"I've Seen How This Goes": Characterizing Diversity via Progressive Conditional Surprise
Pith reviewed 2026-06-28 14:49 UTC · model grok-4.3
The pith
A base model's token log-probabilities across random in-context permutations yield a diversity score that tracks human judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
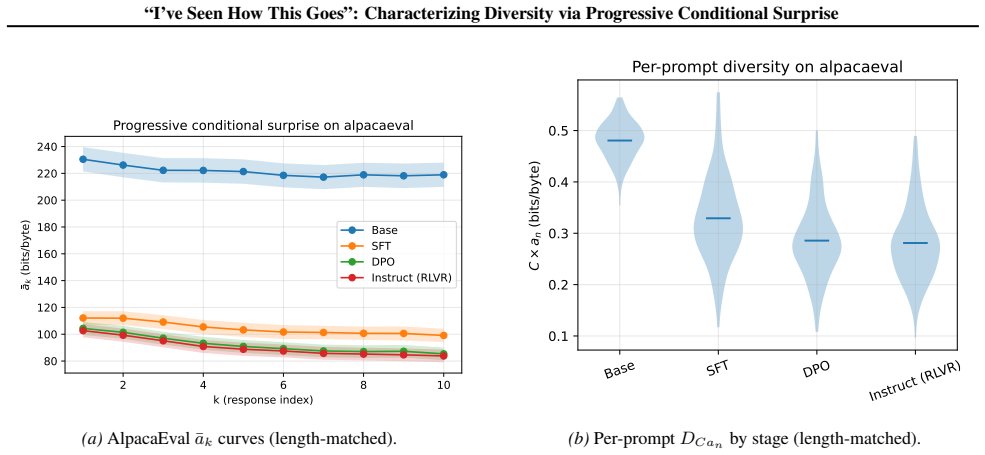
Diversity is quantified as the progressive conditional surprise D_Ca_n = C × a_n extracted from a base model's per-token log-probabilities when responses are presented in random order within an in-context prompt; the metric is computed in one forward pass per permutation, needs no external data or trained components, and achieves 0.846 OCA on the McDiv prompt_gen set while detecting monotonic diversity loss across the base-to-RLVR pipeline on OLMo-2-7B.
What carries the argument
Progressive conditional surprise: the successive reduction in a base model's per-token log-probability when each new response is appended after the preceding ones presented in random order.
If this is right
- The same pipeline scores both AI-generated and human-written response sets without modification.
- D_Ca_n registers a monotonic drop in diversity across the base, SFT, DPO, and RLVR stages of post-training.
- The metric requires only a single forward pass per permutation on the base model already in use.
- No embedding model, reference corpus, or task-specific training is needed to obtain the score.
Where Pith is reading between the lines
- The method could be inserted into training loops to monitor diversity loss in real time using the model being trained.
- It offers a way to compare decoding strategies or temperature settings on any prompt without additional infrastructure.
- Because the score is prompt-conditioned, it may surface prompt-specific notions of diversity that global embedding metrics miss.
Load-bearing premise
The progressive conditional surprise extracted from a base model's in-context permutations accurately captures the human notion of diversity that the McDiv benchmark measures.
What would settle it
Collect new human diversity ratings on a fresh set of response collections where the Decan metric and the existing McDiv labels disagree, then test whether the metric's ranking still aligns with the new human judgments.
Figures














read the original abstract
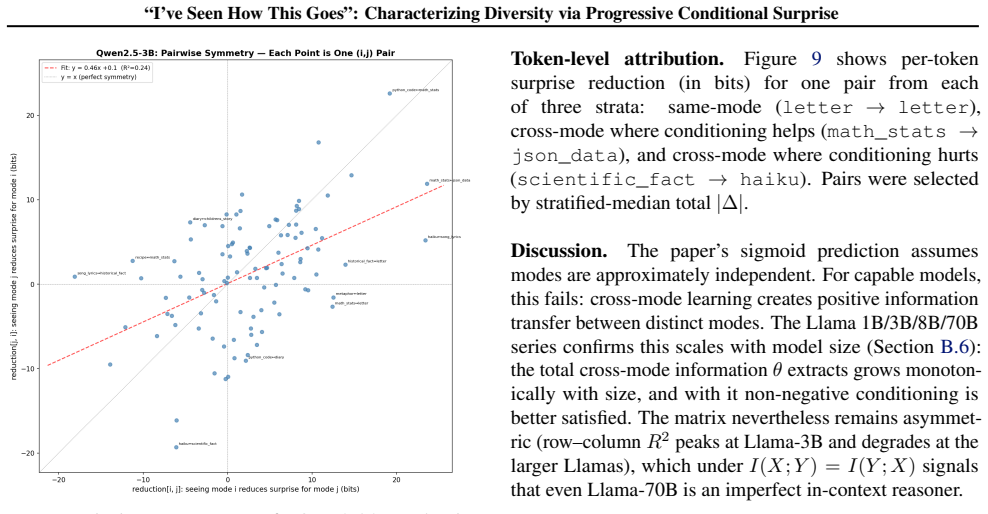
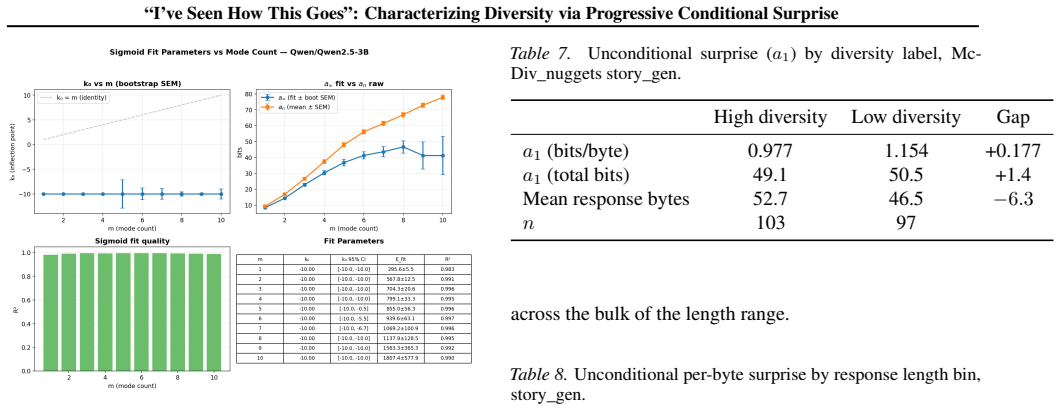
Measuring the diversity of creative outputs is central to evaluating post-training mode collapse, comparing decoding strategies, and quantifying creative behavior in both AI and human writing. We propose a new approach to measuring diversity using in-context learning, of which the ``Decan'' metric, $D_{Ca_n} = C \times a_n$, is the working instance we evaluate: a per-byte score read off the per-token log-probabilities of a base model $\theta$ in a \emph{single forward pass} per permutation, with no embedding model, no reference corpus, and no human labels. This approach is grounded in information theory, makes use of language model in-context learning to detect a wide range of similarities between any number of inputs, and obviates the need to train a special-purpose model. The same pipeline scores AI samples and human-written response sets, with diversity treated as a property of (responses, prompt, scoring model). On Tevet and Berant's human-grounded McDiv benchmark, $D_{Ca_n}$ reaches OCA 0.846 on the McDiv prompt\_gen set where it performs best, behind the strongest neural baseline reported in Tevet and Berant (SentBERT, 0.897). On the OLMo-2-7B post-training pipeline, $D_{Ca_n}$ drops monotonically across the base $\to$ SFT $\to$ DPO $\to$ RLVR stages, detecting the type of diversity loss that creative-writing applications care about.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Decan metric D_{Ca_n} = C × a_n, a reference-free diversity measure derived from progressive conditional surprise in a base model's per-token log-probabilities under in-context permutations of responses (single forward pass per permutation). It reports an OCA of 0.846 on the McDiv prompt_gen set (behind SentBERT at 0.897) as evidence of alignment with human-grounded diversity judgments, and shows that the metric decreases monotonically across the base → SFT → DPO → RLVR stages of the OLMo-2-7B pipeline, claiming to detect post-training diversity loss relevant to creative applications.
Significance. If the metric's validity holds after addressing the noted gaps, the approach would offer a practical, training-free, embedding-free method for quantifying diversity that applies uniformly to AI and human outputs. Its information-theoretic grounding and use of ICL for detecting similarities across arbitrary numbers of items could make it a lightweight alternative for post-training evaluation and decoding comparisons, particularly where mode collapse in creative tasks is a concern.
major comments (3)
- [Abstract] Abstract: The metric is defined as D_{Ca_n} = C × a_n with a_n extracted from per-token log-probabilities, but no derivation of a_n, explicit definition of the scaling factor C, error analysis, or exclusion rules are supplied. This is load-bearing for the central claim that the construction is information-theoretic and isolates diversity.
- [Abstract] McDiv benchmark evaluation (prompt_gen set): The OCA of 0.846 is equated with validity for human notions of diversity, yet the manuscript provides no ablation demonstrating that the progressive conditioning term a_n remains stable when response length, lexical overlap, or surface-form similarity is controlled. Without such controls, it is unclear whether the score reflects semantic/creative variety or model-specific predictability artifacts.
- [Abstract] OLMo-2-7B post-training pipeline: The monotonic drop across stages is presented as detecting the relevant form of diversity loss, but this conclusion rests on the unverified assumption that the base-model permutation pipeline isolates diversity independently of ordering bias or non-diversity factors; the single-forward-pass design is described but not tested for these confounds.
minor comments (1)
- [Abstract] The abstract refers to 'per-byte score' but the metric is described in terms of per-token log-probabilities; clarify the normalization throughout.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for major revision. We respond point-by-point to the major comments below, indicating where we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The metric is defined as D_{Ca_n} = C × a_n with a_n extracted from per-token log-probabilities, but no derivation of a_n, explicit definition of the scaling factor C, error analysis, or exclusion rules are supplied. This is load-bearing for the central claim that the construction is information-theoretic and isolates diversity.
Authors: The manuscript's Section 3 derives a_n as the slope coefficient obtained by regressing the cumulative conditional log-probabilities (under progressive in-context permutations) against the number of conditioning responses; this follows directly from the chain rule applied to conditional entropy. C is the explicit normalization constant converting the slope to a per-byte score, given in Equation (2). Error analysis for the linear fit and exclusion rules for degenerate cases (identical responses or empty sets) appear in Sections 3.2 and 4.3. We agree the abstract is overly terse on these foundational elements and will revise it to include a concise parenthetical definition of a_n together with a reference to the information-theoretic grounding. revision: yes
-
Referee: [Abstract] McDiv benchmark evaluation (prompt_gen set): The OCA of 0.846 is equated with validity for human notions of diversity, yet the manuscript provides no ablation demonstrating that the progressive conditioning term a_n remains stable when response length, lexical overlap, or surface-form similarity is controlled. Without such controls, it is unclear whether the score reflects semantic/creative variety or model-specific predictability artifacts.
Authors: The McDiv evaluation reports correlation with human diversity judgments, but we did not include explicit ablations that hold response length, lexical overlap, or surface-form similarity fixed while varying semantic content. We will add such controlled ablations in the revised manuscript to isolate the contribution of the progressive conditioning term a_n and to rule out predictability artifacts. revision: yes
-
Referee: [Abstract] OLMo-2-7B post-training pipeline: The monotonic drop across stages is presented as detecting the relevant form of diversity loss, but this conclusion rests on the unverified assumption that the base-model permutation pipeline isolates diversity independently of ordering bias or non-diversity factors; the single-forward-pass design is described but not tested for these confounds.
Authors: The design averages a_n across multiple random permutations to reduce ordering effects, with each permutation evaluated in a single forward pass. Nevertheless, we have not reported dedicated experiments quantifying residual ordering bias or other potential confounds. We will add these targeted sensitivity analyses in the revision to confirm that the observed monotonic decline is attributable to diversity reduction rather than pipeline artifacts. revision: yes
Circularity Check
No significant circularity; metric defined directly from log-probabilities and validated externally
full rationale
The paper defines the Decan metric D_Ca_n = C × a_n explicitly as a per-byte score extracted from per-token log-probabilities of a base model θ under in-context permutations in a single forward pass, presented as grounded in information theory with no embedding model or human labels required. It reports external validation on Tevet and Berant's McDiv benchmark (OCA 0.846 on prompt_gen, vs. SentBERT 0.897) and observational results on OLMo-2-7B stages showing monotonic drop. No quoted equations or text indicate that C or a_n are fitted to the McDiv labels, that the metric reduces to its own evaluation targets by construction, or that any uniqueness theorem or ansatz is smuggled via self-citation. The derivation chain remains self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- C
axioms (1)
- domain assumption Language-model in-context learning on response permutations can detect a wide range of similarities relevant to diversity
Reference graph
Works this paper leans on
-
[1]
Berglund, L., Tong, M., Kaufmann, M., Balesni, M., Stickland, A. C., Korbak, T., and Evans, O. The reversal curse: Llms trained on "a is b" fail to learn "b is a", 2023. URL http://arxiv.org/abs/2309.12288v4
arXiv 2023
-
[2]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, ...
Pith/arXiv arXiv 2020
-
[3]
Crutchfield, J. P. and Feldman, D. P. Regularities unseen, randomness observed: Levels of entropy convergence. Chaos: An Interdisciplinary Journal of Nonlinear Science, 13 0 (1): 0 25–54, March 2003. ISSN 1089-7682. doi:10.1063/1.1530990. URL http://dx.doi.org/10.1063/1.1530990
-
[4]
Replicability analysis for natural language processing: Testing significance with multiple datasets
Dror, R., Baumer, G., Bogomolov, M., and Reichart, R. Replicability analysis for natural language processing: Testing significance with multiple datasets. Transactions of the Association for Computational Linguistics, 5: 0 471--486, 2017. doi:10.1162/tacl_a_00074. URL https://aclanthology.org/Q17-1033/
-
[5]
The hitchhiker ' s guide to testing statistical significance in natural language processing
Dror, R., Baumer, G., Shlomov, S., and Reichart, R. The hitchhiker ' s guide to testing statistical significance in natural language processing. In Gurevych, I. and Miyao, Y. (eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1383--1392, Melbourne, Australia, July 2018. Association...
-
[6]
Du, W. and Black, A. W. Boosting dialog response generation. In Korhonen, A., Traum, D., and M \`a rquez, L. (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 38--43, Florence, Italy, July 2019. Association for Computational Linguistics. doi:10.18653/v1/P19-1005. URL https://aclanthology.org/P19-1005/
-
[7]
Dubois, Y., Li, X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P., and Hashimoto, T. B. Alpacafarm: A simulation framework for methods that learn from human feedback, 2023. URL http://arxiv.org/abs/2305.14387v4
arXiv 2023
-
[8]
The pile: An 800gb dataset of diverse text for language modeling, 2020
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling, 2020. URL http://arxiv.org/abs/2101.00027v1
Pith/arXiv arXiv 2020
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux...
Pith/arXiv arXiv 2024
-
[10]
Benchmarking linguistic diversity of large language models, 2024
Guo, Y., Shang, G., and Clavel, C. Benchmarking linguistic diversity of large language models, 2024. URL http://arxiv.org/abs/2412.10271v2
arXiv 2024
-
[11]
Understanding the effects of rlhf on llm generalisation and diversity, 2023
Kirk, R., Mediratta, I., Nalmpantis, C., Luketina, J., Hambro, E., Grefenstette, E., and Raileanu, R. Understanding the effects of rlhf on llm generalisation and diversity, 2023. URL http://arxiv.org/abs/2310.06452v3
Pith/arXiv arXiv 2023
-
[12]
A diversity-promoting objective function for neural conversation models
Li, J., Galley, M., Brockett, C., Gao, J., and Dolan, B. A diversity-promoting objective function for neural conversation models. In Knight, K., Nenkova, A., and Rambow, O. (eds.), Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies , pp.\ 110--119, San Diego, Cali...
-
[13]
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Meta AI . Llama 3.2: Revolutionizing edge AI and vision with open, customizable models. Meta AI Blog, September 2024. URL https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
2024
-
[14]
W., Liu, J., Malik, S., Merrill, W., Miranda, L
OLMo, T., Walsh, P., Soldaini, L., Groeneveld, D., Lo, K., Arora, S., Bhagia, A., Gu, Y., Huang, S., Jordan, M., Lambert, N., Schwenk, D., Tafjord, O., Anderson, T., Atkinson, D., Brahman, F., Clark, C., Dasigi, P., Dziri, N., Ettinger, A., Guerquin, M., Heineman, D., Ivison, H., Koh, P. W., Liu, J., Malik, S., Merrill, W., Miranda, L. J. V., Morrison, J....
Pith/arXiv arXiv 2024
- [15]
-
[16]
Is temperature the creativity parameter of large language models?, 2024
Peeperkorn, M., Kouwenhoven, T., Brown, D., and Jordanous, A. Is temperature the creativity parameter of large language models?, 2024. URL http://arxiv.org/abs/2405.00492v1
arXiv 2024
-
[17]
Qiu, T., Ismail, A. H., He, Z., and Feng, S. Self-improvement as coherence optimization: A theoretical account, 2026. URL http://arxiv.org/abs/2601.13566v1
arXiv 2026
-
[18]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019. URL https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
2019
-
[19]
Reimers, N. and Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks, 2019. URL http://arxiv.org/abs/1908.10084v1
Pith/arXiv arXiv 2019
-
[20]
Tevet, G. and Berant, J. Evaluating the evaluation of diversity in natural language generation. In Merlo, P., Tiedemann, J., and Tsarfaty, R. (eds.), Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp.\ 326--346, Online, April 2021. Association for Computational Linguistics. doi:10....
-
[21]
N., Liu, L., Gottlieb, E., Lu, Y., Cho, K., Wu, J., Fei-Fei, L., Wang, L., Choi, Y., and Li, M
Wang, Z., Wang, K., Wang, Q., Zhang, P., Li, L., Yang, Z., Jin, X., Yu, K., Nguyen, M. N., Liu, L., Gottlieb, E., Lu, Y., Cho, K., Wu, J., Fei-Fei, L., Wang, L., Choi, Y., and Li, M. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning, 2025. URL http://arxiv.org/abs/2504.20073v2
Pith/arXiv arXiv 2025
-
[22]
Unsupervised elicitation of language models, 2025
Wen, J., Ankner, Z., Somani, A., Hase, P., Marks, S., Goldman-Wetzler, J., Petrini, L., Sleight, H., Burns, C., He, H., Feng, S., Perez, E., and Leike, J. Unsupervised elicitation of language models, 2025. URL http://arxiv.org/abs/2506.10139v2
arXiv 2025
-
[23]
Qwen2.5 technical report, 2024
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, Y., Li...
Pith/arXiv arXiv 2024
-
[24]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
Pith/arXiv arXiv 2025
-
[25]
Zhang, J., Yu, S., Chong, D., Sicilia, A., Tomz, M. R., Manning, C. D., and Shi, W. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity, 2025 a . URL http://arxiv.org/abs/2510.01171v3
arXiv 2025
-
[26]
Evaluating the evaluation of diversity in commonsense generation, 2025 b
Zhang, T., Peng, B., and Bollegala, D. Evaluating the evaluation of diversity in commonsense generation, 2025 b . URL http://arxiv.org/abs/2506.00514v1
arXiv 2025
-
[27]
Zhang, Y., Galley, M., Gao, J., Gan, Z., Li, X., Brockett, C., and Dolan, B. Generating informative and diverse conversational responses via adversarial information maximization, 2018. URL http://arxiv.org/abs/1809.05972v5
Pith/arXiv arXiv 2018
-
[28]
Noveltybench: Evaluating language models for humanlike diversity, 2025 c
Zhang, Y., Diddee, H., Holm, S., Liu, H., Liu, X., Samuel, V., Wang, B., and Ippolito, D. Noveltybench: Evaluating language models for humanlike diversity, 2025 c . URL http://arxiv.org/abs/2504.05228v4
arXiv 2025
-
[29]
Texygen: A benchmarking platform for text generation models, 2018
Zhu, Y., Lu, S., Zheng, L., Guo, J., Zhang, W., Wang, J., and Yu, Y. Texygen: A benchmarking platform for text generation models, 2018. URL http://arxiv.org/abs/1802.01886v1
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.