Towards Spec Learning: Inference-Time Alignment from Preference Pairs
Pith reviewed 2026-06-30 10:14 UTC · model grok-4.3
The pith
Preference pairs compile into natural-language specifications that steer LLMs at inference time and often outperform DPO in dense domains
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Spec learning compiles a brief user instruction and a small set of preference judgments into natural-language specifications. When these specifications condition an LLM at inference time, the generated responses often outperform those from direct preference optimization on specialized-domain datasets whose preference signal is dense, while requiring no updates to model parameters.
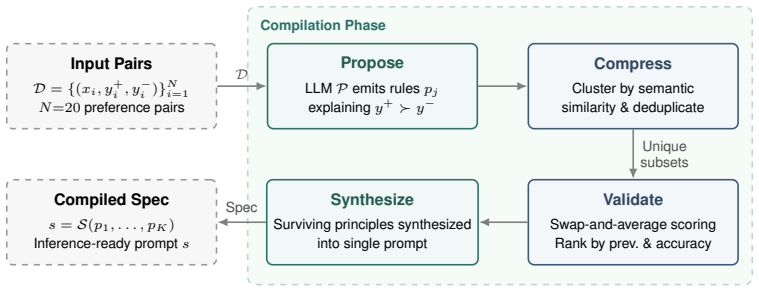
What carries the argument
The compilation process that converts a user instruction and preference pairs into natural-language specifications for inference-time conditioning of LLMs.
Load-bearing premise
That a small set of preference judgments can be reliably compiled by the proposed process into natural-language specifications that capture the intended preference signal and generalize to new inputs in the target domain.
What would settle it
A head-to-head evaluation on a specialized domain dataset in which human raters prefer DPO outputs over those conditioned on the compiled specifications.
Figures




read the original abstract
Steering a large language model (LLM) toward a desired behavior typically relies on an iterative process of hand-crafting a prompt based on a careful inspection of the model's responses. This is an involved, brittle, and error-prone process. Preference-based fine-tuning is a more rigorous but often prohibitively expensive solution. We propose spec learning, a framework that relies on a brief user instruction and a small set of preference judgments. These are compiled into specifications in the form of natural-language prompts for an LLM. Specifications condition LLMs at inference time, and no parameter updates to the underlying models are required. We show that the responses generated based on the compiled specifications often outperform direct preference optimization (DPO) on datasets from specialized domains whose preference signal is dense. Unlike opaque weight updates, the resulting specifications are human-readable and double as interpretable and transparent written embodiments of the preference signal that produced them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'spec learning,' a framework that takes a brief user instruction plus a small set of preference judgments, compiles them into natural-language specifications (prompts), and conditions an LLM with those specifications at inference time. No parameter updates are performed. The central empirical claim is that the resulting responses often outperform direct preference optimization (DPO) on specialized-domain datasets whose preference signal is dense; the specifications are additionally presented as human-readable embodiments of the preference signal.
Significance. If the central claim holds under rigorous controls, the work would be significant for offering an inference-time, training-free alternative to preference fine-tuning that is both cheaper and more interpretable. The emphasis on readable natural-language specifications directly addresses the opacity of weight-based methods. Credit is given for targeting domains with dense preference signals and for avoiding any parameter updates.
major comments (2)
- [§4] §4 (Experiments): the headline claim that compiled specifications outperform DPO rests on the assumption that a small preference set can be compiled into specifications that capture the target signal and generalize to unseen prompts in the same domain. No ablation on the number of preference pairs, no held-out prompt evaluation within the domain, and no comparison against human-edited specifications are reported; these omissions are load-bearing for the outperformance result.
- [§3] §3 (Method): the compilation procedure that turns preference pairs into natural-language specifications is described at a high level only. Without pseudocode, exact prompting templates, or verification that the process is fully automated (i.e., no post-editing), it is impossible to determine whether the reported gains are reproducible or depend on unstated human choices.
minor comments (2)
- [Abstract] Abstract: the qualifier 'often outperform' is not quantified (e.g., fraction of datasets or effect-size range); a concrete statement would strengthen the claim.
- [§2] Notation: the term 'specifications' is used both for the compiled prompts and for the underlying preference signal; a short clarifying sentence in §2 would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points on experimental rigor and method reproducibility are well-taken, and we address them point-by-point below with plans for revision.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the headline claim that compiled specifications outperform DPO rests on the assumption that a small preference set can be compiled into specifications that capture the target signal and generalize to unseen prompts in the same domain. No ablation on the number of preference pairs, no held-out prompt evaluation within the domain, and no comparison against human-edited specifications are reported; these omissions are load-bearing for the outperformance result.
Authors: We agree these controls would strengthen the generalization claim. In revision we will add (1) an ablation varying the number of preference pairs, (2) held-out prompt evaluation within each domain, and (3) a limited comparison to human-edited specifications. These additions directly address the load-bearing concerns while preserving the core automated-specification contribution. revision: yes
-
Referee: [§3] §3 (Method): the compilation procedure that turns preference pairs into natural-language specifications is described at a high level only. Without pseudocode, exact prompting templates, or verification that the process is fully automated (i.e., no post-editing), it is impossible to determine whether the reported gains are reproducible or depend on unstated human choices.
Authors: We accept that the current description is insufficient for reproducibility. The revised manuscript will include pseudocode for the full compilation pipeline, the precise prompting templates, and an explicit statement that the procedure runs end-to-end without human post-editing. This will confirm the process is fully automated and replicable from the preference pairs alone. revision: yes
Circularity Check
No derivation chain present; purely empirical framework claim
full rationale
The paper describes a practical framework that takes a user instruction plus preference pairs as input and compiles them into natural-language prompt specifications for inference-time LLM conditioning. The headline result is an empirical observation that the resulting outputs often outperform DPO on specialized-domain datasets. No equations, parameters, uniqueness theorems, or first-principles derivations are referenced in the provided text. The compilation step is presented as an engineering process whose effectiveness is measured by downstream performance rather than asserted by construction or self-citation. Because no load-bearing mathematical step exists that could reduce to its own inputs, the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PromptWizard: Task-Aware Prompt Optimization Framework, October 2024
Eshaan Agarwal, Joykirat Singh, Vivek Dani, Raghav Magazine, Tanuja Ganu, and Akshay Nambi. PromptWizard: Task-Aware Prompt Optimization Framework, October 2024. arXiv:2405.18369 [cs]
-
[2]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, February 2026. arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
distilabel-math-preference-dpo
Argilla. distilabel-math-preference-dpo. Hugging Face Datasets, 2024
2024
-
[4]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences. arXiv preprint arXiv:2310.12036, 2023
-
[5]
Reference-Guided Verdict: LLMs-as-Judges in Automatic Evaluation of Free-Form QA
Sher Badshah and Hassan Sajjad. Reference-Guided Verdict: LLMs-as-Judges in Automatic Evaluation of Free-Form QA
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott 9 Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Benchmarking Foundation Models with Language-Model-as-an-Examiner
Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. Benchmarking Foundation Models with Language-Model-as-an-Examiner
-
[9]
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fernández, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, André F T Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K Surikuchi, Ece Takmaz, and Alberto Testoni. LLMs instead...
2025
-
[10]
Stack exchange paired preferences
Edward Beeching and Leandro von Werra. Stack exchange paired preferences. Hugging Face Datasets, 2023
2023
-
[11]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[12]
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
-
[13]
Humans or LLMs as the Judge? A Study on Judgement Bias
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or LLMs as the Judge? A Study on Judgement Bias. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301–8327, Miami, Florida, USA, 2024. Association for Computational Linguistics
2024
-
[14]
InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models, August 2023
Lichang Chen, Jiuhai Chen, Tom Goldstein, Heng Huang, and Tianyi Zhou. InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models, August 2023. arXiv:2306.03082 [cs]
-
[15]
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling
Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, and Chuchu Fan. PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3859–3920, Miami, Florida, USA, 2024. Association for Computational Linguistics
2024
-
[16]
Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
Jiale Cheng, Xiao Liu, Kehan Zheng, Pei Ke, Hongning Wang, Yuxiao Dong, Jie Tang, and Minlie Huang. Black-Box Prompt Optimization: Aligning Large Language Models without Model Training. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3201–3219, Bangkok, Thailand, 2024. Association f...
2024
-
[17]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, 2023
2023
-
[18]
Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL
Yunseon Choi, Sangmin Bae, Seonghyun Ban, Minchan Jeong, Chuheng Zhang, Lei Song, Li Zhao, Jiang Bian, and Kee-Eung Kim. Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8252–8271, Bangkok, Thail...
2024
-
[19]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[20]
Code vulnerability security DPO
CyberNative. Code vulnerability security DPO. Hugging Face Datasets, 2024
2024
-
[21]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[22]
RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P Xing, and Zhiting Hu. RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning. 2024
2024
-
[23]
Black-box Prompt Learning for Pre-trained Language Models, February 2023
Shizhe Diao, Zhichao Huang, Ruijia Xu, Xuechun Li, Yong Lin, Xiao Zhou, and Tong Zhang. Black-box Prompt Learning for Pre-trained Language Models, February 2023. arXiv:2201.08531 [cs]. 10
-
[24]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
2024
-
[25]
PACE: Improving Prompt with Actor-Critic Editing for Large Language Model
Yihong Dong, Kangcheng Luo, Xue Jiang, Zhi Jin, and Ge Li. PACE: Improving Prompt with Actor-Critic Editing for Large Language Model. InFindings of the Association for Computational Linguistics ACL 2024, pages 7304–7323, Bangkok, Thailand and virtual meeting, 2024. Association for Computational Linguistics
2024
-
[26]
IPO: Interpretable Prompt Optimization for Vision- Language Models
Yingjun Du, Wenfang Sun, and Cees G M Snoek. IPO: Interpretable Prompt Optimization for Vision- Language Models. 2024
2024
-
[27]
Hashimoto
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled AlpacaEval: A simple way to debias automatic evaluators, 2024
2024
-
[28]
Truthy-DPO v0.1
Jon Durbin. Truthy-DPO v0.1. Hugging Face Datasets, 2023
2023
-
[29]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, September 2023. arXiv:2309.16797 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Inverse Constitutional AI: Compressing Preferences into Principles, April 2025
Arduin Findeis, Timo Kaufmann, Eyke Hüllermeier, Samuel Albanie, and Robert Mullins. Inverse Constitutional AI: Compressing Preferences into Principles, April 2025. arXiv:2406.06560 [cs]
-
[32]
Inter- preting LLM-as-a-Judge Policies via Verifiable Global Explanations, October 2025
Jasmina Gajcin, Erik Miehling, Rahul Nair, Elizabeth Daly, Radu Marinescu, and Seshu Tirupathi. Inter- preting LLM-as-a-Judge Policies via Verifiable Global Explanations, October 2025. arXiv:2510.08120 [cs]
-
[33]
Demystifying prompts in language models via perplexity estimation
Hila Gonen, Srini Iyer, Terra Blevins, Noah A Smith, and Luke Zettlemoyer. Demystifying prompts in language models via perplexity estimation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10136–10148, 2023
2023
-
[34]
Gemma 4 31b, 2025
Google DeepMind. Gemma 4 31b, 2025. Hugging Face model card
2025
-
[35]
A survey on LLM-as-a-judge.The Innovation, page 101253, January 2026
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo. A survey on LLM-as-a-judge.The Innovation, page 101253, January 2026
2026
-
[36]
EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers, May 2025. arXiv:2309.08532 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks
Rajarshi Haldar and Julia Hockenmaier. Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks. 2025
2025
-
[38]
CriSPO: Multi-Aspect Critique-Suggestion-guided Automatic Prompt Optimization for Text Generation
Han He, Qianchu Liu, Lei Xu, Chaitanya Shivade, Yi Zhang, Sundararajan Srinivasan, and Katrin Kirchhoff. CriSPO: Multi-Aspect Critique-Suggestion-guided Automatic Prompt Optimization for Text Generation. 2025
2025
-
[39]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model.arXiv preprint arXiv:2403.07691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Bowman, and Omer Levy
Or Honovich, Uri Shaham, Samuel R. Bowman, and Omer Levy. Instruction Induction: From Few Examples to Natural Language Task Descriptions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1935–1952, Toronto, Canada,
1935
-
[42]
Automatic Engineering of Long Prompts
Cho-Jui Hsieh, Si Si, Felix Yu, and Inderjit Dhillon. Automatic Engineering of Long Prompts. InFindings of the Association for Computational Linguistics ACL 2024, pages 10672–10685, Bangkok, Thailand and virtual meeting, 2024. Association for Computational Linguistics
2024
-
[43]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. 11
2022
-
[44]
Think-J: Learning to Think for Generative LLM-as-a-Judge
Hui Huang, Yancheng He, Hongli Zhou, Rui Zhang, Wei Liu, Weixun Wang, Jiaheng Liu, and Wenbo Su. Think-J: Learning to Think for Generative LLM-as-a-Judge
-
[45]
MORL-Prompt: An Empirical Analysis of Multi-Objective Reinforcement Learning for Discrete Prompt Optimization
Yasaman Jafari, Dheeraj Mekala, Rose Yu, and Taylor Berg-Kirkpatrick. MORL-Prompt: An Empirical Analysis of Multi-Objective Reinforcement Learning for Discrete Prompt Optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9878–9889, Miami, Florida, USA,
2024
-
[47]
APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Can Jin. APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking. 2025
2025
-
[48]
Task Facet Learning: A Structured Approach To Prompt Optimization
Gurusha Juneja, Gautam Jajoo, Nagarajan Natarajan, Hua Li, Jian Jiao, and Amit Sharma. Task Facet Learning: A Structured Approach To Prompt Optimization. 2025
2025
- [49]
-
[50]
CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation
Pei Ke, Bosi Wen, Andrew Feng, Xiao Liu, Xuanyu Lei, Jiale Cheng, Shengyuan Wang, Aohan Zeng, Yuxiao Dong, Hongning Wang, Jie Tang, and Minlie Huang. CritiqueLLM: Towards an Informative Critique Generation Model for Evaluation of Large Language Model Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol...
2024
-
[51]
PRewrite: Prompt Rewriting with Reinforcement Learning
Weize Kong, Spurthi Hombaiah, Mingyang Zhang, Qiaozhu Mei, and Michael Bendersky. PRewrite: Prompt Rewriting with Reinforcement Learning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 594–601, Bangkok, Thailand,
-
[52]
Association for Computational Linguistics
-
[53]
CRIT- ICEV AL: Evaluate Large Language Model as Critic
Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, and Xian-Ling Mao. CRIT- ICEV AL: Evaluate Large Language Model as Critic
-
[54]
Are LLM-Judges Robust to Expressions of Uncertainty? Investigating the effect of Epistemic Markers on LLM-based Evaluation
Dongryeol Lee, Yering Hwang, Yongil Kim, Joonsuk Park, and Kyomin Jung. Are LLM-Judges Robust to Expressions of Uncertainty? Investigating the effect of Epistemic Markers on LLM-based Evaluation
-
[55]
Aligning to Thousands of Preferences via System Messages
Seongyun Lee, Sue Hyun Park, Seungone Kim, and Minjoon Seo. Aligning to Thousands of Preferences via System Messages. InAdvances in Neural Information Processing Systems, 2024
2024
-
[56]
Robust Prompt Optimization for Large Language Models Against Distribution Shifts
Moxin Li, Wenjie Wang, Fuli Feng, Yixin Cao, Jizhi Zhang, and Tat-Seng Chua. Robust Prompt Optimization for Large Language Models Against Distribution Shifts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1539–1554, Singapore, 2023. Association for Computational Linguistics
2023
-
[57]
Prompt Optimization with Human Feedback, May 2024
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, and Bryan Kian Hsiang Low. Prompt Optimization with Human Feedback, May 2024. arXiv:2405.17346 [cs]
-
[58]
Xiaoqiang Lin, Zhaoxuan Wu, Zhongxiang Dai, Wenyang Hu, Yao Shu, See-Kiong Ng, Patrick Jaillet, and Bryan Kian Hsiang Low. Use Your INSTINCT: INSTruction optimization for LLMs usIng Neural bandits Coupled with Transformers, June 2024. arXiv:2310.02905 [cs]
-
[59]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 55(9):1–35, 2023
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys, 55(9):1–35, 2023
2023
-
[60]
Language Models as Black- Box Optimizers for Vision-Language Models
Shihong Liu, Samuel Yu, Zhiqiu Lin, Deepak Pathak, and Deva Ramanan. Language Models as Black- Box Optimizers for Vision-Language Models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12687–12697, Seattle, W A, USA, June 2024. IEEE
2024
-
[61]
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning, 2024
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning, 2024
2024
-
[62]
Yilun Liu, Minggui He, Feiyu Yao, Yuhe Ji, Shimin Tao, Jingzhou Du, Duan Li, Jian Gao, Li Zhang, Hao Yang, Boxing Chen, and Osamu Yoshie. Taming Text-to-Image Synthesis for Novices: User-centric Prompt Generation via Multi-turn Guidance, October 2025. arXiv:2408.12910 [cs]
-
[63]
Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vuli´c, Anna Korhonen, and Nigel Collier. Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators, January 2025. arXiv:2403.16950 [cs]. 12
-
[64]
Prompt Optimization via Adversarial In-Context Learning
Do Long, Yiran Zhao, Hannah Brown, Yuxi Xie, James Zhao, Nancy Chen, Kenji Kawaguchi, Michael Shieh, and Junxian He. Prompt Optimization via Adversarial In-Context Learning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7308–7327, Bangkok, Thailand, 2024. Association for Computatio...
2024
-
[65]
FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema
Junru Lu, Siyu An, Min Zhang, and Yulan He. FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema. 2025
2025
-
[66]
Improving Text-to-Image Consistency via Automatic Prompt Optimization, March 2024
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal. Improving Text-to-Image Consistency via Automatic Prompt Optimization, March 2024. arXiv:2403.17804 [cs]
-
[67]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[68]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettle- moyer. Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11048–11064, 2022
2022
-
[69]
M. Jehanzeb Mirza, Mengjie Zhao, Zhuoyuan Mao, Sivan Doveh, Wei Lin, Paul Gavrikov, Michael Dorkenwald, Shiqi Yang, Saurav Jha, Hiromi Wakaki, Yuki Mitsufuji, Horst Possegger, Rogerio Feris, Leonid Karlinsky, and James Glass. GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models, August 2025. arXiv:2410.06154 [cs]
-
[70]
Kimi k2.6, 2026
Moonshot AI. Kimi k2.6, 2026. Hugging Face model card
2026
-
[71]
In-context learning generalizes, but not always robustly: The case of syntax
Aaron Mueller, Albert Webson, Jackson Petty, and Tal Linzen. In-context learning generalizes, but not always robustly: The case of syntax. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4761–4779, 2024
2024
-
[72]
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340–9366, Miami, Florida, USA, 2024. Association for Computat...
2024
-
[73]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
2022
-
[74]
Plum: Prompt Learning using Metaheuristics
Rui Pan, Shuo Xing, Shizhe Diao, Wenhe Sun, Xiang Liu, Kashun Shum, Jipeng Zhang, Renjie Pi, and Tong Zhang. Plum: Prompt Learning using Metaheuristics. 2024
2024
-
[75]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems, 2024
2024
-
[76]
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Savvas Petridis, Benjamin D Wedin, James Wexler, Mahima Pushkarna, Aaron Donsbach, Nitesh Goyal, Carrie J Cai, and Michael Terry. ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles. InProceedings of the 29th International Conference on Intelligent User Interfaces, pages 853–868, Greenville SC USA, Marc...
2024
-
[77]
GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models
Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3845–3864, Dubrovnik, Croatia, 2023. Association for Computational Linguistics
2023
-
[78]
Gradient Descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7957–7968, Singapore, 2023. Association for Computational Linguistics
2023
-
[79]
PsyCoPref: Psychotherapy preference dataset
Psychotherapy-LLM. PsyCoPref: Psychotherapy preference dataset. Hugging Face Datasets, 2024
2024
-
[80]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 13
2023
-
[81]
Is LLM-as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment
Vyas Raina, Adian Liusie, and Mark Gales. Is LLM-as-a-Judge Robust? Investigating Universal Adversarial Attacks on Zero-shot LLM Assessment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7499–7517, Miami, Florida, USA, 2024. Association for Computational Linguistics
2024
-
[82]
Constructing Domain-Specific Evaluation Sets for LLM-as-a-judge
Ravi Shanker Raju, Swayambhoo Jain, Bo Li, Jonathan Lingjie Li, and Urmish Thakker. Constructing Domain-Specific Evaluation Sets for LLM-as-a-judge. InProceedings of the 1st Workshop on Customiz- able NLP: Progress and Challenges in Customizing NLP for a Domain, Application, Group, or Individual (CustomNLP4U), pages 167–181, Miami, Florida, USA, 2024. Ass...
2024
-
[83]
A systematic survey of automatic prompt optimization techniques
Kiran Ramnath, Kang Zhou, Sheng Guan, Soumya Smruti Mishra, Xuan Qi, Zhengyuan Shen, Shuai Wang, Sangmin Woo, Sullam Jeoung, Yawei Wang, et al. A systematic survey of automatic prompt optimization techniques. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33066–33098, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.