Beyond Text Following: Repairable Arbitration Reversals in Audio-Language Models
Pith reviewed 2026-06-28 04:48 UTC · model grok-4.3
The pith
Audio-language models encode audio evidence but override it with conflicting text during arbitration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
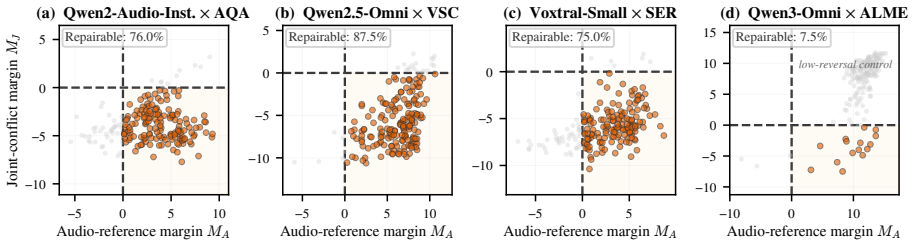
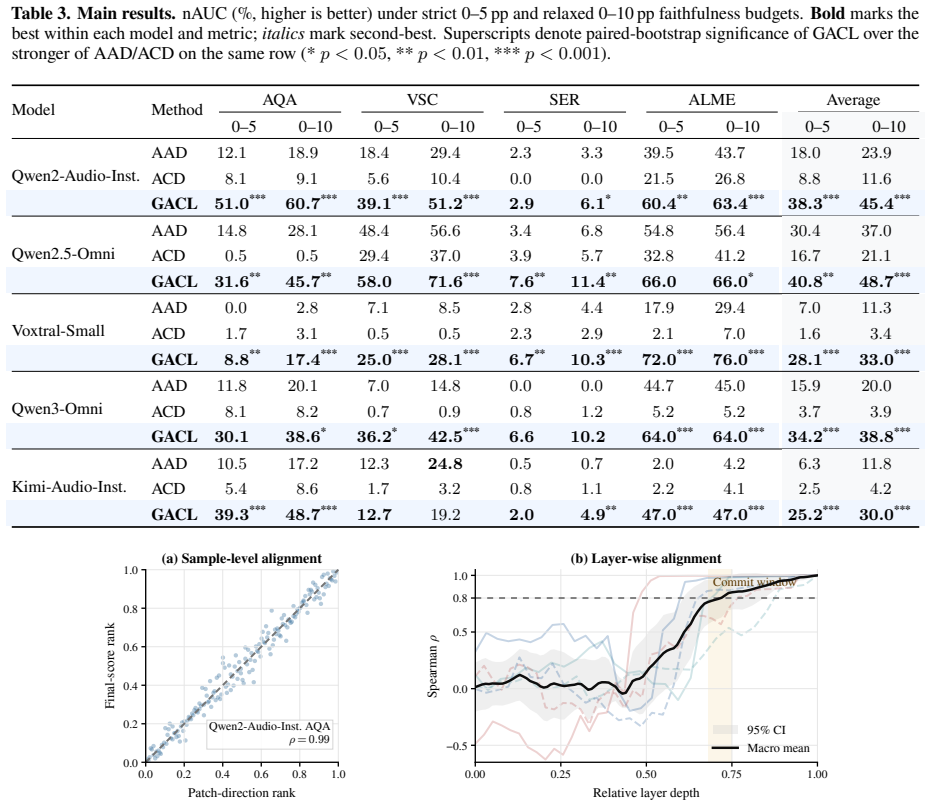
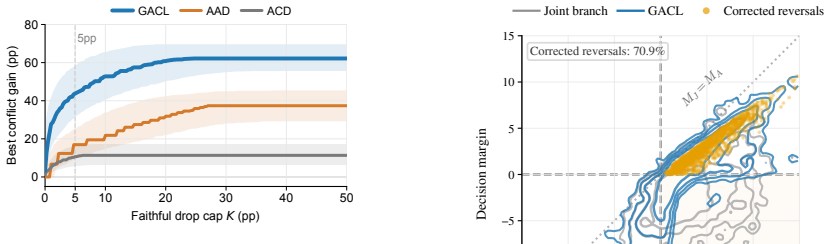
Across five audio-language models and four conflict tasks, 64.1 percent of conflict samples exhibit a sign flip in which the same-audio branch prefers the audio-supported answer while the joint branch prefers the text-supported answer. This pattern indicates that the relevant audio evidence is encoded in the model but loses arbitration to the conflicting text. Activation patching localizes the reversal to answer-position computation, and the patching effects track output candidate-score differences with Spearman rho of 0.93. The proposed Gated Audio Counterfactual Logit Correction rule interpolates between joint and same-audio scores during decoding, improving normalized AUC by 17.8 points o
What carries the argument
The same-audio counterfactual that keeps audio fixed while removing only the conflicting text to isolate the effect of text arbitration on model preference.
If this is right
- Audio evidence is represented internally but loses to text in arbitration, so the supported answer remains recoverable without retraining.
- Reversals localize to answer-position computation and can be detected via activation patching that tracks score differences.
- A training-free interpolation between joint and same-audio scores repairs the reversal while staying within a five-percentage-point faithfulness budget.
- The same reversal pattern and repair method transfer directly to vision-text arbitration without retuning.
Where Pith is reading between the lines
- Training data or loss functions may systematically favor text over audio, creating a general arbitration bias across multimodal models.
- The sign-flip rate could serve as a diagnostic metric for modality balance in new audio-language models.
- The same counterfactual approach could be applied to other sensory-text conflicts to test whether arbitration reversals are modality-specific.
Load-bearing premise
The same-audio counterfactual isolates the effect of text arbitration without altering other model computations or introducing new biases in preference measurement.
What would settle it
If the same-audio branch shows no consistent preference for the audio-supported answer across most conflict samples, or if activation patching effects fail to correlate with output score differences, the claim that audio evidence is encoded but overridden would not hold.
Figures


read the original abstract
Audio-language models (ALMs) often follow text that conflicts with audio, even when the audio evidence is clear. This raises a basic question: is the audio-supported answer unavailable, or is it represented but overridden by the conflicting text? We examine this question using a same-audio counterfactual that keeps the audio fixed, removes only the conflicting text, and measures the resulting shift in model preference. Across five ALMs and four conflict tasks, 64.1% of conflict samples show a sign flip: the same-audio branch prefers the audio-supported answer, whereas the joint branch prefers the text-supported answer. This pattern suggests that the relevant audio evidence is encoded but loses in arbitration. Activation patching further localizes the reversal to answer-position computation, and patching effects closely track output candidate-score differences (Spearman rho=0.93). Using this diagnostic, we propose Gated Audio Counterfactual Logit Correction (GACL), a training-free decoding rule that interpolates between joint and same-audio scores. Under a strict 5 pp faithfulness-drop budget, GACL improves nAUC by 17.8 points over the best contrastive baseline and transfers without retuning to vision-text arbitration (up to +40.5 pp).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that audio-language models (ALMs) encode audio evidence even when it conflicts with text, but this evidence is overridden during arbitration. Using a same-audio counterfactual (audio input fixed while removing only conflicting text), they report a sign flip in model preference for the audio-supported answer in 64.1% of conflict samples across five ALMs and four tasks. Activation patching localizes the reversal to answer-position computation, with patching effects tracking output candidate-score differences (Spearman rho=0.93). They propose Gated Audio Counterfactual Logit Correction (GACL), a training-free decoding rule interpolating between joint and same-audio scores, which improves nAUC by 17.8 points over the best contrastive baseline under a strict 5 pp faithfulness-drop budget and transfers to vision-text arbitration (up to +40.5 pp).
Significance. If the central findings hold, the work provides useful empirical evidence that audio evidence is represented but loses in text arbitration within ALMs, along with a practical diagnostic and training-free intervention (GACL). The scale (five models, four tasks), high patching correlation, and cross-modal transfer results are strengths that would make the contribution notable for understanding multimodal conflicts. The approach supplies falsifiable predictions via the counterfactual and patching measurements.
major comments (1)
- [Abstract] Abstract: The 64.1% sign-flip statistic and the interpretation that audio evidence is 'encoded but overridden' rest on the same-audio counterfactual cleanly isolating text arbitration. Removing conflicting text tokens can shift token positions, attention patterns over audio features, or internal states even with identical audio input, so the observed preference reversal may reflect altered audio encoding rather than pure removal of text influence. This is load-bearing for the central claim and is not obviously ruled out by the reported activation patching (which occurs after the counterfactual input is processed).
minor comments (2)
- The abstract reports concrete percentages, Spearman rho, and transfer results, but full methods, data splits, and statistical tests are not visible, limiting independent verification of the central numbers.
- The definition and implementation details of GACL (including how the interpolation weight is chosen under the faithfulness budget) should be expanded with pseudocode or explicit equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about whether the same-audio counterfactual cleanly isolates text arbitration is substantive and load-bearing. We address it directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 64.1% sign-flip statistic and the interpretation that audio evidence is 'encoded but overridden' rest on the same-audio counterfactual cleanly isolating text arbitration. Removing conflicting text tokens can shift token positions, attention patterns over audio features, or internal states even with identical audio input, so the observed preference reversal may reflect altered audio encoding rather than pure removal of text influence. This is load-bearing for the central claim and is not obviously ruled out by the reported activation patching (which occurs after the counterfactual input is processed).
Authors: We agree that sequence changes from text removal can alter token positions and attention over audio features, so the counterfactual does not provide a perfectly isolated removal of text influence. However, the audio waveform and its encoded features remain identical across branches; the observed sign flip therefore still demonstrates that the joint input (with conflicting text) produces a different preference than the audio-only input. The activation-patching results (performed on the joint input) localize the reversal specifically to answer-position computation and show a Spearman rho of 0.93 with output score differences, which is consistent with arbitration at the final decision stage rather than wholesale changes in upstream audio encoding. We will add an explicit limitations paragraph discussing this potential confound, including the possibility that attention shifts contribute, and will note that stronger isolation (e.g., via attention masking or synthetic position controls) remains future work. revision: partial
Circularity Check
Empirical measurements and diagnostic-defined method are self-contained
full rationale
The paper's load-bearing claims consist of direct empirical counts (64.1% sign flips across five models and four tasks), a measured Spearman correlation (rho=0.93) between patching effects and score differences, and measured nAUC gains for GACL. GACL itself is defined explicitly as an interpolation between the joint-branch and same-audio counterfactual scores rather than being fitted to the target nAUC metric. No equations, self-citations, or uniqueness theorems are invoked that would make any reported result equivalent to its inputs by construction. The derivation chain therefore remains independent of the measured quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
When Audio and Text Disagree: Revealing Text Bias in Large Audio-Language Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.246 , url =
- [2]
-
[3]
2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year =
Reducing Object Hallucination in Large Audio-Language Models via Audio-Aware Decoding , author =. 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year =. doi:10.1109/ASRU65441.2025.11434595 , url =
-
[4]
2026 , eprint =
How Contrastive Decoding Enhances Large Audio Language Models? , author =. 2026 , eprint =
2026
-
[5]
Proceedings of the Twelfth Language Resources and Evaluation Conference , year =
Common Voice: A Massively-Multilingual Speech Corpus , author =. Proceedings of the Twelfth Language Resources and Evaluation Conference , year =
-
[6]
Chu, Yunfei and Xu, Jin and Yang, Qian and Wei, Haojie and Wei, Xipin and Guo, Zhifang and Leng, Yichong and Lv, Yuanjun and He, Jinzheng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , year =. 2407.10759 , archivePrefix =
-
[7]
Xu, Jin and Guo, Zhifang and He, Jinzheng and Hu, Hangrui and He, Ting and Bai, Shuai and Chen, Keqin and Wang, Jialin and Fan, Yang and Dang, Kai and Zhang, Bin and Wang, Xiong and Chu, Yunfei and Lin, Junyang , year =. 2503.20215 , archivePrefix =
-
[8]
Xu, Jin and Guo, Zhifang and Hu, Hangrui and Chu, Yunfei and Wang, Xiong and He, Jinzheng and Wang, Yuxuan and Shi, Xian and He, Ting and Zhu, Xinfa and Lv, Yuanjun and Wang, Yongqi and Guo, Dake and Wang, He and Ma, Linhan and Zhang, Pei and Zhang, Xinyu and Hao, Hongkun and Guo, Zishan and Yang, Baosong and Zhang, Bin and Ma, Ziyang and Wei, Xipin and B...
-
[9]
2025 , eprint=
Voxtral , author=. 2025 , eprint=
2025
-
[10]
2024 , url =
Tang, Changli and Yu, Wenyi and Sun, Guangzhi and Chen, Xianzhao and Tan, Tian and Li, Wei and Lu, Lu and Ma, Zejun and Zhang, Chao , booktitle =. 2024 , url =
2024
-
[11]
The Twelfth International Conference on Learning Representations , year =
Listen, Think, and Understand , author =. The Twelfth International Conference on Learning Representations , year =
-
[12]
Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha
Ghosh, Sreyan and Kumar, Sonal and Seth, Ashish and Evuru, Chandra Kiran Reddy and Tyagi, Utkarsh and Sakshi, S and Nieto, Oriol and Duraiswami, Ramani and Manocha, Dinesh , booktitle =. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.361 , url =
-
[13]
Proceedings of the 41st International Conference on Machine Learning , year =
Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[14]
Knowledge conflicts for LLMs: A survey
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei , booktitle =. Knowledge Conflicts for. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.486 , url =
-
[15]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
Investigating Context Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style , author =. Findings of the Association for Computational Linguistics: ACL 2025 , year =. doi:10.18653/v1/2025.findings-acl.247 , url =
-
[16]
The Twelfth International Conference on Learning Representations , year =
Towards Understanding Sycophancy in Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[17]
2024 , eprint =
Simple Synthetic Data Reduces Sycophancy in Large Language Models , author =. 2024 , eprint =
2024
-
[18]
Discovering Language Model Behaviors with Model-Written Evaluations , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =. doi:10.18653/v1/2023.findings-acl.847 , url =
-
[19]
Hashimoto, Luke Zettlemoyer, and Mike Lewis
Contrastive Decoding: Open-ended Text Generation as Optimization , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/2023.acl-long.687 , url =
-
[20]
and He, Pengcheng , booktitle =
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James R. and He, Pengcheng , booktitle =. 2024 , url =
2024
-
[21]
Vbench: Comprehensive benchmark suite for video generative models
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =. doi:10.1109/CVPR52733.2024.01316 , url =
-
[22]
Vbench: Comprehensive benchmark suite for video generative models
Huang, Qidong and Dong, Xiaoyi and Zhang, Pan and Wang, Bin and He, Conghui and Wang, Jiaqi and Lin, Dahua and Zhang, Weiming and Yu, Nenghai , booktitle =. 2024 , pages =. doi:10.1109/CVPR52733.2024.01274 , url =
-
[23]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding , author =. Findings of the Association for Computational Linguistics: ACL 2024 , year =. doi:10.18653/v1/2024.findings-acl.937 , url =
-
[24]
Advances in Neural Information Processing Systems , year =
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author =. Advances in Neural Information Processing Systems , year =
-
[25]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , volume =
2022
-
[26]
The Twelfth International Conference on Learning Representations , year =
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods , author =. The Twelfth International Conference on Learning Representations , year =
-
[27]
2016 , eprint =
Understanding Intermediate Layers Using Linear Classifier Probes , author =. 2016 , eprint =
2016
-
[28]
Designing and Interpreting Probes with Control Tasks , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , year =. doi:10.18653/v1/D19-1275 , url =
-
[29]
2020 , howpublished =
Interpreting. 2020 , howpublished =
2020
-
[30]
2023 , eprint =
Steering Language Models With Activation Engineering , author =. 2023 , eprint =
2023
-
[31]
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
-
[32]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander , booktitle =. Steering. 2024 , address =. doi:10.18653/v1/2024.acl-long.828 , url =
-
[33]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
2022
-
[34]
Journal of Machine Learning Research , volume =
On the Foundations of Noise-Free Selective Classification , author =. Journal of Machine Learning Research , volume =. 2010 , url =
2010
-
[35]
Advances in Neural Information Processing Systems , volume =
Selective Classification for Deep Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[36]
Analyzing a Portion of the
McClish, Donna Katzman , journal =. Analyzing a Portion of the. 1989 , doi =
1989
-
[37]
2025 , eprint =
Evaluating and Steering Modality Preferences in Multimodal Large Language Model , author =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.