PsyScore: A Psychometrically-Aware Framework for Trait-Adaptive Essay Scoring and ZPD-Scaffolded Feedback
Pith reviewed 2026-06-26 17:36 UTC · model grok-4.3
The pith
PsyScore links essay scoring to ability-adapted feedback through a shared psychometric parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
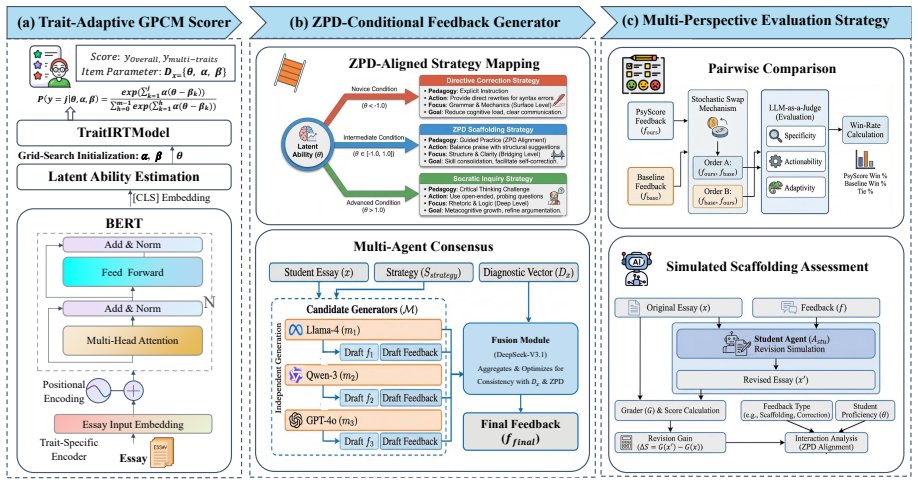
PsyScore comprises a Trait-Adaptive Neural IRT Scorer that embeds the Graded Partial Credit Model to produce both essay scores and an interpretable ability parameter, a ZPD-Scaffolded Feedback Generator that conditions multi-agent strategies on that parameter, and a Multi-Perspective Feedback Evaluation Strategy that measures quality through preference judgments and revision simulations; the shared ability representation thereby unifies diagnostic assessment with level-specific instructional support.
What carries the argument
The shared latent ability parameter produced by the Trait-Adaptive Neural IRT Scorer, which directly conditions the ZPD-Scaffolded Feedback Generator.
If this is right
- Scoring accuracy on ASAP++ remains competitive with prior neural AES systems.
- Feedback becomes more aligned with learner proficiency as judged by preference and revision metrics.
- A single ability estimate supports both assessment and scaffolding without separate models.
Where Pith is reading between the lines
- The same ability-conditioned loop could be tested on short-answer or programming tasks to check whether the unification generalizes.
- If the ability parameter proves stable across multiple essay prompts, the framework offers a route to longitudinal tracking of skill growth inside one system.
Load-bearing premise
The ability parameter estimated by the Trait-Adaptive Neural IRT Scorer can be directly used to condition multi-agent feedback strategies so that instructional focus adapts effectively across proficiency levels.
What would settle it
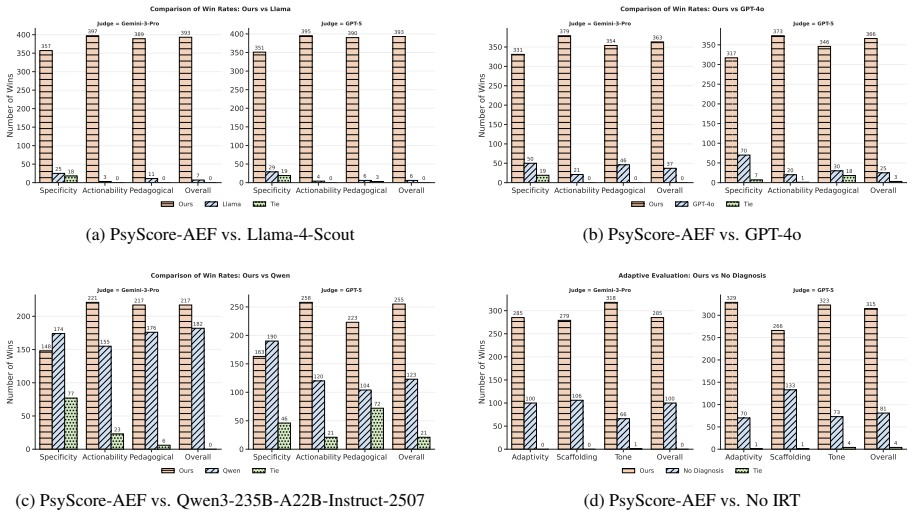
A controlled trial in which feedback generated without conditioning on the estimated ability parameter yields equal or higher student revision quality and preference scores than the ability-conditioned version.
Figures

read the original abstract
Effective Automated Essay Scoring (AES) are expected to support both reliable assessment and actionable instructional feedback. However, existing approaches often treat scoring and feedback as separate components: neural scoring models provide limited interpretability, while Large Language Model (LLM)-based feedback is typically insensitive to learners proficiency levels. To address this fragmentation, this work proposes PsyScore, a psychometrically-aware framework that integrates diagnostic assessment with instructional scaffolding through a shared latent ability representation. PsyScore comprises three key modules: a Trait-Adaptive Neural IRT Scorer that incorporates the Graded Partial Credit Model (GPCM) into a neural architecture, enabling the precise estimation of student ability while maintaining psychometric interpretability, a ZPD-Scaffolded Feedback Generator, which conditions multi-agent feedback strategies on the diagnosed ability parameter to adapt instructional focus across different proficiency levels, and a Multi-Perspective Feedback Evaluation Strategy that assesses feedback quality via pairwise preference judgements and student revision simulations. Experiments on the ASAP++ dataset demonstrate that PsyScore achieves competitive scoring performance while providing more pedagogically aligned feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PsyScore, a framework integrating three modules: a Trait-Adaptive Neural IRT Scorer that embeds the Graded Partial Credit Model (GPCM) into a neural architecture for essay scoring and student ability estimation, a ZPD-Scaffolded Feedback Generator that conditions multi-agent LLM feedback strategies on the estimated ability parameter to adapt instructional focus, and a Multi-Perspective Feedback Evaluation Strategy that uses pairwise preference judgments and student revision simulations to assess feedback quality. Experiments on the ASAP++ dataset are reported to show competitive scoring performance alongside more pedagogically aligned feedback than prior approaches.
Significance. If the central results hold after addressing the evaluation gap, the work would offer a concrete bridge between psychometric models and LLM-based feedback systems, potentially improving interpretability and adaptivity in automated essay scoring. The shared latent ability representation is a clear conceptual strength that could influence future designs in educational NLP if the conditioning effect is isolated and quantified.
major comments (1)
- [Multi-Perspective Feedback Evaluation Strategy] Multi-Perspective Feedback Evaluation Strategy: the reported experiments do not include an ablation isolating the effect of conditioning the ZPD-Scaffolded Feedback Generator on the GPCM-derived ability parameter (e.g., ability-conditioned multi-agent feedback versus fixed-prompt or unconditioned baselines). This comparison is required to substantiate the claim that the shared latent representation yields measurably more pedagogically aligned output or revision gains; without it, improvements cannot be attributed to the ability-parameter mechanism rather than other design choices.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on evaluation design. We agree that isolating the contribution of the ability-parameter conditioning is necessary to strengthen the central claim and will add the requested ablation in revision.
read point-by-point responses
-
Referee: [Multi-Perspective Feedback Evaluation Strategy] Multi-Perspective Feedback Evaluation Strategy: the reported experiments do not include an ablation isolating the effect of conditioning the ZPD-Scaffolded Feedback Generator on the GPCM-derived ability parameter (e.g., ability-conditioned multi-agent feedback versus fixed-prompt or unconditioned baselines). This comparison is required to substantiate the claim that the shared latent representation yields measurably more pedagogically aligned output or revision gains; without it, improvements cannot be attributed to the ability-parameter mechanism rather than other design choices.
Authors: We agree that the current experiments do not contain a direct ablation isolating the conditioning of the ZPD-Scaffolded Feedback Generator on the GPCM-derived ability parameter. The manuscript reports overall competitive scoring and feedback alignment but does not compare ability-conditioned multi-agent strategies against fixed-prompt or unconditioned baselines. In the revised version we will add this ablation on the ASAP++ dataset, reporting pairwise preference judgments and revision-simulation outcomes for the three conditions. This will allow quantification of the incremental effect attributable to the shared latent ability representation. revision: yes
Circularity Check
No circularity: framework integrates independent modules via shared latent variable
full rationale
The derivation chain estimates student ability via the Trait-Adaptive Neural IRT Scorer (incorporating GPCM), then uses that parameter to condition the separate ZPD-Scaffolded Feedback Generator, and evaluates the output with an independent Multi-Perspective Feedback Evaluation Strategy (pairwise preferences and revision simulations). None of these steps reduce to self-definition, fitted-input-as-prediction, or self-citation load-bearing; the shared latent representation is an explicit design choice rather than a tautology, and no equations or claims in the abstract or described modules collapse the output back to the input by construction. The paper remains self-contained against external benchmarks on ASAP++.
Axiom & Free-Parameter Ledger
free parameters (1)
- student ability parameter
axioms (1)
- domain assumption The Graded Partial Credit Model can be incorporated into a neural architecture while preserving psychometric interpretability.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Dual-scale
Cho, Minsoo and Huang, Jin-Xia and Kwon, Oh-Woog , year =. Dual-scale. ETRI Journal , volume =
-
[10]
An interpretable polytomous cognitive diagnosis framework for predicting examinee performance , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.ipm.2024.103913 , url =
-
[11]
2025 , eprint=
MetaCD: A Meta Learning Framework for Cognitive Diagnosis based on Continual Learning , author=. 2025 , eprint=
2025
-
[12]
A Trait-based Deep Learning Automated Essay Scoring System with Adaptive Feedback , journal =. 2020 , publisher =. doi:10.14569/IJACSA.2020.0110538 , url =
-
[13]
Lee, Sanwoo and Cai, Yida and Meng, Desong and Wang, Ziyang and Wu, Yunfang , year =. Unleashing. doi:10.48550/arXiv.2404.04941 , note =
-
[15]
doi:10.48550/ARXIV.2502.11916 , note =
Su, Jiamin and Yan, Yibo and Fu, Fangteng and Zhang, Han and Ye, Jingheng and Liu, Xiang and Huo, Jiahao and Zhou, Huiyu and Hu, Xuming , year =. doi:10.48550/ARXIV.2502.11916 , note =
-
[16]
T - MES : Trait-Aware Mix-of-Experts Representation Learning for Multi-trait Essay Scoring
Wang, Jiong and Liu, Jie. T - MES : Trait-Aware Mix-of-Experts Representation Learning for Multi-trait Essay Scoring. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[17]
Ormerod, Christopher , month =. Automated. 2025 , note =. doi:10.48550/arXiv.2505.22771 , publisher =
-
[18]
Jordan, Joaquin and Yin, Xavier and Fabros, Melissa and Ranade, Gireeja and Norouzi, Narges , month =. 2025 , note =. doi:10.48550/arXiv.2506.13037 , publisher =
-
[19]
Zafar, Samra and Minhas, Shaheer and Zaidi, Syed Ali Hassan and Naeem, Arfa and Ali, Zahra , month =. ". 2025 , note =. doi:10.48550/arXiv.2506.08221 , publisher =
-
[20]
doi:10.1145/3726302.3730143 , author =
2025 , note =. doi:10.1145/3726302.3730143 , author =
-
[22]
Morris, Oscar , month =. Transfer. 2025 , note =. doi:10.48550/arXiv.2503.11836 , publisher =
-
[23]
Liu, Zhexiong and Litman, Diane and Wang, Elaine and Li, Tianwen and Gobat, Mason and Matsumura, Lindsay Clare and Correnti, Richard , month =. 2025 , note =. doi:10.48550/arXiv.2501.00715 , publisher =
-
[24]
Zeinalipour, Kamyar and Mehak, Mehak and Parsamotamed, Fatemeh and Maggini, Marco and Gori, Marco , month =. Advancing. 2025 , note =. doi:10.48550/arXiv.2501.07740 , publisher =
-
[25]
Kim, Minsun and Kim, SeonGyeom and Lee, Suyoun and Yoon, Yoosang and Myung, Junho and Yoo, Haneul and Lim, Hyunseung and Han, Jieun and Kim, Yoonsu and Ahn, So-Yeon and Kim, Juho and Oh, Alice and Hong, Hwajung and Lee, Tak Yeon , month =. 2024 , note =. doi:10.48550/arXiv.2410.15025 , publisher =
-
[26]
Wang, Yupei and Hu, Renfen and Zhao, Zhe , month =. Beyond. 2024 , note =. doi:10.48550/arXiv.2405.19433 , publisher =
-
[27]
Katuka, Gloria Ashiya and Gain, Alexander and Yu, Yen-Yun , month =. Investigating. 2024 , note =. doi:10.48550/arXiv.2405.00602 , publisher =
-
[28]
Karizaki, Mahsa Sheikhi and Gnesdilow, Dana and Puntambekar, Sadhana and Passonneau, Rebecca J. , month =. How. 2024 , note =. doi:10.48550/arXiv.2404.11682 , publisher =
-
[29]
Wang, Izia Xiaoxiao and Wu, Xihan and Coates, Edith and Zeng, Min and Kuang, Jiexin and Liu, Siliang and Qiu, Mengyang and Park, Jungyeul , month =. Neural. 2024 , note =. doi:10.48550/arXiv.2402.17613 , publisher =
-
[30]
Yoon, Su-Youn and Miszoglad, Eva and Pierce, Lisa R. , month =. Evaluation of. 2023 , note =. doi:10.48550/arXiv.2310.06505 , publisher =
-
[31]
Solopova, Veronika and Gruszczynski, Adrian and Rostom, Eiad and Cremer, Fritz and Witte, Sascha and Zhang, Chengming and Plößl, Fernando Ramos López Lea and Hofmann, Florian and Romeike, Ralf and Gläser-Zikuda, Michaela and Benzmüller, Christoph and Landgraf, Tim , month =. 2023 , note =. doi:10.48550/arXiv.2307.07523 , publisher =
-
[32]
Jong, You-Jin and Kim, Yong-Jin and Ri, Ok-Chol , month =. Review of feedback in. 2023 , note =. doi:10.48550/arXiv.2307.05553 , publisher =
-
[33]
Liu, Zhexiong and Litman, Diane and Wang, Elaine and Matsumura, Lindsay and Correnti, Richard , month =. Predicting the. 2023 , note =. doi:10.48550/arXiv.2306.00667 , publisher =
-
[34]
British Journal of Educational Technology , author =
Practical and. British Journal of Educational Technology , author =. 2024 , note =. doi:10.1111/bjet.13370 , number =
-
[35]
Abhishek, Tushar and Rawat, Daksh and Gupta, Manish and Varma, Vasudeva , month =. Transformer. 2022 , note =. doi:10.48550/arXiv.2109.02176 , publisher =
-
[36]
Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =
Afrin, Tazin and Kashefi, Omid and Olshefski, Christopher and Litman, Diane and Hwa, Rebecca and Godley, Amanda , month =. Effective. 2021 , note =. doi:10.1145/3411764.3445683 , booktitle =
-
[37]
Hong, Shengxin and Cai, Chang and Du, Sixuan and Feng, Haiyue and Liu, Siyuan and Fan, Xiuyi , month =. ". 2024 , note =. doi:10.48550/arXiv.2409.07453 , publisher =
-
[38]
Shibata, Takumi and Miyamura, Yuichi , month =. 2025 , note =. doi:10.48550/arXiv.2505.08498 , publisher =
-
[39]
Plasencia-Calaña, Yenisel , month =. Operationalizing. 2025 , note =. doi:10.48550/arXiv.2506.21603 , publisher =
-
[40]
Yoshida, Lui , month =. Do. 2025 , note =. doi:10.48550/arXiv.2505.01035 , publisher =
-
[41]
and Kwong, Theresa and Atif, Amara , month =
Kamalov, Firuz and Calonge, David Santandreu and Smail, Linda and Azizov, Dilshod and Thadani, Dimple R. and Kwong, Theresa and Atif, Amara , month =. Evolution of. 2025 , note =. doi:10.48550/arXiv.2504.20082 , publisher =
-
[42]
Cai, Yida and Liang, Kun and Lee, Sanwoo and Wang, Qinghan and Wu, Yunfang , month =. Rank-. 2025 , note =. doi:10.48550/arXiv.2504.05736 , publisher =
-
[43]
and Yang, Yi and Abbasi, Ahmed , month =
Oketch, Kezia and Lalor, John P. and Yang, Yi and Abbasi, Ahmed , month =. Bridging the. 2025 , note =. doi:10.48550/arXiv.2503.11827 , publisher =
-
[44]
Do, Heejin and Ryu, Sangwon and Lee, Gary Geunbae , month =. Teach-to-. 2025 , note =. doi:10.48550/arXiv.2502.20748 , publisher =
-
[45]
Ghazawi, Rayed and Simpson, Edwin , month =. How well can. 2025 , note =. doi:10.48550/arXiv.2501.16516 , publisher =
-
[46]
Wendlinger, Lorenz and Braun, Christian and Zubaer, Abdullah Al and Nonn, Simon Alexander and Großkopf, Sarah and Fellicious, Christofer and Granitzer, Michael , month =. On the. 2024 , note =. doi:10.48550/arXiv.2412.15902 , publisher =
-
[47]
Zhong, Yang and Hao, Jiangang and Fauss, Michael and Li, Chen and Wang, Yuan , month =. Evaluating. 2024 , note =. doi:10.48550/arXiv.2410.17439 , publisher =
-
[48]
Kundu, Anindita and Barbosa, Denilson , month =. Are. 2024 , note =. doi:10.48550/arXiv.2409.13120 , publisher =
-
[49]
Kim, Seungju and Jo, Meounggun , month =. Is. 2024 , note =. doi:10.1145/3657604.3664703 , booktitle =
-
[50]
Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring
Dong, Fei and Zhang, Yue and Yang, Jie , year =. Attention-based. doi:10.18653/v1/K17-1017 , booktitle =
-
[51]
Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays , booktitle =
Rahul Kumar and Sandeep Mathias and Sriparna Saha and Pushpak Bhattacharyya , editor =. Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays , booktitle =. 2022 , url =
2022
-
[52]
Automated essay scoring with string kernels and word embeddings
Cozma, M a d a lina and Butnaru, Andrei and Ionescu, Radu Tudor. Automated essay scoring with string kernels and word embeddings. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2080
-
[53]
2023 , doi =
Document. 2023 , doi =
2023
-
[54]
Linking essay-writing tests using many-facet models and neural automated essay scoring , url =
Uto, Masaki and Aramaki, Kota , month =. Linking essay-writing tests using many-facet models and neural automated essay scoring , url =. doi:10.3758/s13428-024-02485-2 , journal =
-
[55]
Uto, Masaki and Takahashi, Yuto , editor =. Neural. Artificial. 2024 , doi =
2024
-
[56]
Difficulty-
Tomikawa, Yuto and Uto, Masaki , editor =. Difficulty-. Artificial. 2024 , doi =
2024
-
[57]
Artificial
Shindo, Naoki and Uto, Masaki , editor =. Artificial. 2024 , doi =
2024
-
[58]
Behavior Research Methods , author =
A. Behavior Research Methods , author =. 2022 , pages =. doi:10.3758/s13428-022-01997-z , number =
-
[59]
Yamaura, Misato and Fukuda, Itsuki and Uto, Masaki , editor =. Neural. Artificial. 2023 , doi =
2023
-
[60]
Behavior Research Methods , author =
Accuracy of performance-test linking based on a many-facet. Behavior Research Methods , author =. 2021 , pages =. doi:10.3758/s13428-020-01498-x , number =
-
[61]
Special issue: e-testing from artificial intelligence approach , volume =. Behaviormetrika , author =. 2021 , pages =. doi:10.1007/s41237-021-00146-8 , number =
-
[62]
A multidimensional generalized many-facet. Behaviormetrika , author =. 2021 , pages =. doi:10.1007/s41237-021-00144-w , number =
-
[63]
A review of deep-neural automated essay scoring models , volume =. Behaviormetrika , author =. 2021 , pages =. doi:10.1007/s41237-021-00142-y , number =
-
[64]
Integration of
Aomi, Itsuki and Tsutsumi, Emiko and Uto, Masaki and Ueno, Maomi , editor =. Integration of. Artificial. 2021 , doi =
2021
-
[65]
Uto, Masaki , editor =. A. Artificial. 2021 , doi =
2021
-
[66]
Estimating
Nakayama, Minoru and Sciarrone, Filippo and Uto, Masaki and Temperini, Marco , editor =. Estimating. Methodologies and. 2021 , doi =
2021
-
[67]
A generalized many-facet. Behaviormetrika , author =. 2020 , pages =. doi:10.1007/s41237-020-00115-7 , number =
-
[68]
International Journal of Artificial Intelligence in Education , author =
Time- and. International Journal of Artificial Intelligence in Education , author =. 2020 , pages =. doi:10.1007/s40593-019-00189-9 , number =
-
[69]
Automated
Uto, Masaki and Uchida, Yuto , editor =. Automated. Artificial. 2020 , doi =
2020
-
[70]
Uto, Masaki and Okano, Masashi , editor =. Robust. Artificial. 2020 , doi =
2020
-
[71]
Uto, Masaki , editor =. Rater-. Artificial. 2019 , doi =
2019
-
[72]
Social constructivist approach of motivation: social media messages recommendation system , url =
Louvigné, Sébastien and Uto, Masaki and Kato, Yoshihiro and Ishii, Takatoshi , month =. Social constructivist approach of motivation: social media messages recommendation system , url =. doi:10.1007/s41237-017-0043-7 , journal =
-
[73]
Uto, Masaki and Ueno, Maomi , editor =. Item. Artificial. 2018 , doi =
2018
-
[74]
and Yancey, Kevin and von Davier, Alina A
Burstein, Jill and LaFlair, Geoffrey T. and Yancey, Kevin and von Davier, Alina A. and Dotan, Ravit , year =. Responsible. doi:10.48550/ARXIV.2409.07476 , publisher =
-
[75]
Collaborative
Aramaki, Kota and Uto, Masaki , editor =. Collaborative. Artificial. 2024 , doi =
2024
-
[76]
Ridley, Robert and He, Liang and Dai, Xinyu and Huang, Shujian and Chen, Jiajun , month =. Prompt. 2020 , note =
2020
-
[77]
Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , month =
Automated Essay Scoring Using Grammatical Variety and Errors with Multi-Task Learning and Item Response Theory , author =. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024) , month =. 2024 , address =
2024
-
[78]
IEEE Transactions on Learning Technologies , author =
Integration of. IEEE Transactions on Learning Technologies , author =. 2023 , pages =. doi:10.1109/TLT.2023.3253215 , number =
-
[79]
IEEE Transactions on Learning Technologies , author =
Learning. IEEE Transactions on Learning Technologies , author =. 2021 , pages =. doi:10.1109/TLT.2022.3145352 , number =
-
[80]
Analytic
Shibata, Takumi and Uto, Masaki , year =. Analytic
-
[81]
doi:https://doi.org/10.1016/j.eswa.2023.123043 , journal =
Liu, Yuanchao and Han, Jiawei and Sboev, Alexander and Makarov, Ilya , year =. doi:https://doi.org/10.1016/j.eswa.2023.123043 , journal =
-
[82]
1990 , publisher =
Item Response Theory , author =. 1990 , publisher =
1990
-
[83]
1991 , publisher =
Fundamentals of Item Response Theory , author =. 1991 , publisher =
1991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.