IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
Pith reviewed 2026-06-26 00:17 UTC · model grok-4.3
The pith
Decomposing visual queries into structural planning then semantic rendering improves structure-aware text-to-image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
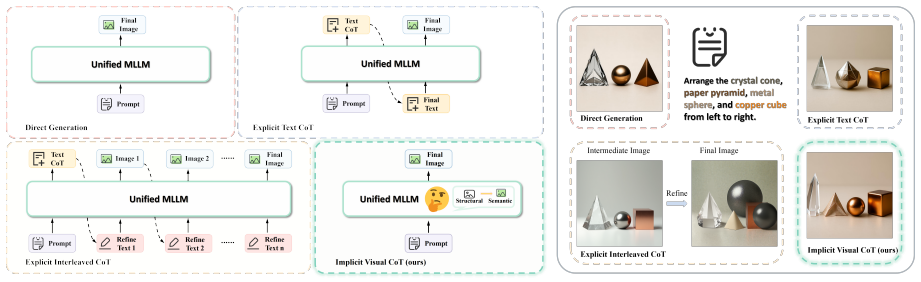
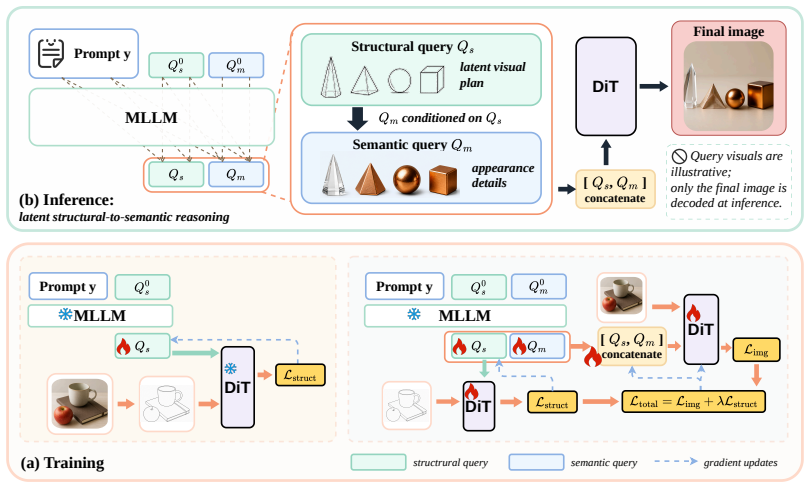
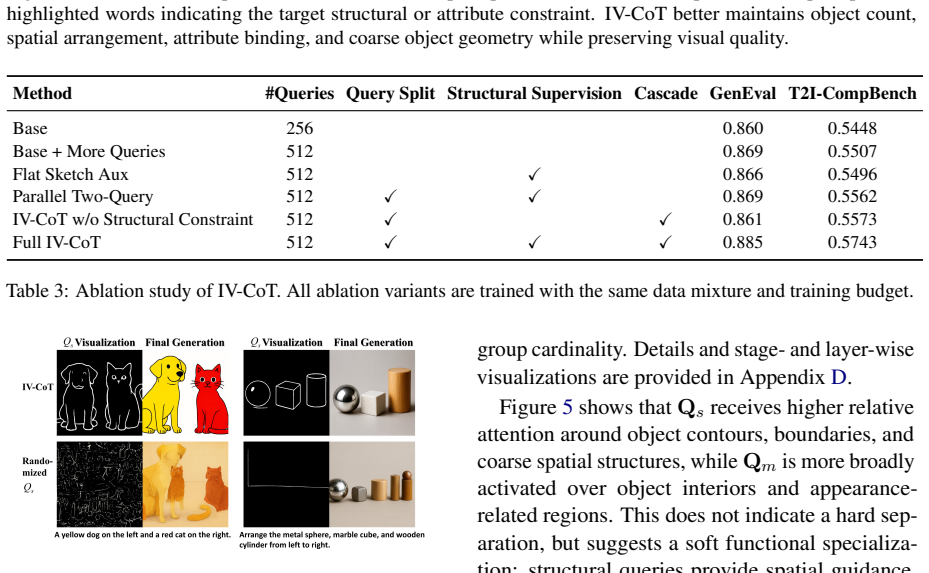
IV-CoT decomposes the visual conditioning queries into a structural-to-semantic cascade, where structural queries first form a latent visual plan and semantic queries then render appearance conditioned on this plan. To guide the structural queries, training-only sketch supervision is introduced, which encourages them to capture structure from sketches without requiring sketch extraction or intermediate decoding at inference time. IV-CoT performs implicit CoT reasoning in a single forward pass and achieves superior results on GenEval and T2I-CompBench. Visualizations show that the learned structural and semantic queries play complementary roles.
What carries the argument
The structural-to-semantic cascade that forms a latent visual plan from structural queries before semantic rendering begins.
If this is right
- Structural queries capture layout and relations while semantic queries handle appearance details.
- No sketches or intermediate outputs are needed when the model generates images.
- Results improve on benchmarks that measure counts, positions, and bindings.
- The two query types play complementary roles, as shown by visualizations.
Where Pith is reading between the lines
- The same query split might help other generation tasks that need planning before detail, such as video sequences.
- The latent plan could be examined after training to locate where structure errors originate.
- Sketch supervision during training could be replaced by other weak signals for structure in future variants.
Load-bearing premise
The main limitation comes from entanglement of planning and rendering in one stream, and that sketch supervision during training alone produces a usable latent plan without needing sketches or extra steps at inference.
What would settle it
Train an otherwise identical model without the structural-query component or without the sketch supervision and check whether scores on GenEval and T2I-CompBench drop on metrics for object count, spatial relations, and attribute binding.
Figures





read the original abstract
Unified multi-modal large language models (MLLMs) have achieved strong text-to-image generation quality, but still struggle with structure-aware prompt following, where object counts, spatial relations, attribute bindings, and coarse layouts must be preserved. We attribute this limitation in part to the entanglement of structural planning and appearance rendering within a single conditioning stream. To address this issue, we propose Implicit Visual Chain-of-Thought (IV-CoT), a latent visual reasoning framework for query-conditioned image generation. IV-CoT decomposes the visual conditioning queries into a structural-to-semantic cascade, where structural queries first form a latent visual plan and semantic queries then render appearance conditioned on this plan. To guide the structural queries, we introduce training-only sketch supervision, which encourages them to capture structure from sketches without requiring sketch extraction or intermediate decoding at inference time. IV-CoT performs implicit CoT reasoning in a single forward pass and achieves superior results on GenEval and T2I-CompBench. Visualizations and analyses demonstrate that the learned structural and semantic queries play complementary roles in structure-aware generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Implicit Visual Chain-of-Thought (IV-CoT) for structure-aware text-to-image generation in unified MLLMs. It decomposes visual conditioning queries into a structural-to-semantic cascade in which structural queries form a latent visual plan (guided by training-only sketch supervision) and semantic queries then render appearance conditioned on that plan, all within a single forward pass without sketches or extra decoding at inference. The method is claimed to address entanglement of planning and rendering and to achieve superior results on GenEval and T2I-CompBench, supported by visualizations and analyses of complementary query roles.
Significance. If the training-only sketch supervision reliably induces a usable latent visual plan that semantic queries actually condition upon, the approach would offer a practical way to improve structural fidelity in MLLM-based generation without inference-time overhead, potentially advancing disentangled reasoning in multimodal models.
major comments (3)
- [Method] Method section (sketch supervision paragraph): no ablation is reported that removes or varies the sketch supervision loss while keeping the structural/semantic query split fixed; without this, it is impossible to attribute any benchmark gains specifically to the formation of an implicit latent plan rather than to the query decomposition or other regularizers.
- [Experiments] Experiments section: the central claim that semantic queries render appearance conditioned on the structural plan requires direct verification (e.g., representation probing, intervention on structural-query outputs, or controlled comparison of query roles); the manuscript supplies only visualizations, which are insufficient to confirm the claimed cascade.
- [Results] Results section (GenEval / T2I-CompBench tables): quantitative deltas, full baseline comparisons, and error analysis are referenced but the visible description provides no numerical values, standard deviations, or statistical significance tests, making it impossible to evaluate whether the reported superiority is robust or load-bearing for the implicit-CoT hypothesis.
minor comments (2)
- [Abstract] Abstract: the phrase 'achieves superior results' should be accompanied by at least the headline metric values (e.g., GenEval overall score) so readers can immediately gauge the magnitude of the improvement.
- [Method] Notation: the distinction between 'structural queries' and 'semantic queries' is introduced without an explicit equation or diagram showing how they are instantiated from the same MLLM backbone; a short formal definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Method] Method section (sketch supervision paragraph): no ablation is reported that removes or varies the sketch supervision loss while keeping the structural/semantic query split fixed; without this, it is impossible to attribute any benchmark gains specifically to the formation of an implicit latent plan rather than to the query decomposition or other regularizers.
Authors: We agree that an ablation isolating the sketch supervision loss (while fixing the query split) is required to attribute gains specifically to the latent plan. We will add this controlled ablation to the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section: the central claim that semantic queries render appearance conditioned on the structural plan requires direct verification (e.g., representation probing, intervention on structural-query outputs, or controlled comparison of query roles); the manuscript supplies only visualizations, which are insufficient to confirm the claimed cascade.
Authors: Visualizations illustrate complementary roles, yet we acknowledge the value of direct verification. We will add representation probing experiments in the revision to confirm that semantic queries condition upon the structural plan outputs. revision: yes
-
Referee: [Results] Results section (GenEval / T2I-CompBench tables): quantitative deltas, full baseline comparisons, and error analysis are referenced but the visible description provides no numerical values, standard deviations, or statistical significance tests, making it impossible to evaluate whether the reported superiority is robust or load-bearing for the implicit-CoT hypothesis.
Authors: The tables contain the quantitative results and comparisons. We will augment them with standard deviations and statistical significance tests in the revised manuscript. revision: yes
Circularity Check
No circularity: new architecture and training procedure with externally verifiable benchmark gains.
full rationale
The paper introduces IV-CoT as a decomposition of conditioning queries into structural-to-semantic cascade with training-only sketch supervision, claiming this addresses entanglement in MLLMs and yields better GenEval/T2I-CompBench scores. No equations, fitted parameters, or self-citations are presented that reduce the claimed latent plan or performance improvements to the inputs by construction. The method is a standard empirical proposal whose validity rests on independent benchmark evaluation and ablation, not on renaming or self-referential definitions. This is the normal case of a self-contained ML architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2505.14683 , year=
Emerging properties in unified multimodal pretraining , author=. arXiv preprint arXiv:2505.14683 , year=
-
[3]
arXiv preprint arXiv:2512.05112 , year=
DraCo: Draft as CoT for Text-to-Image Preview and Rare Concept Generation , author=. arXiv preprint arXiv:2512.05112 , year=
-
[4]
arXiv preprint arXiv:2511.16671 , year=
Thinking-while-generating: Interleaving textual reasoning throughout visual generation , author=. arXiv preprint arXiv:2511.16671 , year=
-
[5]
arXiv preprint arXiv:2505.05422 , year=
Toklip: Marry visual tokens to clip for multimodal comprehension and generation , author=. arXiv preprint arXiv:2505.05422 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Mindomni: Unleashing reasoning generation in vision language models with rgpo , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2604.04911 , year=
Spatialedit: Benchmarking fine-grained image spatial editing , author=. arXiv preprint arXiv:2604.04911 , year=
-
[8]
Forty-third International Conference on Machine Learning , year=
Concept-Guided Tokenization: Closing the Gap Between Reconstruction and Generation , author=. Forty-third International Conference on Machine Learning , year=
-
[9]
arXiv preprint arXiv:2508.05606 , year=
Uni-cot: Towards unified chain-of-thought reasoning across text and vision , author=. arXiv preprint arXiv:2508.05606 , year=
-
[10]
arXiv preprint arXiv:2602.02227 , year=
Show, Don't Tell: Morphing Latent Reasoning into Image Generation , author=. arXiv preprint arXiv:2602.02227 , year=
-
[11]
arXiv preprint arXiv:2501.17811 , year=
Janus-pro: Unified multimodal understanding and generation with data and model scaling , author=. arXiv preprint arXiv:2501.17811 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2412.06769 , year=
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
-
[14]
arXiv preprint arXiv:2508.12587 , year=
Multimodal chain of continuous thought for latent-space reasoning in vision-language models , author=. arXiv preprint arXiv:2508.12587 , year=
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Softcot: Soft chain-of-thought for efficient reasoning with llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
arXiv preprint arXiv:2505.11484 , year=
Softcot++: Test-time scaling with soft chain-of-thought reasoning , author=. arXiv preprint arXiv:2505.11484 , year=
-
[17]
arXiv preprint arXiv:2510.12603 , year=
Reasoning in the dark: Interleaved vision-text reasoning in latent space , author=. arXiv preprint arXiv:2510.12603 , year=
-
[18]
arXiv preprint arXiv:2604.22709 , year=
Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought , author=. arXiv preprint arXiv:2604.22709 , year=
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Pixel difference networks for efficient edge detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Advances in Neural Information Processing Systems , volume=
Geneval: An object-focused framework for evaluating text-to-image alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2505.23661 , year=
Openuni: A simple baseline for unified multimodal understanding and generation , author=. arXiv preprint arXiv:2505.23661 , year=
-
[22]
arXiv preprint arXiv:2504.06256 , year=
Transfer between modalities with metaqueries , author=. arXiv preprint arXiv:2504.06256 , year=
-
[23]
arXiv preprint arXiv:2409.18869 , year=
Emu3: Next-token prediction is all you need , author=. arXiv preprint arXiv:2409.18869 , year=
-
[24]
International Conference on Learning Representations , volume=
Show-o: One single transformer to unify multimodal understanding and generation , author=. International Conference on Learning Representations , volume=
-
[25]
arXiv preprint arXiv:2604.24763 , year=
Tuna-2: Pixel embeddings beat vision encoders for multimodal understanding and generation , author=. arXiv preprint arXiv:2604.24763 , year=
-
[26]
arXiv preprint arXiv:2505.17022 , year=
Got-r1: Unleashing reasoning capability of mllm for visual generation with reinforcement learning , author=. arXiv preprint arXiv:2505.17022 , year=
-
[27]
International Conference on Learning Representations , volume=
Transfusion: Predict the next token and diffuse images with one multi-modal model , author=. International Conference on Learning Representations , volume=
-
[28]
International Conference on Learning Representations , volume=
Itercomp: Iterative composition-aware feedback learning from model gallery for text-to-image generation , author=. International Conference on Learning Representations , volume=
-
[29]
arXiv preprint arXiv:2505.11178 , year=
Compalign: Improving compositional text-to-image generation with a complex benchmark and fine-grained feedback , author=. arXiv preprint arXiv:2505.11178 , year=
-
[30]
arXiv preprint arXiv:2506.02161 , year=
TIIF-Bench: How Does Your T2I Model Follow Your Instructions? , author=. arXiv preprint arXiv:2506.02161 , year=
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Imagegen-cot: Enhancing text-to-image in-context learning with chain-of-thought reasoning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[32]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
What the daam: Interpreting stable diffusion using cross attention , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Advances in Neural Information Processing Systems , volume=
Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
R-Bind: Unified Enhancement of Attribute and Relation Binding in Text-to-Image Diffusion Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[35]
Advances in Neural Information Processing Systems , volume=
Layoutgpt: Compositional visual planning and generation with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2305.13655 , year=
Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models , author=. arXiv preprint arXiv:2305.13655 , year=
-
[37]
arXiv preprint arXiv:2410.09792 , year=
Generating Intermediate Representations for Compositional Text-To-Image Generation , author=. arXiv preprint arXiv:2410.09792 , year=
-
[38]
arXiv preprint arXiv:2511.06888 , year=
A Two-Stage System for Layout-Controlled Image Generation using Large Language Models and Diffusion Models , author=. arXiv preprint arXiv:2511.06888 , year=
-
[39]
arXiv preprint arXiv:2501.13926 , year=
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step , author=. arXiv preprint arXiv:2501.13926 , year=
-
[40]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Janus: Decoupling visual encoding for unified multimodal understanding and generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Advances in Neural Information Processing Systems , volume=
Show-o2: Improved native unified multimodal models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
5: Native multimodal models are world learners , author=
Emu3. 5: Native multimodal models are world learners , author=. arXiv preprint arXiv:2510.26583 , year=
-
[44]
arXiv preprint arXiv:2510.13500 , year=
MedREK: Retrieval-Based Editing for Medical LLMs with Key-Aware Prompts , author=. arXiv preprint arXiv:2510.13500 , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Omnigen: Unified image generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
arXiv preprint arXiv:2603.24840 , year=
Prune as you generate: Online rollout pruning for faster and better rlvr , author=. arXiv preprint arXiv:2603.24840 , year=
-
[47]
arXiv preprint arXiv:2502.06663 , year=
Efficientllm: Scalable pruning-aware pretraining for architecture-agnostic edge language models , author=. arXiv preprint arXiv:2502.06663 , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
Unigen: Enhanced training & test-time strategies for unified multimodal understanding and generation , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
arXiv preprint arXiv:2604.17789 , year=
DuQuant++: Fine-grained Rotation Enhances Microscaling FP4 Quantization , author=. arXiv preprint arXiv:2604.17789 , year=
-
[50]
Authorea Preprints , volume=
Efficient diffusion language models: A comprehensive survey , author=. Authorea Preprints , volume=
-
[51]
arXiv preprint arXiv:2503.12605 , year=
Multimodal chain-of-thought reasoning: A comprehensive survey , author=. arXiv preprint arXiv:2503.12605 , year=
-
[52]
arXiv preprint arXiv:2604.25299 , year=
The Thinking Pixel: Recursive Sparse Reasoning in Multimodal Diffusion Latents , author=. arXiv preprint arXiv:2604.25299 , year=
-
[53]
arXiv preprint arXiv:2509.22761 , year=
Milr: Improving multimodal image generation via test-time latent reasoning , author=. arXiv preprint arXiv:2509.22761 , year=
-
[54]
IEEE Transactions on Multimedia , year=
Scale up composed image retrieval learning via modification text generation , author=. IEEE Transactions on Multimedia , year=
-
[55]
arXiv preprint arXiv:2505.09568 , year=
Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset , author=. arXiv preprint arXiv:2505.09568 , year=
-
[56]
arXiv preprint arXiv:2506.18095 , year=
Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image generation , author=. arXiv preprint arXiv:2506.18095 , year=
-
[57]
arXiv preprint arXiv:2508.09987 , year=
Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation , author=. arXiv preprint arXiv:2508.09987 , year=
-
[58]
grpo , author=
Delving into rl for image generation with cot: A study on dpo vs. grpo , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
arXiv preprint arXiv:2505.24875 , year=
Reasongen-r1: Cot for autoregressive image generation models through sft and rl , author=. arXiv preprint arXiv:2505.24875 , year=
-
[60]
arXiv preprint arXiv:2508.14896 , year=
Quantization meets dllms: A systematic study of post-training quantization for diffusion llms , author=. arXiv preprint arXiv:2508.14896 , year=
-
[61]
arXiv preprint arXiv:2510.05593 , year=
Improving Chain-of-Thought Efficiency for Autoregressive Image Generation , author=. arXiv preprint arXiv:2510.05593 , year=
-
[62]
arXiv preprint arXiv:2504.00010 , year=
Layercraft: Enhancing text-to-image generation with cot reasoning and layered object integration , author=. arXiv preprint arXiv:2504.00010 , year=
-
[63]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Reflect-dit: Inference-time scaling for text-to-image diffusion transformers via in-context reflection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
From reflection to perfection: Scaling inference-time optimization for text-to-image diffusion models via reflection tuning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[65]
arXiv preprint arXiv:2509.06945 , year=
Interleaving reasoning for better text-to-image generation , author=. arXiv preprint arXiv:2509.06945 , year=
-
[66]
arXiv preprint arXiv:2504.10479 , year=
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
-
[67]
arXiv preprint arXiv:2501.18427 , year=
Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer , author=. arXiv preprint arXiv:2501.18427 , year=
-
[68]
International Conference on Learning Representations , volume=
Dq-lore: Dual queries with low rank approximation re-ranking for in-context learning , author=. International Conference on Learning Representations , volume=
-
[69]
arXiv preprint , year=
MMFormalizer: Multimodal Autoformalization in the Wild , author=. arXiv preprint , year=
-
[70]
arXiv preprint arXiv:2512.19271 , year=
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory , author=. arXiv preprint arXiv:2512.19271 , year=
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
UniAlignment: Semantic Alignment for Unified Image Generation, Understanding, Manipulation and Perception , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[72]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
MGHFT: Multi-Granularity Hierarchical Fusion Transformer for Cross-Modal Sticker Emotion Recognition , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Emotion and Intention Guided Multi-Modal Learning for Sticker Response Selection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[74]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Tgca-pvt: Topic-guided context-aware pyramid vision transformer for sticker emotion recognition , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[75]
arXiv preprint arXiv:2508.03668 , year=
CTR-Sink: Attention Sink for Language Models in Click-Through Rate Prediction , author=. arXiv preprint arXiv:2508.03668 , year=
-
[76]
arXiv preprint arXiv:2410.02719 , year=
Uncertaintyrag: Span-level uncertainty enhanced long-context modeling for retrieval-augmented generation , author=. arXiv preprint arXiv:2410.02719 , year=
-
[77]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Divide-then-align: Honest alignment based on the knowledge boundary of rag , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.