EmbodiSteer: Steering Embodiment-Agnostic Visuomotor Policies with Joint-Space Guidance for Zero-Shot Cross-Embodiment Deployment
Pith reviewed 2026-06-27 06:34 UTC · model grok-4.3
The pith
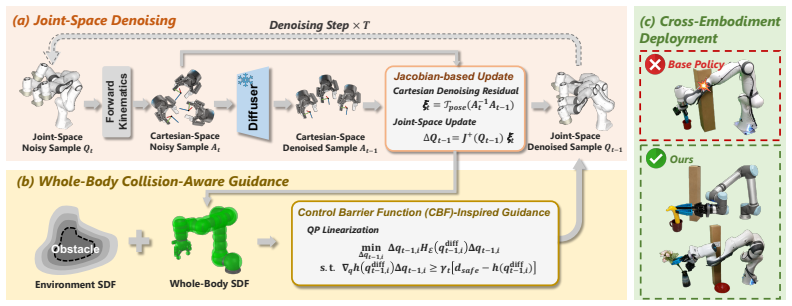
EmbodiSteer steers embodiment-agnostic visuomotor policies into joint space with Jacobian updates after each denoising step to enable collision-free zero-shot deployment on new robot bodies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With whole-body collision-aware guidance over joint trajectories after each denoising step, the arm can be steered away from collisions while preserving learned end-effector behavior from the embodiment-agnostic Cartesian policy.
What carries the argument
Jacobian-based updates that lift inference-time diffusion sampling into the target robot's joint space via forward kinematics and apply collision-aware corrections after each denoising step.
If this is right
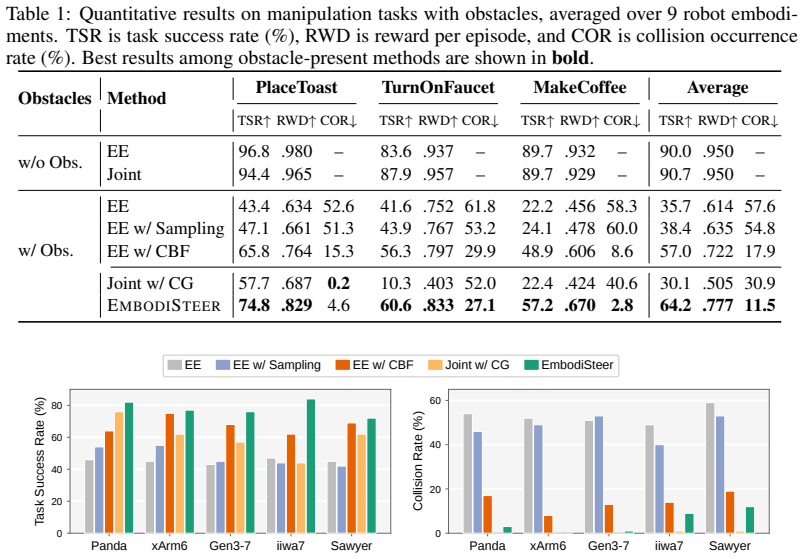
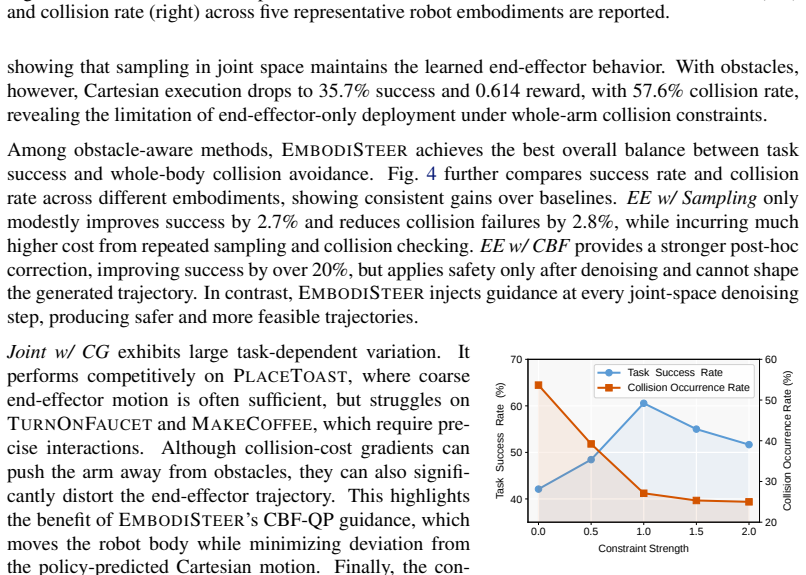
- Collision rate drops by 46.1% with 28.5% higher task success across 9 simulated robots compared to Cartesian-only execution.
- Physical robots see 90.0% collision rate reduction and 36.7% success rate increase in constrained scenarios.
- Policy learning stays in Cartesian space while deployment becomes embodiment-aware at inference time.
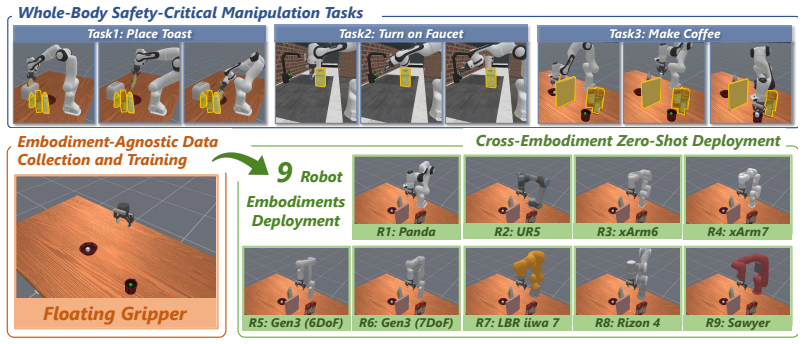
- Zero-shot cross-embodiment deployment becomes possible without retraining or embodiment-specific data.
Where Pith is reading between the lines
- Similar guidance could extend to other constraints like joint velocity limits or torque bounds.
- The approach might allow combining policies trained on body-free data with any new hardware without fine-tuning.
- Testing on more complex tasks with dynamic obstacles could reveal limits of the post-denoising correction.
Load-bearing premise
Jacobian-based updates applied after each diffusion denoising step can steer joint trajectories away from collisions without materially distorting the distribution or end-effector behavior produced by the original Cartesian policy.
What would settle it
A test where applying the joint-space guidance causes the end-effector to miss the target by more than the original policy's error margin, or where collision rates remain unchanged despite the guidance.
Figures



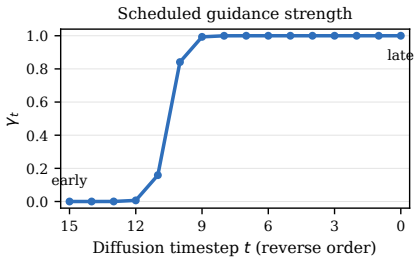
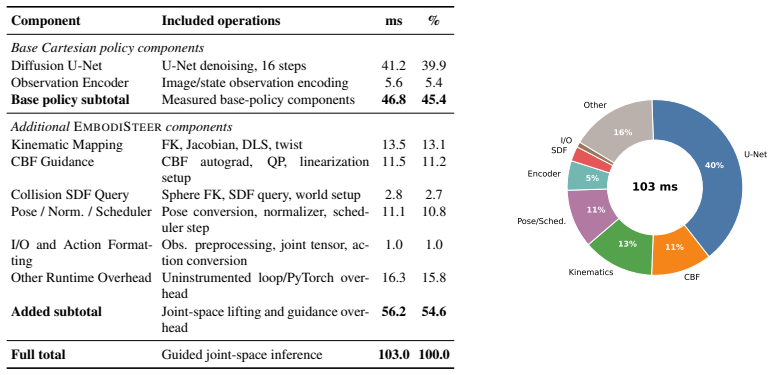
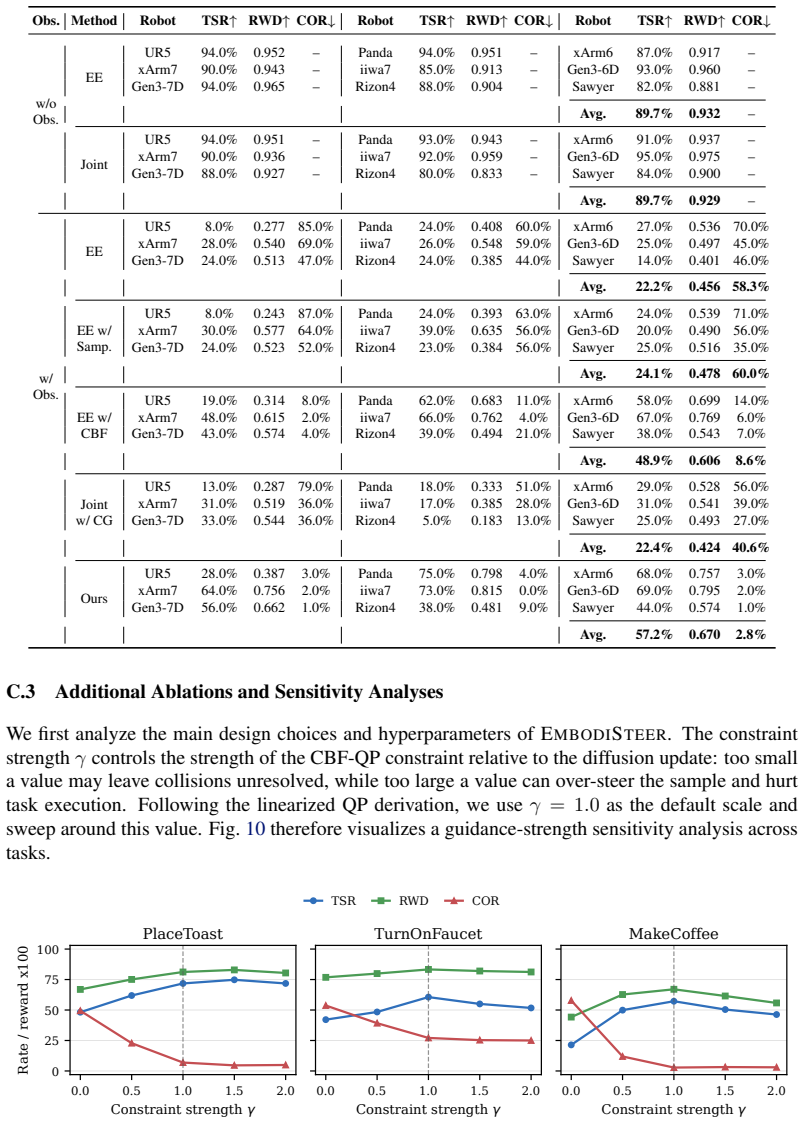
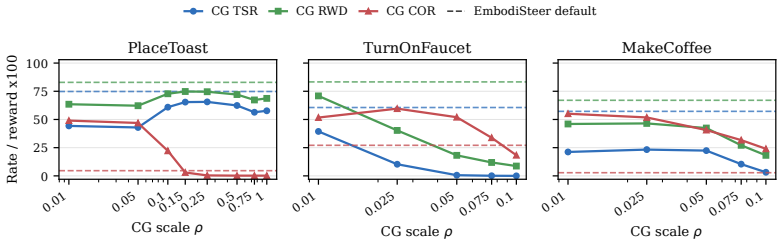





read the original abstract
Scalable robot imitation learning relies on large-scale heterogeneous data from diverse robots or body-free data, making Cartesian end-effector actions a key interface for embodiment-agnostic policy learning. However, end-effector-only abstraction leaves Cartesian policies unaware of the deployed robot body, making them brittle under robot-specific constraints such as whole-body collision avoidance. To overcome this limitation, we present EmbodiSteer, a training-free framework that steers embodiment-agnostic visuomotor policies toward zero-shot, embodiment-aware deployment. EmbodiSteer keeps policy learning in Cartesian space while efficiently lifting inference-time diffusion sampling into the target robot's joint space via forward kinematics and Jacobian-based updates. With whole-body collision-aware guidance over joint trajectories after each denoising step, the arm can be steered away from collisions while preserving learned end-effector behavior. Compared with Cartesian-only execution, EmbodiSteer reduces collision rate by 46.1% and improves task success rate by 28.5% across 9 simulated robots, and further achieves 90.0% collision rate reduction and 36.7% success rate increase on two physical robots in highly constrained scenarios. Our project page is at https://frankwang67.github.io/EmbodiSteer-Page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EmbodiSteer, a training-free framework that steers embodiment-agnostic Cartesian visuomotor policies (learned via imitation on heterogeneous data) into joint space at inference time. It lifts diffusion denoising steps via forward kinematics and applies Jacobian-based whole-body collision-aware guidance after each step to avoid collisions while claiming to preserve the original end-effector behavior, reporting 46.1% collision reduction and 28.5% success improvement across 9 simulated robots plus 90.0% collision reduction and 36.7% success increase on two physical robots in constrained scenarios.
Significance. If the central claim holds with verifiable preservation of the learned Cartesian distribution, the approach would be significant for enabling zero-shot cross-embodiment deployment of policies without retraining or embodiment-specific data, addressing a practical bottleneck in scalable robot learning. The training-free design and reported gains on both simulation and hardware are strengths that could influence deployment practices if the non-distortion property is rigorously established.
major comments (2)
- [Abstract] Abstract (paragraph describing the framework): The central claim that Jacobian-based updates after each denoising step steer joint trajectories away from collisions 'while preserving learned end-effector behavior' rests on an unexamined assumption that these post-denoising corrections commute with the diffusion process and keep samples on the original Cartesian manifold; no preservation guarantees, error bounds, or analysis of accumulated Cartesian deviations are provided, which is load-bearing for the claim that end-effector behavior remains materially unchanged.
- [Abstract] Abstract: The reported performance gains (46.1% collision reduction, 28.5% success increase on 9 sim robots; 90.0% and 36.7% on physical) cannot be evaluated because the abstract supplies no experimental protocol, baseline comparisons, number of trials, variance measures, or implementation specifics for the guidance term (e.g., how the collision cost is formulated or its weighting relative to the denoising process), undermining the data-to-claim link.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the framework): The central claim that Jacobian-based updates after each denoising step steer joint trajectories away from collisions 'while preserving learned end-effector behavior' rests on an unexamined assumption that these post-denoising corrections commute with the diffusion process and keep samples on the original Cartesian manifold; no preservation guarantees, error bounds, or analysis of accumulated Cartesian deviations are provided, which is load-bearing for the claim that end-effector behavior remains materially unchanged.
Authors: We agree that the abstract does not supply formal preservation guarantees, error bounds, or accumulated deviation analysis. The design applies small Jacobian-based corrections after each denoising step so that the diffusion process can continue from a feasible joint configuration; because the pseudo-inverse Jacobian maps the correction primarily into redundant degrees of freedom, end-effector deviation remains local. We will revise the abstract to qualify the claim as approximate preservation and add a short empirical deviation analysis plus discussion of the approximation in the methods section of the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The reported performance gains (46.1% collision reduction, 28.5% success increase on 9 sim robots; 90.0% and 36.7% on physical) cannot be evaluated because the abstract supplies no experimental protocol, baseline comparisons, number of trials, variance measures, or implementation specifics for the guidance term (e.g., how the collision cost is formulated or its weighting relative to the denoising process), undermining the data-to-claim link.
Authors: Abstract length constraints prevent inclusion of full protocol details. The complete experimental protocol (trial counts, variance reporting, baselines, collision-cost formulation, and guidance weighting) appears in Sections 4–6 and the supplement. We will revise the abstract to include a concise statement of the evaluation scale and key implementation parameters. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and framework description introduce EmbodiSteer as a training-free method that applies Jacobian-based updates after diffusion denoising steps for collision avoidance. No equations, predictions, or claims in the text reduce reported gains (e.g., collision rate reduction) to quantities defined by fitted parameters or self-referential definitions. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation are present. The central claim rests on the proposed guidance mechanism itself rather than reducing to its inputs by construction. This is the expected honest non-finding for a methods paper whose performance metrics are externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[2]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[3]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[5]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[6]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[7]
Y . Wang, S. Zheng, H. Luo, W. Zhang, H. Yuan, C. Xu, H. Xu, Y . Feng, M. Yu, Z. Kang, et al. Rethinking visual-language-action model scaling: Alignment, mixture, and regulariza- tion.arXiv preprint arXiv:2602.09722, 2026
arXiv 2026
-
[8]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
- [9]
-
[10]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[11]
L. Wang, X. Chen, J. Zhao, and K. He. Scaling proprioceptive-visual learning with hetero- geneous pre-trained transformers.Advances in neural information processing systems, 37: 124420–124450, 2024
2024
-
[12]
M. Xu, Z. Xu, C. Chi, M. Veloso, and S. Song. Xskill: Cross embodiment skill discovery. In Conference on robot learning, pages 3536–3555. PMLR, 2023
2023
-
[13]
L. Zha, A. J. Hancock, M. Zhang, T. Yin, Y . Huang, D. Shah, A. Z. Ren, and A. Majum- dar. Lap: Language-action pre-training enables zero-shot cross-embodiment transfer.arXiv preprint arXiv:2602.10556, 2026
arXiv 2026
-
[14]
Zheng, J
J. Zheng, J. Li, D. Liu, Y . Zheng, Z. Wang, Z. Ou, Y . Liu, J. Liu, Y .-Q. Zhang, and X. Zhan. Universal actions for enhanced embodied foundation models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22508–22519, 2025
2025
-
[15]
Patel and S
A. Patel and S. Song. Get-zero: Graph embodiment transformer for zero-shot embodiment generalization. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 14262–14269. IEEE, 2025. 9
2025
- [16]
-
[17]
M. Xu, H. Zhang, Y . Hou, Z. Xu, L. Fan, M. Veloso, and S. Song. Dexumi: Using hu- man hand as the universal manipulation interface for dexterous manipulation.arXiv preprint arXiv:2505.21864, 2025
arXiv 2025
-
[18]
H. Ha, Y . Gao, Z. Fu, J. Tan, and S. Song. Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers.arXiv preprint arXiv:2407.10353, 2024
arXiv 2024
-
[19]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[20]
C. Sferrazza, D.-M. Huang, F. Liu, J. Lee, and P. Abbeel. Body transformer: Leveraging robot embodiment for policy learning.arXiv preprint arXiv:2408.06316, 2024
arXiv 2024
-
[21]
N. Bohlinger, G. Czechmanowski, M. Krupka, P. Kicki, K. Walas, J. Peters, and D. Tateo. One policy to run them all: an end-to-end learning approach to multi-embodiment locomotion. arXiv preprint arXiv:2409.06366, 2024
arXiv 2024
-
[22]
H. Luo, W. Zhang, Y . Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y . Fu, and Z. Lu. Being-h0. 7: A latent world-action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
Pith/arXiv arXiv 2026
-
[23]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
- [24]
-
[25]
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025
Pith/arXiv arXiv 2025
-
[26]
Y . Liu, J. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional decoding: Improving action chunking via guided test-time sampling. InInternational Conference on Learning Rep- resentations, volume 2025, pages 4594–4627, 2025
2025
-
[27]
R. R ¨omer, J. Balletshofer, J. Thumm, M. Pavone, A. P. Schoellig, and M. Althoff. From demonstrations to safe deployment: Path-consistent safety filtering for diffusion policies.arXiv preprint arXiv:2511.06385, 2025
arXiv 2025
-
[28]
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
- [29]
-
[30]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[31]
K. M. Lee, S. Ye, Q. Xiao, Z. Wu, Z. Zaidi, D. B. D’Ambrosio, P. R. Sanketi, and M. C. Gombolay. Learning diverse robot striking motions with diffusion models and kinematically constrained gradient guidance. In2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 12017–12024, 2025. doi:10.1109/ICRA55743.2025.11127310. 10
-
[32]
Xiao, T.-H
W. Xiao, T.-H. Wang, C. Gan, R. Hasani, M. Lechner, and D. Rus. Safediffuser: Safe planning with diffusion probabilistic models. InInternational Conference on Learning Representations, 2025
2025
-
[33]
Zhang, L
J. Zhang, L. Zhao, A. Papachristodoulou, and J. Umenberger. Constrained diffusers for safe planning and control.Advances in Neural Information Processing Systems, 38:34965–34998, 2026
2026
-
[34]
Zhong, Q
Y . Zhong, Q. Jiang, J. Yu, and Y . Ma. Dexgrasp anything: Towards universal robotic dex- terous grasping with physics awareness. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22584–22594, 2025
2025
-
[35]
Z. Weng, H. Lu, D. Kragic, and J. Lundell. Dexdiffuser: Generating dexterous grasps with diffusion models.IEEE Robotics and Automation Letters, 9(12):11834–11840, 2024
2024
-
[36]
Y . Jia, Y . Jiang, K. Lv, Y . Ren, and X. Li. Arm-aware guided dexterous grasp generation with arm-agnostic grasp models.IEEE Robotics and Automation Letters, 11(5):5875–5882, 2026. doi:10.1109/LRA.2026.3674025
-
[37]
Du and S
M. Du and S. Song. Dynaguide: Steering diffusion policies with active dynamic guidance. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[38]
Y . Wang, L. Wang, Y . Du, B. Sundaralingam, X. Yang, Y .-W. Chao, C. P ´erez-D’Arpino, D. Fox, and J. Shah. Inference-time policy steering through human interactions. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15626–15633. IEEE, 2025
2025
-
[39]
H. Gupta, X. Guo, H. Ha, C. Pan, M. Cao, D. Lee, S. Scherer, S. Song, and G. Shi. Umi- on-air: Embodiment-aware guidance for embodiment-agnostic visuomotor policies. In2026 IEEE International Conference on Robotics and Automation (ICRA), 2026. URLhttps: //arxiv.org/abs/2510.02614
Pith/arXiv arXiv 2026
-
[40]
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada. Control barrier functions: Theory and applications. In2019 18th European control conference (ECC), pages 3420–3431. Ieee, 2019
2019
-
[41]
S. Hu, Z. Liu, S. Liu, J. Cen, Z. Meng, and X. He. Vlsa: Vision-language-action models with plug-and-play safety constraint layer.arXiv preprint arXiv:2512.11891, 2025
arXiv 2025
-
[42]
Brunke, Y
L. Brunke, Y . Zhang, R. R¨omer, J. Naimer, N. Staykov, S. Zhou, and A. P. Schoellig. Semanti- cally safe robot manipulation: From semantic scene understanding to motion safeguards.IEEE Robotics and Automation Letters, 2025
2025
-
[43]
K. P. Wabersich and M. N. Zeilinger. A predictive safety filter for learning-based control of constrained nonlinear dynamical systems.Automatica, 129:109597, 2021
2021
-
[44]
S. Gros, M. Zanon, and A. Bemporad. Safe reinforcement learning via projection on a safe set: How to achieve optimality?IF AC-PapersOnLine, 53(2):8076–8081, 2020
2020
-
[45]
X. Zhai, B. Ou, Y . Wang, H. Y . Leong, Q. Yu, C. Hao, and Y . Liu. Cofreevla: Collision-free dual-arm manipulation via vision-language-action model and risk estimation.arXiv preprint arXiv:2601.21712, 2026
arXiv 2026
-
[46]
H. Li, Q. Feng, Z. Zheng, J. Feng, Z. Chen, and A. Knoll. Language-guided object-centric dif- fusion policy for generalizable and collision-aware manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12834–12841. IEEE, 2025
2025
-
[47]
H. Deng, W. Guo, Q. Wang, Z. Wu, and Z. Wang. Safebimanual: Diffusion-based trajectory optimization for safe bimanual manipulation.arXiv preprint arXiv:2508.18268, 2025. 11
arXiv 2025
-
[48]
Dastider, H
A. Dastider, H. Fang, and M. Lin. Apex: Ambidextrous dual-arm robotic manipulation using collision-free generative diffusion models. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9526–9533. IEEE, 2024
2024
-
[49]
K. Lv, M. Yu, Y . Jia, C. Zhang, and X. Li. Kinematics-aware diffusion policy with consistent 3d observation and action space for whole-arm robotic manipulation.IEEE Robotics and Automation Letters, 2026. doi:10.1109/LRA.2026.3685437
-
[50]
Q. Lv, H. Li, X. Deng, R. Shao, Y . Li, J. Hao, L. Gao, M. Y . Wang, and L. Nie. Spatial- temporal graph diffusion policy with kinematic modeling for bimanual robotic manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17394– 17404, 2025
2025
-
[51]
K. Chen, Z. Bi, G. Zhao, C. Zheng, Y . Li, H. Zhao, and J. Ma. Samp: Spatial anchor-based motion policy for collision-aware robotic manipulators.arXiv preprint arXiv:2509.11185, 2025
arXiv 2025
-
[52]
Fishman, A
A. Fishman, A. Walsman, M. Bhardwaj, W. Yuan, B. Sundaralingam, B. Boots, and D. Fox. Avoid everything: Model-free collision avoidance with expert-guided fine-tuning. InCoRL Workshop on Safe and Robust Robot Learning for Operation in the Real World, 2024
2024
-
[53]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5745–5753, 2019
2019
-
[54]
H. Ma, S. Bodmer, A. Carron, M. Zeilinger, and M. Muehlebach. Constraint-aware diffusion guidance for robotics: Real-time obstacle avoidance for autonomous racing.arXiv preprint arXiv:2505.13131, 2025
arXiv 2025
-
[55]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.