BRo-JEPA: Learning Modular Arithmetic in Latent Space
Pith reviewed 2026-06-28 17:38 UTC · model grok-4.3
The pith
A block-rotation predictor in a JEPA latent world model enables learning of modular arithmetic with 99.46% zero-shot generalization to unseen operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
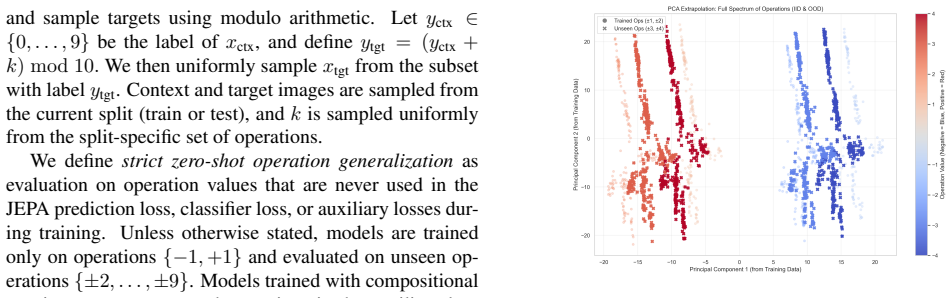
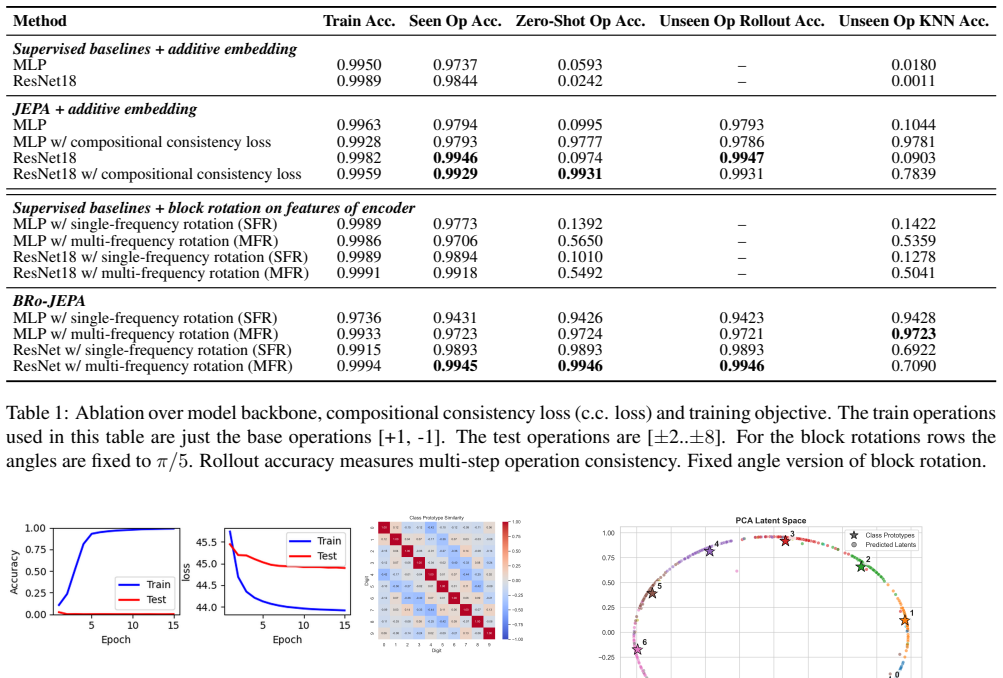
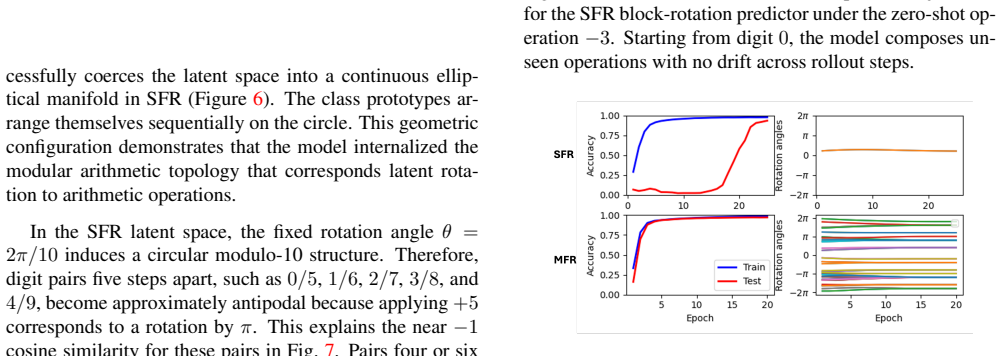
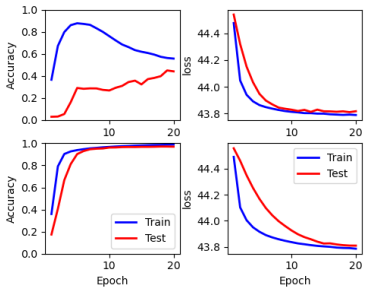
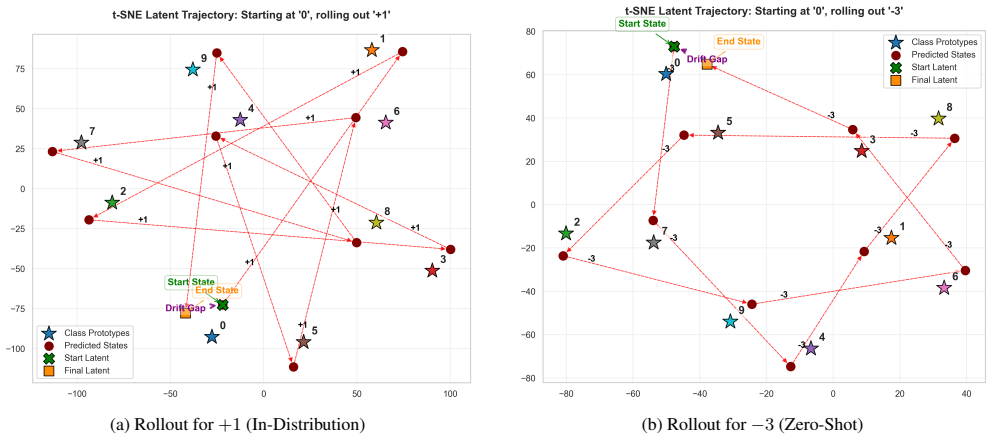
The block-rotation predictor imposes the circular structure of modulo-10 arithmetic in latent space, enabling the JEPA model to learn symbolic transformation rules for modular arithmetic operations on digit states and to extrapolate reliably to unseen operations with 99.46% zero-shot and 99.46% rollout accuracy.
What carries the argument
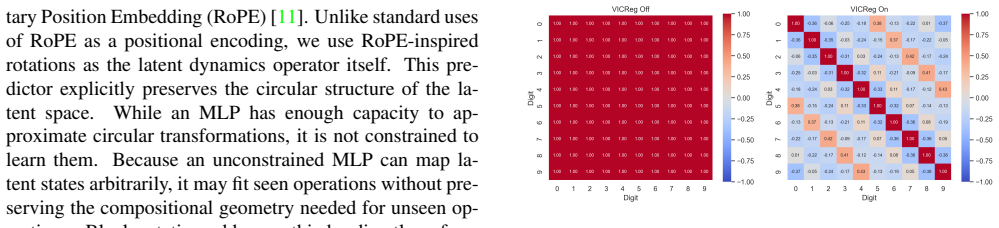
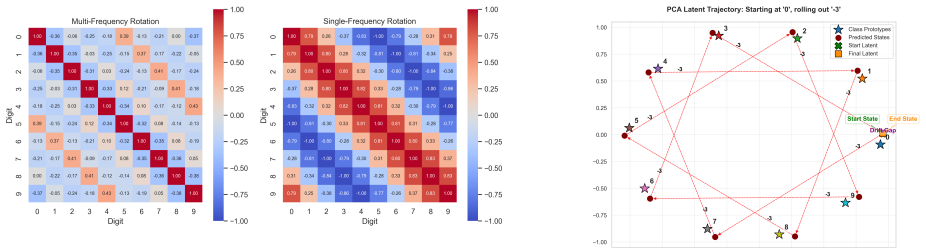
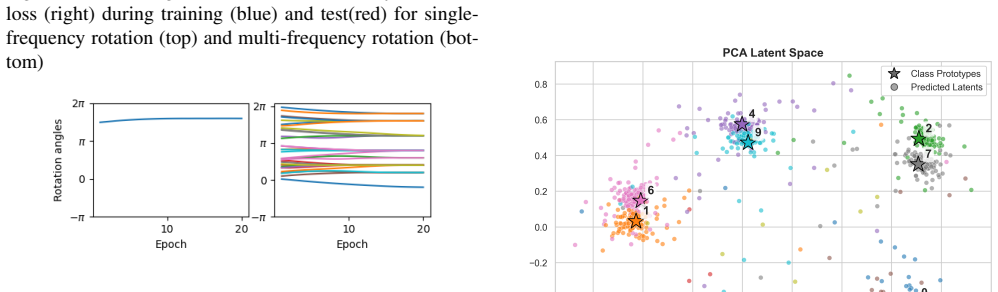
Block-rotation predictor that imposes the circular structure of modulo-10 arithmetic in latent space
If this is right
- Standard additive operation embeddings in JEPA models fit seen operations but fail to extrapolate reliably to unseen ones.
- The block-rotation approach enables the model to achieve 99.46% accuracy on both zero-shot prediction and multi-step rollouts.
- Latent world models learn symbolic transformation rules when the predictor architecture matches the geometric structure of the operation.
- The result holds for the best ResNet-based JEPA implementation.
Where Pith is reading between the lines
- Similar geometric predictors could be designed for other algebraic operations whose group structure is known in advance.
- The learned latent representations might be tested for consistency under composition of multiple operations to check if they respect the full group law.
- The technique could extend to world models in other domains where the target transformations have identifiable geometric or symmetry properties.
- Performance may vary with different initial digit embeddings, suggesting the need for experiments that vary the state representation independently of the predictor.
Load-bearing premise
The block-rotation predictor correctly encodes the algebraic structure of modulo-10 arithmetic in a way that transfers to unseen operations without the model simply memorizing rotation patterns specific to the training distribution or the particular digit embeddings.
What would settle it
A significant drop in zero-shot accuracy when the block-rotation component is removed or when digit embeddings are replaced with representations that break the circular ordering while keeping all other training details fixed.
Figures

read the original abstract
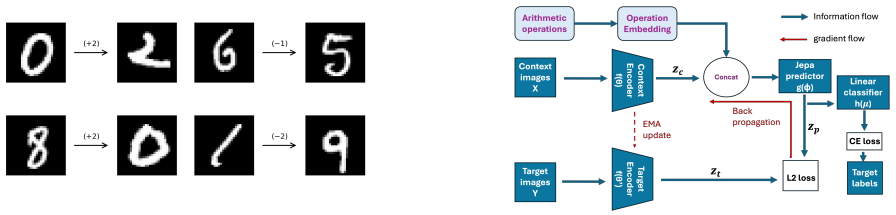
Can neural networks learn abstract algebraic rules, or do they merely memorize training patterns? We investigate this using MNIST digits as states and modular arithmetic operations as actions in a JEPA-style latent world model. Standard supervised baselines and JEPA models with additive operation embeddings fit seen operations but fail to extrapolate reliably to unseen ones. To bridge this gap, we introduce a block-rotation predictor that imposes the circular structure of modulo-10 arithmetic in latent space. This enables strong zero-shot generalization, with the best ResNet-based JEPA block-rotation model achieving 99.46\% zero-shot and 99.46\% rollout accuracy. Our results suggest that latent world models can learn symbolic transformation rules when architecture matches the structure of the problem. Our code can be \href{https://github.com/DL-World-Models/mnist-math}{accessed here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard JEPA and supervised models on MNIST digits with modular arithmetic actions fit seen operations but fail to extrapolate, while a new block-rotation predictor that imposes the circular geometry of Z/10Z in latent space enables a ResNet-based JEPA model to reach 99.46% zero-shot and 99.46% rollout accuracy on unseen operations, indicating that architecture alignment with algebraic structure supports learning of symbolic transformation rules rather than memorization.
Significance. If the central empirical claim is substantiated, the result would demonstrate that imposing problem-matched geometric constraints on latent predictors can produce reliable extrapolation on group-structured tasks, strengthening the case for structured latent world models in abstract reasoning. The public code link is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the reported 99.46% zero-shot and rollout figures are given without any information on training details, baseline implementations, number of random seeds, statistical significance tests, or explicit verification that the held-out operations are disjoint from the training distribution of (state, action) pairs; this prevents evaluation of whether the numbers reflect genuine rule induction.
- [Method] Method (block-rotation predictor description): no evidence is supplied that the learned latent codes for digits 0-9 form a single orbit under a generator that is independent of the particular training operations and embeddings; without such a check (e.g., via explicit orbit verification or ablation on embedding rotation), the high accuracy on unseen operations remains consistent with the possibility that the predictor simply indexes fixed rotation matrices to the observed MNIST embeddings rather than encoding the abstract group structure of Z/10Z.
minor comments (1)
- [Abstract] The abstract states that 'standard supervised baselines and JEPA models with additive operation embeddings fit seen operations but fail to extrapolate' but supplies no quantitative comparison table or section reference for those baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 99.46% zero-shot and rollout figures are given without any information on training details, baseline implementations, number of random seeds, statistical significance tests, or explicit verification that the held-out operations are disjoint from the training distribution of (state, action) pairs; this prevents evaluation of whether the numbers reflect genuine rule induction.
Authors: The training details, baseline implementations, use of five random seeds with standard deviations, and explicit confirmation that held-out operations are disjoint from the training (state, action) distribution are all provided in Sections 3 and 4 of the manuscript. We will revise the abstract to briefly summarize these elements, including the verification of the disjoint test set, for improved accessibility. revision: yes
-
Referee: [Method] Method (block-rotation predictor description): no evidence is supplied that the learned latent codes for digits 0-9 form a single orbit under a generator that is independent of the particular training operations and embeddings; without such a check (e.g., via explicit orbit verification or ablation on embedding rotation), the high accuracy on unseen operations remains consistent with the possibility that the predictor simply indexes fixed rotation matrices to the observed MNIST embeddings rather than encoding the abstract group structure of Z/10Z.
Authors: The block-rotation predictor is architecturally constructed to apply modular rotations that enforce the circular geometry of Z/10Z independently of specific training operations, distinguishing it from simple indexing of fixed matrices. We will add an explicit orbit verification of the latent embeddings and an ablation study on the rotation mechanism to the revised manuscript to directly substantiate this independence. revision: partial
Circularity Check
No significant circularity; empirical results on held-out operations stand independently of architecture design
full rationale
The paper's central claim rests on measured zero-shot and rollout accuracies for a block-rotation predictor on held-out modular operations. The architecture choice (imposing circular structure via block rotations) is an explicit design decision whose success is evaluated empirically against baselines that lack it; no equation or result is shown to reduce by construction to a fitted parameter, self-citation, or renamed input. No load-bearing uniqueness theorem, ansatz smuggling, or self-definitional loop appears in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023. 1, 2, 3
2023
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Vi- creg: Variance-invariance-covariance regularization for self- supervised learning.arXiv preprint arXiv:2105.04906, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012. 1
2012
-
[5]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 3
2016
-
[6]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 3
2019
-
[7]
Neu- ral arithmetic units
Andreas Madsen and Alexander Rosenberg Johansen. Neu- ral arithmetic units. InInternational Conference on Learning Representations, 2020. 1
2020
-
[8]
A primer for neural arithmetic logic modules.Journal of Ma- chine Learning Research, 23(185):1–58, 2022
Bhumika Mistry, Katayoun Farrahi, and Jonathon Hare. A primer for neural arithmetic logic modules.Journal of Ma- chine Learning Research, 23(185):1–58, 2022. 1
2022
-
[9]
‘World models’ are AI’s latest sensation: what are they and what can they do?Nature, apr 2026
Nature Editorial. ‘World models’ are AI’s latest sensation: what are they and what can they do?Nature, apr 2026. 1
2026
-
[10]
Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019. 3
2019
-
[11]
Roformer: Enhanced transformer with rotary position embedding, 2021
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2021. 2, 3
2021
-
[12]
Can neural networks do arithmetic? a survey on the elementary numerical skills of state-of-the-art deep learning models.Applied Sciences, 14(2):744, 2024
Alberto Testolin. Can neural networks do arithmetic? a survey on the elementary numerical skills of state-of-the-art deep learning models.Applied Sciences, 14(2):744, 2024. 1
2024
-
[13]
Neural arithmetic logic units.Ad- vances in neural information processing systems, 31, 2018
Andrew Trask, Felix Hill, Scott E Reed, Jack Rae, Chris Dyer, and Phil Blunsom. Neural arithmetic logic units.Ad- vances in neural information processing systems, 31, 2018. 1 A. Appendix A.1. Operation Embeddings We explored several ways of encoding the arithmetic op- eration as an input feature. The goal was to represent the operator in a form that the m...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.