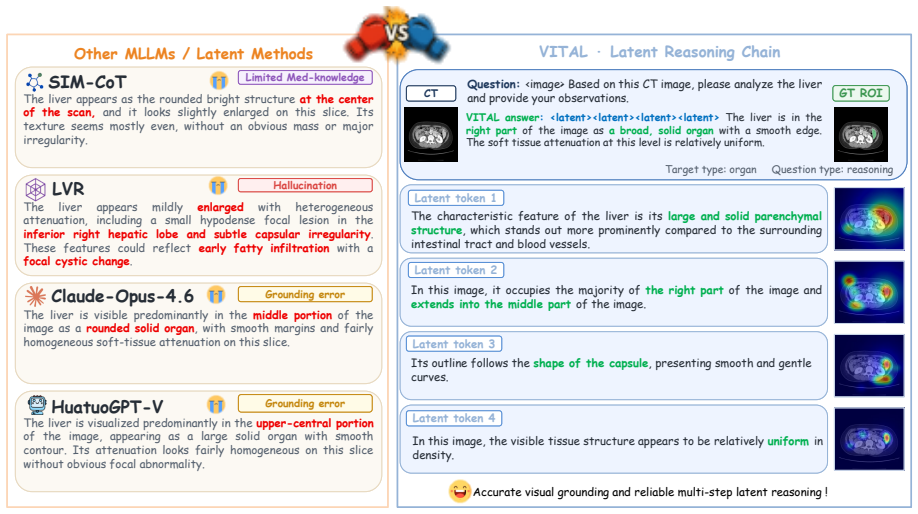
VITAL trains an auxiliary text decoder to reconstruct explicit reasoning chains from the model's latent states and a visual projector to regress region-of-interest features from a frozen independent medical vision encoder; both modules are discarded after training so that inference uses only the original model, yet they can be re-attached later to produce textual and visual explanations of the latent reasoning process.
What carries the argument
Visual-semantic dual supervision: auxiliary text decoder and visual projector that supervise latent states during training only.
If this is right
- Medical MLLMs reach higher accuracy on visual question answering tasks across multiple imaging modalities.
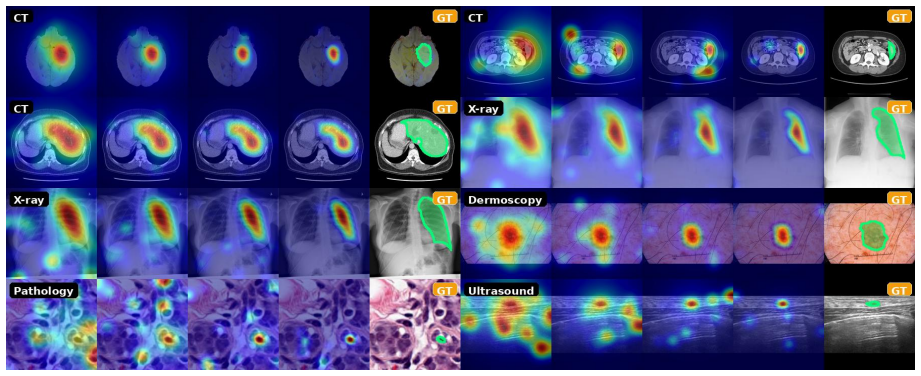
- Latent reasoning becomes inspectable through both textual chains and visual region highlights without changing inference speed.
- Models trained this way compete with much larger proprietary systems on standard medical benchmarks.
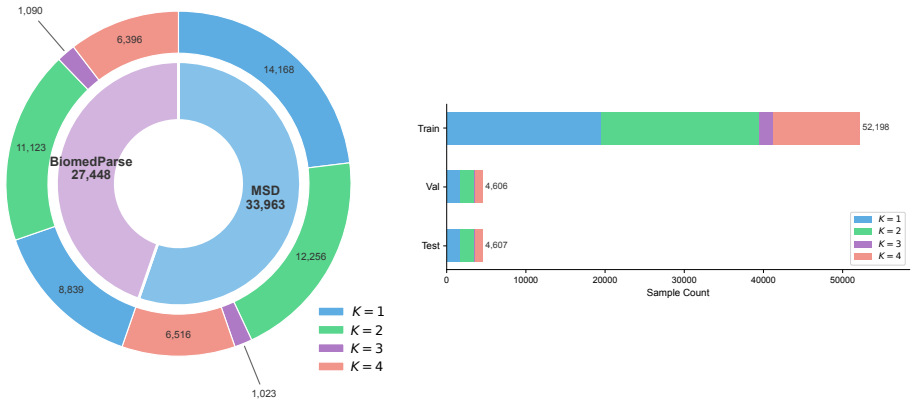
- A 61K-example dataset spanning nine modalities becomes available for training and evaluating similar methods.
- No extra parameters or compute remain at deployment time compared with the unmodified backbone.
Where Pith is reading between the lines
- The same training pattern could be tested on non-medical vision-language tasks where both accuracy and explanation are required.
- The dataset size increase by an order of magnitude may itself be a useful resource for studying modality alignment beyond this method.
- Re-attachment of the projectors could be used to surface failure modes when a model gives an incorrect answer on a clinical case.
- If the dual supervision generalizes, future work might explore additional supervision signals such as segmentation masks or temporal sequences.
Load-bearing premise
The auxiliary decoder and projector can be removed after training without losing the performance gains they produced, and re-attaching them will recover faithful explanations of the actual reasoning that occurred.
What would settle it
Measure whether accuracy on the seven benchmarks falls when the auxiliary modules are never present during training, or whether the explanations recovered by re-attaching the modules diverge from the decisions the model actually made on held-out cases.
Figures







read the original abstract
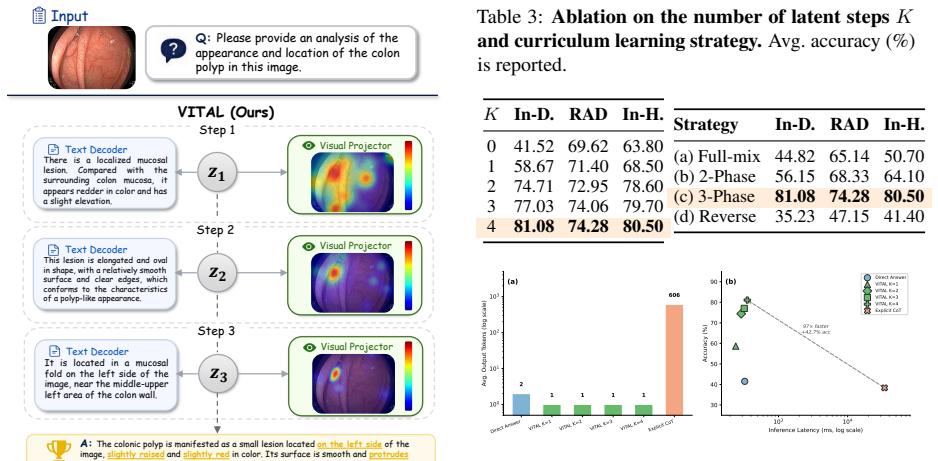
Latent reasoning enables reasoning over continuous hidden states rather than explicit tokens, avoiding the language bottleneck and inference overhead of chain-of-thought for medical VQA. However, existing methods suffer from modality collapse, insufficient visual supervision, and train-inference mismatch. Moreover, their opaque latent states offer no interpretability, which is critical in clinical applications. We propose VITAL, a latent-space reasoning framework for medical MLLMs with visual-semantic dual supervision: an auxiliary text decoder reconstructs reasoning chains from latent states, while a visual projector regresses ROI features from a frozen, independent medical vision encoder. Both modules are discarded at inference with zero overhead, yet can be re-attached post-hoc for dual interpretability, providing textual and visual explanations of the reasoning process without sacrificing efficiency. We construct a 61K dataset spanning 9 imaging modalities, exceeding prior medical visual latent reasoning datasets by an order of magnitude. Experiments on 7 benchmarks show that VITAL consistently and substantially outperforms the backbone, all latent reasoning baselines, and medical MLLMs trained on far larger data, achieving state-of-the-art results competitive with trillion-parameter proprietary models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VITAL, a latent reasoning framework for medical MLLMs that employs visual-semantic dual supervision through an auxiliary text decoder for reconstructing reasoning chains and a visual projector for regressing ROI features from a frozen vision encoder. These modules are discarded at inference for zero overhead but can be re-attached for interpretability. The authors introduce a 61K dataset across 9 modalities and report that VITAL outperforms the backbone, latent reasoning baselines, and larger medical MLLMs on 7 benchmarks, achieving SOTA results competitive with proprietary models.
Significance. If the reported performance gains are robust and the latent states indeed transfer effectively without the auxiliary modules, this work could significantly advance efficient, interpretable latent reasoning in medical vision-language models, addressing key issues like modality collapse and train-inference mismatch while providing clinical interpretability.
major comments (2)
- [Abstract] Abstract: The central claim that dual supervision produces latent states that remain effective once the auxiliary text decoder and visual projector are removed at inference (with 'zero overhead') is load-bearing for the efficiency-plus-performance argument, yet the text provides no explicit ablation isolating the auxiliaries' contribution versus the core latent-reasoning objective. If the SOTA margins on the 7 benchmarks depend on the presence of these supervision signals during training, the transfer claim does not hold.
- [Abstract] Abstract: The 61K dataset is presented as exceeding prior medical visual latent reasoning datasets by an order of magnitude and spanning 9 modalities, but no protocol for construction, quality assurance, or how it mitigates the cited limitations of existing datasets is described; this detail is required to substantiate the scale and novelty claims.
minor comments (1)
- The abstract invokes 'modality collapse' and 'train-inference mismatch' without a brief definition or citation; adding one sentence of context would aid readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that dual supervision produces latent states that remain effective once the auxiliary text decoder and visual projector are removed at inference (with 'zero overhead') is load-bearing for the efficiency-plus-performance argument, yet the text provides no explicit ablation isolating the auxiliaries' contribution versus the core latent-reasoning objective. If the SOTA margins on the 7 benchmarks depend on the presence of these supervision signals during training, the transfer claim does not hold.
Authors: We agree that an explicit ablation isolating the contribution of the dual supervision signals (auxiliary text decoder and visual projector) during training versus the core latent-reasoning objective alone would strengthen the transfer claim. The current experiments compare VITAL against the backbone and other latent reasoning baselines, but do not include a direct variant trained without the auxiliaries. In the revised manuscript, we will add this ablation study on the 7 benchmarks to demonstrate that the performance gains persist due to improved latent states from dual supervision. revision: yes
-
Referee: [Abstract] Abstract: The 61K dataset is presented as exceeding prior medical visual latent reasoning datasets by an order of magnitude and spanning 9 modalities, but no protocol for construction, quality assurance, or how it mitigates the cited limitations of existing datasets is described; this detail is required to substantiate the scale and novelty claims.
Authors: We acknowledge that the abstract does not detail the dataset construction protocol. The full manuscript contains a dedicated dataset section describing collection across 9 modalities and scale, but we agree it should more explicitly address quality assurance (e.g., expert validation and filtering criteria) and how it mitigates prior limitations such as small scale and limited modality diversity. In the revision, we will expand this section with the requested protocol details, quality controls, and explicit comparison to cited limitations of existing datasets. revision: yes
Circularity Check
No circularity: empirical gains from auxiliary supervision do not reduce to input definitions
full rationale
The paper's central claim rests on an additive training procedure (auxiliary text decoder + visual projector) whose outputs are evaluated on external benchmarks after the auxiliaries are removed. No equations, fitted parameters, or self-citations are shown to make the reported SOTA margins equivalent to the training inputs by construction. Dataset construction and dual-supervision objectives are independent of the final performance numbers. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.19280 , year=
The medical segmentation decathlon.Nature communications, 13(1):4128. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xi- dong Wang, Ruifei Zhang, ...
-
[2]
Suyang Xi, Songtao Hu, Yuxiang Lai, Wangyun Dan, Yaqi Liu, Shansong Wang, and Xiaofeng Yang
Unibiomed: A universal foundation model for grounded biomedical image interpretation. Suyang Xi, Songtao Hu, Yuxiang Lai, Wangyun Dan, Yaqi Liu, Shansong Wang, and Xiaofeng Yang
-
[3]
MedLVR: Latent Visual Reasoning for Reliable Medical Visual Question Answering
Medlvr: Latent visual reasoning for reliable medical visual question answering.arXiv preprint arXiv:2604.09757. Weiwen Xu, Hou Pong Chan, Long Li, Mahani Alju- nied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, and 1 others. 2025. Lingshu: A generalist foundation model for unified multimodal medical understanding an...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Biomedclip: a multimodal biomedical founda- tion model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915. Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2024. Pmc-vqa: Visual instruction tuning for medical visual question answering, 2024. Theodore Zhao, Yu Gu, Jianwei Y...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
A foundation model for joint segmentation, de- tection and recognition of biomedical objects across nine modalities.Nature methods, 22(1):166–176. A Training Data Construction VITAL requires each training sample to be a five- tuple (I,q,a,{e k}K k=1,f ROI): a medical image, a question, the final answer, a K-step reasoning chain, and a pre-extracted ROI vi...
2022
-
[6]
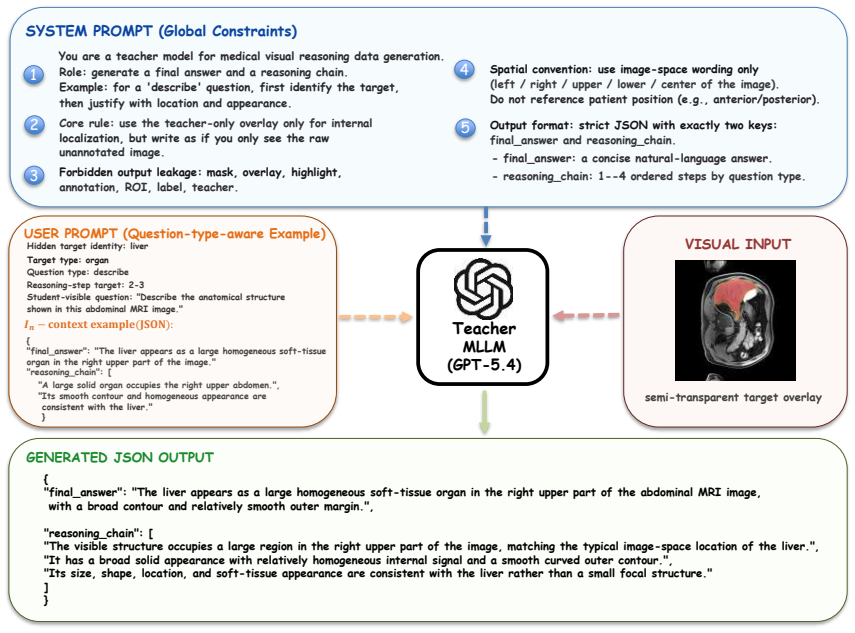
The teacher is in- structed to generate concise supervision for latent reasoning training, including a final an- swer and a reasoning chain
Role definition.The system prompt defines the model as a teacher for medical visual rea- 12 soning data generation. The teacher is in- structed to generate concise supervision for latent reasoning training, including a final an- swer and a reasoning chain
-
[7]
However, the output must be written as if it were produced by a stu- dent model that can only observe the original unannotated image
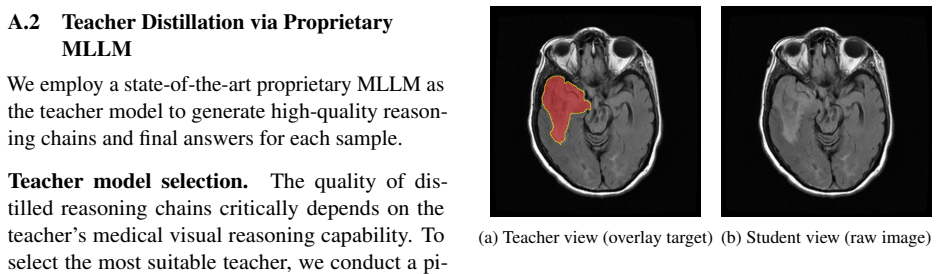
Teacher-only information usage.The teacher is allowed to use teacher-only infor- mation internally, including the overlay image and the hidden target identity, to localize the target region correctly. However, the output must be written as if it were produced by a stu- dent model that can only observe the original unannotated image
-
[8]
It also forbids statements suggesting that the cor- rect target identity was provided beforehand
Annotation-leakage prevention.The prompt explicitly forbids any mention or implication of hidden guidance, special markings, anno- tations, masks, overlays, highlighted areas, segmentation maps, ROI, labels, ground truth, teacher-only metadata, or extra visual cues. It also forbids statements suggesting that the cor- rect target identity was provided beforehand
-
[9]
Image-grounded medical reasoning.The teacher is required to base the answer and rea- soning chain on visible image evidence, such as location, shape, boundary, extent, density or signal intensity, texture, and relationships to nearby structures. For lesion or finding tar- gets, the teacher may name the given target itself, but should not introduce unsuppo...
-
[10]
Patient-space or radiological-convention wording, such as patient-left, patient-right, anatomical-left, or anatomical-right, is explicitly disallowed
Spatial convention.For spatial descrip- tions, the teacher must use image-space word- ing only, such as left, right, center, upper, and lower parts of the image. Patient-space or radiological-convention wording, such as patient-left, patient-right, anatomical-left, or anatomical-right, is explicitly disallowed
-
[11]
left”, “right
Output format.The teacher must return strict JSON with exactly two fields: final_answer and reasoning_chain. Markdown, code fences, and additional explanations are not allowed. The sample-specific user prompt further injects the target identity, target type, question type, and student-visible question. It also appends a question- type-specific guidance bl...
-
[12]
JSON parse validation.Verify that the teacher output is valid JSON conforming to the required schema (final_answer: string, reasoning_chain: list of strings)
-
[13]
Any hit triggers rejection and retry
Forbidden-term filtering.Scan both final_answer and all entries of reasoning_chain for any of the 30 annotation-leakage terms. Any hit triggers rejection and retry
-
[14]
lesion” or “mass
Pathology-style filtering (Organ only).For the normal-anatomy subset, check for inappro- priate use of pathology terms (e.g., describing a healthy liver as having a “lesion” or “mass”). This filter is disabled for BiomedParse where pathological descriptions are valid
-
[15]
patient’s right
Location-mixed filtering.Detect mixing of patient-space and image-space spatial refer- ences (e.g., “patient’s right” or “anatomical left”), which violates our image-space-only convention
-
[16]
Step-count validation.Verify that |reasoning_chain| falls within the tar- get range [min_steps,max_steps] defined by the question type
-
[17]
pancreas
Answer normalization.Standardize final_answer format according to question type: identification answers shorter than 4 words are expanded into complete sentences (e.g., “pancreas” → “The main organ shown is the pancreas.”); location answers are refor- matted with explicit image-space phrasing; all answers are ensured to end with a period. Retry mechanism....
2025
-
[18]
at the center of the scan
evaluates medical visual grounding through reasoning-based multiple-choice questions that re- quire attending to specific anatomical regions. We report accuracy following the official evaluation script. Held-out in-house testset.To mitigate evalua- tion bias caused by training-set contamination lead- ing to inflated accuracy and token-F1 scores, we in- tr...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.