When Symptoms Are Not Enough: Evidence-Weighting Patterns in Large Language Model Psychiatric Screening
Pith reviewed 2026-06-30 16:35 UTC · model grok-4.3
The pith
Large language models discount explicit psychiatric symptoms when patient narratives include preserved functioning or protective context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
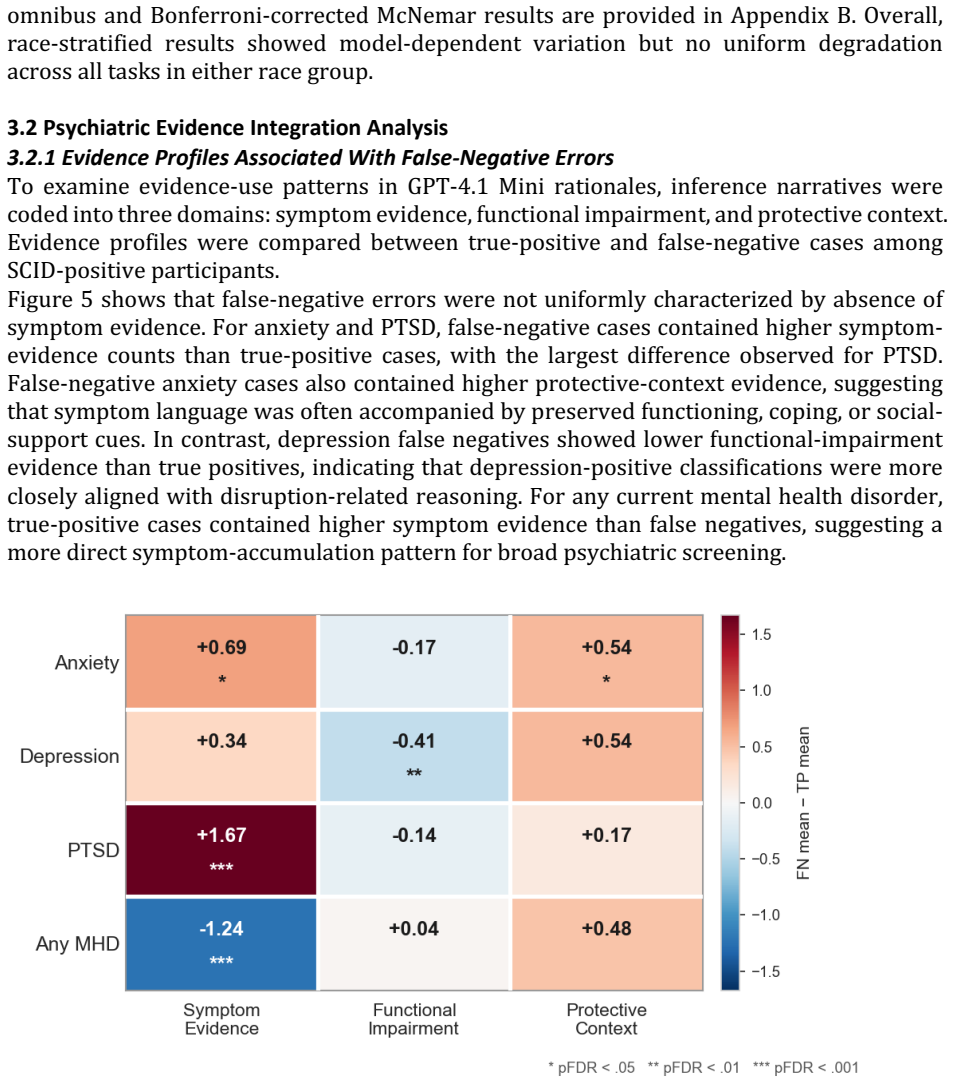
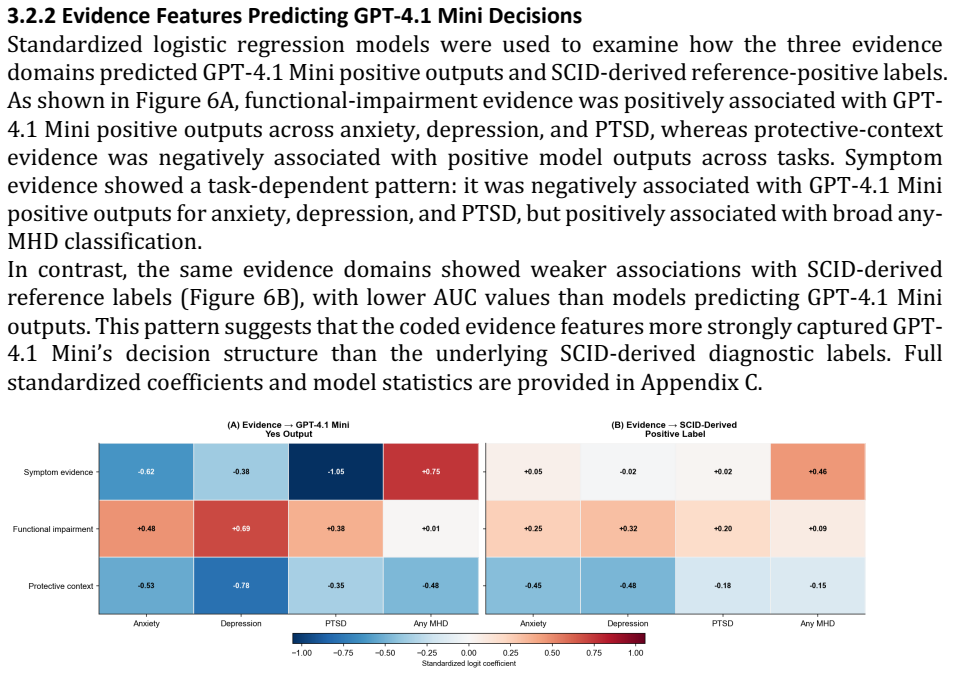
On the SCID-anchored benchmark, LLMs produce false-negative classifications for anxiety and PTSD that contain explicit symptom evidence yet are accompanied by preserved functioning, coping ability, or social support; functional-impairment evidence shifts outputs toward positive labels while protective-context evidence shifts outputs away from them.
What carries the argument
Differential weighting of symptom, functional-impairment, and protective-context cues extracted from interview transcripts during zero-shot LLM classification.
If this is right
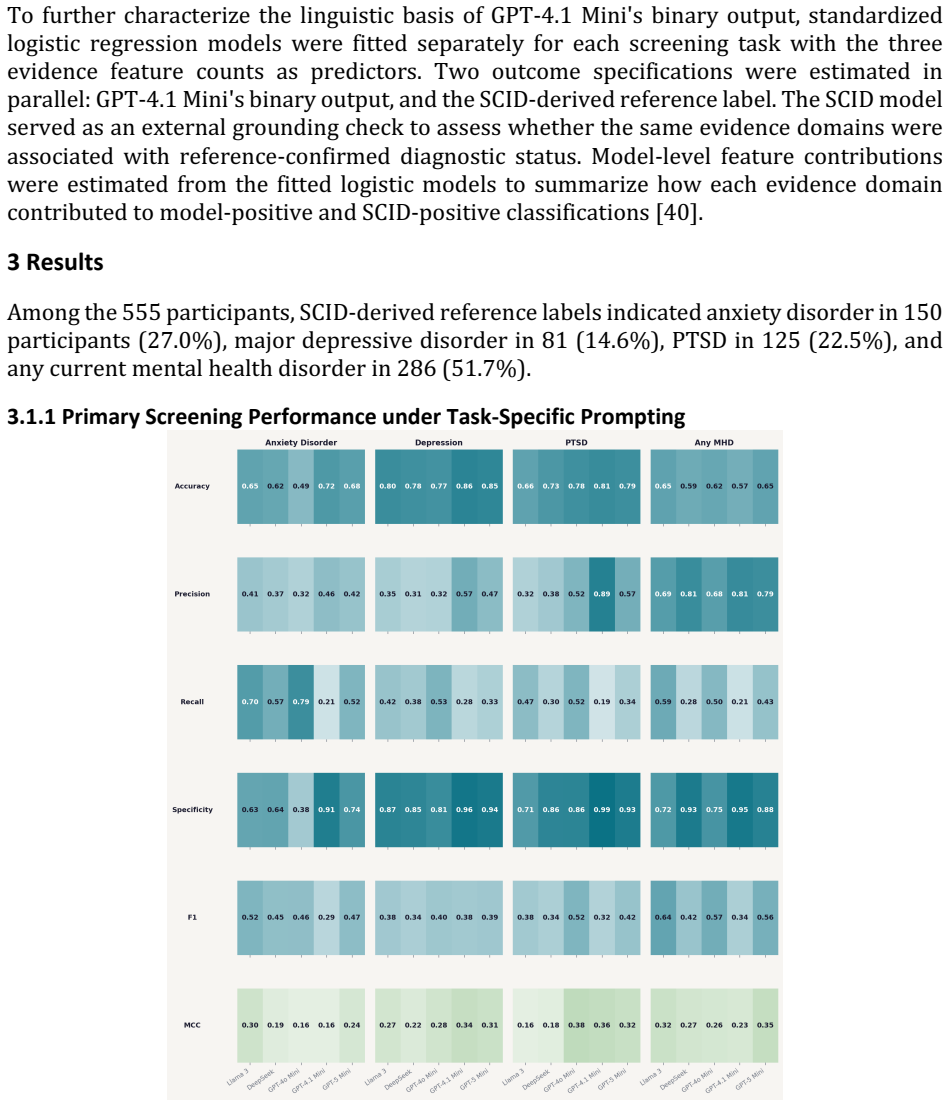
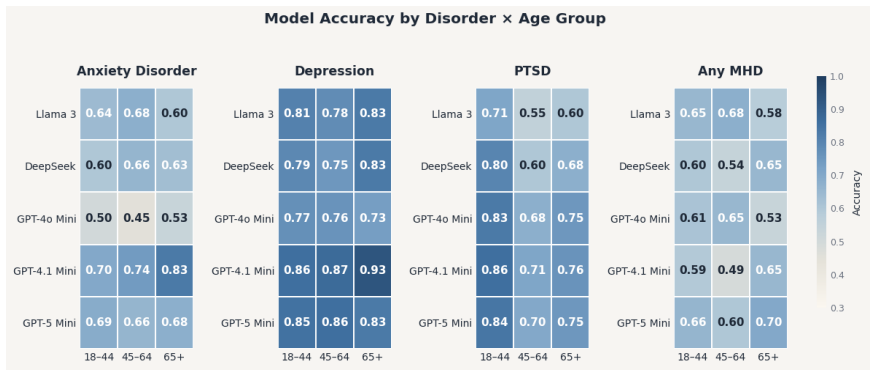
- Accuracy varies by disorder and model, with GPT-4.1 Mini and GPT-5 Mini showing the most consistent results across tasks.
- False-negative errors in anxiety and PTSD often contain explicit symptoms that are discounted in the presence of preserved functioning or support.
- Functional-impairment evidence reliably increases positive classifications while protective-context evidence decreases them.
- Subgroup accuracy differs modestly by sex for depression and shows non-uniform variation by race.
Where Pith is reading between the lines
- Prompt engineering or fine-tuning that explicitly instructs models to prioritize symptom evidence over context may reduce the observed discounting pattern.
- The same evidence-weighting bias could appear in other narrative-based diagnostic tasks such as medical or legal risk assessment.
- Validation studies would need to test whether human clinicians apply the same discounting when given identical transcripts.
Load-bearing premise
The SCID reference labels are an accurate gold standard and the manual identification of symptom, impairment, and protective evidence in the transcripts is complete and unbiased.
What would settle it
A direct comparison in which trained clinicians independently classify the same 555 transcripts while blinded to model outputs, then tally how often they assign a disorder when only protective-context evidence is added to symptom evidence.
Figures
read the original abstract
As demand for mental health care outpaces clinician-delivered assessment, scalable screening tools are increasingly needed. Large language models (LLMs) may identify psychiatric risk from patient narratives, but their reliability across diagnoses, demographic subgroups, and evidence-use patterns remains uncertain. We introduce a SCID-anchored benchmark of 555 semi-structured experiential interviews paired with diagnostic reference labels for anxiety disorder, major depressive disorder, post-traumatic stress disorder, and any current mental health disorder. Using zero-shot task-specific prompting, we evaluated five state-of-the-art LLMs and examined whether false-negative errors reflected missed psychiatric evidence or differential weighting of symptom, functional-impairment, and protective-context cues. Performance varied across tasks and models, with accuracy ranging from 0.49 to 0.86 and Matthews correlation coefficients from 0.16 to 0.38. GPT-4.1 Mini and GPT-5 Mini showed the most consistent disorder-specific accuracy. Subgroup analyses found higher depression-classification accuracy among male than female participants, no consistent age-related pattern, and modest non-uniform variation across race strata. Evidence-integration analyses showed that false-negative anxiety and PTSD classifications often contained explicit symptom evidence but were accompanied by preserved functioning, coping ability, or social support. Functional-impairment evidence shifted model outputs toward positive classifications, whereas protective-context evidence shifted outputs away. These findings suggest that LLMs may support scalable psychiatric screening, but their tendency to discount symptom evidence in the presence of preserved functioning or protective context requires careful validation before clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark consisting of 555 SCID-anchored semi-structured experiential interviews with diagnostic reference labels for anxiety disorder, MDD, PTSD, and any current mental health disorder. It evaluates five LLMs via zero-shot task-specific prompting, reports accuracy (0.49–0.86) and MCC (0.16–0.38) across tasks and models, conducts subgroup analyses by gender, age, and race, and analyzes evidence-integration patterns, concluding that false-negative classifications frequently occur when explicit symptom evidence is accompanied by preserved functioning or protective context, which shifts model outputs negative.
Significance. If the central claims hold after addressing annotation reliability, the work offers a useful empirical measurement of how LLMs differentially weight symptom, impairment, and protective-context evidence in psychiatric screening tasks. The SCID-anchored benchmark itself is a concrete contribution that could support future reproducible studies in this area. The subgroup and error-pattern analyses provide falsifiable observations about model behavior that are directly testable on the released data.
major comments (2)
- [Evidence-integration analyses] The central claim that LLMs discount symptom evidence in the presence of preserved functioning or protective context rests on the manual classification of evidence types within the 555 transcripts (described in the evidence-integration analyses). No inter-annotator agreement statistics, annotation protocol, segmentation procedure, or validation of the evidence codes against SCID items are reported; without these, shifts in model output cannot be confidently attributed to LLM evidence-weighting rather than annotation artifacts.
- [Results] Performance metrics (accuracy 0.49–0.86, MCC 0.16–0.38) and subgroup differences are presented in the abstract and results without accompanying statistical tests, confidence intervals, or exact prompt text; this omission is load-bearing for the claim that GPT-4.1 Mini and GPT-5 Mini are most consistent and for the reported demographic patterns.
minor comments (1)
- [Abstract] The abstract refers to 'five state-of-the-art LLMs' without naming them; the methods section should list the exact models and versions evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating where revisions have been made.
read point-by-point responses
-
Referee: [Evidence-integration analyses] The central claim that LLMs discount symptom evidence in the presence of preserved functioning or protective context rests on the manual classification of evidence types within the 555 transcripts (described in the evidence-integration analyses). No inter-annotator agreement statistics, annotation protocol, segmentation procedure, or validation of the evidence codes against SCID items are reported; without these, shifts in model output cannot be confidently attributed to LLM evidence-weighting rather than annotation artifacts.
Authors: We agree that fuller documentation of the evidence classification is needed. The revised manuscript now includes an expanded Methods subsection detailing the annotation protocol, the segmentation rules applied to transcripts, and the mapping of evidence codes to specific SCID items. Annotations were performed by one trained clinical rater; inter-annotator agreement statistics are therefore unavailable and have been noted as a limitation. The full annotation guidelines have been added as supplementary material. revision: partial
-
Referee: [Results] Performance metrics (accuracy 0.49–0.86, MCC 0.16–0.38) and subgroup differences are presented in the abstract and results without accompanying statistical tests, confidence intervals, or exact prompt text; this omission is load-bearing for the claim that GPT-4.1 Mini and GPT-5 Mini are most consistent and for the reported demographic patterns.
Authors: We have revised the Results section and supplementary materials to include bootstrap-derived 95% confidence intervals for all accuracy and MCC values, chi-squared tests (with FDR correction) for the reported subgroup differences, and the complete zero-shot prompt templates. These additions support the consistency claims without changing the original numerical findings or interpretations. revision: yes
Circularity Check
No circularity; direct empirical measurement against external labels
full rationale
The paper reports an empirical evaluation of LLM outputs on 555 fixed transcripts against SCID-derived reference labels, with post-hoc manual categorization of symptom/impairment/protective evidence. No equations, fitted parameters, or derivations are present. No self-citations are used to justify uniqueness theorems or ansatzes. The central claims rest on direct comparison and observation rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SCID provides accurate diagnostic reference labels for the conditions studied.
Reference graph
Works this paper leans on
-
[1]
Gupta GK, Singh A, Manikandan SV, Ehtesham A. Digital diagnostics: the potential of large Language models in recognizing symptoms of common illnesses. AI. 2025;6(1):13. 16. Ciharova M, Amarti K, van Breda W, et al. Use of Machine Learning Algorithms Based on Text, Audio, and Video Data in the Prediction of Anxiety and Posttraumatic Stress in General and C...
-
[2]
McNemar Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika. 1947;12(2):153-157. doi:10.1007/BF02295996 29. Kessler RC, Berglund P, Demler O, Jin R, Merikangas KR, Walters EE. Lifetime Prevalence and Age-of-Onset Distributions of DSM-IV Disorders in the National Comorbidity Survey Replication. Arch ...
-
[3]
Benjamini Y, Hochberg Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J R Stat Soc Ser B Methodol. 1995;57(1):289-300. doi:10.1111/j.2517-6161.1995.tb02031.x 40. Lundberg SM, Lee SI. A Unified Approach to Interpreting Model Predictions. 41. Xu Y, Fang Z, Lin W, et al. Evaluation of large language models on me...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.